李弘毅机器学习笔记:第十四章—Why deep?
问题1:越深越好?
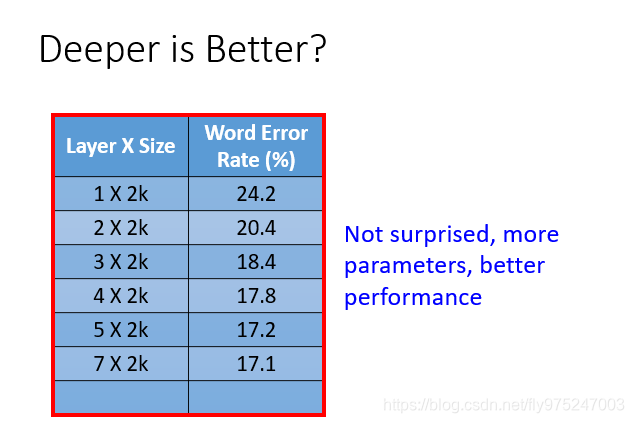
learning从一层到七层,error rate在不断的下降。能看出network越深,参数越多,performance较也越好。
问题2:矮胖结构 v.s. 高瘦结构
真正比较deep和shallow
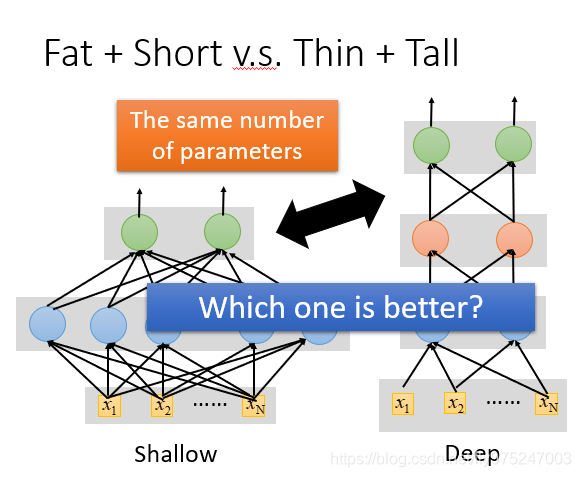
比较shallow model较好还是deep model较好,在比较的时候一个前提就是调整shallow和Deep让他们的参数是一样多,这样就会得到一个矮胖的模型和高瘦的模型。
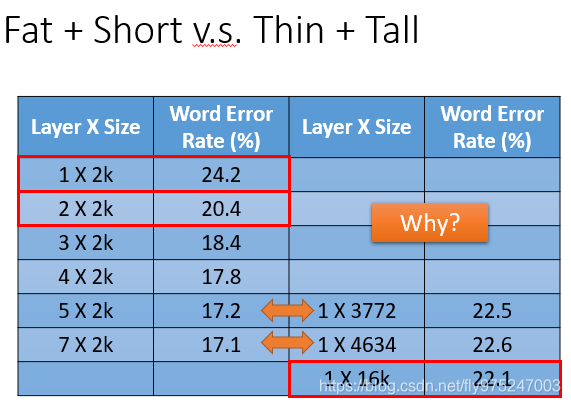
这个实验的后半段的实验结果是:我们用5层hidden layer,每层2000个neural,得到的error rate是17.2%(error rate是越小越好的)而用相对应的一层的模型,得到的错误率是22.5%,这两个都是对应的拥有相似参数个数的模型。继续看下面的4634个参数和16k个参数,如果你只是单纯的增加parameters,是让network变宽不是变高的话,其实对performance的帮助是比较小的。
所以如果把network变高对performance是很有帮助的,network变宽对performance帮助没有那么好的
引入模块化
问题1:为什么变高比变宽好呢?
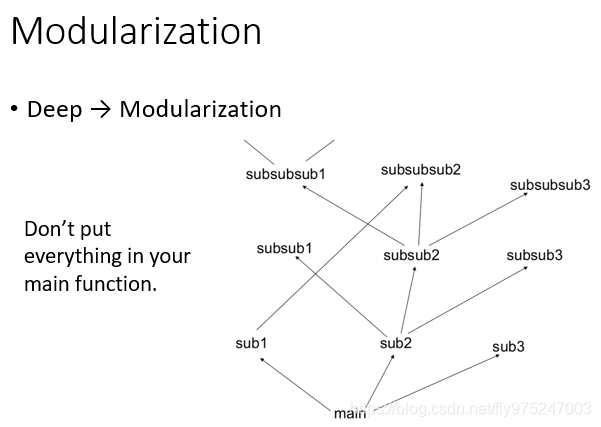
我们在做deep learning的时候,其实我们是在模块化这件事。我们在main function时,我们会写一些sub function,一层一层结构化的架构。有一些function是可以共用的,就像一个模型,需要时候去用它减小复杂度(如图所示)


在 machine learning上,可以想象有这样的test。我们现在要做影像分类,我们把image分为四类(每个类别都有一些data),然后去train 四个classifier。但问题是boys with long hair的data较少(没有太多的training data),所以这个boys with long hair的classifier就比较weak(performance比较差)
解决方法:利用模组化的概念(modularization)的思想

假设我们先不去解那个问题,而是把原来的问题切成比较小的问题。比如说,我们先classifier,这些classifier的工作就是决定有没有一种特征出现。
现在就是不直接去分类长头发男生还是短头发男生,而是我们先输入一张图片,判断是男生还是女生和是长头发还是短头发,虽然说长头发的男生很少,但通过女生的数据和男生的数据都很多,虽然长头发的数据很少,但是短发的人和长发的人的数据都很多。所以,这样训练这些基分类器就不会训练的太差(有足够的数据去训练)
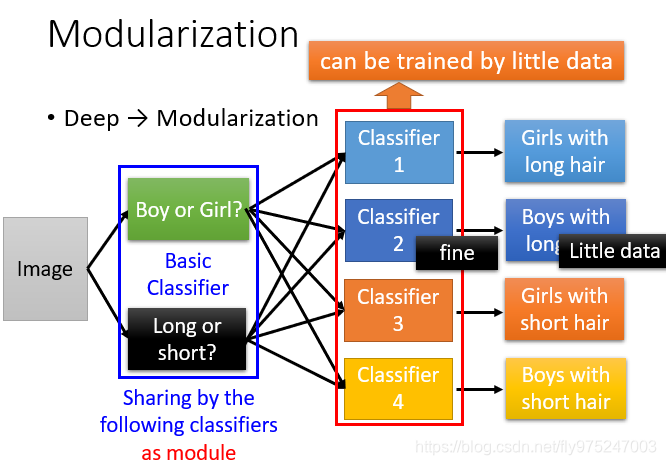
现在我们要解决真正问题的时候,你的每个分类器就可以去参考输出的基本特征,最后要下决定的分类器,它是把前面的基分类器当做模组,每一个分类器都共用同一组模型(只是用不同的方式来使用它而已)。对分类器来说,它看到前面的基分类器告诉它说是长头发是女生,这个分类器的输出就是yes,反之就是no。
所以他们可以对后面的classifier来说就可以利用前面的classifier(中间),所以它就可以用比较少的训练数据就可以把结果训练好。
深度学习
问题2:深度学习和模组化有什么关系?
