本文是继上篇博客的补充,不清楚原文的同学请看这里 关于新型冠状病毒肺炎疫情追踪的可视化数据的采集、处理
最终效果图
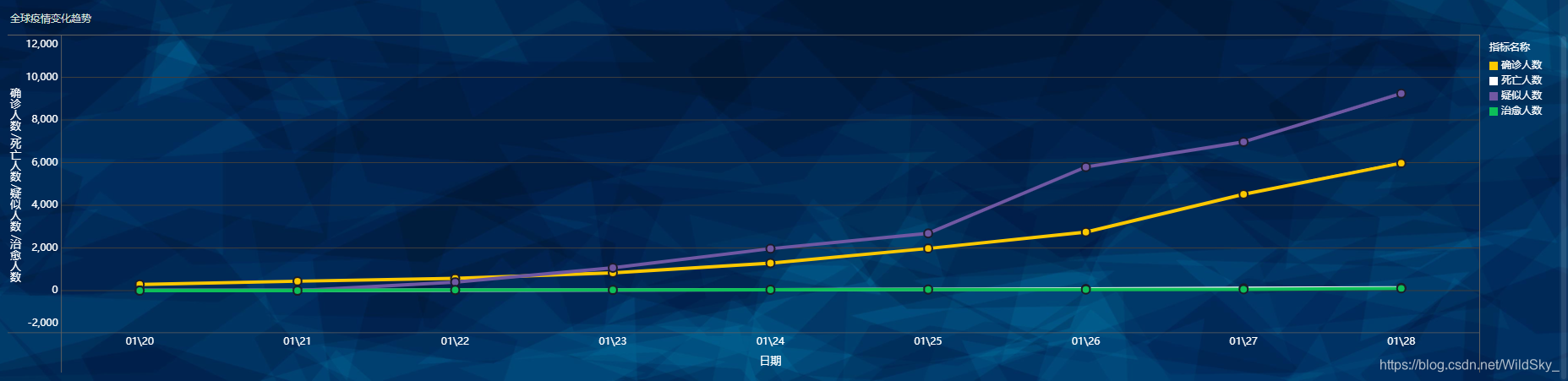
有些细心的小伙伴在看了上篇博客后告诉我,尽管抓取的数据确实不少,但还是遗漏了一个十分重要的数据——每日疫情数据的变化趋势
首先,感谢你们的好心提醒以及对我的鼓励!感谢你们能够赏脸看我的文章!
其实抓取这些数据和上篇博客提到的方法是一样的,看过的小伙伴们就当是重温一遍叭
数据准备:要抓取数据,自然需要找一个具有这样数据的数据源,那就找呗
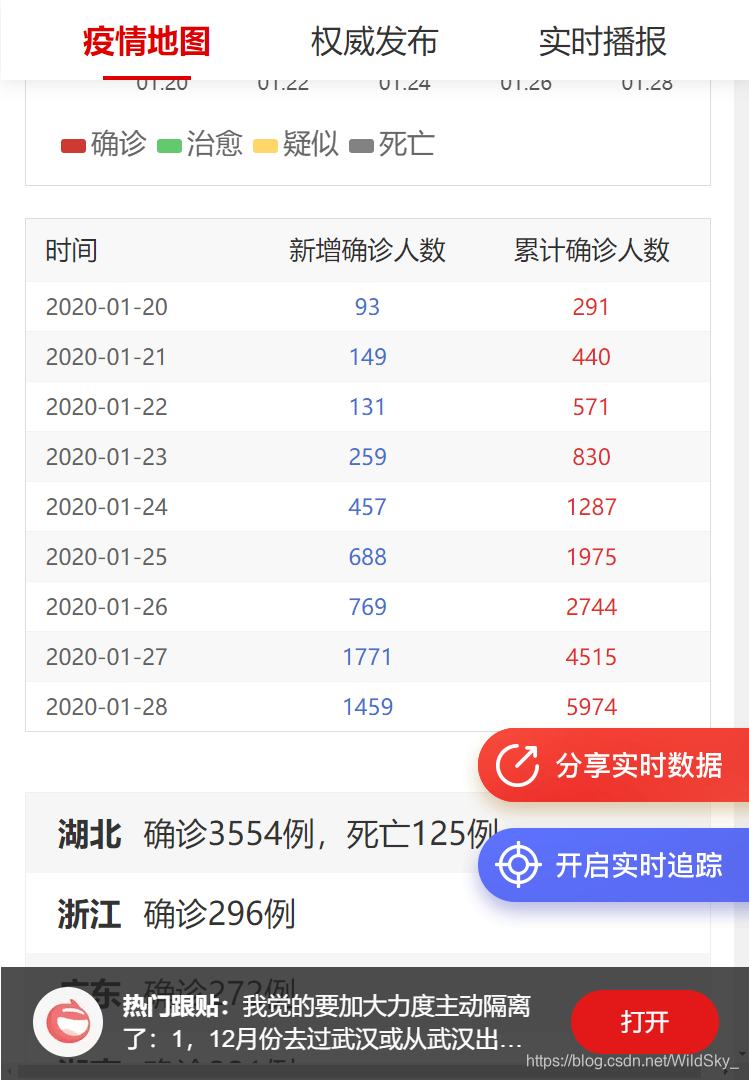
于是发现了网易新闻提供了一个这样的数据源
url:https://news.163.com/special/epidemic/
开干!
数据采集:和上篇一样,使用谷歌浏览器自带的开发者工具进行数据包抓取
采集过程:和上篇一样,打开开发者工具的捕获按钮后,F5刷新查看数据包,搜索对应的数据
如图,我直接搜索第一个数据 93(但是要注意一下“新增确诊人数”,因为你观察一下“累计确诊人数”中的数据后,可以得知“新增确诊人数”是相邻两个“累计确诊人数”的差,如果直接搜“新增确诊人数”的话,可能无法搜索到我们要找的数据包,原因是“新增确诊人数”的数据完全是可以通过计算得出的)
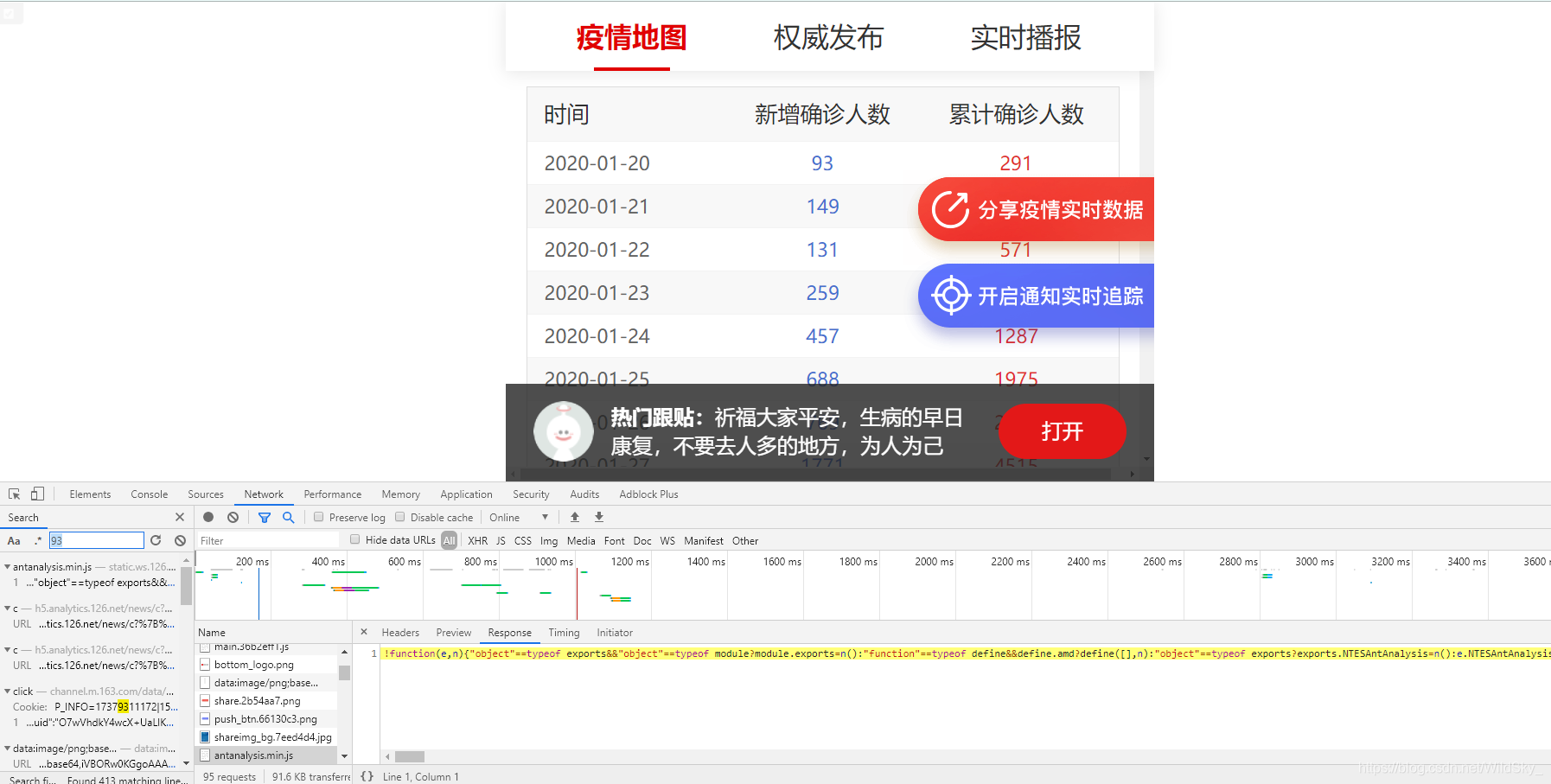
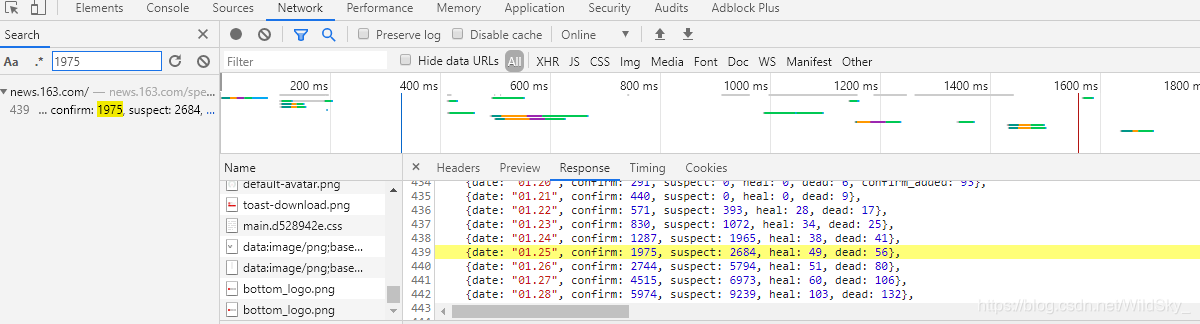
但是在排查这些数据包发现,这些数据包太多了,很难找到。没关系,我们换一个数据,搜索“累计确诊人数”里的数据看看,以1975为例,发现只有一个搜索结果,如图
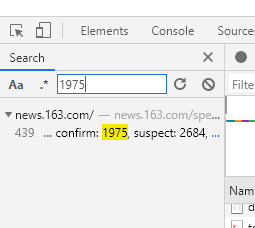
