修改字体样式
Font(name=字体名称,size=字体大小, bold=是否加粗,italic=是否斜体,color=字体颜色)
import os
os.chdir('D:\\python_major\\auto_office8')
from openpyxl.styles import Font
from openpyxl import load_workbook
workbook = load_workbook(filename = '这是一个表格.xlsx')
sheet = workbook.active
cell = sheet['A1']
font = Font(name = '思源黑体 Regular',size = 12,bold=True,italic = True,color = 'FF0000' )
cell.font = font
workbook.save(filename='这是一个表格.xlsx')
–> 输出结果为:

获取表格中字体的样式
cell.font.属性
from openpyxl import load_workbook
workbook = load_workbook(filename = '这是一个表格.xlsx')
sheet = workbook.active
cell = sheet['A2']
font = cell.font
print(font.name, font.size, font.bold, font.italic)
–> 输出结果为: 等线 11.0 False False
设置对齐样式
Alignment(horizontal=水平对齐模式,vertical=垂直对齐模式,text_rotation=旋转角度,wrap_text=是否自动换行)
关于水平样式和垂直样式具体的设置,可以通过参数配置进行修改
from openpyxl import load_workbook
from openpyxl.styles import Alignment
workbook = load_workbook(filename = '这是一个表格.xlsx')
sheet = workbook.active
cell = sheet['A1']
alignment = Alignment(horizontal='center',vertical='center',text_rotation=45 )
cell.alignment = alignment
workbook.save(filename='这是一个表格.xlsx')
–> 输出结果为:
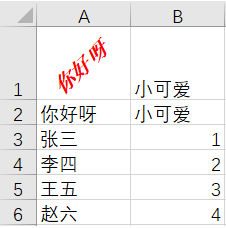
设置边框样式
Side(style=边线样式,color=边线颜色)
Border(left=左边线样式,right=右边线样式,top=上边线样式,bottom=下边线样式)
关于边线样式的设置,可以通过参数配置进行修改
from openpyxl.styles import Border,Side
from openpyxl import load_workbook
workbook = load_workbook(filename = '这是一个表格.xlsx')
sheet = workbook.active
cell = sheet['A3']
side = Side(style='thin',color='FF000000')
border = Border(left=side,right=side,top=side,bottom=side)
cell.border = border
workbook.save(filename='这是一个表格.xlsx')
–> 输出结果为:
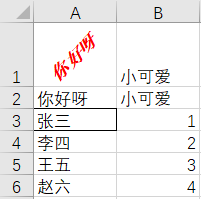
填充
PatternFill(fill_type=填充样式, fgColor=填充颜色)
GradientFill(stop=(渐变颜色1,渐变颜色2,…))
from openpyxl.styles import PatternFill,GradientFill
from openpyxl import load_workbook
workbook = load_workbook(filename = '这是一个表格.xlsx')
sheet = workbook.active
cell_3 = sheet['A3']
pattern_fill = PatternFill(fill_type='solid',fgColor='99ccff')
cell_3.fill = pattern_fill
cell_4 = sheet['A4']
gradient_fill = GradientFill(stop=('FFFFFF','99CCFF','000000'))
cell_4.fill = gradient_fill
workbook.save(filename='这是一个表格.xlsx')
