文章目录
前言
之前专业课有上Java,但当时没总结Java的知识点,回头找的时候,电脑中只剩下大堆大堆的Java代码,直到后来参加蓝桥杯的时候也没有系统的Java知识点复习,很后悔。所以趁着现在正在学数据结构,就想着把书中的一些经典算法分别用C++或Python重新实现一遍(学校数据结构教课书居然用的是Java写的算法 233333),之后复习也会方便一些。
现在常用的排序算法有插入排序,选择排序,冒泡排序,快速排序,归并排序,基数排序,和希尔排序等等。
C语言定义数组
C语言有很多定义数组的方法,常用的方法有如下三种:
1、直接使用int a[N]创建数组,但是此数组是静态数组,不能动态申请内存,也就是创建数组之初就应该声明N的值。
2、使用int* a=new int[N]创建数组,new出来数组所需的内存,属于动态申请,N可以是变量。
3、使用malloc函数动态创建数组,也属于动态申请。
需要注意的是后两种方法在使用完数组需要释放内存,new出来的数组使用delete[] a释放,malloc创建的数组使用free(a)来释放。
当N很大很大的时候,不能使用int a[N]来创建数组,应该使用后两种方法,因为int a[N]创建的数组内存放在栈上,栈的实际内存是连续空间,所以系统很难找到很大一块的连续空间,导致栈溢出而不能成功创建数组。后两种方法的内存是在堆上,堆可以是非连续内存,可以分配较大空间。
使用int a[N]这种方式,内存大小应该用常量指定,比如说数字10,或者宏定义,而不能使用int N=10,因为这时候N是变量。但是使用new还有malloc函数这两种方法可以,因此在动态分配内存上,后两者有很大优势,但是相应的,后两者需要释放内存。
/*
*created on May 13 13:47 2019
*
*@author:lhy
*/
#include <iostream>
#include<stdlib.h>
#define N 10
using namespace std;
void Output(int* a){
for(int i=0;i<N;i++){
cout<<a[i]<<" ";
}
cout<<"\n";
}
int main()
{
//第一种方法,直接创建数组
int a[N];
for(int i=0;i<N;i++)
a[i]=i;
Output(a);
//第二种方法,使用new动态开辟数组需要的空间,用指针指向首部
int* b=new int[N];
for(int i=0;i<N;i++)
b[i]=i+10;
Output(b);
delete[] b;
//第三种方法,使用malloc函数动态创建数组,用指针指向首部
int* c;
c=(int *)malloc(sizeof(int)*(N));
for(int i=0;i<N;i++)
c[i]=i+20;
Output(c);
free(c);
return 0;
}
Python定义数组
使用numpy即可。
import numpy as np
a=np.array([1,2,3,4,5])
目录
插入排序
插入排序核心思想:
将线性表看作有序列和无序列的两部分,有序列子表是a[0:i-1],无序列子表是a[i:n-1],排序过程中每次从无序列子表中取出一个元素,将这个元素按照大小插入有序列子表中的正确位置。随着这个过程,有序列子表不断增大,无序列子表不断减小,直到所有的记录都插入有序列子表为止。
下面是代码实现:
C++版本:
/*
created on April 11 2019 19:30
@author:lhy
*/
#include <iostream>
#include<stdio.h>
#define N 10
using namespace std;
void Output(int* a){
for(int i=0;i<N;i++)
cout<<a[i]<<" ";
cout<<"\n";
}
int main()
{
//创建动态数组a
int* a=new int[10]{1,2,4,43,11,456,1982,9,10,167};
int i,j=0;
//输出排序前的数组
Output(a);
for(i=1;i<N;i++){
int temp=a[i];
//找到temp应该插入的位置
for(j=i-1;j>=0;j--){