查看其Response可以得知,这正是我们要找的数据包。
刚开始我以为这是条json数据,心想这个json的成员名和之前的成员名都是一样的,可以直接套之前的代码了。可但我瞪大眼睛仔细看了看,这个成员们是没有引号括起来的,顿时一脸懵逼。(本人学识尚浅,还不清楚这个类型是什么,希望懂的小伙伴能够帮助在下,指点一二。)
但是处理这些数据我们可以通过截取字符串的方式将它处理掉。
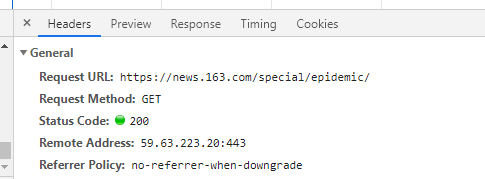
之后我们看其Headers,提交方式为Get,而且凑巧的是,这个URL正是我们的数据源(我们不需要提交任何参数了)
至此,数据采集完毕,进入代码环节。
数据处理:
由于这一次不需要处理json数据,所以我们只需要导入三个模块,然后写出返回Response的函数框架
- requests模块 (用于网页访问)
- re模块 (用于正则表达式,处理数据时需要)
- openpyxl (用于将数据生成excel表格)
import re
import requests
import openpyxl
url=r"https://news.163.com/special/epidemic/"#数据来源 网易
def GetHtmlText(url):
kv = {'user-agent': 'Mozilla/5.0'}#用于修改头部信息,破除其网站对应的反爬虫机制
try:
res=requests.get(url,timeout =30,headers = kv)
res.raise_for_status()
res.encoding=res.apparent_encoding
return res.text
except:
return "Error"
此处的代码与之前有些不同,这里的requests.get()语句接受了一条headers的参数,之所以这样做是因为有一些网站有反爬虫机制的,Python在使用requests爬取资源时,其头部信息headers中为:

其User-Agent字段的信息为python-requests/2.22.0,所以一些反爬虫机制就会通过一信息使你的访问变得错误,导致数据爬取失败。(这就相当于你想要偷别人家东西时,向别人大喊我是小偷,不抓你抓谁)这时我们就可以通过修改User-Agent字段的信息将自己伪装起来,其中Mozilla/5.0是一个标准的浏览器身份标识字段。(小偷:“我是良民啊!”,于是主人将信将疑的让你溜了)
但网易新闻并未设置这样的机制,写这个只是因为最近学到了这个知识,一方面是让自己巩固知识,一方面也是想顺便提醒大家。
继续我们的代码
由于不清楚之前那个类似于json的数据是什么,不知道如何解析,所以我只想到了一个笨方法,用提取中间文本的方式,提取出这些数据。函数如下:
def GetTextCenter(Text,TextLeft,TextRight):#取出中间文本
L = Text.find(TextLeft) + len(TextLeft)
Text = Text[L:]
R = Text.find(TextRight)
return Text[:R]
原理:Python对字符串的find操作,可以找出需要查找字符的索引位置,而字符串是可以索引值来进行截取的,我们利用这些知识,就可以实现提取中间文本了
开始我们的字符串数据处理环节
首先利用之前我们定义的函数框架来Get一下我们的URL,将其获取的信息打印出来。
Html=GetHtmlText(url)
print(Html)
找到我们需要的数据
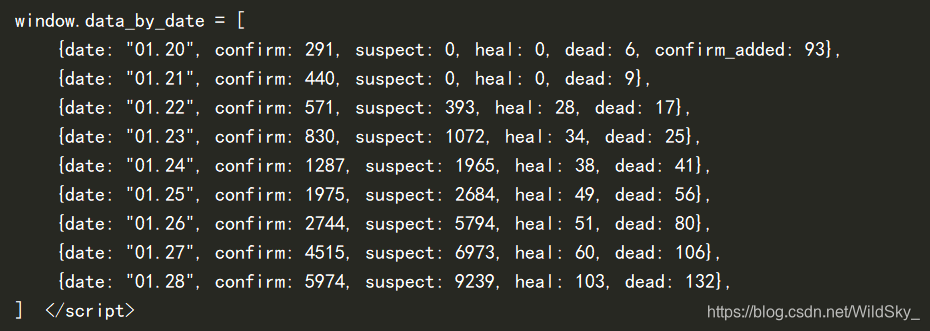
先把中括号中的内容提取出来,这样我们就可以利用我们定义的GetTextCenter函数来获取初步我们需要的信息了。
