资源Bilibili AV46914471 + AV57921488
汇编语言与计算机系统结构 清华大学 张悠慧
本次笔记内容:
01.汇编语言与计算机系统结构
02.汇编基础知识——指令集综述
文章目录
课程前言
机器语言、汇编语言、高级语言
汇编语言是机器语言、高级语言中间的过渡。
汇编语言大致可以看成,机器语言的助记符。
- 机器语言:依赖于机器的低级语言,书写格式为二进制代码。
-
- 优点:执行速度快,效率高;
-
- 缺点:表达的意义不直观,编写、阅读、调试较困准。
- 汇编语言:是一种符号语言,与机器语言一一对应;它使用助记符表示相应的操作,并遵循一定的语法规则。
-
- 优点:面向机器编程,在“时间”和“空间”上效率高;
-
- 缺点:涉及硬件细节,要求熟悉计算机系统的內部结构。
- 高级语言:面向人的语言,表达形式接近自然语言。
-
- 优点:便于阅读,易学易用,不涉及硬件,具有通用性;
-
- 缺点:目标代码冗长,占用内存多,从而执行时间长,效率不高,不能对某些硬件进行操作。
计算机系统结构
计算机系统结构(中国计算机科学技术百科全书的定义):
- 计算机系统的物理或者硬件结构、各部分组成的属性以及这些部分的相互联系;
- 系统软件开发人员看到的计算机系统的功能行为和概念结构;
- 计算机系统的结构与实现(计算机组成)。
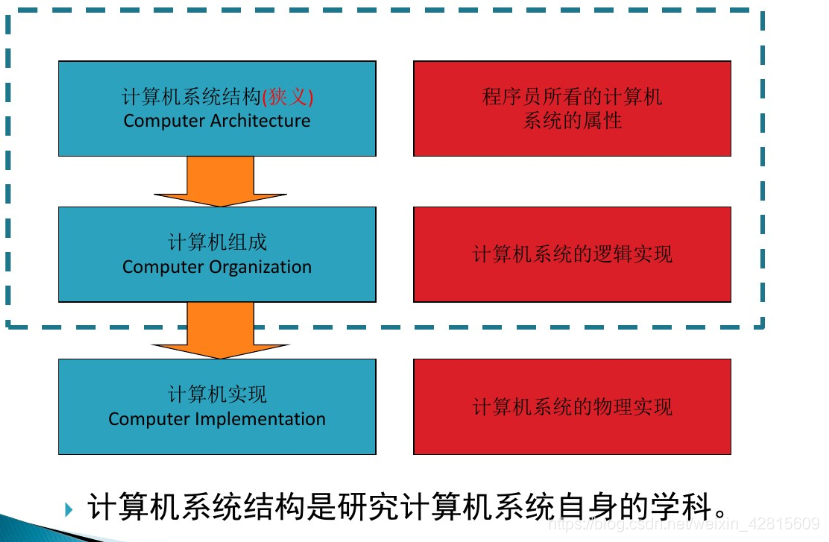
- 计算机系统结构(Computer Architecture,计算机属性的狭义定义):程序员所看的计算机系统的属性;
- 计算机组成(Computer Organization):计算机系统的逻辑实现;
- 计算机实现(Computer Implementation):计算机系统的物理实现。
指令系统(表现为汇编语言)
- 计算机处理器对外提供的接口与规格;
- 软硬件的分界;
- 系统程序员看到的计算机的主要属性。
指令系统的分类
CISC(复杂指令系统,,Complex Set Instruction Compute)
- 面向高级语言,缩小机器指令系统与高级语言语义差距;
- 指令条数多,寻址方式多变;
- 单条指令能够完成多个操作;
- 代表:X86
后来,工程师倾向于把指令简化,具体任务交给上层语言组织,而指令系统要精简。
RISG(精简指令系统,Reduced Instruction Set Computer)
- 通常只支持常用的能在一个周期内完成的操作(80:20原则);
- 简单而统一格式的指令格式与译码;
- 只有LOAD和 STORE指令可以访问存储器,简单的寻址方式;
- 较多的寄存器:
- 指令条数相对较少,依赖于编译器产生高效的代码;
- 处理器体系结构相对简单,运行频率高;
- 代表:MIPS / ARM / PowerPC
各指令集(系统)的具体描述
之后,CISC与RISC走向融合。
- X86处理器内部采用类似RISC的micro-op(出于兼容性考虑,其指令集一直属于CISC)
- 经典的RISC指令集也日益扩展、复杂化(Powerpc指令集(RISC)有超过230多条指令,较许多CISC指令集更为复杂)
MIPS是一个经典的RISC指令集,兼具RISC设计的简洁优雅与不足:
- 代码密度较低;
- 应用于嵌入式领域,32bit指令有些“大材小用”;
- 因此注重扩展,包括提高代码密度(16位指令)以及多媒体、加密领域的指令扩展。
ARM指令集介于经典的RISC与CISC之间,相对复杂:
- 注重代码密度,降低功耗;
- 浮点较弱,逐步扩展强化。
课程定位
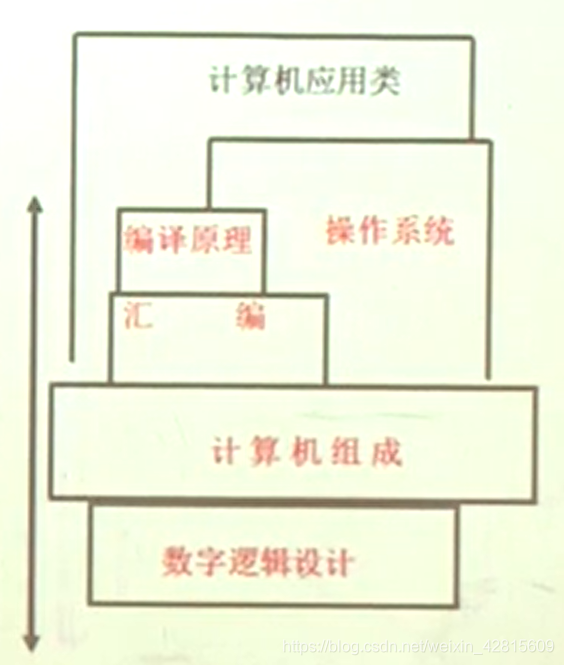
如上图,汇编在软硬件界面起到“承上启下”的作用。
基本知识:
- 各类指令集初步;
- 数制与整数表示;