if(a[j]>temp){
a[j+1]=a[j];
}
else{
break;
}
}
//将temp插入有序部分
a[j+1]=temp;
}
//输出排序后的数组
Output(a);
delete []a;
return 0;
}
}
Python版本:
'''
created on April 11 2019 19:53
@author:lhy
'''
import numpy as np
#定义插入排序算法
def InsertSort(array):
for i in range(1,array.size):
x=array[i]
#将数组从i-1到0进行遍历,被遍历的区间是有序数组,找到合适的位置把数据插入到有序数组中
for j in range(i-1,-1,-1):
if(array[j]>x):
a[j+1]=a[j]
else:
break
a[j+1]=x
print(array)
if __name__=='__main__':
a=[1,2,4,43,11,456,1982,9,10,167]
#将Python列表转换成numpy数组
a=np.array(a)
#进行排序
InsertSort(a)
选择排序
选择排序基本思想:
选择排序仍然是将线性表看成有序和无序两个部分,其中有序子表是a[0:i-1],无序子表是a[i:n-1]。排序过程中每次从无序子表中挑选出最小的一个元素,将其添加到有序子表的末尾,有序子表保持有序状态并长度加1,无序子表长度减小1,重复这个过程直到无序子表为空。
下面是代码实现:
C++版本:
/*
created on April 11 2019 20:03
@author:lhy
*/
#include <iostream>
#define N 10
using namespace std;
//实现选择排序的函数
void ChooseSort(int a[]){
int i,j;
for(i=0;i<N-1;i++){
//从a[i+1:N-1]中选出最小的元素放在a[i]的位置
for(j=i+1;j<N;j++){
if(a[i]>a[j]){
int temp=a[i];
a[i]=a[j];
a[j]=temp;
}
}
}
}
//输出数组的函数
void Output(int* a){
for(int i=0;i<N;i++)
cout<<a[i]<<" ";
}
int main()
{
int a[N]={1,2,4,43,11,456,1982,9,10,167};
//进行排序
ChooseSort(a);
//输出排序后的数组
Output(a);
return 0;
}
Python版本:
'''
created on April 11 2019 19:55
@author:lhy
'''
import numpy as np
def ChooseSort(array):
for i in range(array.size-1):
#从a[i+1:n-1]选出最小的元素放在a[i]的位置上
for j in range(i+1,array.size):
if(array[j]<array[i]):
temp=array[j];
array[j]=array[i];
array[i]=temp;
print(array)
if __name__=="__main__":
a = [1, 2, 4, 43, 11, 456, 1982, 9, 10, 167]
# 将Python列表转换成numpy数组
a = np.array(a)
# 进行排序
ChooseSort(a)
冒泡排序
冒泡排序基本思想:
把数组a[n]中的n个元素看成一个有序表和一个无序表,与前两种排序不同,冒泡排序的有序表部分处于表的右端,而插入和选择排序堵塞有序表在表的左侧。开始时,有序表中没有元素,无序表中有n个元素。当进行排序的时候,将无序表中前后相邻元素(a[j]和a[j+1])逐个比较,如果满足大于或者小于条件就将两个元素进行交换,这样可以从选出无序表中最大or最小的元素放在无序表最后一个位置。最后将无序表的长度减一,有序表的长度加一,再进行无序表中的逐个比较,直到无序表长度为0,有序表长度为n为止。
下面是代码实现:
C++版本:
/*
created on April 12 2019 17:09
@author:lhy
*/
#include <iostream>
#define N 10
using namespace std;
void Output(int* a){
for(int i=0;i<N;i++){
cout<<a[i]<<" ";
}
}
int main()
{
//创建动态数组a
int* a=new int[N]{1,2,4,43,11,456,1982,9,10,167};
int i,j;
//进行冒泡排序
for(i=N-1;i>=0;i--){
for(j=0;j<i;j++){
if(a[j]>a[j+1]){
int temp=a[j];
a[j]=a[j+1];
a[j+1]=temp;
}
}
}
Output(a);
//释放数组a的内存
delete []a;
return 0;
}
Python版本:
'''
created on April 12 2019 17:17
@author:lhy
'''
import numpy as np
#冒泡排序函数
def BubbleSort(a):
for i in range(a.size-1,-1,-1):
for j in range(i):
if a[j]>a[j+1]:
t=a[j]
a[j]=a[j+1]
a[j+1]=t
print(a)
if __name__=="__main__":
a=np.array([1,2,4,43,11,456,1982,9,10,167])
#开始排序
BubbleSort(a)
快速排序
介绍完上面最基本的三种排序算法,接下来介绍目前一种实测平均速度最快的排序算法:快速排序,它是在冒泡排序的基础上进行改进的算法。
快速排序基本思想:
通过一趟划分将要排序序列分割成独立的三个部分,即为左部、基准值、右部三部分。其中,左部的所有数据都比基准值要小,右部的所有数据都比基准值大。经过这样一趟划分,就将数据分为两部分,且有初步的顺序。然后再对左部和右部进行划分,对左右部划分后的四个区间再进行左右划分,直到不能再划分为止。整个过程可以用递归实现。
举例
原始数据:49 38 65 97 76 13 27(以49为基准值进行一趟划分)
一趟划分的结果:27 38 13 49 76 97 65(分别取27和76作为左右部的基准值对左右部进行划分)
二趟划分的结果:13 27 38 49 65 76 97
可以看到,每次根据基准值划分的步骤
1、先向前搜索小于pivotkey(基准值)的值,将这个值放在前面,然后空出这个值的位置。
2、然后从前面开始搜索大于pivotkey的值,放在刚刚空出那个值的位置上。
3、然后再从后面向前搜索,开始重复1、2步骤。
下面是代码实现:
C++实现:
/*
created on April 12 2019 18:02
@author:lhy
*/
#include <iostream>
#define N 10
using namespace std;
//输出数组的函数
void Output(int a[]){
for(int i=0;i<N;i++)
cout<<a[i]<<" ";
}
//将a[i:j]根据基准值进行划分为两半的函数
int divide(int a[],int i,int j){
int pivotkey;
pivotkey=a[i];
while(i<j){
//从索引j向左搜索出第一个比pivotkey小的值所在的索引
while((i<j)&&(a[j]>pivotkey))
j--;
if(i<j){
//将右边比pivotkey小的值放在a[i]的位置
a[i]=a[j];
//将i索引加一,并从新的这个索引向后搜索
i++;
}
//从索引i向右搜索出第一个比pivotkey大的值所在的索引
while((i<j)&&(a[i]<pivotkey))
i++;
if(i<j){
//将左边比pivotkey大的值放在a[j]的位置
a[j]=a[i];
//将j索引减一,并从这个新索引向前搜索
j--;
}
}
//这时i=j,将pivotkey的值放在i或者j所在的位置,反正i和j都一样
a[i]=pivotkey; //也可以使用a[j]=pivotkey代替
return i;
}
//实现快速排序的函数
void quickSort(int a[],int l,int h){
if(l>=h){
