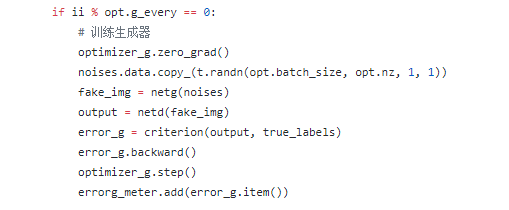
答:
detach的作用是冻结梯度下降,无论是对于判别网络还是生成网络而言,我们更新的都是关于logD(G(z)),对于判别网络而言,冻结G并不影响整体的梯度更新(就是内层函数看成是一个常数,不影响外层函数求梯度),但是反过来,如果冻结D,就没有办法完成梯度更新了。所以,我们在训练生成器的时候没用冻结D的梯度。所以,对于生成器而言,我们的确计算了D的梯度,但是我们没有更新D的权重(只写了optimizer_g.step),所以训练生成器的时候也就不会改变判别器了。你可能会问,那既然如此,为什么训练判别器的时候还要加上detach呢,这不是多此一举吗?
因为我们冻结梯度下降,可以加快训练速度,所以能用的地方就可以用一下,不是多此一举。然后我们在训练生成器的时候,因为logD(G(z))的原因,冻结D的梯度根本就没有办法计算了,所以,这里就不写detach了