- 浮点数表示。
X86汇编:
- 80x86计算机组织与保护模式;
- X86指令系统与寻址方式;
- C与X86汇编;
- X86汇编语言程序格式与基本编程。
MIPS汇编:
- MIPS计算机组织初步;
- 指令系统介绍;
- 汇编代码与异常处理。
学习目标与要求
- 了解汇编语言与计算机系统结构的关系及其起到的作用;
- 了解以X86系列微处理器为基础的PC机的编程结构,建立起“机器”与“程序”、“时间”与“空间”的概念;
- 基本掌握X86系列微处理器的指令系统及寻址方式,能够编写程序;
- 掌握C语言基本代码段与汇编语言的对应关系;
- 掌握MIPS指令集的指令类型,初步了解对应的系统结构;
- 掌握使用简单的MIPS指令实现复杂指令的方法;
- 初步了解MIPS指令集在操作系统中的作用。
参考书
- 《深入理解计算机系统》( Computer Systems: A Programmers Perspective),第二版,2010。
- 第2、3章;
- 课程ppt的部分素材也来源于该书作者的课程网站。
- SEE MIPS RUN(MIPS体系结构透视),第二版,2008;
- IBM-PC汇编语言程序设计(第2版),沈美明,温冬婵编著,清华大学出版社。
x86指令集
x86指令集的基本特色
- 向下兼容(商业上的考虑);
- 变长指令:1-15字节,多数为2-3字节长度;
- 多种寻址方式(可以访问不对齐内存地址);
- 指令集的通用寄存器个数有限(x86-32系统下拥有8个通用寄存器,x86-64扩展到16个);
x86-32/64 General Purpose Registers

如上图,左侧白色底,e开头的通用寄存器(共8个),是32位x86系统所能使用的寄存器,其中%esp还是需要在特殊情况下使用的。
之后,扩展到64位,则新增了左侧紫色底的8个寄存器(r开头),即一共有16个寄存器可用。
右侧%r8到%r15表示新增的8个寄存器的助记符,并且,可用以32位的形式访问,方式为%r8d到%r15d。
x86指令类型
数据传输指令(在存贮器和寄存器、寄存器和输入输出端口之间传送数据):
- 通用数据传送指令:MOV、PUSH、POP、XCHG;
- 累加器专用传送指令:IN、OUT、XLAT;
- 地址传送指令:LEA、LDS、LES;
- 标志寄存器传送指令:LAHF、SAHF、 PUSHE、POPF;
- 类型转换指令:BW、CWD。
算数指令:
- 加法指令:ADD、ADC、INC;
- 减法指令:SUB、SBB、DEC、NEG、CMP;
- 乘法指令:MUL、IMUL;
- 除法指令:DIV、IDIV;
- 十进制调整指令:DAA、DAS、AAA、AAS、AAM、AAD。
逻辑指令:
- 逻辑运算指令:AND、OR、NOT、XOR、TEST;
- 移位指令:SHL、SHR、SAL、SAR、ROL、ROR、RCL、RCR。
串处理指令(不要求掌握):
- 设置方向标志指令:CLD、STD;
- 串处理指令;
- 串重复前缀。
控制转移指令:
- 无条件转移指令:JMP;
- 条件转移指令:JZ/JNZ、JE/JNE、JS/JNS、JO/JNO、JP/JNP、JB/JNB、JL/JNL、JBE/JNBE、JLE/JNLE、JCXZ;
- 循环指令:LOOP、 LOOPZ、LOOPE、 LOOPNZ 、LOOPNE;
- 子程序调用和返回指令:CALL、RET;
- 中断与中断返回指令:INT、INTO、IRET。
处理机控制与杂项操作指令:
- 标志处理指令:CLC、STC、CMC、CLD、STD、CL、STI;
- 其他处理机控制与杂项操作指令:NOP、HLT、WAIT、ESC、LOCK。
x86浮点指令与SIMD
基于浮点寄存器,SIMD概念的引出
专用的浮点寄存器(最初为80-bit internal registers,后宽度逐步扩展)
- IEEE Standard 754 (Established in 1985 as uniform standard for floating point arithmetic)
- Extended precision: 15 exp bits, 63 frac bits
| s | exp | frac |
|---|
- 早先的x86中浮点寄存器是一个基于栈的结构(现在不是栈了,RSC处理器中的浮点寄存器一般可使用寄存器号直接得址,并且寄存器个数较多)
- STO ~ ST7
SIMD(Single Instruction Multi-DATA)
-单指令、多数据指令,使得多个运算可以在同一条指令内并发进行(向量运算),结构距离如下。
| 此为一个64位指令,存储一个数据 | |||
|---|---|---|---|
| 可以视为2个32位,或4个16位指令 | |||
| 16 | 16 | 16 | 16 |
- 通常其复用浮点寄存器,如128-bit的寄存器可以同时存放2或4个浮点数(64 or 32 bits wide respectively);或者是2,4,8或16个整数,同时进行相同运算;
- 充分利用应用的数据并发性;
- 较新的 Intel Sandy Bridge架构拥有了256-bit的SIMD指令(including 256-bit memory load and store)。
- SIMD位宽的加大的一个前提条件是访问内存指令的数据宽度的增大:但是SIMD的应用效率取決于两个方面,一是处理器的IO带宽 (处理器发展瓶颈:肚子大,嘴巴小) ;二是应用自身的特性能否提供充分的数据并发性。
SIMD技术发展
MMX
较早的MMX(1997, Intel)主要应用于多媒体处理:
- MMX“增加”了8个寄存器(MMO-MM7)
- 实际上,其复用了现有的浮点寄存器(ST0-ST7),但是寻址方式不同(寄存器号直接寻址);
- 任一个MMX寄存器的宽度是64bit,使用了 packed datatypes (two 32-bit integers(doubleword), four 16-bit integers (word) or eight 8-bit integers)。
- MMX的缺点:
-
- 只支持整数运算,浮点数运算仍然要使用传统浮点指令;
-
- 与浮点寄存器相互重叠,这限制了MMX指令在需要大量浮点运算的程序,如三维几何变换、裁剪和投影中的应用;
- 堆栈式暂存器结构,使得硬件上将其流水线化和软件上合理调度指令都很困难,这成为提高x86架构浮点性能的一个瓶颈。
3DNOW! (AMD)
- K6-2处理器是第一个能执行浮点SIMD指令的x86处理器;
- SIMD多媒体指令集,支持单精度浮点数的向量运算。
SSE(Streaming SIMD Extensions)
- SSE彻底抛弃了传统的堆栈式浮点处理器结构;
- 8个独立的128位寄存器(XMM0 - XMM7),64位结构下增至16个。
- SSE-1:同时处理4个32位单精度浮点数;
- SSE-2:增加了对于2×64位浮点或者整数、4×32位整数、8×16位整数、16×8位整数的支持。
Intel Sandy Bridge架构引入了 Advanced Vector Extensions指令集扩展
- SIMD寄存器宽度增至256位,16个寄存器(YMMO-YMM15)
-
- 向下兼容SSE;
-
- 每个周期可以进行两个256-bit的AVX操作;
- 引入了三操作数的指令;
- Sandy Bridge架构支持256位的内存访问接口;
2013年7月推出最新的AVX-512(512位)。
为何x86指令集长久不衰?
- 商业上的成功是其主要原因(生态环境);
- 技术上注重向下兼容:一个反例是Itanium(IA-64,Explicitly Parallel Instruction Computing),技术创新但无法兼容,前景不被看好。
x86指令集的缺点
- 向下兼容导致指令集越来越大、越复杂;
- 类RISC内核,采用 micro-op模式进行翻译,使得功耗相对增大,这导致其在注重低功耗的嵌入式领域不占优势;
- 对很多领域而言,资源利用率低(在高性能计算领城,300余条x86指今中,大致只有80余条是核科学计算所需要的)
MIPS指令集
是经典的RISC指令集(主要应用于嵌入式领域):MIPS I、 MIPS II、 MIPS II、 MIPS IV到 MIPS V,嵌入式指令体系MIPS 16、MIPS 32到MIPS 64的发展已经十分成熟。
为充分利用处理器的流水线结构,其设计思想是使得各个指令的流水线分段较为均匀:
- 分段一致,每段的操作时延相差不多,从而提高主频;
- 尽量使得能够每一周期完成一条指令,控制相对简单。
尽量利用软件办法避免流水线中的数据相关/控制相关问题,实例:Delay Slot。
MIPS 32
- 以寄存器为中心(32个),只有Load/ Store指令访问内存,所有的计算类型的指令均从寄存器堆中读取数据并把结果写入寄存器堆中。
- MIPS 32还定义了32个浮点寄存器。
- MPS 32指令集的指令格式非常规整,所有的指令长度一定,而且指令操作码在固定的位置上。
- MIPS指令的寻址方式非常简单,每条指令的操作也较简单。
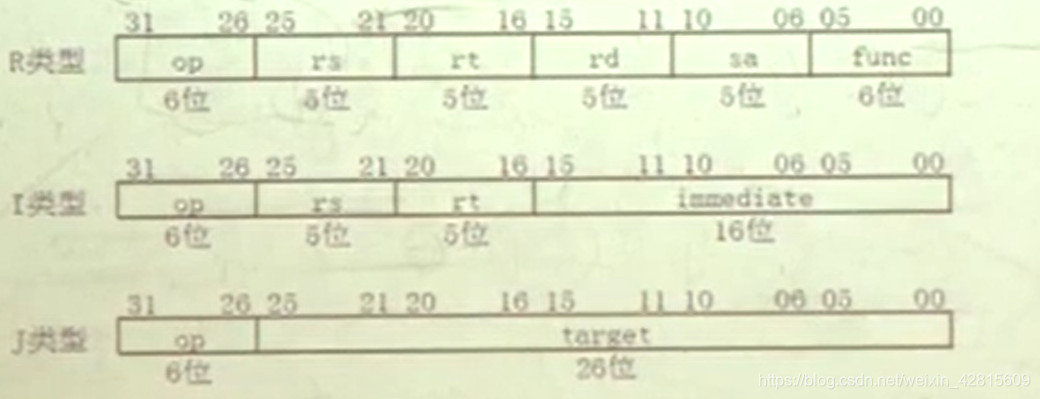
MIPS 32 TM 的指令格式只有3种
- R(register)类型的指令从寄存器堆中读取两个源操作数,计算结果写回寄存器堆;
- l(immediate)类型的指令使用一个16位的立即数作为源操作数;
- J(jump)类型的指令使用一个26位立即数作为跳转的目标地址(target address)。
Load / Store
- Load和Store指令都为立即数(l-type)类型,用来在存储器和通用寄存器之间的储存和装载数据。MIPS指令集只有该类指令访问内存,而其他指令都在寄存器之间进行,所以指令的执行速度较高。
- 该类指令只有基址寄存器的值加上扩展的16位有符号立即数一种寻址模式,数据的存取方式可以是字节(byte)、字(word)和双字(double word)。
MIPS扩展指令集
MIPS-3,浮点SIMD用于三维几何处理(MIPS 64架构下)
- Vertex transformation (matrix multiplication)
- Clip-check(compare and branch)
- Transform to screen coordinates (perspective division using reciprocal)
- Lighting: infinite and local (normalization using reciprocal square root)
采用MIPS 64浮点运算单元和双单精度数据类型。
- PS(paired- single, 双单精度)操作可对64位寄存器中的两个32位浮点值进行运算,从而提供2路SIMD(单指令多数据)能力。
除此之外,还有MIPS 16e等扩展指令集。
MIPS小结
MIPS是一个经典的RISC指令集,兼具RISC设计的简洁优雅与不足:
- 代码密度较低;
- 应用于嵌入式领域,32 bit指令有些“大材小用”;
- 因此注重扩展,包括提高代码密度(16位指令)以及多媒体、加密领域的指令扩展。
ARM指令集
ARM是有些不同的RISC指令集(32位)
- ARM指令提供简单的操作,使一个周期就可以执行一条指令。编译器或者程序员通过几条简单指令的组合来实现一个复杂的操作;
- ARM指令集大多数指令采用相同的字节长度,并且在字边界上对齐,字段位置固定,特别是操作码的位置。
- ARM处理器使用Load/ Store的存储模式,其中只有Load和Store指令才能从内存中读取数据到寄存器,所有其他指令只对寄存器中的操作数进行计算(ARM有16个32位寄存器,x86是8个,MIPS 32是32个)。
与MIPS相比,寻址相对复杂
- 立即数寻址:每个立即数都是采用一个8位的常数循环右移偶数位间接得到;
- 寄存器导址:ADD R3, R2, RI, LSR#2,即寄存器R1的内容右移了两位,但是注意本指令执行完毕以后R1的内容并不改变。
- 前变址,自动变址和后变址
-
- 前变址:LDR R0 , [R1, #4],R1寄存器的内容先加4,然后执行操作,但操作完毕以后,R1的内容不变。
-
- 自动变址R1寄存器的内容先加4,然后执行操作,,R1变化;
-
- 后变址:LDR R0, [R1], #4,先进行操作,然后R1+4->R1,操作完毕后,R1=R1+4。
- 堆栈寻址;
- 多寄存器寻址。
多数指令支持条件执行
- A 4-bit condition code selector,而多数处理器只有跳转指令有条件码判断;
- 这一设计的优势在于对于简单的if-else语句,无需产生跳转指令,劣势在于减少了“立即数”域的位数。
while(i != j) {
if(i > j)
i -= j;
else
j -= i;
}
转换为ARM指令集的汇编语言即:
loop CMP Ri, Rj ; set condition "NE" if(i != j),
; "GT" if(i > j)
; or "LT" if(i < j)
SUBGT Ri, Ri, Rj; if "GT" (greater than), i = i-j;
SUBLT Rj, Rj, Ri; if "LT (less than), j = j-i;
BNE loop ; if "NE"(not equal), then loop
其他特性(一般RISC指令集所不具具备)
- PC-relative addressing(PC:program counter,即,可以相对PC寻址);
- 融合数据处理功能(数据移动、算术计算)与移位(shifts与rotates)功能。
ARM的Thumb指令集
- Thumb指令可以看做是ARM指令压缩形式的子集,为提高代码度而引入的;
- 必须与ARM指令集混用;
- 主要区别:
-
- 除了跳转指令有条件执行功能外,其它指令均为无条件执行;
-
- 没有乘加指令及64位乘法指令等,且指令的第二操作数受到限制。
The shorter opcodes give improved code density overall, even though some operations require extra instructions. Instructions where the memory port or bus width is constrained to less than 32 bits, the shorter Thumb opcodes allow increased performance compared with 32-bit ARM code, as less program code may need to be loaded into the processor over the constrained memory bandwidth.
浮点运算的扩展
- ARM的浮点运算能力不是强项,某些ARM内核只支持软件浮点指令模拟;
- VFP:
-
- single-precision and double-precision floating-point computation;
- 但是对于SIMD的支持不好;
- NEON:
-
- 64/128位的SIMD浮点指令集(相当于Intel的SSE);
-
- 采用独立的寄存器堆与硬件流水线;
-
- 支持8-, 16-, 32- and 位整数与单精度(32-bit)浮点数据与计算。
ARM小结
ARM指令集介于经典的RISC与CISC间,相对复杂,注重代码密度,降低功耗;浮点较多,逐步扩展强化。
指令集对比小结
- CISC与RISC指令集互为借鉴,走向融合;
- 兼容性考虑是指令集发展的关键性因素;
- 为提高数据井行度,SIMD扩展是指令集发展的一个共性:
-
- 但是取决于处理器访问存储的宽度以及应用的特性;
-
- 充分利用SIMD是一个非常困难的事!
顶会HPCA一篇文章引发的思考
Power Struggles: Revisiting the RISC vs . CISC Debate on Contemporary ARM and x86 Architectures
In the 19th IEEE International Symposium on High Performance Computer Architecture ( HPCA 2013)
Question:
- The question of whether ISA(Instruction Set Architecture,指令集架构) plays an intrinsic role in performance or energy efficiency is becoming important. We seek to answer this question through a detailed measurement based study on real hardware running real applications.
Answer:
- We find that ARM and x86 processors are simply engineering design points optimized for different levels of performance, and there is nothing fundamentally more energy efficient in one ISA class or the other. The ISA being RISC or CISC seems irrelevant.