return ;
}
else if(l<h){
int k;
//将数组a[l:h]之间的元素进行划分并重排序
k=divide(a,l,h);
//对划分后的左部分进行递归排序
quickSort(a,l,k-1);
//对划分后的右部分进行递归排序
quickSort(a,k+1,h);
}
}
int main()
{
int* a=new int[N]{1,2,4,43,11,456,1982,9,10,167};
//对数组的0到N-1进行排序
quickSort(a,0,N-1);
//输出排序后的数组
Output(a);
delete []a;
return 0;
}
Python实现:
'''
created on April 12 2019 22:08
@author:lhy
'''
import numpy as np
# 将a[i:j]根据基准值进行划分为两半的函数
def divide(a,i,j):
# 设置基准值为a[i]的值
povotkey=a[i]
while i<j:
#从右向左搜索出第一个比pivotkey小的值所在的索引
while i<j and a[j]>povotkey:
j-=1
if i<j:
#将右边比pivotkey小的值放在a[i]的位置
a[i]=a[j]
#将i索引加一,并从新的这个索引向后搜索
i+=1
# 从索引i向右搜索出第一个比pivotkey大的值所在的索引
while i<j and a[i]<povotkey:
i+=1
if i<j:
#将左边比pivotkey大的值放在a[j]的位置
a[j]=a[i]
#将j索引减一,并从这个新索引向前搜索
j-=1
# 这时i=j,将pivotkey的值放在i或者j所在的位置,反正i和j都一样
a[i]=povotkey
return i
def QuickSort(a,l,h):
if(l>=h):
return;
else:
#将数组a[l:h]之间的元素进行划分并重排序
k=divide(a,l,h)
#对划分后的左部分进行递归排序
QuickSort(a,l,k-1)
#对划分后的右部分进行递归排序
QuickSort(a,k+1,h)
if __name__=='__main__':
a=np.array([1,2,4,43,11,456,1982,9,10,167])
#开始排序
QuickSort(a,0,9)
print(a)
归并排序
合并算法
合并算法仅仅是让两个有序序列合并成为一个有序序列,例如将a[0:4]={3 , 8 ,12 , 15, 18},a[5:7]={2 , 5 ,14}合并成一个有序序列b[0:7]=[2,3,5,8,12,14,15,18]。算法实现如下:
C++实现:
/*
created on April 14 2019 15:56
@author:lhy
*/
#include <iostream>
#define N 8
using namespace std;
void Output(int a[]){
for(int i=0;i<N;i++)
cout<<a[i]<<" ";
cout<<"\n";
}
void merge(int a[],int b[],int l,int m,int h){
int i,j,k;
i=l;
j=m+1;
k=l;
while(i<=m&&j<=h){
if(a[i]<a[j]){
b[k]=a[i];
i++;
k++;
}
else{
b[k]=a[j];
j++;
k++;
}
}
while(i<=m){
b[k]=a[i];
k++;
i++;
}
while(j<=h){
b[k]=a[j];
k++;
j++;
}
}
int main()
{
int a[N]={3 , 8 ,12 , 15, 18, 2 , 5 ,14};
int b[N];
merge(a,b,0,4,7);
Output(b);
return 0;
}
因为合并算法仅仅是归并排序的基础,能看懂以上C语言的代码就行,所以合并算法就不用Python再写一遍了。接下来介绍归并排序:
递归归并排序
递归归并排序的思路很简单,就是将无序的序列S[i:j]分成等长的两部分:S[i:m]和S[m+1:j],一般m=(i+j)/2。
然后对S[i,m]和S[m+1,j]分别进行归并排序,然后将其排序结果进行有序合并。由于S[i,m]和S[m+1,t]分解之后的子序列可能仍然是无序的,所以整个过程需要递归执行,直到每个子序列只有一个元素为止,然后进行合并操作。
下面是代码实现:
C++实现:
/*
created on April 14 2019 16:23
@author:lhy
*/
#include <iostream>
#define N 10
using namespace std;
void Output(int* a){
for(int i=0;i<N;i++)
cout<<a[i]<<" ";
cout<<"\n";
}
//合并算法,将a[l:m]和a[m+1:h]合并到b数组上
void Merge(int a[],int b[],int l,int m,int h){
int i,j,k;
i=l;
j=m+1;
k=l;
while(i<=m&&j<=h){
if(a[i]<a[j]){
b[k]=a[i];
k++;
i++;
}
else{
b[k]=a[j];
k++;
j++;
}
}
while(i<=m){
b[k]=a[i];
k++;
i++;
}
while(j<=h){
b[k]=a[j];
k++;
j++;
}
}
void MergeSortByRecu(int Q[],int P[],int s,int t){
cout<<s<<" "<<t<<"\n";
//对a[s:t]进行归并排序,将排序后的记录存入b[s:t]
int T[N]; //T数组来存储归并排序中,中间结果的辅助空间
if(s==t){
P[s]=Q[s];
}
else if(s<t){
int m=(s+t)/2; //将a[s:t]分为a[s:m]和a[m+1:t]
//int temp=m+1;
cout<<"m="<<m<<"s="<<s<<"\n";
MergeSortByRecu(Q,T,s,m);//递归,将a[s:m]归并为有序的T[s:m]
MergeSortByRecu(Q,T,m+1,t);//递归,将a[m+1:t]归并为有序的T[m+1,t]
Merge(T,P,s,m,t); //将T[s:m]和T[m+1:t]的结果归并到P[s:t]
}
}
int main()
{
int a[N]={1,2,4,43,11,456,1982,9,10,167};
//b数组来存储排序后的数组
int b[N];
MergeSortByRecu(a,b,0,N-1);
Output(b);
return 0;
}
Python实现:
'''
created on April 17 11:31 2019
@author:lhy
'''
import numpy as np
def Merge(a,b,l,m,h):
i=l
j=m+1
k=l
while i<=m and j<=h:
if a[i]<a[j]:
b[k]=a[i]
k+=1
i+=1
else:
b[k]=a[j]
k+=1
j+=1
while i<=m:
b[k]=a[i]
k+=1
i+=1
while j<=h:
b[k]=a[j]
k+=1
j+=1
def MergeSort(Q,P,s,t):
T=np.zeros(shape=[10],dtype=int)
if s==t :
P[s]=Q[s]
elif s<t:
m=(int)((s+t)/2)
MergeSort(Q,T,s,m)#将Q[s:m]递归归并成有序的T[s:m]
MergeSort(Q,T,m+1,t)#将Q[m+1:t]递归归并成有序的T[m+1:t]
#开始合并,将T[s:m]和T[m+1:t]合并到P中
Merge(T,P,s,m,t)
if __name__=="__main__":
a=np.array([1,2,4,43,11,456,1982,9,10,167])
b=np.zeros(shape=[10],dtype=int)
MergeSort(a,b,0,9)
print(b)
桶排序
桶排序
基本思路是:
1、将待排序元素划分到不同的痛。先扫描一遍序列求出最大值 maxV 和最小值 minV。
2、设桶的个数为 k ,则把区间 [minV, maxV] 均匀划分成 k 个区间,每个区间就是一个桶。将序列中的元素分配到各自的桶。
3、对每个桶内的元素进行排序。可以选择任意一种排序算法。最后将各个桶中有序序列合并成一个大的有序序列。
时间复杂度分析:
假设数据是均匀分布的,则每个桶的元素平均个数为 n/k 。假设选择用快速排序对每个桶内的元素进行排序,
那么每次排序的时间复杂度为 O(n/klog(n/k)) 。
总的时间复杂度为 O(n)+O(k)O(n/klog(n/k)) = O(n+nlog(n/k)) = O(n+nlogn-nlogk )。
当 k 接近于 n 时,桶排序的时间复杂度就可以金斯认为是 O(n) 的。即桶越多,时间效率就越高,而桶越多,占用的空间就越大。
计数排序
在接触基数排序之前,我们先看一下计数排序,这是一种特殊的桶排序,即当桶的个数取最大( 取maxV-minV+1 )的时候,就变成了计数排序。
计数排序是一种按关键字则组成成分进行排序的方法。这种方法与前面各种排序(除了桶排序,因为使用的就是桶排序)都不同,他不需要对关键字进行比较和记录的移动。
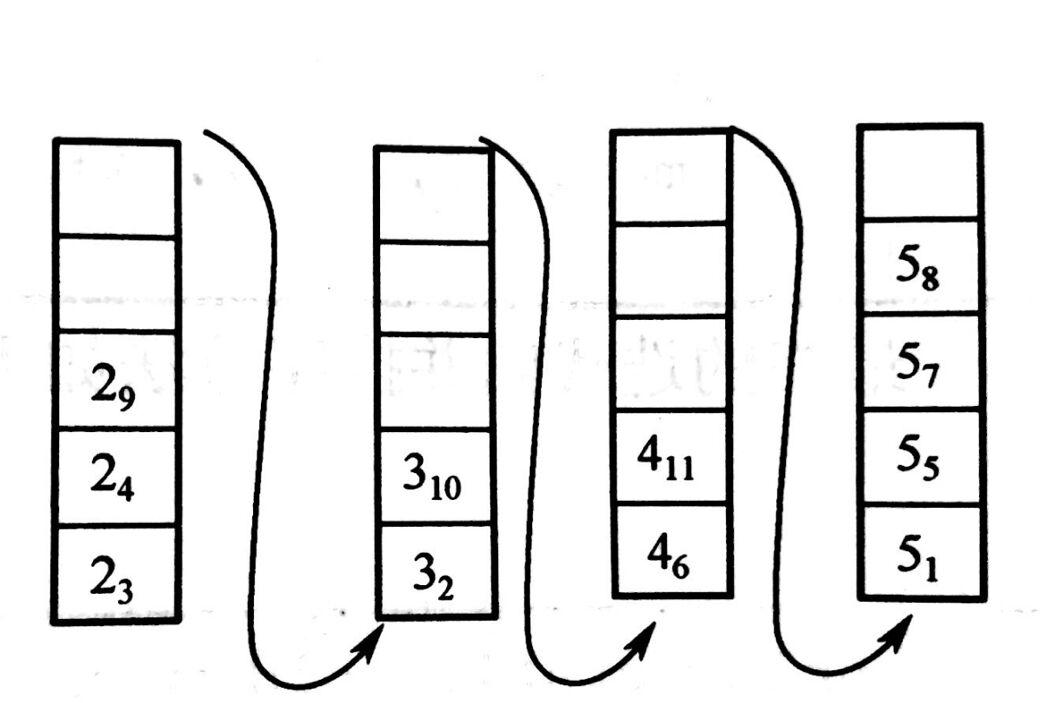
计数排序具体过程如下: 现在有一个数组a={5,3,2,2,5,4,5,5,2,3},通过分析我们可以发现这10个数的取值范围是有上限的,即最小值为2,最大值为5。这样,我们就可以设置6个桶来装这些数据,第一个桶装数值为0的数据的个数,第二个桶装数值为1的数据的个数,第三个桶装数值为2的数据的个数…,第六个桶装数值为5的数据的个数。那么我们可以知道,桶中的数据如下图所示(由于数组中没有0和1,所以就没有画出下标为0和1的桶,直接从下标为2桶的开始):
下面是代码实现:
C++实现:
/*
created on April 17 14:14 2019
@author:lhy
*/
#include <iostream>
#define N 10
using namespace std;
void Output(int* a){
for(int i=0;i<N;i++)
cout<<a[i]<<" ";
cout<<"\n";
}
//获取数组最大值,用来设置桶的上界
int get_max(int* a){
int max_num,i=0;
max_num=a[0];
for(i=0;i<N;i++)
if(a[i]>max_num)
max_num=a[i];
return max_num;
}
int main()
{
int* a=new int[N]{5,3,2,2,5,4,5,5,2,3};
int b[N],num=0;
int top=0;
cout<<"原数组为:";
Output(a);
//获取最大值,也即是桶的上界,创建数组的时候需要上界值加一
top=get_max(a)+1;
//设置0~top的桶,并对桶初始化后赋值
int Bucket[top];
for(int k=0;k<top;k++)
Bucket[k]=0;
for(int j=0;j<N;j++)
for(int i=0;i<top;i++){
if(a[j]==i)
Bucket[i]++;
}
//拿出桶中的数据,放入数组b中,数组b即为排好序的数组
for(int i=0;i<top;i++){
//每个桶的数值就是这个桶下标的值在原数组中的个数
for(int j=0;j<Bucket[i];j++){
b[num]=i;
num++;
}
}
cout<<"排序之后的数组为:";
Output(b);
delete[] a;
return 0;
}
可以看到,虽然这种思想在可以达到时间复杂度为O(n),但是需要使用大量的空间进行辅助排序,比如说桶的内存开辟,所以计数排序在内存管理方面并不占优势。
Python实现:
'''
created on April 17 14:56 2019
@author:lhy
'''
import numpy as np
def get_max(a):
max_num=a[0]
for i in range(a.size):
if a[i]>max_num:
max_num=a[i]
return max_num
if __name__=="__main__":
a=np.array([5,3,2,2,980,4,54,5,2,313])
b=np.zeros(shape=[10],dtype=int)
top=get_max(a)+1
num=0