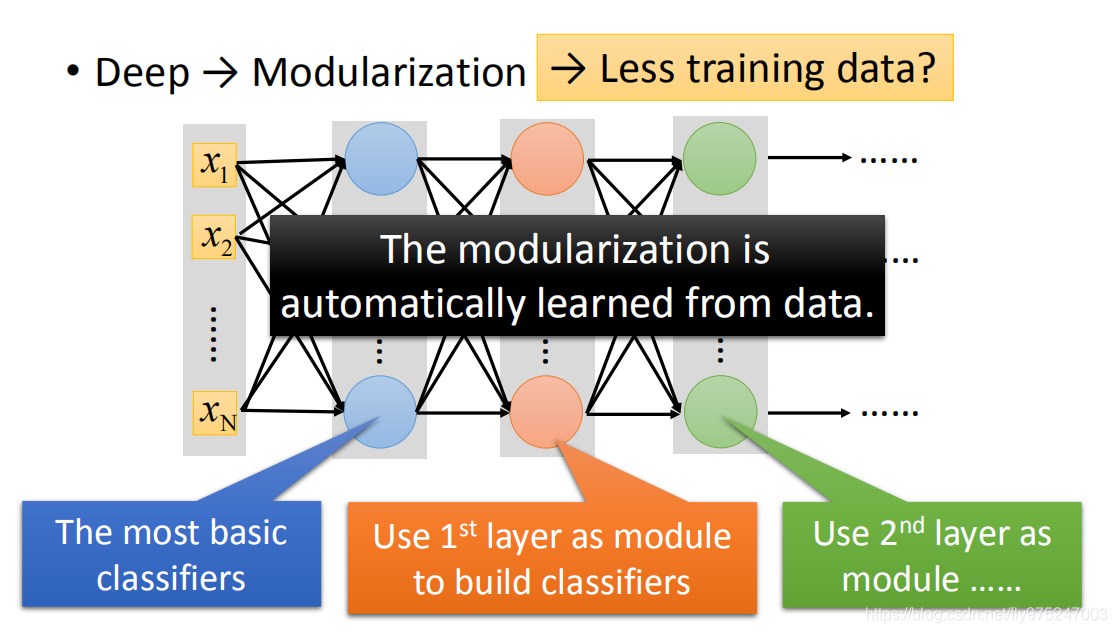
每一层neural可以被看做是一个basic classifier,第一层的neural就是最基分类器,第二层的neural是比较复杂的classifier,把第一层basic classifier 的output当做第二层的input(把第一层的classifier当做module),第三层把第二层当做module,以此类推。
在做deep learning的时候,如何做模组化这件事,是机器自动学到的。
做modularization这件事,把我们的模型变简单了(把本来复杂的问题变得简单了),把问题变得简单了,就算训练数据没有那么多,我们也就可以把这个做好
使用语音识别举例
在语音上我们为什么会用到模组化的概念
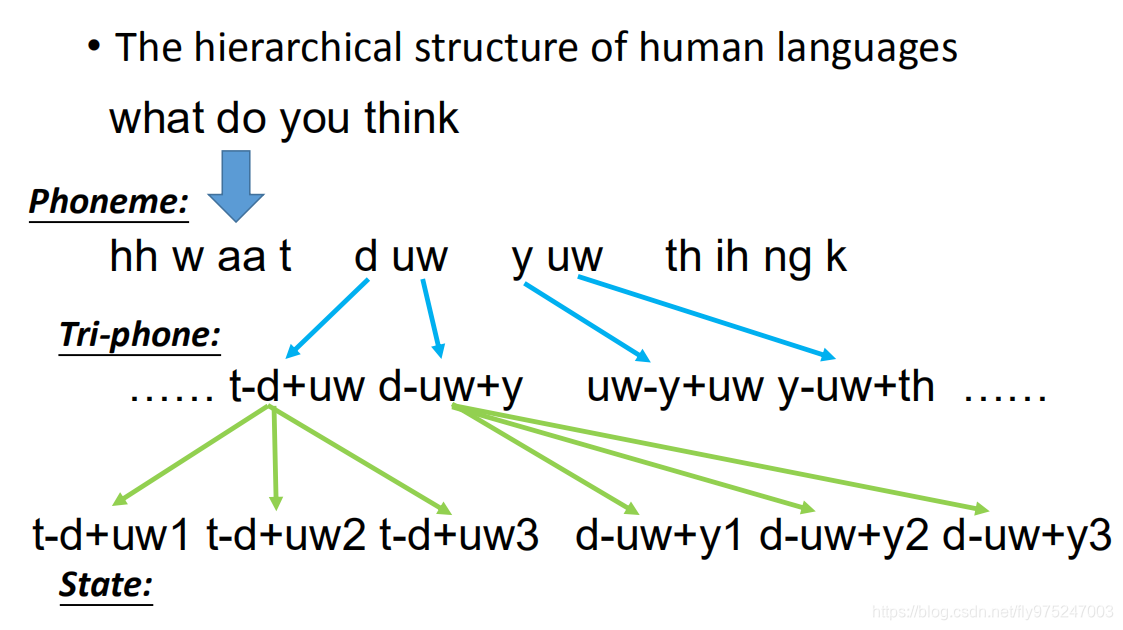
当你说一句:what do you think,这句话其实就是由一组phoneme(音素)所组成的。同样的phoneme可能会有不太一样的发音。当你发d-uw的u时和发y-uw的u时,你心里想的是同一个phoneme,心里想要发的都是-uw。但是因为人类口腔器官的限制,所以你没办法每次发的-uw都是一样的。因为前面和后面都接了其他的phoneme,因为人类发音口腔器官的限制,你的phoneme发音会受到前后的影响。为了表达这件事情,我们会给同样的phoneme不同的model,这就是Tri-phone。
Tri-phone表达是这样的,你把这个-uw加上前面的phoneme和后面的phoneme,跟这个-uw加上前面phoneme和后面的phonemeth,就是Tri-phone(这不是考虑三个phone的意思)
这个意思是说,现在一个phone用不同的model来表示,一个phoneme它的constant phone不一样,我们就要不同model来模拟描述这个phoneme。
一个phoneme可以拆成几个state,state有几个通常自己定义,通常就定义为三个state
语音辨识:
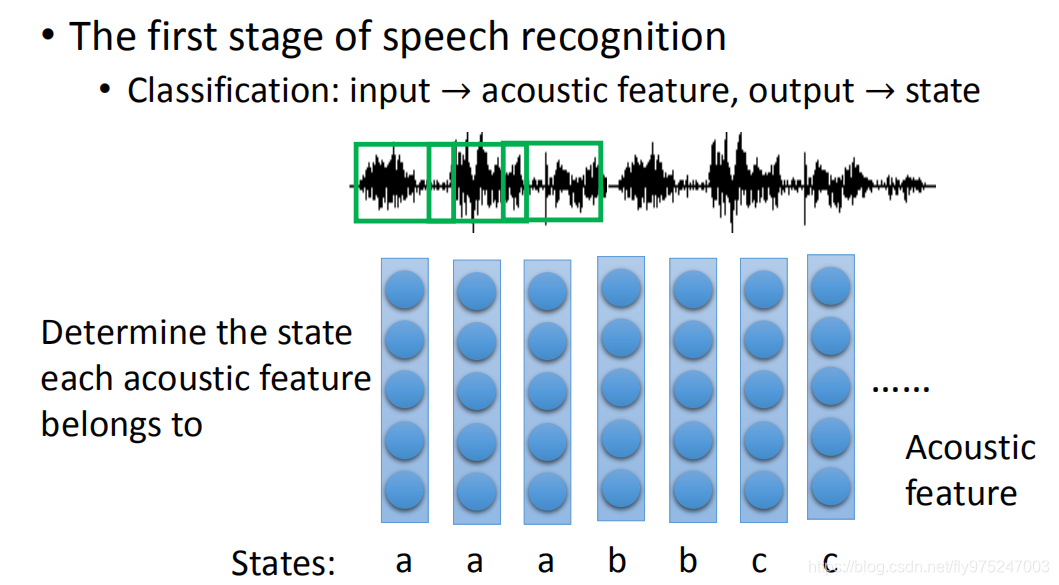 语音辨识特别的复杂,现在来讲第一步,第一步要做的事情就是把acoustic feature转成state。所谓的acoustic feature简单说起来就是声音讯号发生一段wave phone,这这个wave phone通常取一段window(这个window通常不是太大)。一个window里面就用一个feature来描述里面的特性,那这个就是一个acoustic feature。你会在这个声音讯号上每隔一段时间来取一个window,声音讯号就变成一串的vector sequence。在语音辨识的第一阶段,你需要做的就是决定了每一个acoustic feature属于哪一个state。把state转成phone,phoneme,在把phoneme转成文字,接下来考虑同音异字的问题,这不是我们今天讨论的问题。