Html_data=GetTextCenter(Html,r"window.data_by_date = [",r","+"\n"+r"]")
然后我们print一下Html_data,看其数据
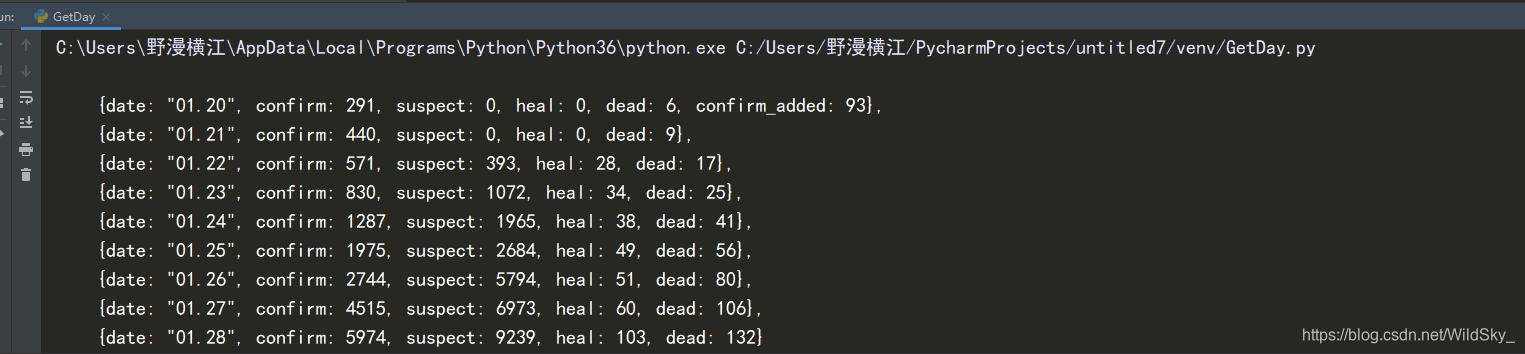
(看到这个我真想把data,confirm等全都加一个双引号)
虽然它不是json数据,但是我们也可以一样先用正则提取出每一条花括号的内容
Data_list=re.findall(r"{[^}]+}",Html_data)
数据即将处理完成,我们还需要处理一点小细节,你看这个confirm_added: 93,显然,这是第一个日期增加的数据,之后的每个日期,应该都是利用其他数据相减得出的结果。(印证了之前的猜想),现在我们要做的工作是将这个confirm_added: 93连同它之前的逗号都删去。
我们不妨定义一个函数,找到这个这个与众不同的字符串列表所在的位置,就直接命名为找不同吧
def Find_Different(list):
for i in range(0,len(list)):
n = list[i].find(r", confirm_added")
if (n != -1):
return [i,n]#由于需要返回两个数据,所以在此返回一个列表,i表示列表的索引,n表示出现该字符串的首位置
然后根据这个位置,将其多余的部分截取掉。
value = Find_Different(Data_list)
Data_list[value[0]] = Data_list[value[0]][:value[1]] + "}" #截取字符串
接着我们遍历一遍Data_list,看看有没有变化
for each in Data_list:
print(each)
可见已经成功了

接下来的工作就是将这些字段的数据提取出来了