Bucket=np.zeros(shape=[top],dtype=int)
#初始化桶并对桶赋值
for i in range(a.size):
for j in range(top):
if a[i]==j:
Bucket[j]+=1
#拿出桶中的数据
for i in range(top):
for j in range(Bucket[i]):
b[num]=i
num+=1
print(b)
链式基数排序
链式基数排序是利用计数排序思想进行的排序算法。
举个例子:考虑十进制(基数为10)的数组D,数组D={123,42,453,45,654,76,432,75,3,99}
数组D中关键字最多为3位,不足3位的补0其变成3位,结果如下:
D={123,042,453,045,654,076,432,075,003,099}
下面那我们就用计数排序的思想对D进行排序:
- 由于基数排序的基数是10,所以每一位数字的取值范围应该是0-9
- 对关键字的每一位都使用计数排序(10个桶,编号是0-9)
- 那么我们可以知道,百位数的关键字有三位,应该使用三次计数排序
- 应该先从最低位(个位)开始排序,然后是十位,最后对百位排序,这称为最低位优先。
第一趟计数排序结果(对个位排序):
042, 432, 123, 453, 003, 654,045, 075, 076, 099
第二趟计数排序结果(对十位排序):
003, 123, 432, 042, 045, 453, 654, 075, 076, 099
第三趟计数排序结果(对百位排序):
003, 042 ,045, 075, 076, 099, 123, 432, 453,654
可见第三趟计数排序过后数组已经排序完成。
下面是代码实现:
C++实现:
/*
created on April 17 13:46 2019
@author:lhy
*/
#include <iostream>
#include <stdlib.h>
#define Max 10 //数组个数10
#define Radix 10 //基数为10
#define Keynum 10//关键字个数,这里是整形的位数,int表示的的整形最大有32位,换算成十进制,能表示的最大数字为2147483647,有10位
using namespace std;
void Output(int* a){
for(int i=0;i<Max;i++)
cout<<a[i]<<" ";
cout<<"\n";
}
//找到num的从低到高第pos位的数据
int GetBunInPos(int num,int pos){
int temp=1;
for(int i=0;i<pos-1;i++){
temp*=10;
}
return (num/temp)%10;
}
void RadixSort(int* a,int DataNum){
//创建0-9序列空间,为二维数组
//第一维表示0-9这10个数的桶
//第二维index=0的元素记录的是这组数据的个数,后面是存放的数据
int* radixArray[Radix];
for(int i=0;i<Radix;i++){
//动态开辟二维数组第二维空间
radixArray[i]=(int *)malloc(sizeof(int)*(DataNum+1));
//index为0处记录的是这组数据的个数
radixArray[i][0]=0;
}
//开始排序,对每一位依次操作,先对个位操作即pos=1时开始
for(int pos=1;pos<=Keynum;pos++){
//分配过程
for(int i=0;i<DataNum;i++){
int num=GetBunInPos(a[i],pos);
int index= ++radixArray[num][0];
//将a[i]放在桶radixArray[num]里
radixArray[num][index]=a[i];
}
int j=0;
//收集过程
for(int i=0;i<Radix;i++){
for(int k=1;k<=radixArray[i][0];k++){
a[j++]=radixArray[i][k];
}
radixArray[i][0]=0;//复位,等待下一次使用
}
}
}
int main()
{
int* a=new int[Max]{5,3,2,2,980,4,54,5,2,313};