语音辨识特别的复杂,现在来讲第一步,第一步要做的事情就是把acoustic feature转成state。所谓的acoustic feature简单说起来就是声音讯号发生一段wave phone,这这个wave phone通常取一段window(这个window通常不是太大)。一个window里面就用一个feature来描述里面的特性,那这个就是一个acoustic feature。你会在这个声音讯号上每隔一段时间来取一个window,声音讯号就变成一串的vector sequence。在语音辨识的第一阶段,你需要做的就是决定了每一个acoustic feature属于哪一个state。把state转成phone,phoneme,在把phoneme转成文字,接下来考虑同音异字的问题,这不是我们今天讨论的问题。
传统的实现方法:HMM-GMM
在deep learning之前和之后,语音辨识有什么不同,这时候你就更能体会deep learning会在语音辨识有显著的成果。
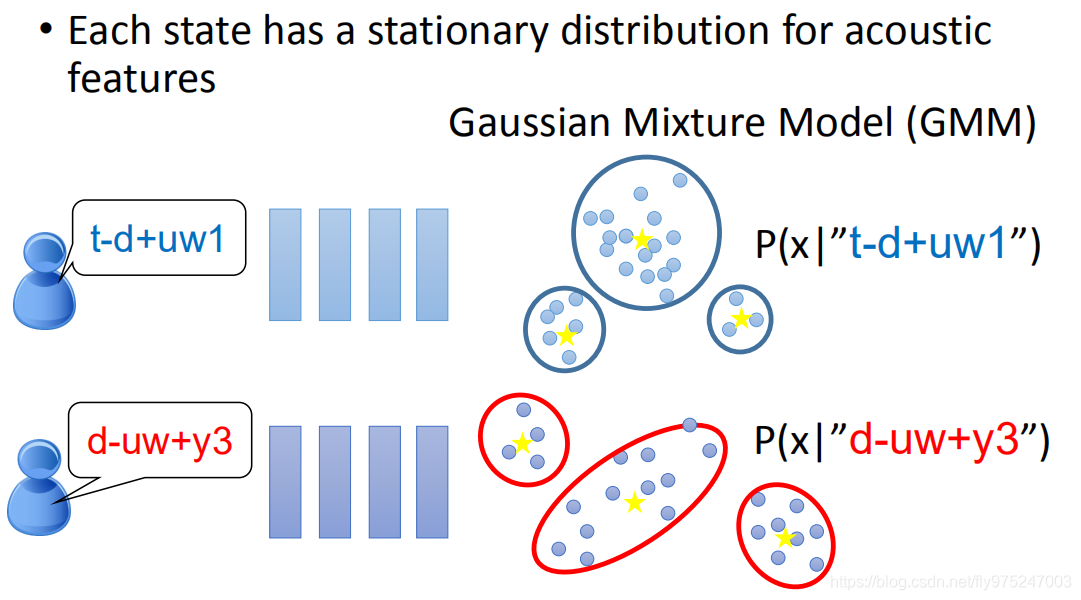
我们要机器做的是,在第一阶段做的是分类这件事,就是决定一个acoustic feature属于哪一个state,传统方式是做GNN
我们假设每一个state就是一个stationary,属于每一个state的acoustic feature的分布是stationary,所以你可以用model来描述。
比如第一个state,可以用GNN来描述;另外一个state,可以用另外一个GNN来描述。这时候给你一个feature,你就可以说每一个acoustic feature从每一个state产生出来的几率,这个就叫做Gaussian Mixture Model
仔细一想,这一招根本不太work,因为这个Tri-phone的数目太多了。一般的语言(中文、英文)都有将近30、40phone。在Tri-phone里面,每一个phoneme随着它constant不同,你要用不同的model。到底有多少个Tri-phone,你有30的三次方的Tri-phone(27000),每个Tri-phone有三个state,所以,你有数万的state,而你每一个state都要用Gaussian Mixture Model来描述,参数太多了。
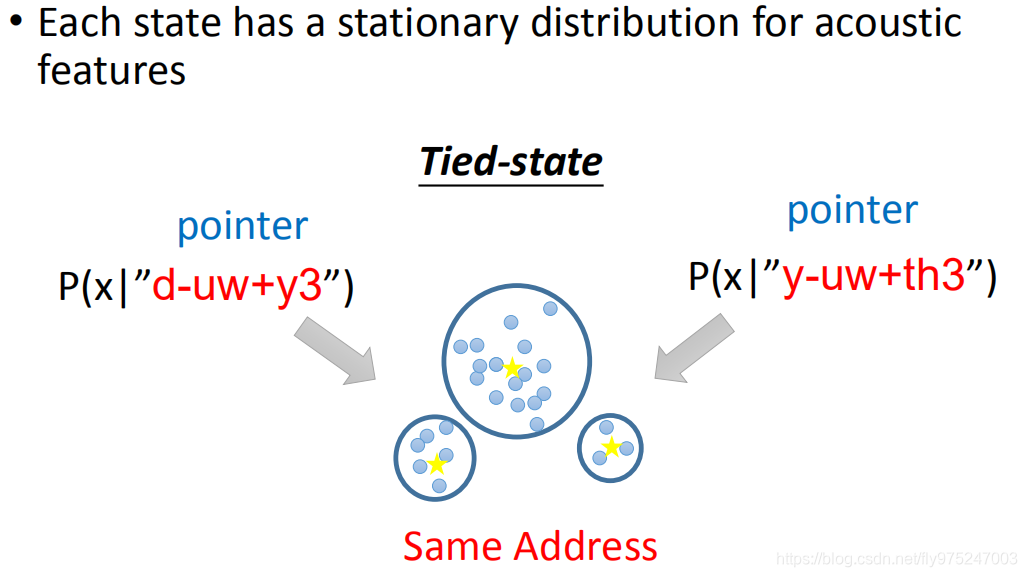
有一些state,他们会共用同一个model distribution,这件事叫做Tied-state。加入说,我们在写一些程式的时候,不同的state名称就好像是pointer,那不同的pointer他们可能会指向同样的distribution。所以有一些state,它的distribution是共用的,有些是不共用的。那到底哪些事共用的,哪些不是共用的,那么就变成你要凭着经验和一些语言学的知识来决定哪些state是要共用的
这些是不够用的,如果只分state distribution是共用的或不共用的,这样就太粗了。所以就有人开始提一些想法:如何让它部分共用等等。
仔细想想刚才讲的HMM-GMM的方式,所有困惑的是state是independently,这件事是不effection对model人类的声音来说。
想看人类的声音来说,不同的phoneme虽然归为不同的因素,分类归类为不同的class,但这些phoneme不是完全无关的。这些都是人类发音器官generate出来的,它们中间是有根据人类发音器官发音的方式,之间是有关系的
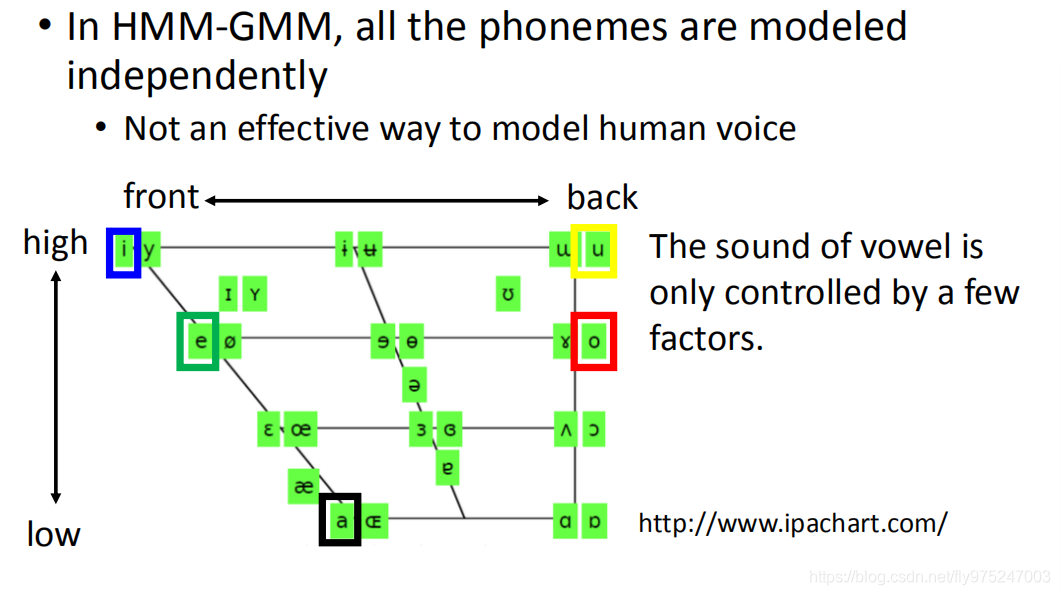
举例来说,在这张图上画出了人类语言所有的母音,那么这个母音的发音其实就只是受到三件事的影响。一个是你舌头前后的位置,一个是你舌头上下的位置,还有一个是你的嘴型。(母音就只受到这三件事的影响)在这张图你可以找到最常见的母音(i,e,a,u,o)i,e,a,u,0它们之间的差别就是当你从a发到e发到i的时候,你的舌头是由往上的。i跟u的差别是你的舌头在前后的区别。你可能感觉不要舌头的位置在哪里,你要知道的是舌头的位置是不是真的跟这个图上一样,你可以在对着镜子喊a,e,i,u,o,你就会发现你舌头的位置就跟这个图上的形状一模一样的。
这这个图上,同一个位置的母音代表说舌头的位置是一样的但是嘴型是不一样的。比如说,我们看最左上角的母音,一个是i一个是y,i跟y的差别就是嘴型不一样的。如果是i的话嘴型是扁的,如果是y的话嘴型是圆的,所以改变嘴型就可以从i到y。
所以这个不同的phoneme之间是有关系的,如果说每个phoneme都搞一个model,这件事是没有效率的。
深度学习的实现方法 DNN
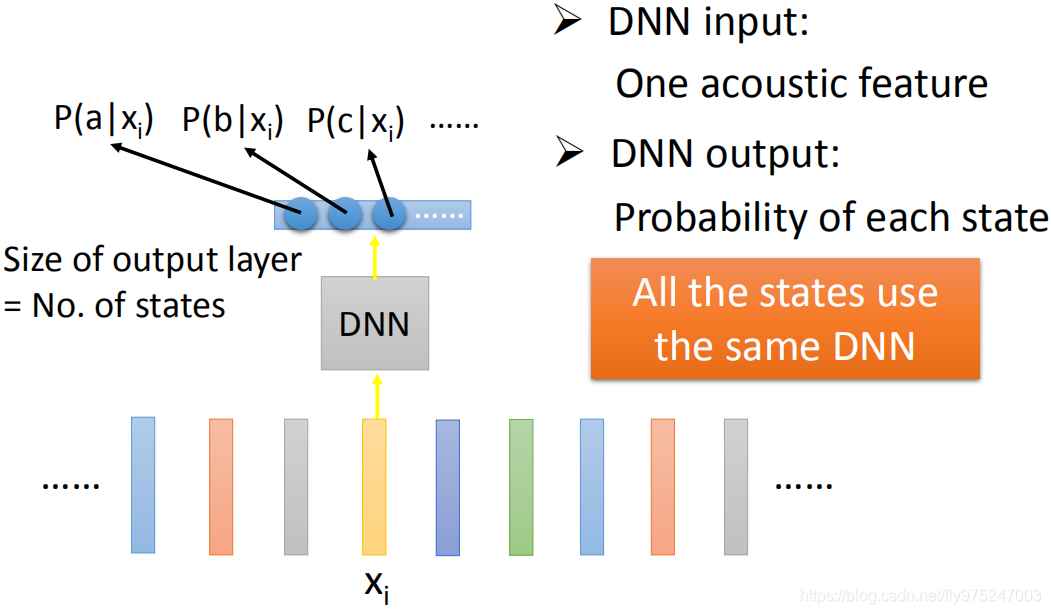
如果是deep learning的话,那你就是去learn一个neural network,这个neural network的input就是一个acoustic feature,output就是这个feature属于每一个state的几率。就是一个很单纯classification probably跟作业上做的影像是没有差别的。learn一个DNN,input是一个acoustic feature,然后output就是告诉你说,acoustic feature属于每个state的几率,那最关键的一点是所有的state都共用同一个DNN,在这整个辨识里面就做一个DNN而已,你没有每一个state都有一个DNN。
所以就有人说,有些人是没有想清楚的这个deep learning到底是power在哪里,从GMM到deep learning厉害的地方就是本来GMM通常也就64Gauusian matrix,那DNN有10层,每层都有1000个neural,参数很多,参数变多performance就会变好,这是一种暴力碾压的方法。
其实DNN不是暴力碾压的方法,你仔细想想看,在做HMM-GMM的时候,你说GMM有64个matrix觉得很简单,那其实是每一个state都有一个Gauusian matrix,真正合起来那参数是多的不得了的。如果你仔细去算一下GMM用的参数和DNN用的参数,在不同的test去测这件事情,他们的参数你就会发现几乎是差不多多的。DNN几乎是一个很大的model,GMM是很多很小的model,但将这两个比较参数量是差不多多的。但是DNN是将所有的state通通用同一个model来做分类,会使有效率的方法。
两种方法的对比 GMM v.s. DNN