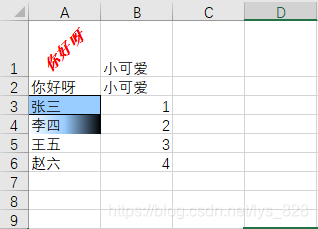
–> 输出结果为:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wFK461fL-1579518034651)(0D87DD8DF52D46A5B2FC7B47C6163A2D)]](https://img-blog.csdnimg.cn/20200120190222348.png)
设置行高和列宽
.row_dimensions[行编号].height = 行高
.column_dimensions[列编号].width = 列宽
workbook = load_workbook(filename = '这是一个表格.xlsx')
sheet = workbook.active
sheet.row_dimensions[1].height = 50
sheet.column_dimensions['B'].width = 20
workbook.save(filename='这是一个表格.xlsx')
–> 输出结果为:
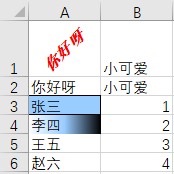
合并单元格
.merge_cells(待合并的格子编号)
.merge_cells(start_row=起始行号,start_column=起始列号,end_row=结束行号,end_column=结束列号)
workbook = load_workbook(filename = '这是一个表格.xlsx')
sheet = workbook.active
sheet.merge_cells('C1:D2')
sheet.merge_cells(start_row=7,start_column=1,end_row=8,end_column=4)
workbook.save(filename='这是一个表格.xlsx')
–> 输出结果为:
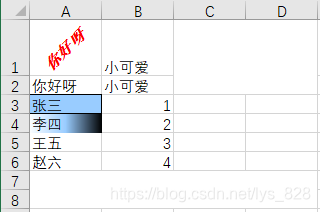
取消合并单元格
.unmerge_cells(待合并的格子编号)
.unmerge_cells(start_row=起始行号,start_column=起始列号,end_row=结束行号,end_column=结束列号)
workbook = load_workbook(filename = '这是一个表格.xlsx')
sheet = workbook.active
sheet.unmerge_cells('C1:D2')
sheet.unmerge_cells(start_row=7,start_column=1,end_row=8,end_column=4)
workbook.save(filename='这是一个表格.xlsx')
–> 输出结果为:
综合应用
编写一个python程序,要求
(1)打开文件阿里云天池电商婴儿用户数据.xlsx
(2)找到day在2014年以后,buy_mount中大于5的数据
(3)将其他数据删除,最后不要在中间留空行
(4)将buy_mount中大于10的数据背景标为红色,字体标为白色
(5)保存该Excel文件
分析发现,这个综合应用和自动化办公(7)中的综合应用类似,只是多加了一个筛选条件(day中找到2014年之后的数据,也就是不包含2014年的),然后对满足要求的单元格,进行样式的修改。关于第三个要求,做数据分析工作,不建议删减原始数据,我的做法就是把满足要求的数据全部存储在另外一个Excel文件中,中间不留空行,当然也可以直接将其他数据删除,但是要重新排一下位置,保证满足要求。
参考示例代码如下:
第一步:准备工作
import os
os.chdir('D:\\python_major\\auto_office8')
from openpyxl import Workbook
from openpyxl import load_workbook
from openpyxl.styles import Font
from openpyxl.styles import PatternFill
workbook = load_workbook(filename = '阿里云天池电商婴儿用户数据.xlsx')
sheet = workbook.active
workbook_1 = Workbook()
sheet_1 = workbook_1.active
该部分代码完成的工作是:设置程序运行路径,加载相关的库、数据文件的加载以及新文件表单的创建
第二步 找到满足要求数据的行列表
步骤分解一:加载办公自动化(7)中已经封装好的函数
def return_col_or_row(content):
'''函数功能:根据输入的content,
筛选出窗格中含有这个content的所有的col(列)和row(行)
返回两个的列表,第一个是所在列的数据,第二个是所在行的数据
'''
data_size = sheet.dimensions
size_ls = data_size.split(":")
col_min,row_min,col_max,row_max = size_ls[0][0],size_ls[0][1],size_ls[1][0],size_ls[1][1:]
row_ls = []
col_ls = []
for col in range(ord(col_min),ord(col_max)+1):
for row in range(int(row_min), int(row_max)+1):
if sheet[chr(col)+str(row)].value == content:
col_content = chr(col)
row_content = str(row)
col_ls.append(col_content)
row_ls.append(row_content)
return(col_ls,row_ls)
步骤分解二:调用函数,找到题目中要求的数据的列,并获取该列中所有的元素
col_by_mount = return_col_or_row('buy_mount')[0][0]
col_year = return_col_or_row('day')[0][0]
data_col_bymount = sheet[col_by_mount]
data_col_year = sheet[col_year]
步骤分解三:按照题目要求进行满足条件的数据筛选,这一部分需要注意,这两列的数据中,单元格的数据类型并不全是整型(还有空值和字符创类型),所以在筛选时,首先判断数值是不是整型,然后在进行大小的比较
data_finial_row = []
for i in range(len(data_col_year)):
if isinstance(data_col_year[i].value, int) and int(str(data_col_year[i].value)[:4]) >2014 and isinstance(data_col_bymount[i].value, int) and data_col_bymount[i].value >5:
print('buy_mount的数值为{},对应的时间日期是{}'.format(data_col_bymount[i].value,data_col_year[i].value))
data_finial_row.append(data_col_year[i].row)
print('\n筛选后满足要求的数据行列表输出为:{}\n'.format(data_finial_row))
至此,所有满足要求的行列表就输出出来了,下一步就是删除其他的数据,尽量不留空行,或者将这些目标数据转移到新文件中,顺序排列并保存,这这两种的操作最后的结果是一样的,由于办公自动化(7)已经实现了数据转移,这里直接将代码搬过来就行了,而且做数据工作要尽量保证原数据的不动,我推荐是使用后者的方法处理数据
第三步:将数据转移到新的Excel文件中
data_finial_row.insert(0,1)
#这一步的目的是将原来文件的标签写到新文件中去
j = 1
for row in data_finial_row:
for col in range(ord('A'),ord('G')+1):
#print(sheet[chr(col)+str(row)].value)
sheet_1[chr(col)+str(j)] = sheet[chr(col)+str(row)].value
print('正在写入第{}行数据'.format(j),end = ' ')
j += 1
print('\n\n数据已全部导入新Excel文件!下面给数据做标记......\n')
该部分很容易忽视的就是第一行代码,因为转移数据的时候,标签肯定不满足要求,但是为了产看数据方便,标签又必须要有,所以把数据转入新的Excel文件之前,要把原数据的标签先转移过来,第一行代码就是为了这个目的
第四步:将满足要求的数据做标记
data_after_buy_mount = sheet_1[return_col_or_row('buy_mount')[0][0]]
for cell in data_after_buy_mount:
if isinstance(cell.value,int) and cell.value >10:
#第一行是标签所以要过滤掉标签
#print(cell.value)
cell.fill = PatternFill(fill_type='solid',fgColor='FF0000')
cell.font = Font(color='FFFFFF')
print('数据标记完成')
workbook_1.save(filename='筛选数据后的表格.xlsx')
print('\ncompleted!')
由于第一行引入了标签,所以在进行单元格数值遍历的时候第一行就是str,这时候就需要滤过这个数据类型,只看整型的数据,因此在进行判断时候要先排除不是整型的数据,再进行数值大小的比较
综合应用的全部代码以及输出结果
import os
os.chdir('D:\\python_major\\auto_office8')
from openpyxl import Workbook
from openpyxl import load_workbook
from openpyxl.styles import Font
from openpyxl.styles import PatternFill
workbook = load_workbook(filename = '阿里云天池电商婴儿用户数据.xlsx')
sheet = workbook.active
workbook_1 = Workbook()
sheet_1 = workbook_1.active
def return_col_or_row(content):
'''函数功能:根据输入的content,
筛选出窗格中含有这个content的所有的col(列)和row(行)
返回两个的列表,第一个是所在列的数据,第二个是所在行的数据
'''
data_size = sheet.dimensions
size_ls = data_size.split(":")
col_min,row_min,col_max,row_max = size_ls[0][0],size_ls[0][1],size_ls[1][0],size_ls[1][1:]
row_ls = []
col_ls = []
for col in range(ord(col_min),ord(col_max)+1):
for row in range(int(row_min), int(row_max)+1):
if sheet[chr(col)+str(row)].value == content:
col_content = chr(col)
row_content = str(row)
col_ls.append(col_content)
row_ls.append(row_content)
return(col_ls,row_ls)
col_by_mount = return_col_or_row('buy_mount')[0][0]
col_year = return_col_or_row('day')[0][0]
data_col_bymount = sheet[col_by_mount]
data_col_year = sheet[col_year]
data_finial_row = []
for i in range(len(data_col_year)):
if isinstance(data_col_year[i].value, int) and int(str(data_col_year[i].value)[:4]) >2014 and isinstance(data_col_bymount[i].value, int) and data_col_bymount[i].value >5:
print('buy_mount的数值为{},对应的时间日期是{}'.format(data_col_bymount[i].value,data_col_year[i].value))
data_finial_row.append(data_col_year[i].row)
print('\n筛选后满足要求的数据行列表输出为:{}\n'.format(data_finial_row))
data_finial_row.insert(0,1)#这一步的目的是将原来文件的标签写到新文件中去
j = 1
for row in data_finial_row:
for col in range(ord('A'),ord('G')+1):
#print(sheet[chr(col)+str(row)].value)
sheet_1[chr(col)+str(j)] = sheet[chr(col)+str(row)].value
print('正在写入第{}行数据'.format(j),end = ' ')
j += 1
print('\n\n数据已全部导入新Excel文件!下面给数据做标记......\n')
data_after_buy_mount = sheet_1[return_col_or_row('buy_mount')[0][0]]
for cell in data_after_buy_mount:
if isinstance(cell.value,int) and cell.value >10:
#第一行是标签所以要过滤掉标签
#print(cell.value)
cell.fill = PatternFill(fill_type='solid',fgColor='FF0000')
cell.font = Font(color='FFFFFF')
print('数据标记完成')
workbook_1.save(filename='筛选数据后的表格.xlsx')
print('\ncompleted!')
–> 输出结果为:
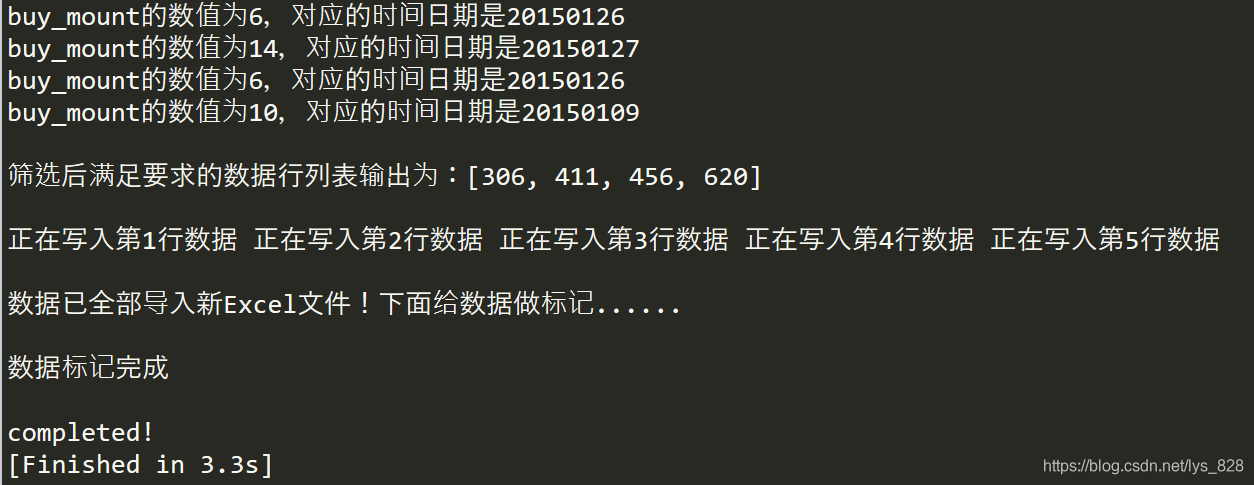
新Excel的数据为:

