
这是一个自写库系列,即笔者在数据可视化路上踩过的坑的汇总,并自定义函数和传入参数来实现快速避坑 + 快速绘制出复杂精美的图片。
引言
Python 的绘图功能非常强大,如果能将已有的绘图库和各种复杂操作汇总在一个自己写的库/包中,并实现一行代码就调用并实现复杂的绘图功能,那就更强大了。所以本博文只强调绘图代码的实现,绘图中的统计学知识(名义变量,数值变量,xx图与xx图的区别等等)与 Python 基础库操作(seaborn,matplotlib)并不会提及,不过也欢迎关注,后续会有更多更广更丰富的知识疯狂输出。
使用方法 & 实现效果

细节图

为什么说树形图 treemap 是饼图的升级版呢? 先来看看饼图效果吧!
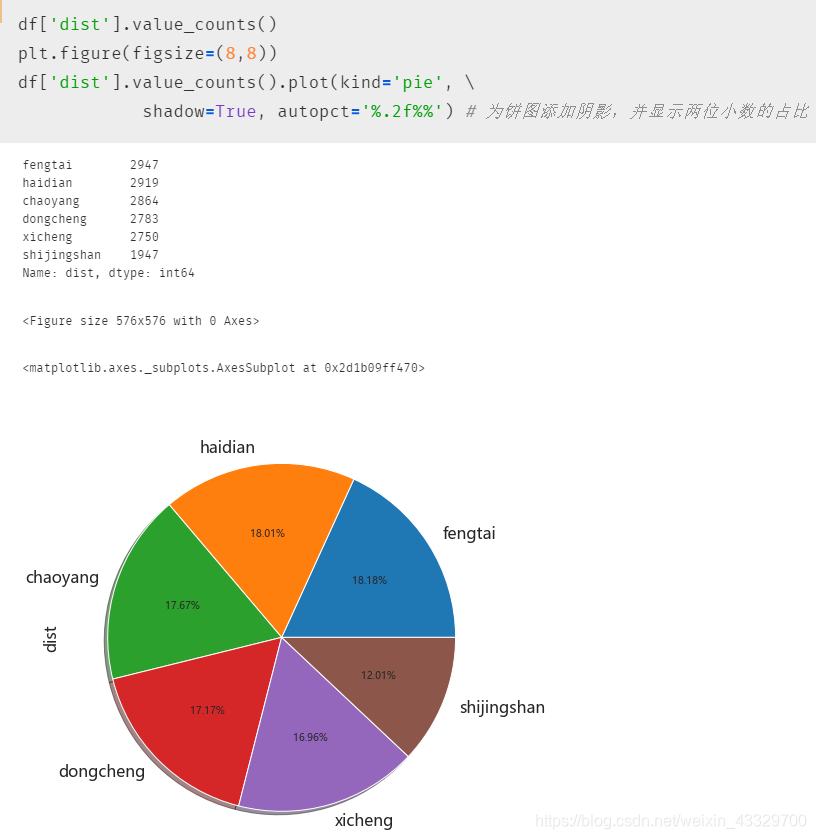
不难看出,我们的目的是对北京几个地区数据数目进行一个直观的可视化,饼图颜色会有点杀马特(需要另外调整),占比需要显式设置;反观树形图,占比不用设置,方块大小一目了然,数量也在每一列别的下面用小括号呈现了,配色也相对柔和。
如果我们一定需要展示占比情况的话,可以先使用 value_counts() 结合具体参数来观察一下差别,后再决定是选用水平条形图,垂直条形图,饼图,还是什么堆叠面积图之类的来绘制,这里指明一个快捷的有点骚的技巧。初识 pandas 者肯定都知道大名鼎鼎的 value_counts() ,但如果我们能在括号中添加两个小小的细节感满满的参数,效果就真的大不一样了,请看下图

明显可以看出,升级版 value_counts() 也就是添加了三个参数的 value_counts()还是有明显的变化的
- 有时候数目大,希望看出占比情况而不是只是显示出数量
- 升降序排列,谁多谁少一目了然,还可以直接在后面 .plot() 绘图
- dropna 参数的添加,避免数据中的空值占比没有算进去
随意画个图看下

这是这里的差别不明显罢了,所以柱子长短对排名的呈现并不是那么明显,以后呈现的商业实战就会贼明显了
代码展示!!
代码中的注释已经非常非常详细了!希望能够帮你规避画图中的各种坑。绘图代码并不是自己创作的,而是从前人(创造绘图库的人)和各种大神的代码中学习并积累下来的,为了画出一幅还比较完美的图,已经踩过无数的坑了,最终通过自己设置函数和函数中的参数来进行自定义的传参绘制,真的太难了
# 基础绘图库
import matplotlib.pyplot as plt
import seaborn as sns
# %matplotlib inline
# 各种细节配置如 文字大小,图例文字等杂项
large = 22; med = 16; small = 12
params = {'axes.titlesize': large,
'legend.fontsize': med,
'figure.figsize': (16, 10),
'axes.labelsize': med,
'axes.titlesize': med,
'xtick.labelsize': med,
'ytick.labelsize': med,
'figure.titlesize': large}
plt.rcParams.update(params)
plt.style.use('seaborn-whitegrid')
sns.set_style("white")
plt.rc('font', **{'family': 'Microsoft YaHei, SimHei'}) # 设置中文字体的支持
# sns.set(font='SimHei') # 解决Seaborn中文显示问题,但会自动添加背景灰色网格
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
# ====================== 树形图:饼图升级版 =============================
def treemap(data, column, figsize=(12 ,8), title=None, ax=None):
"""
data: 整份数据
column:传入格式 'col_name'
基准行,求改行各定类变量的个数,并以占比的情况反映在矩形区域中
"""
import squarify # 这个库需要 pip install 一下
# Prepare Data
# 下面这行代码是 pandas 中非常经典的操作,根据选中的名义变量进行分组,
## 分组后求每组的元素数量,并重置索引,新增的索引列为 counts,可以自己定制
## 这一行代码可以单独抽出来尝试使用并理解
data = data.groupby(column).size().reset_index(name='counts')
# 下面的这三行代码不用理解,就是在创造 squarify 时大神自己定义的
labels = data.apply(lambda x: str(x[0]) + "\n (" + str(x[1]) + ")", axis=1)
sizes = data['counts'].values.tolist() # 转成列表
colors = [plt.cm.Spectral( i /float(len(labels))) for i in range(len(labels))]
# Draw Plot
plt.figure(figsize=figsize, dpi= 80) # 设置图片大小
# 添加标签,图中部分元素
squarify.plot(sizes=sizes, label=labels, color=colors, alpha=.8, ax=ax)
# Decorate
plt.title(title)
plt.axis('off') # 关闭坐标轴显示
plt.title(title)
plt.show()
后记
数据分析,商业实践,数据可视化,网络爬虫,统计学,Excel,Word, 社会心理学,认知心理学,行为科学,民族意志学 各种专栏后续疯狂补充。
欢迎评论与私信交流!