这里可以像之前一样,直接声明列表来储存数据,也可以像这样,用一个类来储存
class item:
def __init__(self):
self.data=list()
self.confirm=list()
self.suspect=list()
self.heal=list()
self.dead=list()
Data_Box = item()
for i in range(0,len(Data_list)):#将数据提取出来
Data_Box.data.append(GetTextCenter(Data_list[i],r'{date: "',r'",'))#获取日期
Data_Box.confirm.append(GetTextCenter(Data_list[i],r"confirm: ",r", "))#获取确诊人数
Data_Box.suspect.append(GetTextCenter(Data_list[i],r"suspect: ",r", "))#获取疑似人数
Data_Box.heal.append(GetTextCenter(Data_list[i],r"heal: ",r", "))#获取治愈人数
Data_Box.dead.append(GetTextCenter(Data_list[i],r"dead: ",r"}"))#获取死亡人数
最后,将数据保存至Excel中
for i in range(0,len(Data_list)):
ws.cell(i + 2, 1, Data_Box.data[i].replace(".","\\"))
ws.cell(i + 2, 2, int(Data_Box.confirm[i]))
ws.cell(i + 2, 3, int(Data_Box.suspect[i]))
ws.cell(i + 2, 4, int(Data_Box.heal[i]))
ws.cell(i + 2, 5, int(Data_Box.dead[i]))
wb.save("date_data.xlsx")
至此,数据处理阶段结束
将数据可视化
由于在上一篇博客中,有说明如何将数据导入FineBI可视化平台中,所以本次跳过这些步骤,直接以创建折线图为例。
准备工作
- 导入刚刚生成的Excel数据
- 新建一个仪表板
- 添加组件
- 在“我的自助数据集”中选中刚刚导入的Excel数据后,点击确定
创建折线图
首先我们将“日期”拖入横轴
然后点击“确诊”、“死亡”、“疑似”、“治愈”后,将其拖入纵轴
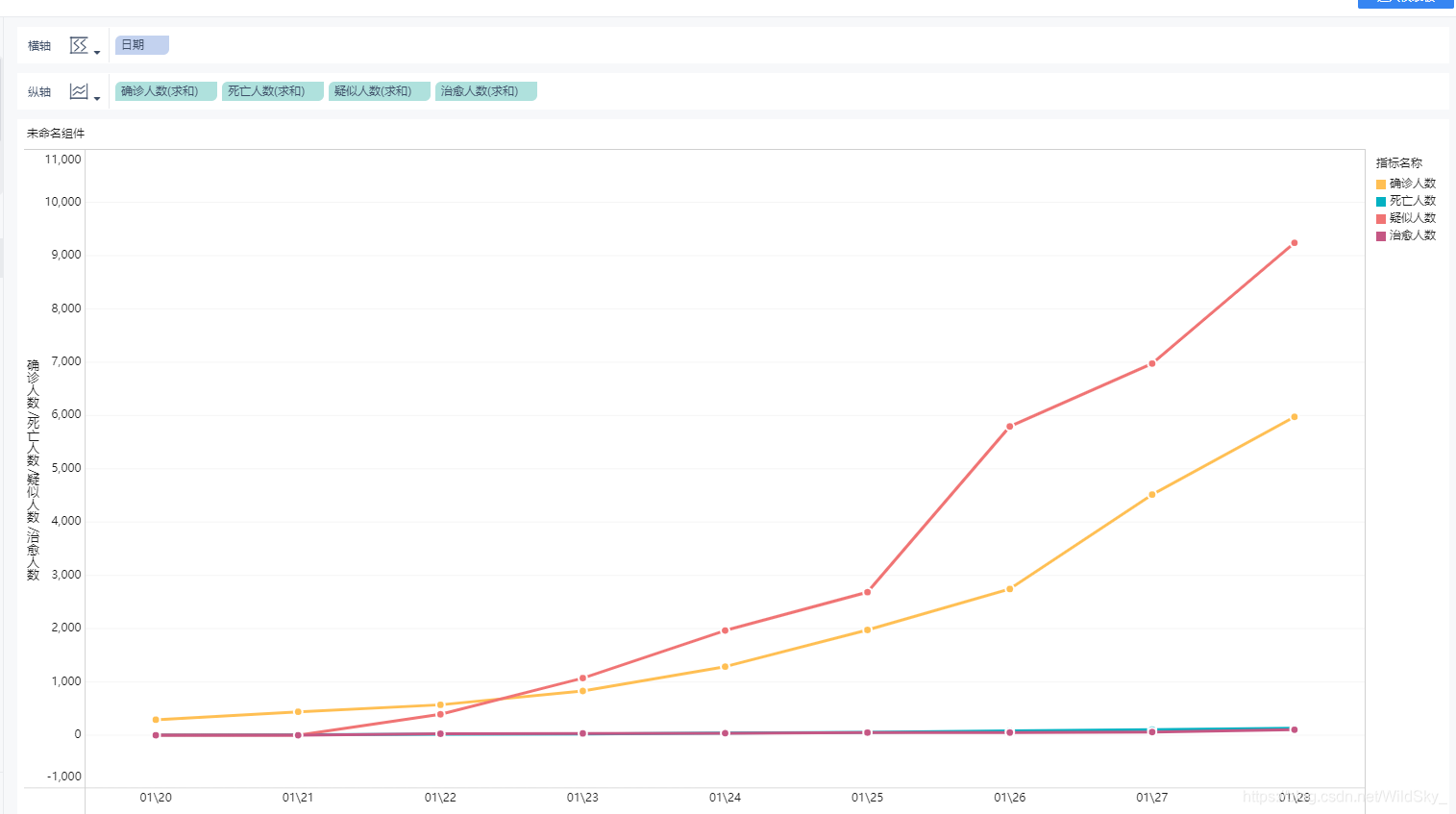
可以看到图表类型中,多系列折线图区域已经亮起

选中它
折线图出现了
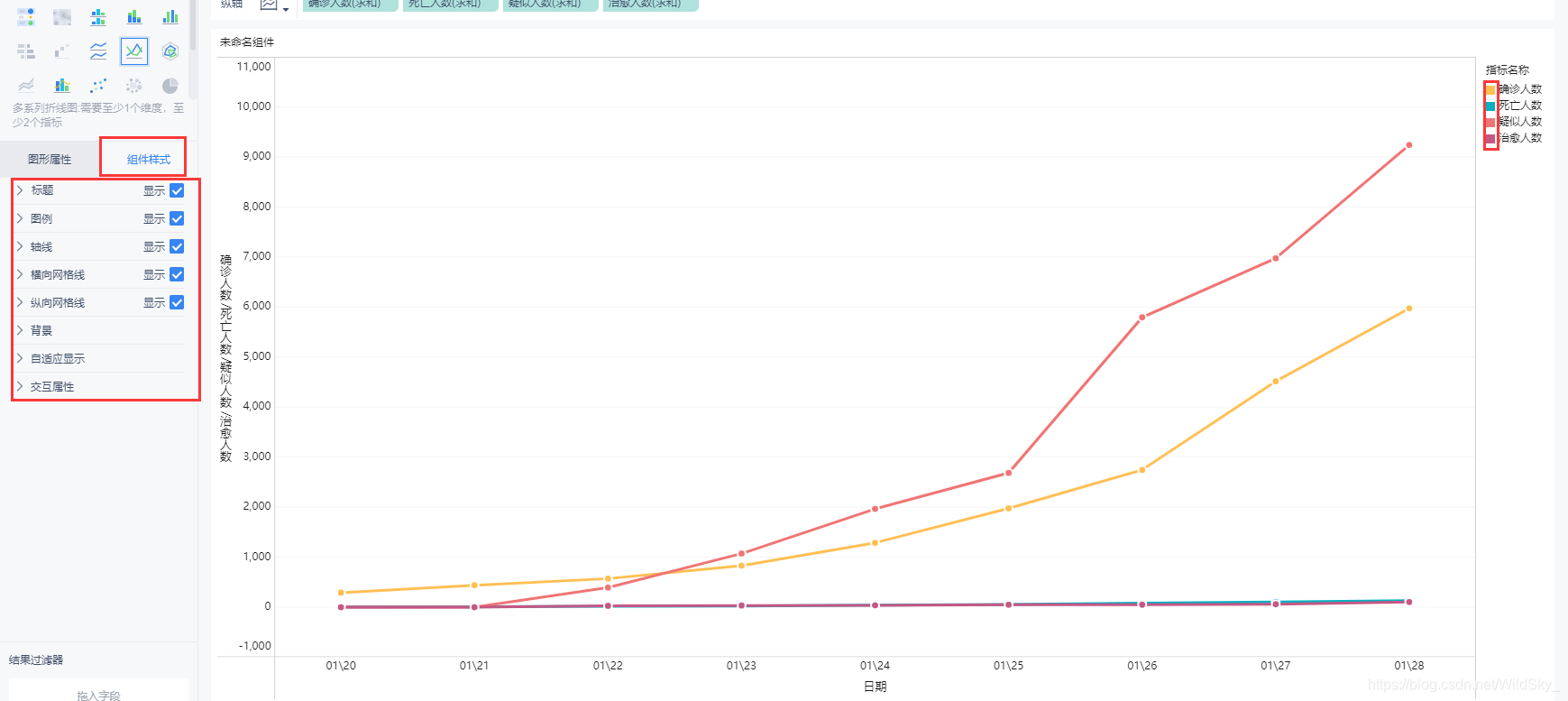
至此,折线图已经制作完毕,你可能还有一些个性化处理的需求,这可以自己去探索,具体细节不再详述,这里给出设置个性化的方式,左侧可以调整其说明上的内容,点击右侧的框中的小方块可以调整其折线图中线的颜色
Python代码
import re
import requests
import openpyxl
url = r"https://news.163.com/special/epidemic/"#数据来源 网易
def GetHtmlText(url):
kv = {'user-agent': 'Mozilla/5.0'}#用于修改头部信息,破除其网站对应的反爬虫机制
try:
res=requests.get(url,timeout =30,headers = kv)
res.raise_for_status()
res.encoding=res.apparent_encoding
