文章目录
并发与并行
- 并发:同时发生,轮流处理
假设,我们电脑只有一个CPU,同时只能处理一个线程,我们开机后运行的QQ,浏览器,还有众多系统服务,这些软件和服务只能轮流去调用则这个CPU,这种情况就属于并发(但因为每个软件只需要几毫秒甚至更少的时间就能执行完成,所以这时候我们并不会感觉到有明显卡顿等状况。)
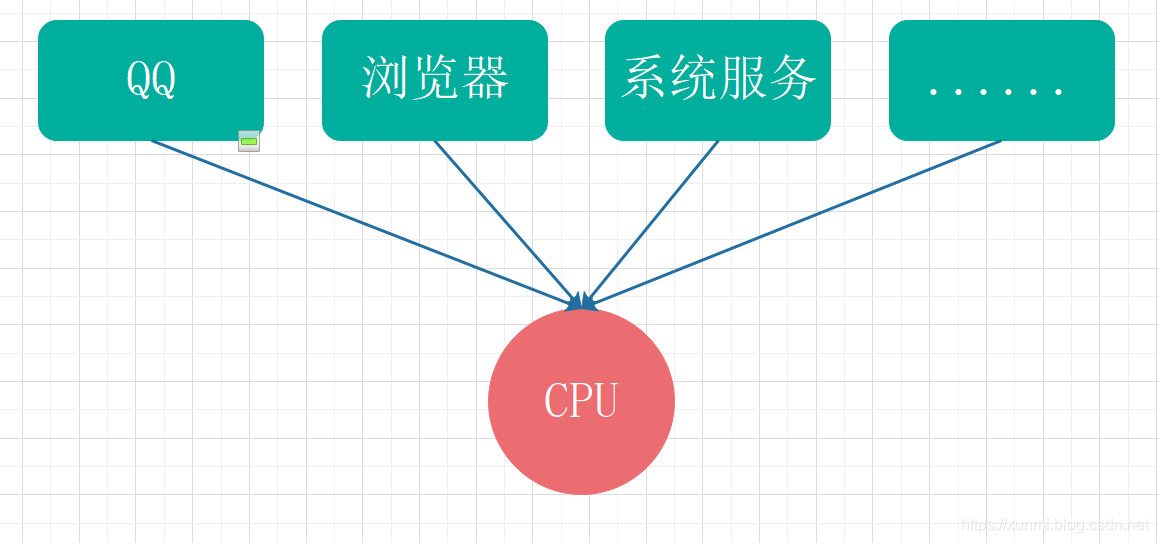
- 并行:同时发生,同时处理
假设,当电脑中有多个CPU时,QQ和浏览器在不同的CPU中运行,这种情况就属于并行。(但电脑中因为会同时运行大量服务和软件,所以并发的情况比并行要更加普遍。)
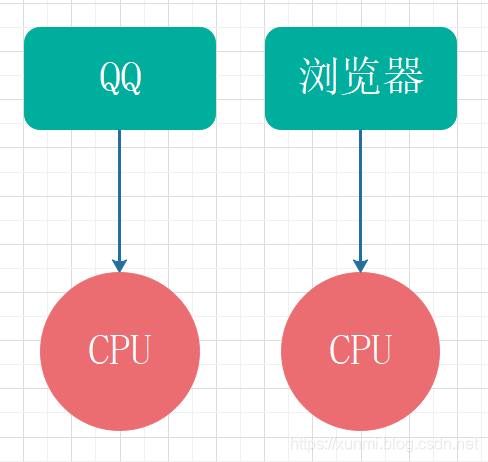
线程与进程
-
线程: 任务调度和执行的基本单位
- 假设打开QQ,同一个QQ中,同时打开众多聊天窗口,而这每个窗口都是一个线程。而QQ是一个进程。线程要依附于进程存在,同进程内切换线程消耗资源少,切同一进程内的所以线程都使用同一份共享资源。

- 假设打开QQ,同一个QQ中,同时打开众多聊天窗口,而这每个窗口都是一个线程。而QQ是一个进程。线程要依附于进程存在,同进程内切换线程消耗资源少,切同一进程内的所以线程都使用同一份共享资源。
-
进程: 操作系统资源分配的基本单位
- 假设打开QQ音乐与网易云音乐,这两个程序就是启动后分别称为两个进程,而在这两个进程真我们同时进行音乐播放和下载,这两个功能分别为这两个进程中的两个线程。我们可以看出进程中进行通信成本要高于线程,且进程切换的成本较高,但进程的优势是能更好的利用多处理器。
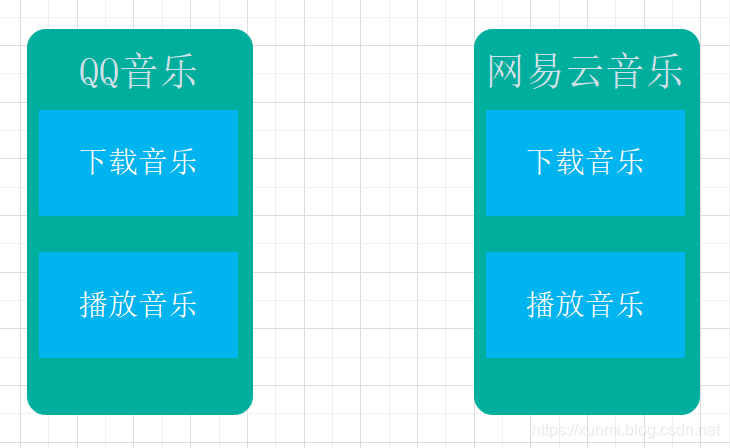
- 假设打开QQ音乐与网易云音乐,这两个程序就是启动后分别称为两个进程,而在这两个进程真我们同时进行音乐播放和下载,这两个功能分别为这两个进程中的两个线程。我们可以看出进程中进行通信成本要高于线程,且进程切换的成本较高,但进程的优势是能更好的利用多处理器。
同步、异步与阻塞、非阻塞
- 同步: 当存在IO操作时,必须等到IO操作结束才能在进行下一步操作(如:当程序碰到用户输入时必须等待用户输入)
- 异步: 当存在IO操作时,程序不必等到IO操作也能继续运行。(如当程序碰到用户输入时,不必等待用户输入)
- 阻塞: 当程序在运行时被卡住.导致程序不再继续向下运行,需要等待,即为阻塞
- 非阻塞: 程序运行没有卡住,持续运行,无需等待,即为非阻塞
Python的多线程与多进程
因为Python的GIL(globalinterpreterlock,全局解释锁)的存在,在一个程序内只能同时运行一个进程,所以我们可以将Python的多线程理解为一个人同时干多个事与多个人同时干多个事情的区别。(GIL是CPython的一个特性,虽然限制了Python的性能,Python社区也尝试过去掉GIL,但GIL的主要作用是为了一个资源同时只会被一个线程占用,这样不仅让共享资源变得更加可信,同时也让死锁不会再Python的多线程中发生)
Python使用多线程时,内部资源是共享的;而多进程之间资源是不共享的,不过我们可以通过进程之间的通信来解决这个问题。
Python多线程
同一个程序如何在同时能运行多个功能模块?比如在通信的时候,我们如何做到在一遍监视通信端口时候收到信息,一边去发送信息?这时候就需要用到多线程,Python中的内置库中就包含多线程库threading。threading官方库文档
创建函数多线程
首先我们要用到threading库中的.Thread()方法,并且方法中需要用到关键字参数传入需要创建的函数目标参数target=
.Thread()方法中的参数顺序分别为group=None, target=None, name=None, args=(), kwargs=None, *, daemon=None
Thread()方法的参数 |
作用 |
|---|---|
| group | 预留参数,当前无作用。 |
| target | 指定需要执行的函数。(官方点的解释是用run()方法调用的对象) |
| name | 线程名称。默认名称为(Thread-N,N是创建的第几个线程) |
| args与kwargs | 作用相似,都是传入指定函数所带的参数 ,不同的是args是位置传参,kwargs是关键字传参。传入的参数会成为全局共享参数。 |
| daemon | 守护进程,默认关闭(False),包括主线程的守护进程默认也为关闭的非守护线程。 |
众所周知,程序员时间紧张,所以我们就来用Thread来解决一遍吃饭一遍敲码的需求吧。