cout<<"排序前,数组a为:";
Output(a);
RadixSort(a,Max);
cout<<"排序后,数组a为:";
Output(a);
delete[] a;
return 0;
}
Python实现:
'''
created on April 17 17:07 2019
@author:lhy
'''
import numpy as np
Max=10 #数组元素个数
Radix=10 #桶的下标个数为0-9,同时也表达基数是10的意思
Keynum=31 #关键字个数,整形最大有31位
#从num的最低位向高位找第pos位的数据并返回
def GetBunInPos(num,pos):
temp=1
for i in range(pos-1):
temp *=10
return ((int)(num/temp))%10
def RadixSort(a,DataNum):
radixArray=np.zeros(shape=[Radix,DataNum+1],dtype=int)
for i in range(Radix):
radixArray[i][0]=0
#开始排序
for pos in range(1,Keynum+1,1):
for i in range(DataNum):
num=GetBunInPos(a[i],pos)
radixArray[num][0]+=1
index=radixArray[num][0]
radixArray[num][index]=a[i]
j=0
#收集过程
for i in range(Radix):
for k in range(1,radixArray[i][0]+1,1):
a[j]=radixArray[i][k]
j+=1
radixArray[i][0]=0 #复位
if __name__=="__main__":
array=np.array([5,3,2,2,980,4,54,5,2,313])
RadixSort(array,Max)
print(array)
当pos值大于数组中元素最大位数的时候,num为0,换句话讲就是将这个数放在当前操作数为0的桶中,正好符合了上面所讲的当位数不够时在数字前面补上0的原则。
但是不管是桶排序、计数排序或者是基数排序,都只能对整数数组进行操作,所以这个排序算法的使用场景比较有限。
希尔排序
希尔排序是插入排序的一种,也称为缩小增量排序,是直接插入排序的一种改进版本。在直接插入排序中,如果序列是按照升序有序的,则直接插入排序的时间复杂性是O(n)。希尔排序就利用了这一特点,主要的思想是:先将序列进行粗略的分组,使整个序列大致按照升序排列,然后再进行直接插入排序时,时间复杂度就会降低。
因为希尔排序有很多种写法,所以在这里就只介绍一下 希尔排序的主要思想:
- 选取一个正整数a1<n(n为数组长度),然后从第一个元素开始往后,把所有与当前元素下标相隔a1的数组元素放在一起形成子数组,对这些子数组进行直接插入排序,然后取a2<a1,重复上述步骤,每一轮结束后都可以使整个数组更加靠近有序状态;
- 依次选取a3<a2,a4<a3直到ak=1为止,当ak等于1时,就是对整个数组进行直接插入排序。
上面文字没看懂的没关系,下面用一张图来解释会比较明了:

图源:https://www.cnblogs.com/chengxiao/p/6104371.html
需要注意的是,希尔排序是不稳定排序算法。
排序算法时间复杂度对比
O(n^2)
- 插入排序
- 选择排序
- 希尔排序
- 冒泡排序
O(nlogn)
- 快排
- 归并排序
- 堆排序
注:本文没有介绍堆排序,因为堆排序需要引入二叉树的概念,具体思想和实现步骤可参考如下文章:堆排序就这么简单
O(n)
- 桶排序
- 计数排序
- 基数排序
结语
上面就是几种主流排序算法的基本思想还有他们具体实现的代码,可以解决大部分的排序问题。而且其实在写这些代码的时候就可以感觉到,C语言/C++的确在写算法方面比Python好用的多,思路更加明了,写起来也更加顺手。最重要的是,用C++和Python写同样的排序算法情况下,虽然C++使用的代码多,Python使用的代码少,但是C++编译输出速度明显比Python快得多,工程项目中使用C++会大大提高代码的速度,归根到底还是各种语言职能不一样吧。