return res.text
except:
return "Error"
def GetTextCenter(Text,TextLeft,TextRight):#取出中间文本
L = Text.find(TextLeft) + len(TextLeft)
Text = Text[L:]
R = Text.find(TextRight)
return Text[:R]
Html=GetHtmlText(url)
Html_data=GetTextCenter(Html,r"window.data_by_date = [",r","+"\n"+r"]")
Data_list=re.findall(r"{[^}]+}",Html_data)
def Find_Different(list):
for i in range(0,len(list)):
n = list[i].find(r", confirm_added")
if (n != -1):
return [i,n]#由于需要返回两个数据,所以在此返回一个列表,i表示列表的索引,n表示出现该字符串的首位置
value = Find_Different(Data_list)
Data_list[value[0]]=Data_list[value[0]][:value[1]]+"}"#截取字符串
for each in Data_list:
print(each)
class item:
def __init__(self):
self.data=list()
self.confirm=list()
self.suspect=list()
self.heal=list()
self.dead=list()
Data_Box=item()
for i in range(0,len(Data_list)):#将数据提取出来
Data_Box.data.append(GetTextCenter(Data_list[i],r'{date: "',r'",'))#获取日期
Data_Box.confirm.append(GetTextCenter(Data_list[i],r"confirm: ",r", "))#获取确诊人数
Data_Box.suspect.append(GetTextCenter(Data_list[i],r"suspect: ",r", "))#获取疑似人数
Data_Box.heal.append(GetTextCenter(Data_list[i],r"heal: ",r", "))#获取治愈人数
Data_Box.dead.append(GetTextCenter(Data_list[i],r"dead: ",r"}"))#获取死亡人数
#数据Excel化
wb = openpyxl.Workbook()#建立Excel工作簿
ws = wb.active#获取工作表
ws.cell(1,1,"日期")
ws.cell(1,2,"确诊人数")
ws.cell(1,3,"疑似人数")
ws.cell(1,4,"治愈人数")
ws.cell(1,5,"死亡人数")
for i in range(0,len(Data_list)):
ws.cell(i + 2, 1, Data_Box.data[i].replace(".","\\"))
ws.cell(i + 2, 2, int(Data_Box.confirm[i]))
ws.cell(i + 2, 3, int(Data_Box.suspect[i]))
ws.cell(i + 2, 4, int(Data_Box.heal[i]))
ws.cell(i + 2, 5, int(Data_Box.dead[i]))
wb.save("date_data.xlsx")