# 多线程
import threading
import time
# 创建多线程的函数
def eat():
for i in range(3):
print('我在吃饭')
time.sleep(1)
def code():
for i in range(3):
print('我在敲码')
time.sleep(1)
if __name__ == '__main__':
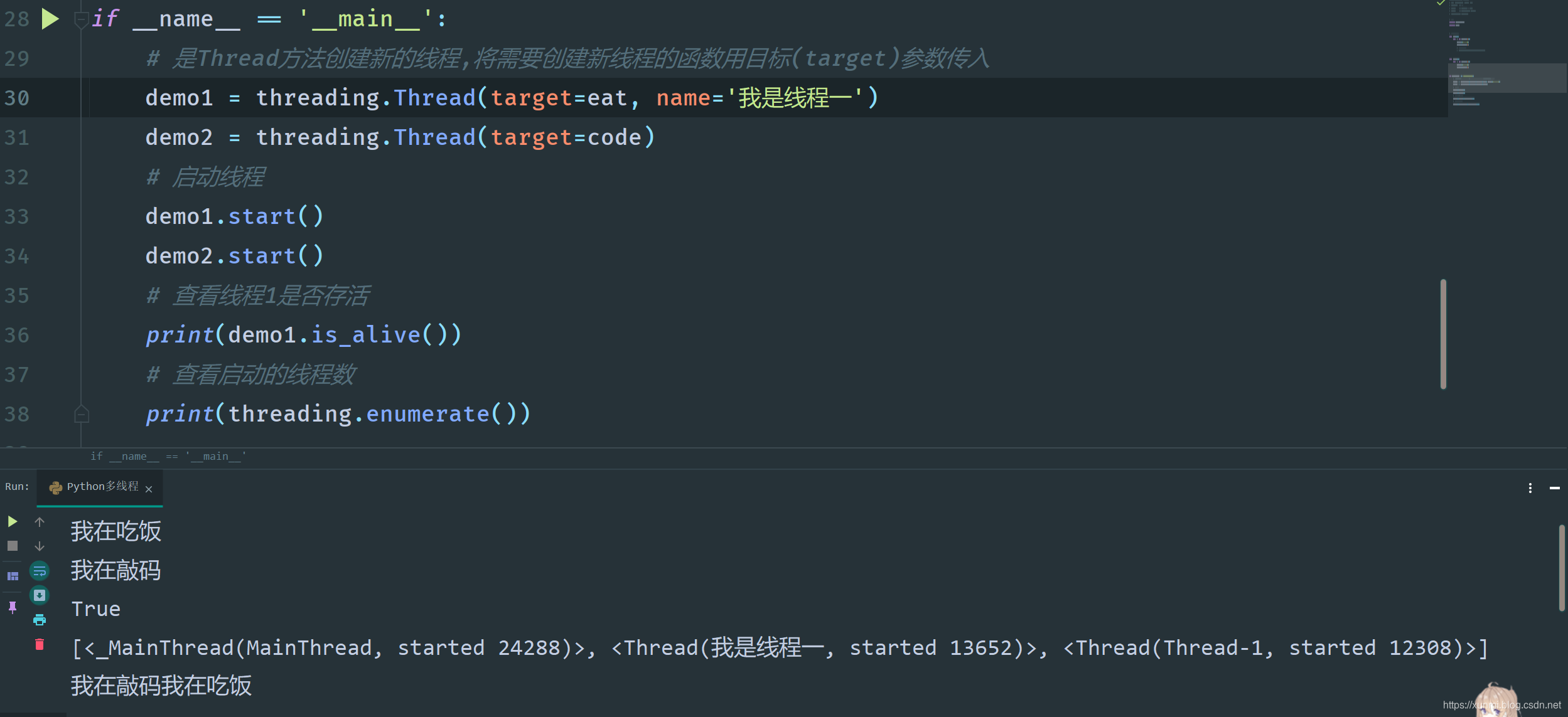
# 是Thread方法创建新的线程,将需要创建新线程的函数用目标(target)参数传入
demo1 = threading.Thread(target=eat)
demo2 = threading.Thread(target=code)
demo1.start()
demo2.start()
在使用Thread()方法创建好线程后,我们需要使用srart()方法开始线程活动。
线程被srart()启动后,Python就会在一个独立的新线程中调用run()方法(我们传入的函数就在此方法中),线程启动后被判定为’存活的’线程,当线程正常或因为异常退出时,线程就不在是’存活的’。
查看线程
- 使用
.is_alive()方法可以查看指定线程当前是否存活。 - 使用
.enumerate()方法可以查看当前一共有哪些存活线程。
可以使用.Tread()方法的name参数给线程指定名称
# 查看线程1是否存活
print(demo1.is_alive())
# 查看启动的线程数
print(threading.enumerate())
用继承方式创建多线程类
上述我们多次提到.run()方法,在继承中我们就能更完整的看到他的实际意义。
class ThreadDemo(threading.Thread):
def __init__(self, name='自定义线程'):
super().__init__()
# 自动定义一个线程名字
self.name = name
def run(self):
for i in range(5):
print('我在run方法中', i)
time.sleep(1)
if __name__ == '__main__':
# 继承多线程类
demo = ThreadDemo('测试')
demo.start()
print(threading.enumerate())
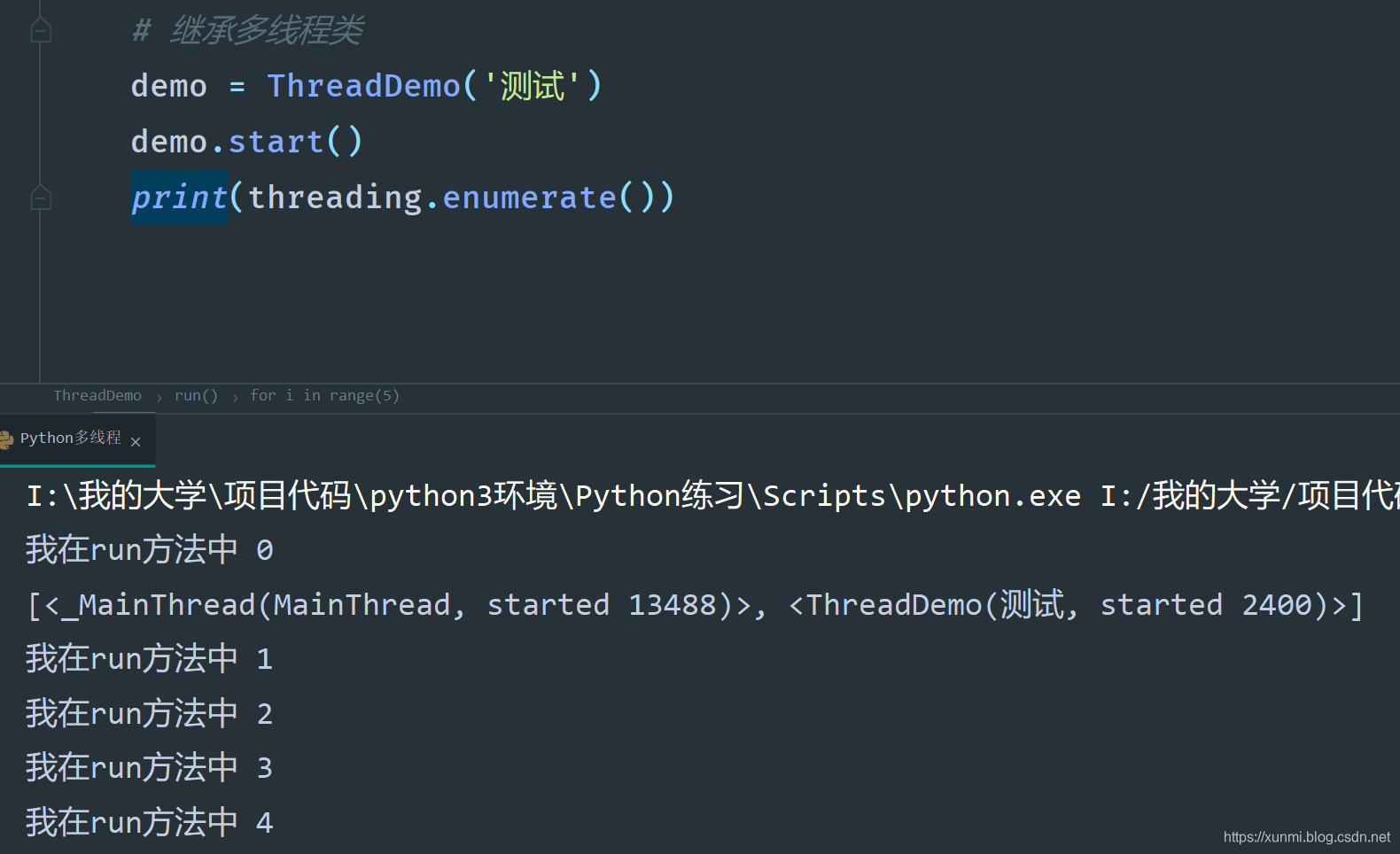
可以看到在继承threading.Thread后,我们创建的类实例化后调用.staet()方法,运行的却是.run()方法,如果你想直接调用.run()方法虽然同样不会报错,但是并不会创建新线程,还是会在主线程中运行。
多线程共享全局变量(线程间通信)
如果我们在正常单线程中只需要形参与实参就能像函数内传入参数,进行通信,而多线程中,我们如果想要进行通信就需要用到.Thread()方法中的args与kwars属性,其中args我们可以看做为位置传参,而kwars则为关键字传参使用。
args属性接收元组,kwars属性接收字典
import threading
import time
x = 0
lis = [1, 2]
# 创建多线程的函数
def eat(a, items):
for i in range(3):
a += 1
items.append(a)
print('我在吃饭', a, items)
time.sleep(1)
if __name__ == '__main__':
# 是Thread方法创建新的线程,将需要创建新线程的函数用目标(target)参数传入
demo1 = threading.Thread(target=eat, name='我是线程一', args=(x, ), kwargs={'items': lis})
# 启动线程
demo1.start()
print(x, lis)
共享全局变量资源竞争(锁)
当多线程中如果发生资源抢占,新版Python使用的是一套时间轮方式进行资源分配
当多个线程都需要用到同一个变量时,这时候如果需要保证这个变量能在一个线程中拥有最高的优先级,需要此线程控制变量时,不能让其他线程改变变量,这时候我们就需要用到.Lock锁或.RLock递归锁。
在使用中,锁与递归锁最大的不同为:锁只能加单层,而递归锁能加多层锁(递归锁解锁的层数需要与加锁相同)
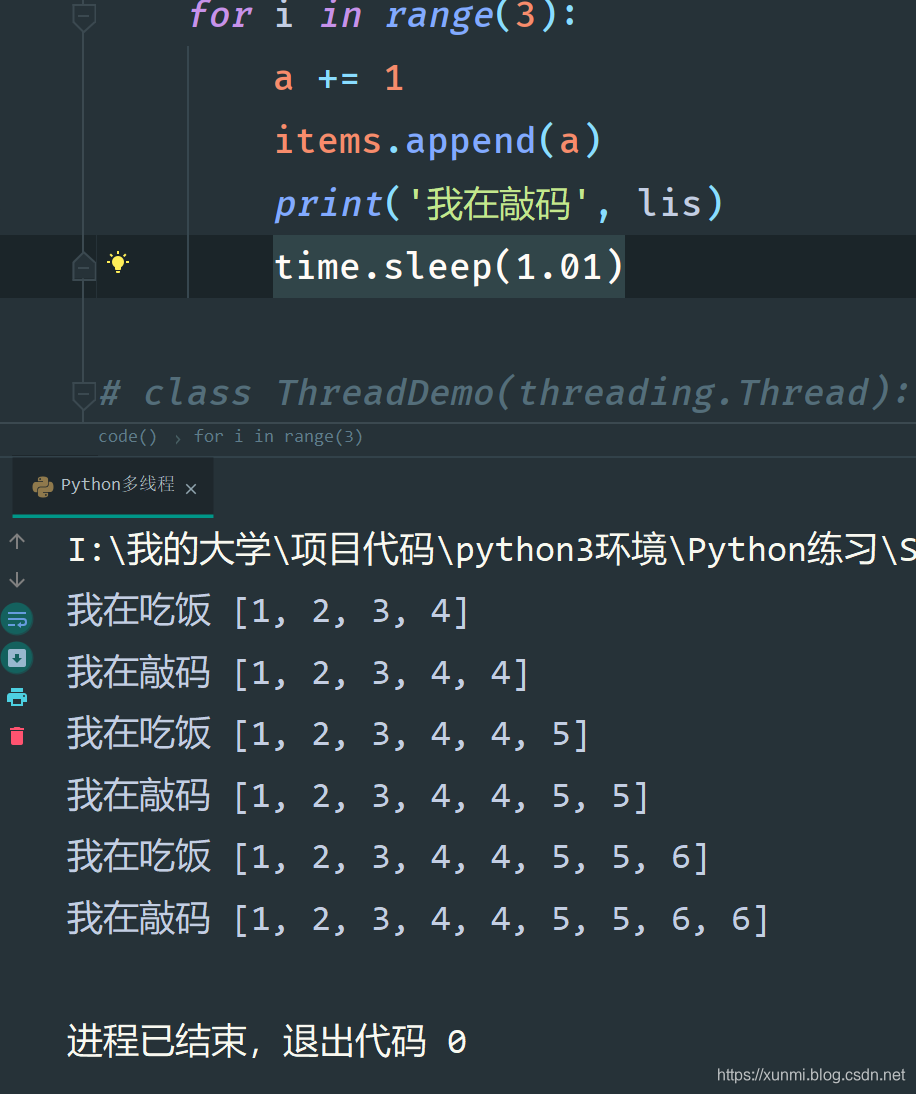
