- InnoDB支持3种行锁的算法,分别是:
- Record Lock:单个行记录上的锁
- Gap Lock:间隙锁,锁定一个范围,但不包含记录本身
- Next-Key Lock:Gap Lock与Record Lock的结合,锁定一个范围,并且锁定记录本身
一、Record Lock
- Record Lock总是会去锁住索引记录
- 如果InnoDB存储引擎表在建立的时候没有设置任何一个索引,那么这时InnoDB会使用隐式的主键来进行锁定
二、Gap Lock
三、Next-Key Lock
- Next-key Lock是结合了Gap Lock和Record Lock的一种锁定算法,在该算法下,InnoDB对于行的查询都是采用这种锁定算法
- 在默认的隔离级别下,即REPEATABLE READ下,InnoDB采用Next-key Locking机制。而在READ COMMITTED下,其仅采用Record Lock
- 例如一个索引有10、11、13、20这四个值,那么该索引可能被Next-Key Locking的区间为:

Next-Key Locking锁定技术
- 采用Next-Key Lock的锁定技术称为Next-Key Locking。其设计的目的是为了解决Phantom Problem(在下面介绍)
- 而利用这种锁定技术,锁定的不是单个值,而是一个范围,是谓词锁(predict lock)的一种改进
- 若事务T1已经通过Next-Key Locking锁定了如下范围:
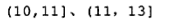
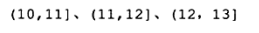
previous-key locking锁定技术
- 除了Next-Key Locking,还有previous-key locking技术。同样上述的索引10、11、13、20,若采用previous-key locking,则可锁定的区间如下:

演示案例①(Next-Key Lock降级为Record Lock)
- 然而,当查询的索引含有唯一属性时,InnoDB会对Next-Key Lock进行优化,将其降级为Record Lock,即仅锁住索引本身,而不是范围
- 看下面的例子,首先根据如下代码创建测试表t
drop table if exists t;
create table t(
a int primary key
);
insert into t select 1;
insert into t select 2;
insert into t select 5;

- 然后执行下面的两个事务:
- 表t中共有1、2、5三个值
- 下面的例子中,在会话A中首先对a=5进行X锁定,而由于a是主键且唯一,因此锁定的仅仅是5这个值,而不是(2,5)这个范围
- 这样在会话B中插入值4而不会阻塞,可以立即插入并返回

- 这就是Next-Key Lock算法降级为了Record Lock,从而提高应用的并发性
演示案例②(辅助索引使用Next-Key Lock)
- Next-Key Lock降级为Record Lock仅在查询的列是唯一索引的情况下。若是辅助索引,则情况会完全不同
- 同样,首先根据如下代码创建测试表z:
create table z(
a int,
b int,
primary key(a),
key(b)
);
insert into z select 1,1;
insert into z select 3,1;
insert into z select 5,3;
insert into z select 7,6;
insert into z select 10,8;

- 表z的列b是辅助索引,若在会话A中执行下面的SQL语句:
select * from z where b=3 for update;
- 这时SQL语句通过索引b进行查询,因此其使用传统的Next-Key Locking技术加锁
- 并且由于有两个索引,其需要分别进行加锁:
- 对于聚集索引,其仅在列a等于5的索引上加上Record Lock
- 对于辅助索引,其加上的是Next-Key Lock,锁定的范围是(1,3)
- 需要注意的是,InnoDB还会对辅助索引下一个键值加上gap lcok,即还有一个辅助索引范围为(3,6)的锁
- 因此,若在新会话B中运行下面的SQL语句,都会被阻塞:
- 第1个SQL语句:因为在会话A中执行的SQL语句已经对聚集索引中列a=5加上了X锁,因此执行会被阻塞
- 第2个SQL语句:主键插入4,没有问题,但是插入的辅助索引值2在锁定的范围(1,3)内,因此执行同样会阻塞
- 第3个SQL语句:插入的主键6没有被锁定,5也不在范围(1,3)之间。但插入的值4在另一个锁定的范围(3,6)中,故也会阻塞
select * from z where a=5 lock in share mode;
insert itno z select 4,2;
insert itno z select 6,5;
- 而下面SQL语句不会阻塞,可以执行执行:
- 因为下面的辅助索引的值都不在Next-Ket Lock的范围内
insert itno z select 8,6;
insert itno z select 2,0;
insert itno z select 6,7;
Phantom Problem问题
- Phantom(中文意为:虚幻)
- 在演示案例②中,可以看到Gap Lock的作用是为了阻止多个事务将记录插入到同一范围内,这会导致Phantom Problem问题的产生
- 例如在演示案例②中,会话A中用户已经锁定了b=3的记录。若此时没有Gap Lock锁定(3,6),那么用户可以插入索引b列为3的记录,这会导致会话A中的用户再执行同样查询时会返回不同的记录,即导致Phantom Problem问题的产生
- 用户可以通过以下两种方式来显式地关闭Gap Lock:
- 将事务的隔离级别设置为READ COMMITTED
- 将参数innodb_locks_unsafe_for_binlog设置为1
- 在上述配置中,除了外键约束和唯一性检查依然需要的Gap Lock,其余情况仅使用Record Lock进行锁定。但需要牢记的是,上述设置破坏了事务的隔离性,并且对于replication(复制),可能会导致主从数据的不一致。此外,从性能上看,READ COMMITED也不会优于默认的事务隔离级别READ REPEATTABLE
- 在InnoDB中,对于insert操作,其会检查插入记录的下一跳记录是否被锁定,若已经被锁定,则不允许查询。对于上面的例子,会话A已经锁定了表z中b=3的记录,即已经锁定了(1,3)的范围,这时若其他会话中进行如下的插入同样会导致阻塞:
- 因为在辅助索引列b上插入值为2的记录时,会检测到下一个记录3已经被索引
insert into z select 2,2;
insert into z select 2,0;
- 最后需再次提醒的是,对于唯一键值的锁定,Next-Key Lock降级为Record Lock仅存在于查询所有的唯一索引列。若唯一索引由多个列组成,而查询仅是查找多个唯一索引列中的其中一个,那么查询其实是range类型的查询,而不是point类型的查询,故InnoDB依然使用Next-Key Lock进行锁定
四、解决Phantom Problem
- 在默认的隔离级别下,即REPEATABLE READ下,InnoDB采用Next-key Locking机制来避免Phantom Problem(幻象问题)。这点可能不同于其他数据库,如Oracle数据库,因为其可能需要在SERIALIZABLE的事务隔离级别下才能解决Phantom Problem
- Phantom Problem是指:在同一事务下,连续执行两次同样的SQL语句可能导致不同的结果,第二次的SQL语句可能会返回之前不存在的行
演示案例
- 下面使用一个例子演示Phantom Problem
- 使用前面创建的表t,表t由1、2、5三个值组成
drop table if exists t;
create table t(
a int primary key
);
insert into t select 1;
insert into t select 2;
insert into t select 5;
select * from t where a>2 for update;
- 注意这时事务T1并没有进行提交操作,上述应该返回5这个结果
- 若与此同时,另一个事务T2插入了4这个值,并且数据库允许该操作
- 那么事务T1再次执行上述SQL语句会得到结果4和5,这与第一次得到的结果不同,违反了事务的隔离性,即当前事务能够看到其他事务的结果:
select * from t where a>2 for update;

- 此案例中,会话A采用READ COMMITED隔离级别(见下面介绍)
- InnoDB采用Next-Key Locking的算法避免Phantom Problem。对于上述的SQL语句,“select * from t where a>2 for update”,其锁住的不是5这单个值,而是对(2,+∞)这个范围加了X锁。因此任何对于这个范围的插入都是不被允许的,从而避免Phantom Problem
- InnoDB存储引擎默认的事务隔离级别是REPEATABLE READ,在该隔离级别下,其采用Next-Key Locking的方式来加锁。而在READ COMMITTED下,其仅采用Record Lock,因此在上述的演示案例中,会话A需要将事务的隔离级别设置为READ COMMITED
- 此外,用户可以通过InnoDB的Next-Key Locking机制在应用层面实现唯一性的检查。例如:

- 如果用户通过索引查询一个值,并对该行加上一个SLock,那么即使查询的值不在,其锁定的也是一个范围,因此若没有返回任何行,那么新插入的值一定是唯一的。也许有很多人疑问,如果在进行第一步“SELECT ... LOCK IN SHARE MODE”操作时,有多个事务并发操作,那么这种唯一性检查机制是否存在问题。其实并不会,因为这时会导致死锁,只有一个事务的插入操作会成功,而其余的事务会排除死锁的错误,如下图所示:

