阅读目录
基本概述
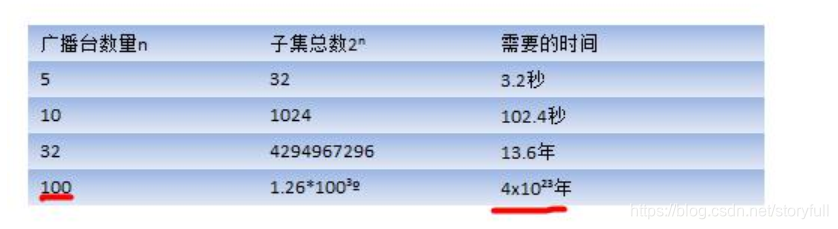
- 先来看一个应用场景:集合覆盖问题

(1)一般思路解答:

- 贪心算法介绍:


(1)贪婪算法解决思路:

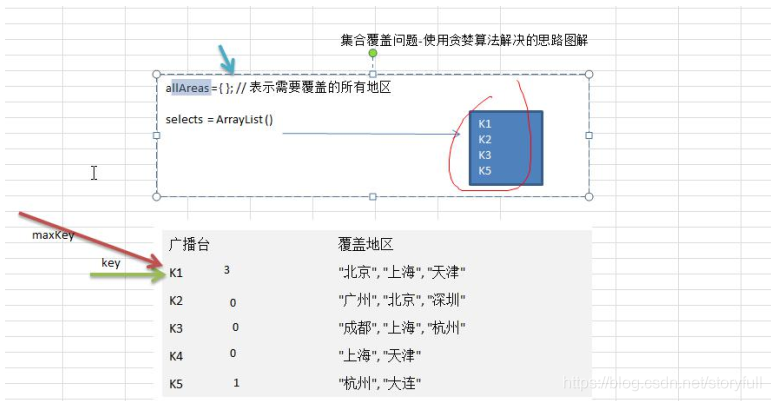
(2)图解思路:
Python实现贪心算法:集合覆盖问题
-
题目:
假设存在如下表的需要付费的广播台,以及广播台信号可以覆盖的地区。 如何选择最少的广播台,让所有的地区都可以接收到信号?广播台 覆盖地区
K1 “北京”, “上海”, “天津”
K2 “广州”, “北京”, “深圳”
K3 “成都”, “上海”, “杭州”
K4 “上海”, “天津”
K5 “杭州”, “大连”
第一种解法:完全参照教程
class GreedAlgorithm(object):
@staticmethod
def greed_algorithm(self, broad_dict):
all_areas = set()
for value in broad_dict.values():
for item in value:
all_areas.add(item)
# all_areas = {'北京', '上海', '天津', '广州', '深圳', '成都', '杭州', '大连'}
selects = []
# 定义一个临时集合,在遍历的过程中,存放遍历过程中的电台覆盖的地区和当前还没有覆盖的地区的交集
temp_set = set() # set类型,便于求交并补集
# 定义max_key,保存在一次比那里过程中,能够覆盖最大为覆盖的地区对应的电台key
# 如果max_key 不为None,则会加入到selects
max_key = ""
while len(all_areas) != 0: # 如果all_areas不为0,则表示还没有覆盖到所有地区
# 每进行一次while,需要把max_key置空
max_key = ""
max_num = 0
# 遍历broad_casts,对应的key
for key in broad_dict.keys():
# 每进行一次for 需要将已有的temp_set清空
temp_set.clear()
# 当前这个key能覆盖的地区
areas = broad_dict.get(key)
for item in areas:
temp_set.add(item)
# 求出temp和all_areas 集合的交集,交集再temp_set
temp_set = temp_set & all_areas
# 如果当前这个集合包含的未覆盖地区的数量,比max_key指向的集合未覆盖地区还要多
# 就需要重置max_key
# 下面判断条件,就体现贪婪算法的特点
if len(temp_set) > max_num:
max_key = key
max_num = len(temp_set)
# 如果max_key != None,就应该将max_key 加入到 selects中
if max_key:
selects.append(max_key)
# 将max_key指向的广播电台地区,从all_areas 中去掉
# all_areas.remove(broad_dict.get(str(max_key))) 坑:set不能一次性添加可变类型,所以要遍历一个个添加
for ele in broad_dict.get(max_key):
if ele in all_areas:
all_areas.remove(ele)
print(selects)
if __name__ == '__main__':
broad_casts = {'k1': ["北京", "上海", '天津'], 'k2': ['广州', '北京', '深圳'],
'k3': ['成都', '上海', '杭州'], 'k4': ['上海', '天津'],'k5': ['杭州', '大连']}
g = GreedAlgorithm()
g.greed_algorithm(g, broad_casts)
优化
def greedy_cover(broad_dict: dict):
# 创建一个set存放需要覆盖但还未覆盖的地区
all_areas = set()
for val in broad_dict.values():
for s in val:
all_areas.add(s)
selects = [] # 存放最终选择的电台
while len(all_areas): # 如果,all_areas为空即所有地区已覆盖,则可以结束
# 首先,选择覆盖了最多未覆盖地区的电台
max_key = ''
max_num = 0
for k in broad_dict.keys():
intersection = all_areas.intersection(broad_dict[k])
if len(intersection) > max_num:
max_key = k
max_num = len(intersection)
selects.append(max_key)
# 然后,将选择电台覆盖的地区从all_areas中移除
for e in broad_dict[max_key]:
if e in all_areas:
all_areas.remove(e)
return selects
if __name__ == '__main__':
broad_casts = {"k1": ["北京", "上海", "天津"], "k2": ["广州", "北京", "深圳"],
"k3": ["成都", "上海", "杭州"], "k4": ["上海", "天津"],
"k5": ["杭州", "大连"]}
print(greedy_cover(broad_casts))
- 总结:主要是用到了set集合,充分利用了set集合求交集和去除元素比较方便,对于这个不常用的数据类型,还是要多运用一下,注意一些细节,看来还得重新整理下set集合的用法,坑太多了!