在不加锁的情况下,运行下列代码,我们会发现两个线程都会对共享的全局变量进行修改。
import threading
import time
x = 3
lis = [1, 2, 3]
# 创建多线程的函数
def eat(a, items):
for i in range(3):
a += 1
items.append(a)
print('我在吃饭', lis)
time.sleep(1)
def code(a, items):
for i in range(3):
a += 1
items.append(a)
print('我在敲码', lis)
time.sleep(1.01)
if __name__ == '__main__':
# 是Thread方法创建新的线程,将需要创建新线程的函数用目标(target)参数传入
demo1 = threading.Thread(target=eat, name='我是线程一', args=(x, ), kwargs={'items': lis})
demo2 = threading.Thread(target=code, args=(x, ), kwargs={'items': lis})
# 启动线程
demo1.start()
demo2.start()
互斥锁
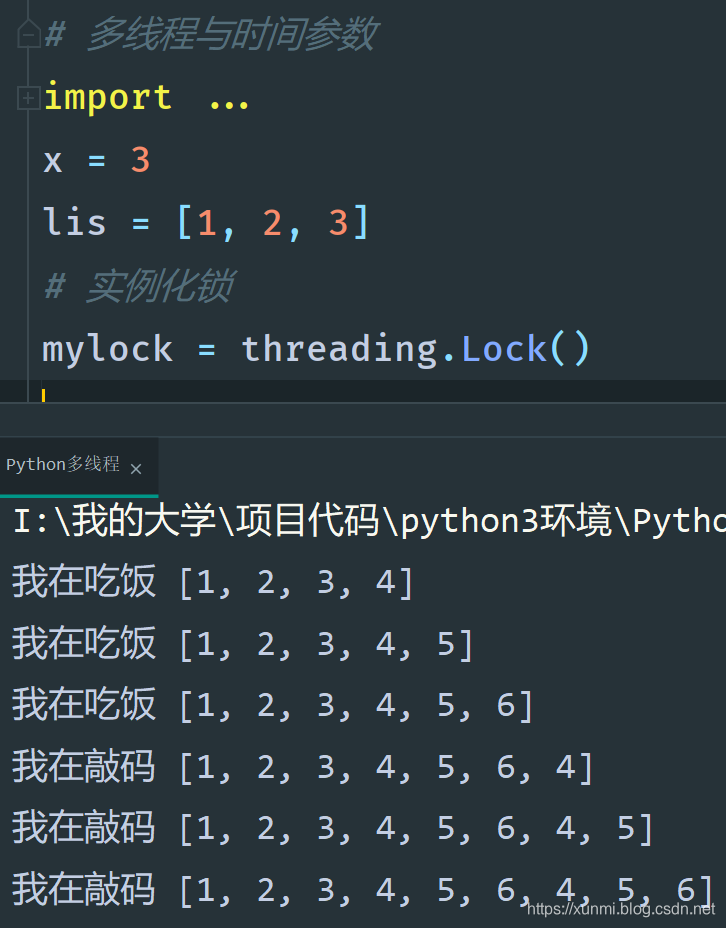
我们当前我们需要一个线程独占此资源进行修改的时候,我们就要用到锁。
我们先需要实例化一个锁.threading.Lock(),然后在需要加锁的地方调用实例化互斥锁的.acquire()方法,解锁用.release()方法。(如果需要多层锁实例化的是递归锁RLock,则加锁次数需要和解锁次数相同才能完全解锁)
import threading
import time
x = 3
lis = [1, 2, 3]
# 实例化锁
mylock = threading.Lock()
# 创建多线程的函数
def eat(a, items):
mylock.acquire()
for i in range(3):
a += 1
items.append(a)
print('我在吃饭', lis)
time.sleep(1)
mylock.release()
def code(a, items):
mylock.acquire()
for i in range(3):
a += 1
items.append(a)
print('我在敲码', lis)
time.sleep(1.01)
mylock.release()
if __name__ == '__main__':
# 是Thread方法创建新的线程,将需要创建新线程的函数用目标(target)参数传入
demo1 = threading.Thread(target=eat, name='我是线程一', args=(x, ), kwargs={'items': lis})
demo2 = threading.Thread(target=code, args=(x, ), kwargs={'items': lis})
# 启动线程
demo1.start()
demo2.start()
死锁
在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁。
比如说现有A、B两个变量,我们创建一个线程加锁调用了A变量,又创建了一个线程加锁调用B变量,然后调用A变量的线程现在需要调用B变量,等调用结束才会结束,而当前调用了B变量的线程需要调用A变量,等结束了才会解锁,这时候就形成了死锁。
import threading
import time
x = 3
y = 0
lis = [1, 2, 3]
# 实例化锁
mylocka = threading.Lock()
mylockb = threading.Lock()
# 创建多线程的函数
def eat(a, b):
mylocka.acquire()
print(a)
# 适当给些延迟让另一个线程能顺利启动
time.sleep(1)
mylockb.acquire()
print(b)
mylockb.release()
mylocka.release()
def code(a, b):
mylockb.acquire()
print(b)
mylocka.acquire()
print(a)
mylocka.release()
mylockb.release()
if __name__ == '__main__':
# 是Thread方法创建新的线程,将需要创建新线程的函数用目标(target)参数传入
demo1 = threading.Thread(target=eat, args=(x, y))
demo2 = threading.Thread(target=code, args=(x, y))
# 启动线程
demo1.start()
demo2.start()
在程序设计的时候尽量避免死锁,一旦导致死锁,可能会导致系统资源被大量消耗,导致系统崩溃等严重后果。还可以考虑加入超时等待,来主动跳出死锁。
Python守护线程
在多线程中只要还有一个非守护线程线程存活,那么我们的程序就不会结束,主线程默认为非守护线程,所以继承与主线程的所以子线程默认也为非守护线程,我们可以改变daemon属性的值来改变是否为守护线程。当主线程执行完毕后,剩下的线程如果没有非守护线程,那么程序就会退出。
就哪上述死锁的案例来说,我们如果将两个会行程死锁的线程设置成为守护线程,当主线程执行完毕后,已经被设置成守护线程的死锁子线程就不会影响程序的退出。
import threading
import time
x = 3
y = 0
lis = [1, 2, 3]
# 实例化锁
mylocka = threading.Lock()
mylockb = threading.Lock()
# 创建多线程的函数
def eat(a, b, items):
mylocka.acquire()
print(a)
time.sleep(1)
mylockb.acquire()
print(b)
mylockb.release()
mylocka.release()
def code(a, b, items):
mylockb.acquire()
print(b)
mylocka.acquire()
print(a)
mylocka.release()
mylockb.release()
time.sleep(1)
if __name__ == '__main__':
# 是Thread方法创建新的线程,将需要创建新线程的函数用目标(target)参数传入
demo1 = threading.Thread(target=eat, args=(x, y),)
demo2 = threading.Thread(target=code, args=(x, y), daemon=True)
# 启动线程
demo1.daemon = True
demo1.start()
demo2.start()
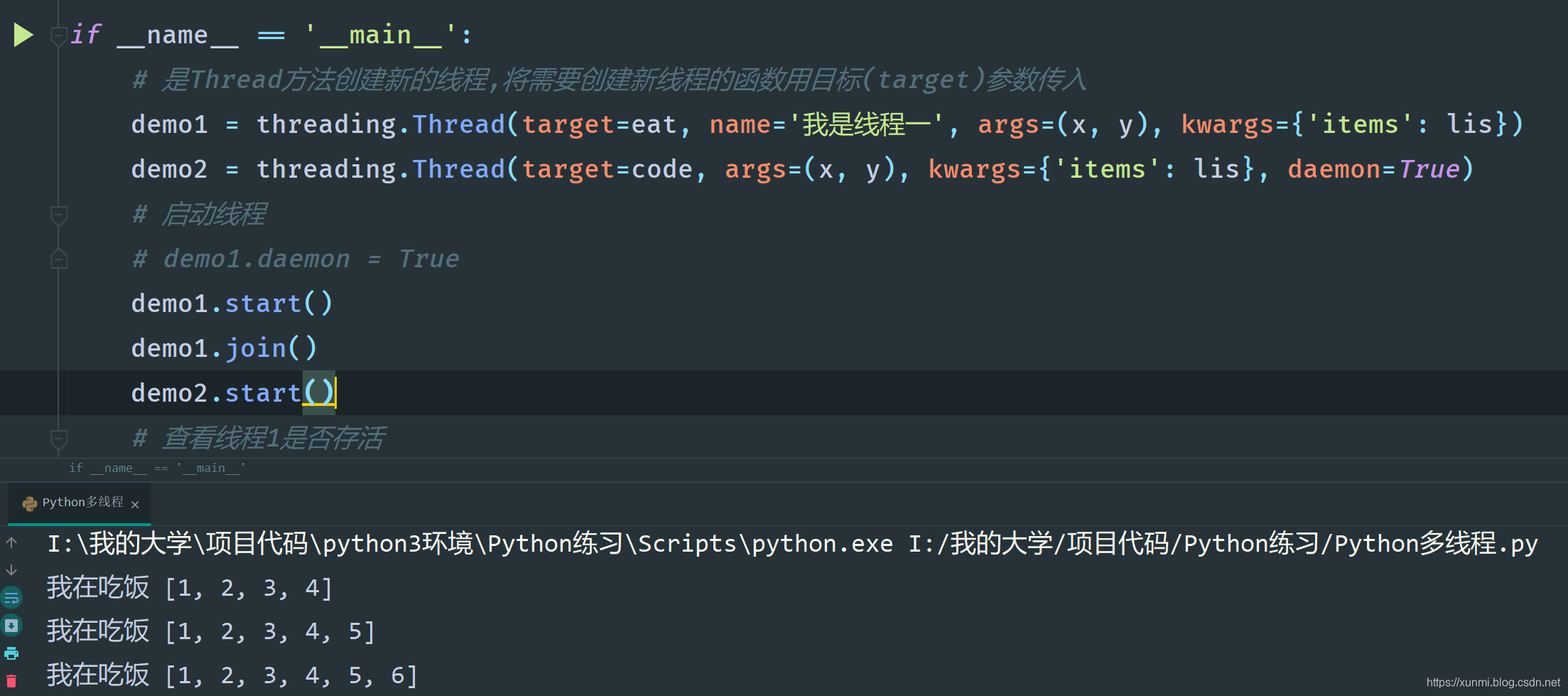
手动添加阻塞进程
多进程中还有一个比较常用的方法是.join(),用于等待子进程执行完成
如下图所示,当给demo1添加.join()后,会阻塞demo2的运行。当demo1运行完成后demo2才会开始运行。
Python多进程
多进程在Python中显得至关重要,因为CPython的GIL的存在Python,导致Python在多线程时同时只会有一个线程在运行,所以无法很好的利用多处理器的优势。但如果我们使用多个进程,那么他们的GIL也是独立存在的,这样我们在处理计算密集型任务的时候就可以更加高效的发挥出多核处理器的性能。
GIL(Global Interpreter Lock 全局解释器锁)CPython 解释器所采用的一种机制,它确保同一时刻只有一个线程在执行 Python bytecode。此机制通过设置对象模型(包括 dict 等重要内置类型)针对并发访问的隐式安全简化了 CPython 实现。给整个解释器加锁使得解释器多线程运行更方便,其代价则是牺牲了在多处理器上的并行性。
不过,某些标准库或第三方库的扩展模块被设计为在执行计算密集型任务如压缩或哈希时释放 GIL。此外,在执行 I/O 操作时也总是会释放 GIL。
创建一个(以更精细粒度来锁定共享数据的)“自由线程”解释器的努力从未获得成功,因为这会牺牲在普通单处理器情况下的性能。据信克服这种性能问题的措施将导致实现变得更复杂,从而更难以维护。
简述:一个时刻只有一个线程可以执行Python代码
创建多进程
多进程在基础用法上和多线程十分类似,只是库名有所区别,多进程的库为multiprocessing,
import time
import multiprocessing
import random
def eat():
for i in range(3):
print('我在吃饭')
time.sleep(1)
def code():
for i in range(3):
print('我在撸码')
time.sleep(1)
def bilibili():
for i in range(3):
print('我在看番')
time.sleep(1)
def main():
demo1 = multiprocessing.Process(target=eat)
demo2 = multiprocessing.Process(target=code)
demo3 = multiprocessing.Process(target=bilibili)
demo1.start()
demo2.start()
demo3.start()
if __name__ == '__main__':
main()
当上述代码运行任务管理器中会出现了五个Python进程,Pycharm会产生两个进程,还有三个则为我们生成的子进程。
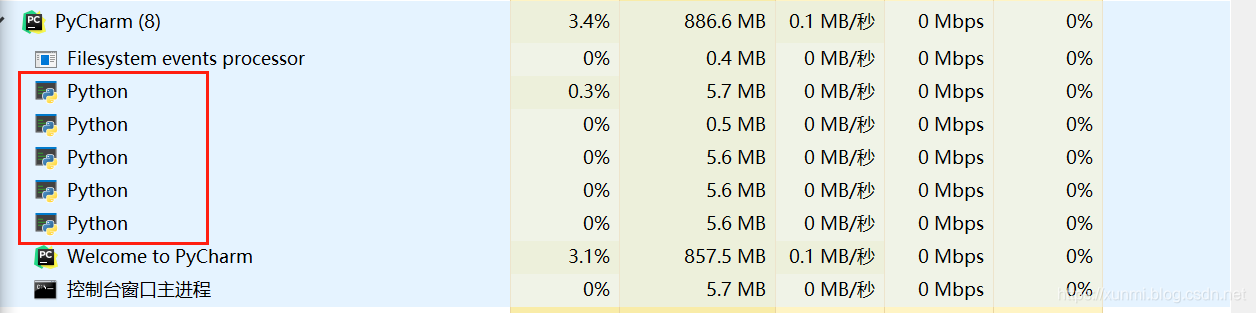
多进程的multiprocessing.Process()方法中和多线程的threading.Thread()方法中使用的属性相同,并且功能类似。很多在多线程threading库中存在的方法在在multiprocessing库中也同样存在。
多进程交换对象与共享资源(进程通信)
多进程不同于多线程使用的所有资源都为共享资源,Python每创建一个进程都可以看做Python将代码重新进行了复制粘贴。所以每个进程之中的资源并不是共享的,在使用多进程时尽量避免共享资源的使用,不过无论是对象,还是变量,都有对应的方法可以进行资源共享。
队列Queue()
这里的队列就是数据结构中的队列,在这里就不在赘述,如果有不熟悉队列可以查看我这篇博客通过Python创建队列。队列的单向结构也标注着队列在多进程中交互对象是单向的。
注意:多线程中的队列不同于普通队列,线程中用于交互对象的队列不能为queue.Queue,必须是multiprocessing.Queue队列中需要传入指定一个长度(默认长度根据系统自动设定),如果超过长度继续添加程序会被阻塞。
| Queue常用方法名 | 作用 |
|---|---|
| put | 向队列中添加元素,如果队列已满则线程进入堵塞状态 |
| get | 从队列中取出元素,如果队列为空则线程进入堵塞状态 |
| full | 判断队列是否已满 |
| empty | 判断队列是否为空 |
| qsize | 判断当前队列中有多少元素 |
| close | 情况队列 |
| put_nowait | 向队列中添加元素,如果队列已满则返回异常并不堵塞 |
| get_nowait | 从队列中取出元素,如果队列为空则返回异常并不堵塞 |
import time
import multiprocessing
def eat(q):
for i in range(3):
q.put(i)
print('我在吃饭')
time.sleep(1)
def code(q):
for i in range(3):
print('我在撸码', q.get())
time.sleep(1)
def main():
# 定义一个用于共享数据的队列
q = multiprocessing.Queue(3)
demo1 = multiprocessing.Process(target=eat, args=(q,))
demo2 = multiprocessing.Process(target=code, args=(q,))
demo1.start()
demo1.join()
demo2.start()
队列是线程和进程安全的。
管道Pipe()
不同于队列,管道默认是双向的。
请注意,如果两个进程(或线程)同时尝试读取或写入管道的 同一 端,则管道中的数据可能会损坏。当然,在不同进程中同时使用管道的不同端的情况下不存在损坏的风险。
当实例化管道时,会已元组的形式返回两个对象,分别为管道的首尾。
我在windows环境下测试管道发现会出现很多异常,而且存在数据损坏的风险,所以除非必要,否则不建议使用管道。
管道的添加与读取元素分别为send() 和 recv()
import time
import multiprocessing
def eat(p):
for i in range(3):
p.send(i)
print('我在吃饭')
time.sleep(1)
def code(p):
for i in range(3):
print('我在撸码', p.recv())
time.sleep(1)
def main():
# 定义一个用于共享数据的管道
head_p, foot_p = multiprocessing.Pipe()
demo1 = multiprocessing.Process(target=eat, args=(head_p,))
demo2 = multiprocessing.Process(target=code, args=(foot_p,))
demo1.start()
demo1.join()
demo2.start()
if __name__ == '__main__':
main()
共享内存
在多进程multiprocessing中同样支持锁,且使用方式与上述线程一致,再次就不做赘述了。
在多进程中如果需要共享变量我们可以使用Value 或 Array,Value为单个对象,而 Array为数组类型共享内存。
而且Value 与 Array都需要传入一个代码类型或类型(typecode_or_type),同时Array还需传入一个默认数组
| 常用代码类型或类型 | 含义 |
|---|---|
'b' |
整数型 |
'd' |
浮点型 |
'u' |
字符型 |
import time
import multiprocessing
def eat(v, a):
for i in range(3):
v.value = a[i]
a[i] = -a[i]
print('我在吃饭', v.value, a[i])
time.sleep(1)
def code(v, a):
for i in range(3):
print('我在撸码', v.value, a[i])
time.sleep(1.01)
def main():
# 定义一个共享对象
v = multiprocessing.Value('b')
a = multiprocessing.Array('b', range(3))
demo1 = multiprocessing.Process(target=eat, args=(v, a))
demo2 = multiprocessing.Process(target=code, args=(v, a))
demo1.start()
demo2.start()
if __name__ == '__main__':
main()
进程池
当存在一个正在运行的进程时,需要耗费大量资源,所以无休无止的创建进程无疑严重影响计算机性能,而进程池就是为解决这个问题而产生的。
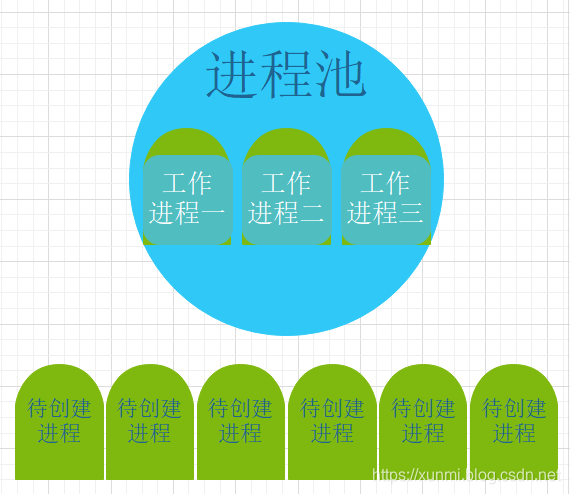
我们可以设置一个工作进程数目,如果当前创建进程时,没有到达工作进程数目,则立马创建,如果工作进程数目已满,则等待有进程关闭后在将待创建的进程创建。
Pool([processes[, initializer[, initargs[, maxtasksperchild[, context]]]]]
processes 是要使用的工作进程数目。如果 processes 为 None,则使用 os.cpu_count() 返回的值(os.cpu_count() 为系统中cpu的数量)。
如果 initializer 不为 None,则每个工作进程将会在启动时调用 initializer(*initargs)。
maxtasksperchild 是一个工作进程在它退出或被一个新的工作进程代替之前能完成的任务数量,为了释放未使用的资源。默认的 maxtasksperchild 是 None,意味着工作进程寿与池齐。
context 可被用于指定启动的工作进程的上下文。通常一个进程池是使用函数 multiprocessing.Pool() 或者一个上下文对象的 Pool() 方法创建的。在这两种情况下, context 都是适当设置的。
在Pool中我们最常会用到的是processes 参数,我们一般会指定线程池的大小。向线程池中添加线程的方法有两种分别是.apply()与.apply_async()方法
apply(func[, args[, kwds]]):使用此方法会造成阻塞,当主线程执行到此时会立即启用此进程,然后等待此进程执行完毕后在继续往下执行(使用此方法会导致程序始终只会有一个进程在运行,导致程序无法并行),官方建议弃用此方法apply_async(func[, args[, kwds[, callback[, error_callback]]]]):非阻塞运行,进程被添加到进程池后,进程池会启动进程并且准备就绪,等待系统调度运行。(如果主进程运行结束,则会导致进程池关闭,未被调度运行的进程会被清除)- func:传入的函数或方法
- args与kwds:相当于
.Process()中的args与kwargs - callback:它必须是一个接受单个参数的可调用对象。当执行成功时, callback 会被用于处理执行后的返回结果,否则,调用 error_callback 。
- error_callback:它必须是一个接受单个参数的可调用对象。当目标函数执行失败时, 会将抛出的异常对象作为参数传递给 error_callback 执行。
close():阻止后续任务提交到进程池,当所有任务执行完成后,工作进程会退出。(这里的close并不是清除或者关闭进程池的意思)terminate():不必等待未完成的任务,立即停止工作进程。当进程池对象呗垃圾回收时, 会立即调用 terminate() 。join():等待工作进程结束。
import time
import multiprocessing
def eat(v, a):
print('我在吃饭', v, a)
time.sleep(random.random())
return 'eat执行结束'
def code(v, a):
print('我在撸码', code出现bug)
time.sleep(random.random())
def callback(data):
print(data)
def main():
# 定义一个只能同时运行三个进程的进程池
po = multiprocessing.Pool(3)
for i in range(10):
po.apply_async(eat, (i, ), {'a': '我是关键字传参'}, callback, callback)
po.apply_async(code, (i, '0'))
print("--开始运行--")
po.close()
po.join()
print("--结束运行--")
if __name__ == '__main__':
main()
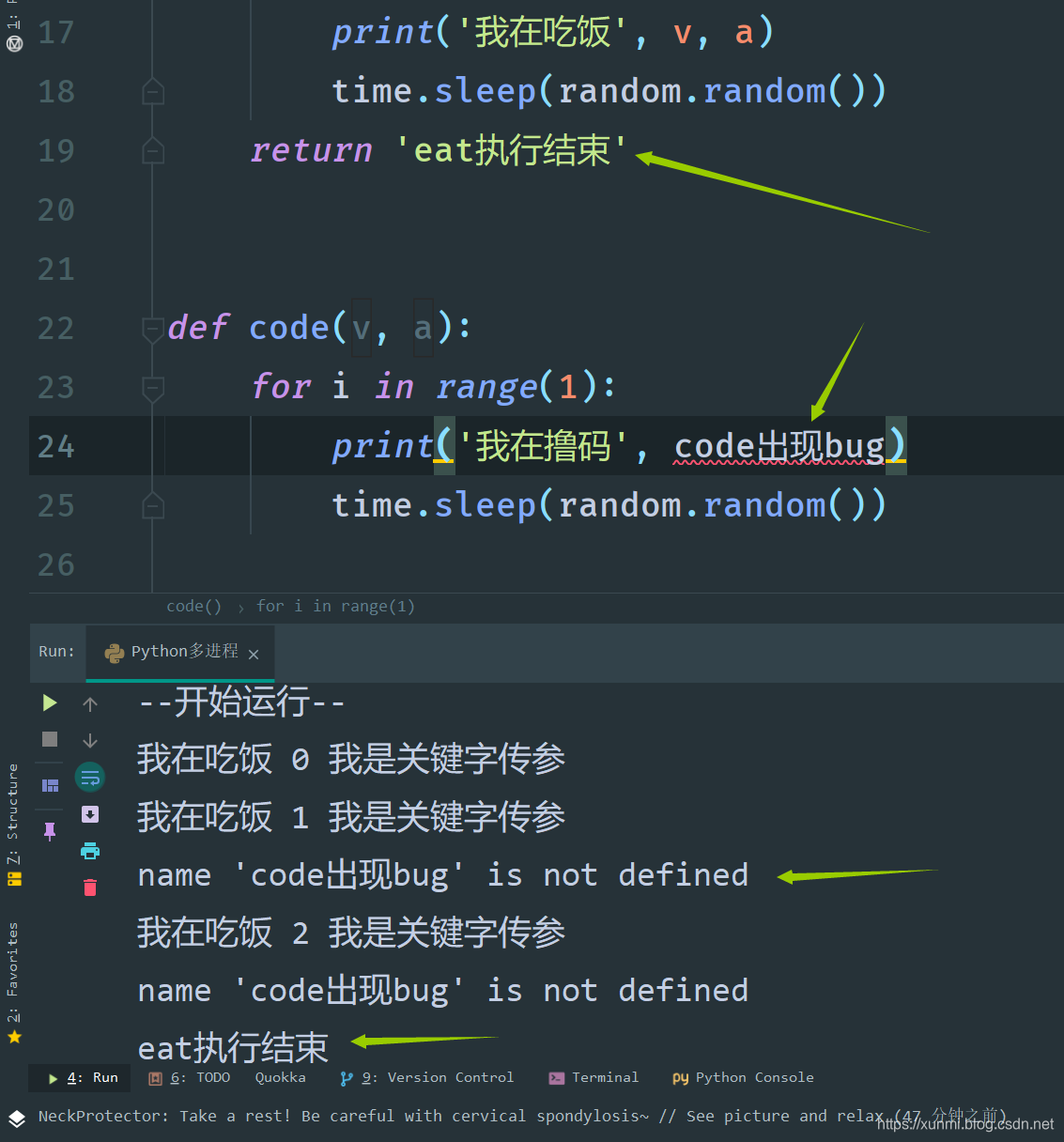
因为这里我们使用的是.apply_async()方法,主进程不会主动等待子进程,所以当我们将所以进程添加到进程池后使用.close()方法关闭进程添加通道,然后使用.join()方法让主进程停下等待子进程完全结束后在结束。
进程池间的进程通信(服务进程)
进程池使用常规的多进程方式是无法正常通信的,这时候我们就需要服务进程Manager()的帮助
Manager() 返回的管理器支持类型: list 、 dict 、 Namespace 、 Lock 、 RLock 、 Semaphore 、 BoundedSemaphore 、 Condition 、 Event 、 Barrier 、 Queue 、 Value 和 Array 。Manager() 中调用的类似和原类型使用方式一致,他只是使这些方式能在进程池中正常工作,下面我们就哪Queue来演示.Manager().Queue()的使用方式
import time
import multiprocessing
import random
def eat(v, a):
for i in range(1):
v.put(i)
print('我在吃饭', a)
time.sleep(1)
return 'eat执行结束'
def code(v, a):
for i in range(1):
print('我在撸码', v.get())
time.sleep(1)
def callback(data):
print(data)
def main():
# 使用服务进程(Manager方法)定义一个队列
q = multiprocessing.Manager().Queue(3)
# 定义一个只能同时运行三个进程的进程池
po = multiprocessing.Pool(3)
for i in range(10):
po.apply_async(eat, (q, ), {'a': '我是关键字传参'}, callback, callback)
po.apply_async(code, (q, '0'), callback=callback, error_callback=callback)
print("--开始运行--")
po.close()
po.join()
print("--结束运行--")
if __name__ == '__main__':
main()
协程
协程,又称微线程。是一种以极小资源就可以进行多任务的方法。也就是在单个线程中实现多任务。协程是用单个线程实现程序的异步非阻塞处理。
进程、线程、协程多任务对比
- 进程: 多核兼容性好,并发情况相对较多,占用资源大,线程切换成本高
- 线程: 多核兼容性一般,因为Python的GIL的存在,只有在特殊情况在会用到多核,占用资源较少,切换成本较低
- 协程: 只能单线程运行,不兼容多核,不会占用额外资源,切换成本最低。
协程的使用
协程的出现是由生成器(yield)一步步进化而来,生成器我在之前的一篇博客中已经进行了详细的描述,在这里就不在赘述Python的生成器
Python在Python3.5之后引入了:async、await语法实现协程(在Python3.7中全面推广,并且将其设为关键字),在旧版的Python中也可以下载第三方的greenlet、gevent下载使用(pip install greenlet、pip install gevent)因为旧版已经逐渐被淘汰,下面我们会使用官方的async、await进行协程的说明已经使用。
使用协程我们需要引入asyncio这个库。
注:async、await语法在Python3.7后为关键字,属于Python的重要语法,但是大多时候我们都需要asyncio这个库里面的一些方法才能进行协程。
import asyncio
# 使用async语法创建的对象为协程
async def eat():
while True:
# await用于指定可等待的对象(await指定的可等待对象必须包含__await__方法)
await asyncio.sleep(1)
print('开饭了')
# 如果直接调用eat()函数,不会有任何作用,因为创建好的eat()没有被等待
eat()
# 使用asyncio的run方法即可启动协程中可等待对象
asyncio.run(eat())
协程中最基础的async是用来创建协程的,而await用来标明可等待对象
asyncio用法
| 常用的asyncio方法 | 作用 |
|---|---|
| asyncio.sleep(delay, result=None, *, loop=None) | 用于线程睡眠(time.sleep()不可作为替代品) |
| asyncio.run(coro, *, debug=False) | 启动协程并返回coro结果 |
| asyncio.create_task(coro, *, name=None) | 创建任务(coro为协程,Python3.8之后支持给协程命名) |
| asyncio.gather(*aws, loop=None, return_exceptions=False) | 并发 运行 aws 序列中的 可等待对象。最后程序会以列表的形式返回所有运行的协程值。(loop为指定循环顺序,return_exceptions为是否跳过报错协程,默认不会跳过,如果改成True则会将报错信息同以返回值的形式返回) |
创建多任务
使用协程创建多任务如果是少量,我们可以使用create_task方法逐个创建并且启用,如果有大量需要创建协程的对象,我们可以使用gather方法一次性全部添加使用
import asyncio
# 使用async方法创建的对象为协程
async def eat(n):
for i in range(n):
# await用于指定可等待的对象(await指定的可等待对象必须包含__await__方法)
await asyncio.sleep(n-i)
print('开饭了')
# 使用asyncio的run方法即可启动协程
# asyncio.run(eat())
async def code(n):
for i in range(n):
await asyncio.sleep(i)
print('撸码了')
async def main():
# 使用create_task创建一个
dome1 = asyncio.create_task(eat(3))
dome2 = asyncio.create_task(code(3))
print('--开始执行--')
await dome1
await dome2
print('--结束执行--')
asyncio.run(main())
上述程序中使用的create_task方法可以用gather方法代替
# dome1 = asyncio.create_task(eat(3))
# dome2 = asyncio.create_task(code(3))
# await dome1
# await dome2
# 以上代码相当于
await asyncio.gather(eat(3), code(3))