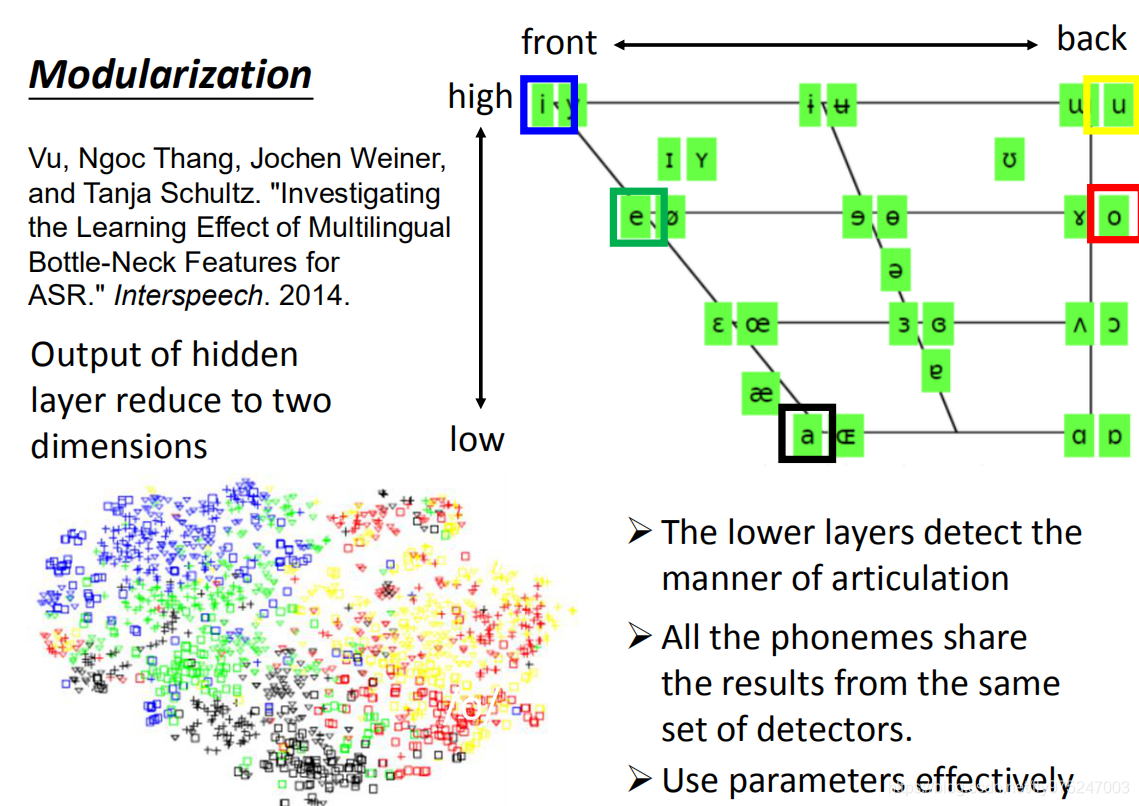 举例来说,如果你今天把一个DNN它的某一个hidden layer拿出来,然后把那个hidden layer假设有1000个neural你没有办法分析它,但是你可以把那1000个layer的output降维降到二维。所以在这个图上面呢,一个点代表一个acoustic feature,然后它通过DNN以后,把这个output降到二维,可以发现它的分布是这样的。
举例来说,如果你今天把一个DNN它的某一个hidden layer拿出来,然后把那个hidden layer假设有1000个neural你没有办法分析它,但是你可以把那1000个layer的output降维降到二维。所以在这个图上面呢,一个点代表一个acoustic feature,然后它通过DNN以后,把这个output降到二维,可以发现它的分布是这样的。
在这个图上的颜色代表什么意思呢?这边颜色其实就是a,e,i,o,u这样,特别把这五个母音跟左边这个图用相同的颜色框起来。那你会神奇的发现,左边这五个母音的分布跟右边的图几乎是一样的。所以你可以发现DNN做的事情比较low layer的事情它其实是在它并不是真的要马上去侦测这个发音是属于哪个state。它的做事是它先观察说,当你听到这个发音的时候,人是用什么方式在发这个声音的,它的石头的位置在哪里(舌头的位置是高还是低呢,舌头位置是在前还是后呢等等)。然后lower layer比较靠近input layer先知道发音的方式以后,接下来的layer在根据这个结果去说现在的发音是属于哪个state/phone。所以所有的phone会用同一组detector。也就是这些lower layer是人类发音方式的detector,而所有phone的侦测都用是同一组detector完成的,所有phone的侦测都share(承担)同一组的参数,所以这边就做到模组化这件事情。当你做模组化的事情,你是要有效率的方式来使用你的参数。
普遍性定理
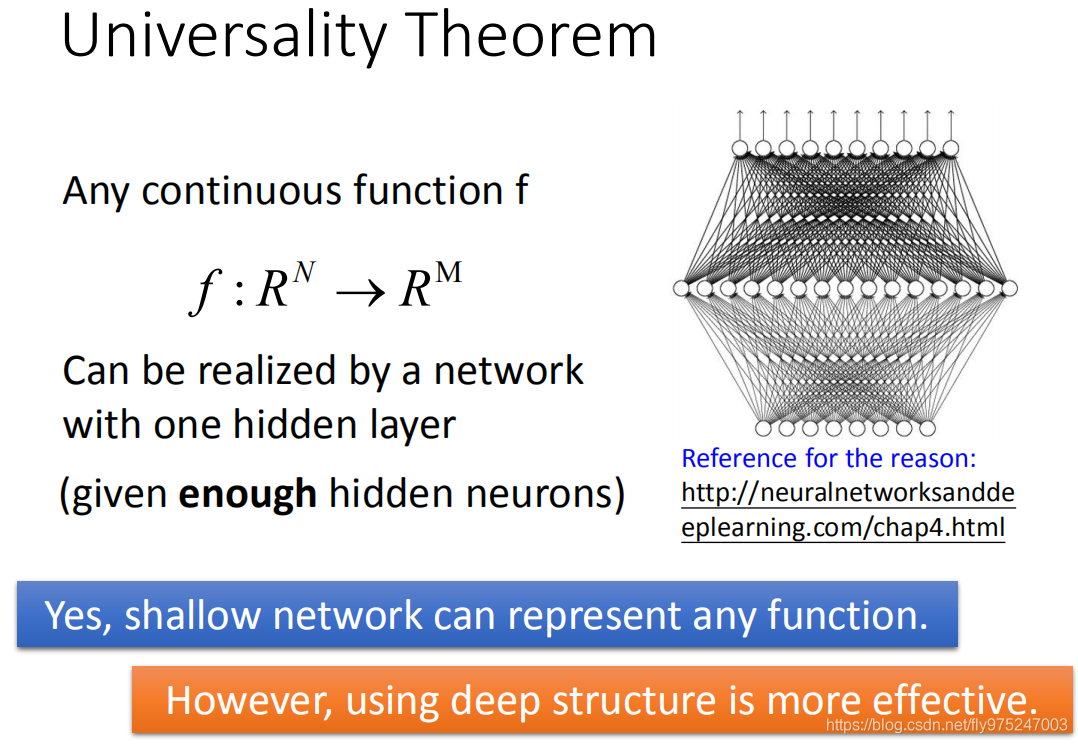
过去有一个理论告诉我们说,任何continuous function,它都可以用一层neural network来完成(只要那一层只要够宽的话)。这是90年代,很多人放弃做deep learning的原因,只要一层hidden layer就可以完成所有的function(一层hidden layer就可以做所有的function),那做deep learning的意义何在呢?,所以很多人说做deep是很没有必要的,我们只要一个hidden layer就好了。
但是这个理论没有告诉我们的是,它只告诉我们可能性,但是它没有告诉我们说要做到这件事情到底有多有效率。没错,你只要有够多的参数,hidden layer够宽,你就可以描述任何的function。但是这个理论没有告诉我们的是,当我们用这一件事(我们只用一个hidde layer来描述function的时候)它其实是没有效率的。当你有more layer(high structure)你用这种方式来描述你的function的时候,它是比较有效率的。
举例
使用逻辑电路举例
Analogy(当你刚才模组化的事情没有听明白的话,这时候举个例子)
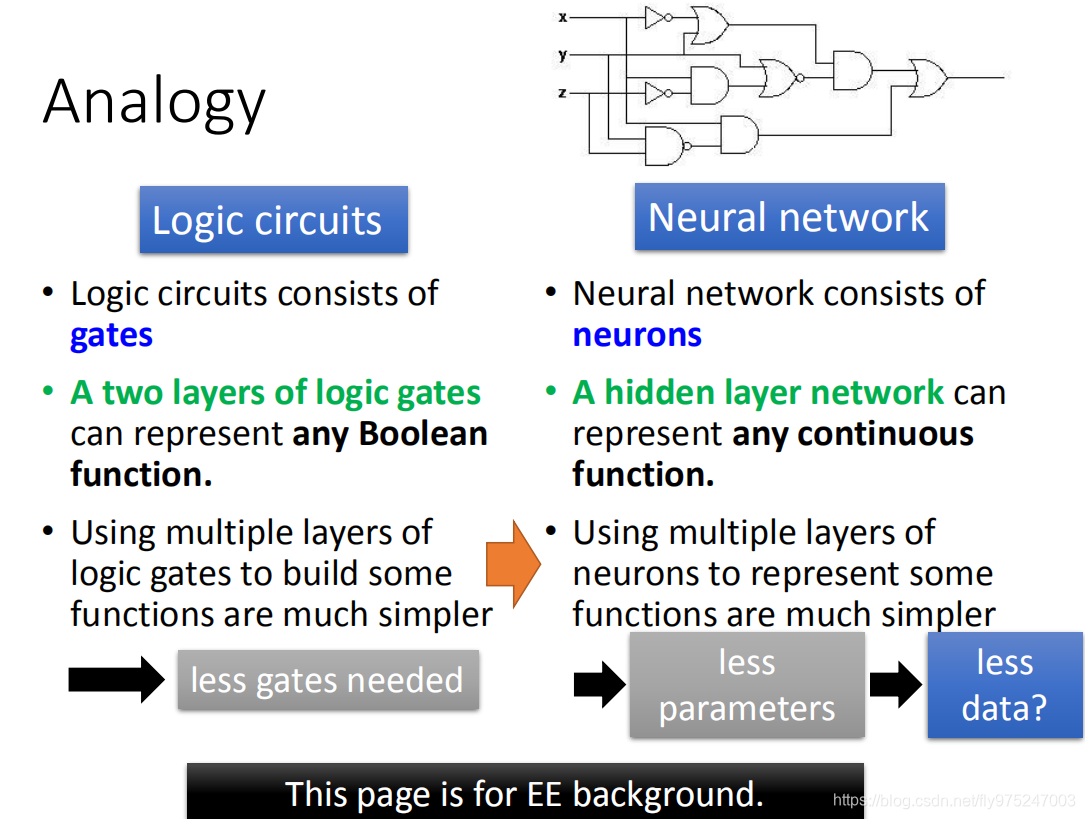
逻辑电路(logistic circuits)跟neural network可以类比。在逻辑电路里面是有一堆逻辑闸所构成的在neural network里面,neural是有一堆神经元所构成的。若你有修过逻辑电路的话,你会说其实只要两层逻辑闸你就可以表示任何的Boolean function,那有一个hidden layer的neural network(一个neural network其实是两层,input,output)可以表示任何的continue function。
虽然我们用两层逻辑闸就描述任何的Boolean function,但实际上你在做电路设计的时候,你根本不可能会这样做。当你不是用两层逻辑闸而是用很多层的时候,你拿来设计的电路是比较有效率的(虽然两层逻辑闸可以做到同样的事情,但是这样是没有效率的)。若如果类比到neural network的话,其实是一样的,你用一个hidden layer可以做到任何事情,但是用多个hidden layer是比较有效率的。你用多层的neural network,你就可以用比较少的neural就完成同样的function,所以你就会需要比较少的参数,比较少的参数意味着不容易overfitting或者你其实是需要比较少的data,完成你现在要train的任务。(很多人的认知是deep learning就是很多data硬碾压过去,其实不是这样子的,当我们用deep learning的时候,其实我们可以用比较时少的data就可以达到同样的任务)
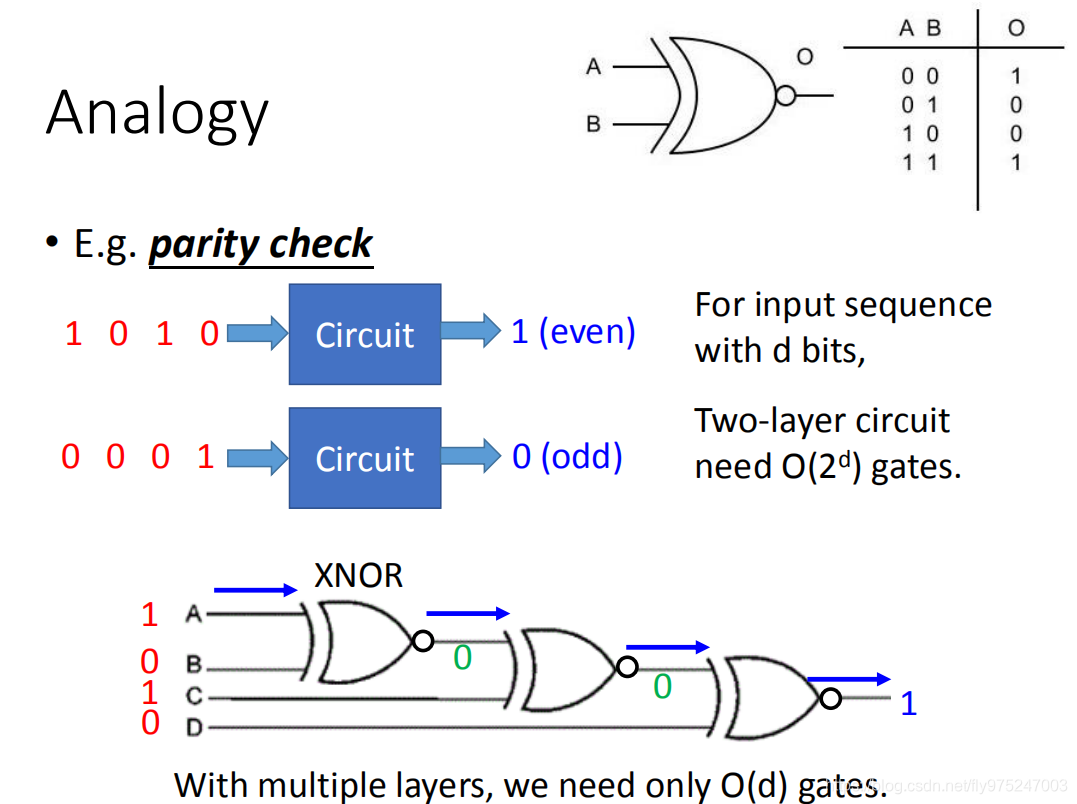
那我们再从逻辑闸举一个实际的例子,假设我们要做parity check(奇偶性校验检查)(你希望input一串数字,若如果里面出现1的数字是偶数的话,它的output就是1;如果是奇数的话,output就是0).假设你input sequence的长度总共有d个bits,用两层逻辑闸,理论可以保证你要
次方的gates才能描述这样的电路。但是你用多层次的架构的话,你就可以需要比较少的逻辑闸就可以做到parity check这件事情,
举例来说,你可以把好几个XNOR接在一起(input和output真值表在右上角)做parity check这件事。当你用多层次的架构时,你只需要 gates你就可以完成你现在要做的这个任务,对neural network来说也是一样的,可以用比较的neural就能描述同样的function。
使用剪窗花举例

一个日常生活中的例子,这个例子是剪窗花(折起来才去剪,而不是真的去把这个形状的花样去剪出来,这样就太麻烦了),这个跟deep learning有什么关系呢?
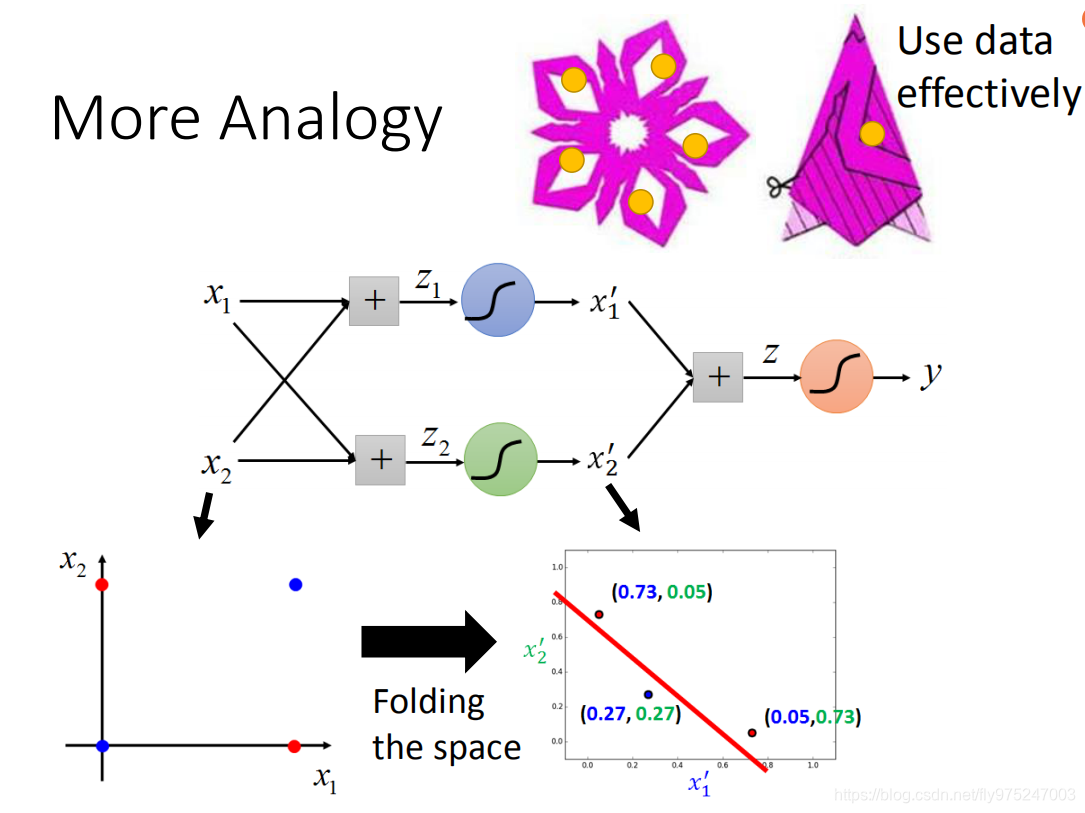
这个跟deep learning 有什么关系呢,我们用之前讲的例子来做比喻,假设我们现在input的点有四个(红色的点是一类,蓝色的点是一类)。我们之前说,如果你没有hidden layer的话,如果你是linear model,你怎么做都没有办法把蓝色的点和红色的点分来开,当你加上hidden layer会发生怎样的事呢?当你加hidde layeer的时候,你就做了features transformation。你把原来的
,
转换到另外一个平面
plane,
plane(蓝色的两个点是重合在一起的,如右图所示),当你从左下角的图通过hidden layer变到右下角图的时候,其实你就好像把原来这个平面对折了一样,所以两个蓝色的点重合在了一起。这就好像是说剪窗花的时候对折一样,如果你在图上戳一个洞,那么当你展开的时候,它在这些地方都会有一些洞(看你对折几叠)。如果你把剪窗花的事情想成training。你把这件事想成是根据我们的training data,training data告诉我们说有画斜线的部分是positive,没画斜线的部分是negative。假设我们已经把这个已经折起来的时候,这时候training data只要告诉我们说,在这个范围之内(有斜线)是positive,在这个区间(无斜线)展开之后就是复杂的图样。training data告诉我们比较简单的东西,但是现在有因为对折的关系,展开以后你就可以有复杂的图案(或者说你在这上面戳个洞,在就等同于在其他地方戳了个洞)。
所以从这个例子来看,一笔data,就可以发挥五笔data效果。所以,你在做deep learning的时候,你其实是在用比较有效率的方式来使用你的data。你可能很想说真的是这样子吗?我在文件上没有太好的例子。所以我做了一个来展示这个例子。
使用二位坐标举例
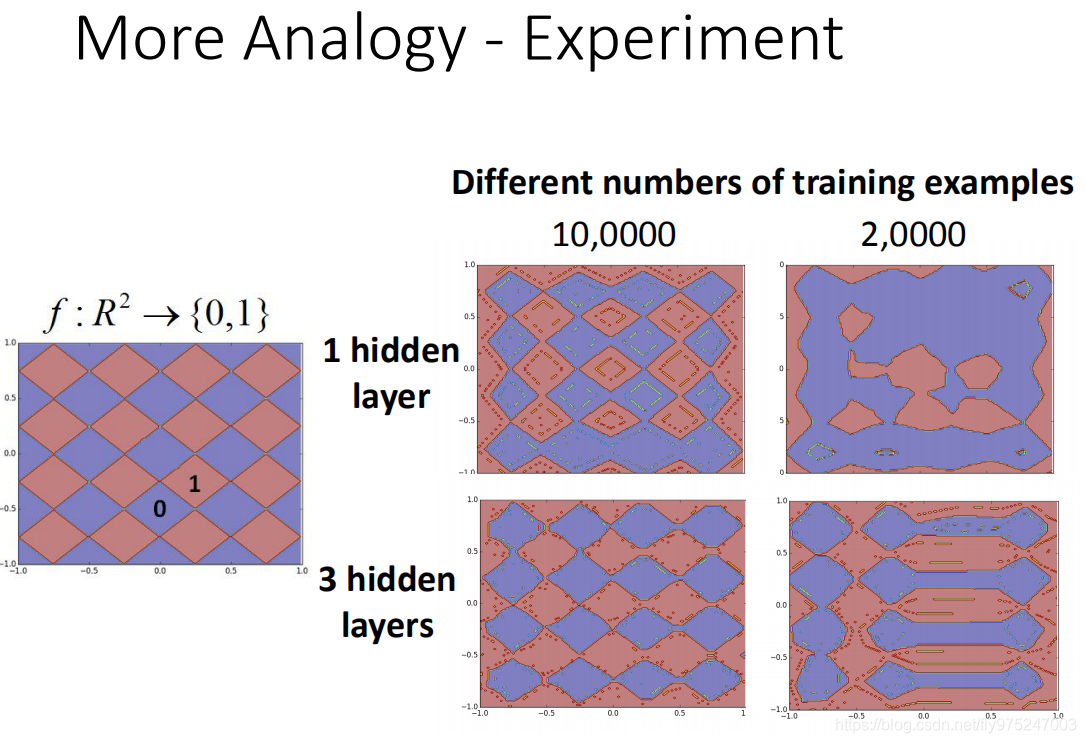
我们有一个function,它的input是二维
(坐标),它的output是{0,1},这个function是一个地毯形式的function(红色菱形的output就要是1,蓝色菱形output就要是0)。那现在我们要考虑如果我们用了不同量的training example在1个hidden layer跟3个hidden layer的时候。我们看到了什么的情形,这边要注意的是,我们要特别调整一个hidden layer和3个hidden layer的参数,所以并不是说当我是3个hidden layer的时候,是一个hidden layer的network。(这1个neural network是一个很胖的neural network,3个hidden layer是一个很瘦的neural network,他们的参数是要调整到接近的)
那现在这边是要有10万笔data的时候,这两个neural都可以learn出这样的train data(从这个train data sample 10万笔data然后去给它学,它学出来就是右边这样的)
那现在我们减小参数的量,减少到只用2万笔来做train,这时候你会发现说,你用一个hidden lyaer的时候你的结果的就崩掉了,但如果是3个hidden layer的时候,你的结果变得只是比较差(比train data多的时候要差),但是你会发现说你用3个hidden layer的时候是有次序的崩坏。这个结果(最右下角)就像是你今天要剪窗花的时候,折起来最后剪坏了,展开以后成这个样子。你会发现说在使用比较少的train data的时候,你有比较多的hidden layer最后得到的结果其实是比较好的。
端到端的学习
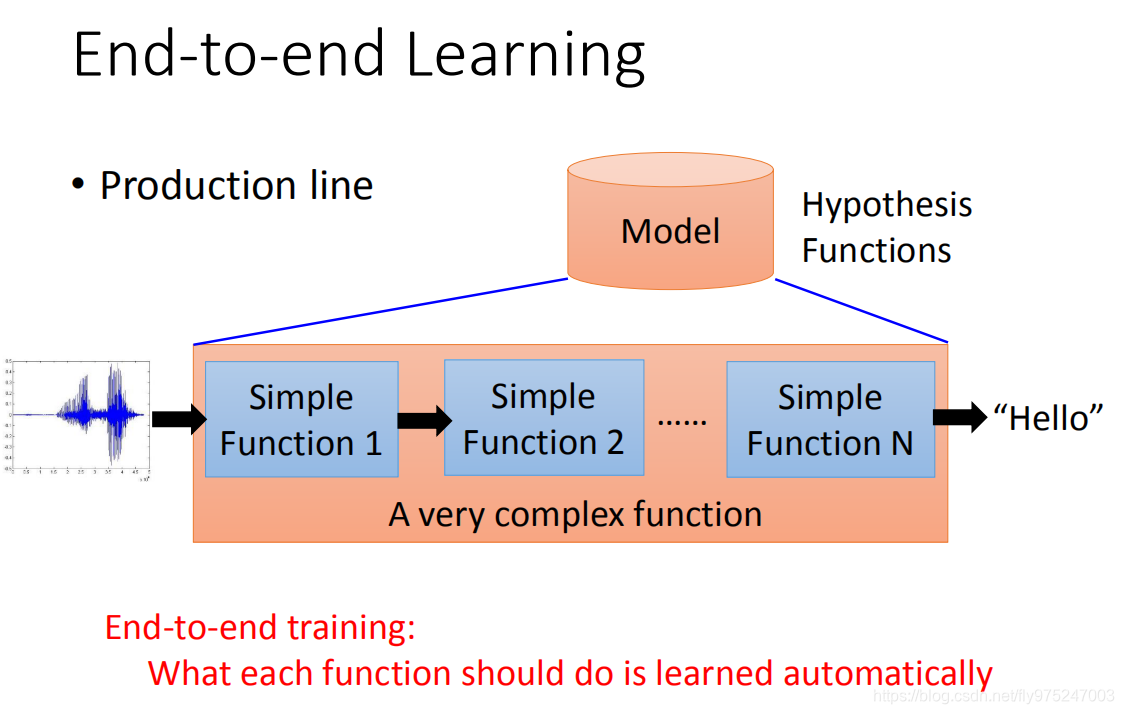
当我们用deep learning的时候,另外的一个好处是我们可以做End-to-end learning。
所谓的End-to-end learning的意思是这样,有时候我们要处理的问题是非常的复杂,比如说语音辨识就是一个非常复杂的问题。那么说我们要解一个machine problem我们要做的事情就是,先把一个Hypothesis funuctions(也就是找一个model),当你要处理1的问题是很复杂的时候,你这个model里面它会是需要是一个生产线(由许多简单的function串接在一起)。比如说,你要做语音辨识,你要把语音送进来再到通过一层一层的转化,最后变成文字。当你多End-to-end learning的时候,意思就是说你只给你的model input跟output,你不告诉它说中间每一个function要咋样分工(只给input跟output,让它自己去学),让它自己去学中间每一个function(生产线的每一个点)应该要做什么事情。
那在deep learning里面要做这件事的时候,你就是叠一个很深的neural network,每一层就是生产线的每一个点(每一层就会学到说自己要做什么样的事情)
语音识别
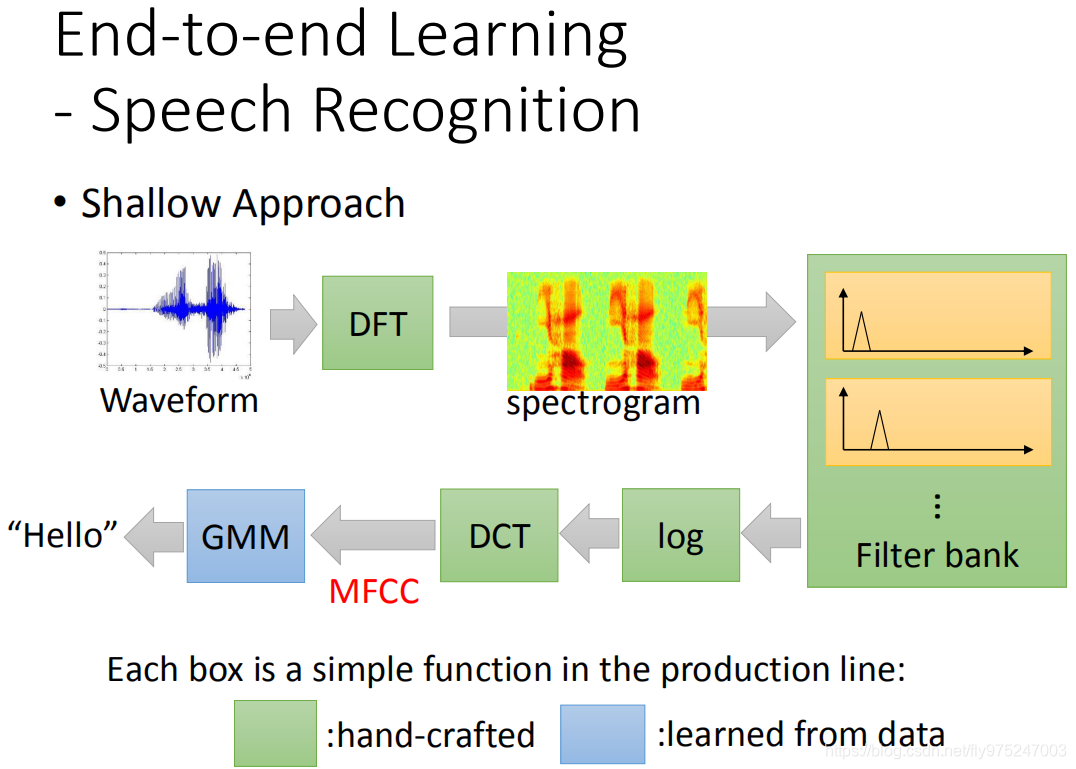 比如说,在语音辨识里面。还没有用deep learning的时候,我们怎么来做语音辨识呢,我们可能是这样做的。
比如说,在语音辨识里面。还没有用deep learning的时候,我们怎么来做语音辨识呢,我们可能是这样做的。
先有一段声音讯号(要把声音对应成文字),你要先做DF,你不知道这是什么也没有关系,反正就是一个function,变成spectogram,这个spectogram通过filter bank(不知道filter bank是什么,没有关系,就是生产线的另外一个点),最后得到output,然后再去log(取log是非常有道理的),然后做DCT得到MFCC,把MFCC丢到GMM里面,最后你得到语音辨识的结果。
只有最后蓝色的这个bank是用训练数据学出来的,前面这些绿色的这些都是人手定(研究人的生理定出了这些function)。但是后来有了deep learning以后,这些东西可以用neural network把它取代掉。你就把你的deep network多加几层就可以把DCT拿掉。现在你可以从spectogram开始做,你这这些都拿掉,通通都拿deep neural network取代掉,也可以得到更好的结果。deep learning它要做的事情,你会发现他会自动学到要做filter bank(模拟人类听觉器官所制定的filter)这件事情
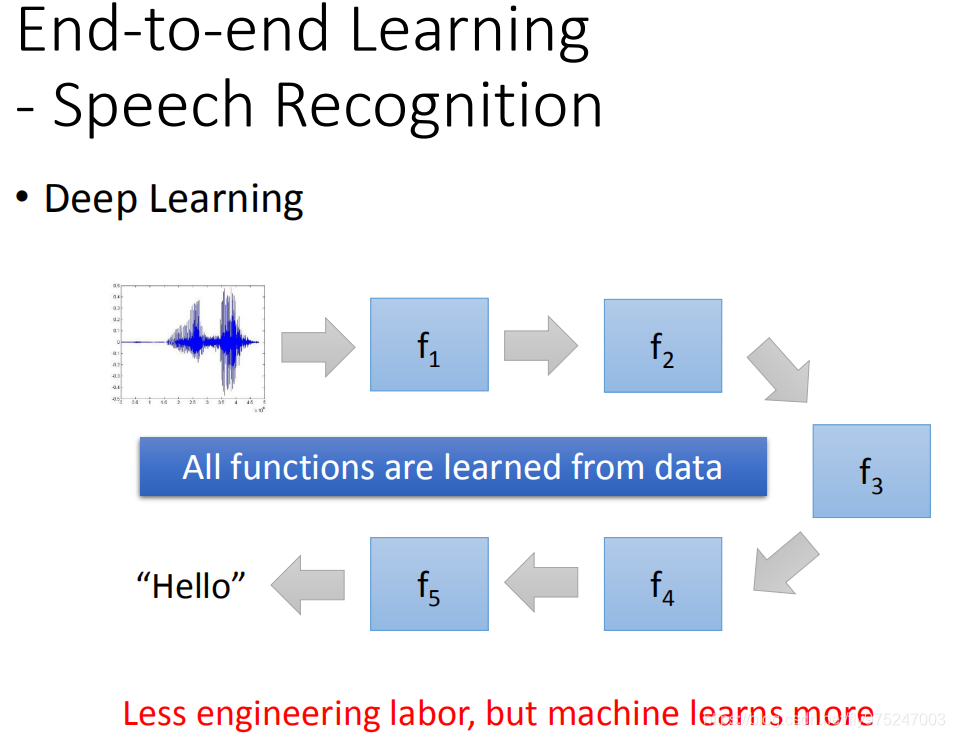
接下来就有人挑战说我们可不可以叠一个很深很深的neural network,直接input就是target main声音讯号,output直接就是文字,中间完全就不用做,那就不需要学信号与系统
Google 有一篇paper是这样子,它最后的结果是这样子的,它拼死去learn了一个很大neural network,input就是声音讯号,完全不做其它的任何事情,它最后可以做到跟有Fourier transform的事情打平,也仅次于打平而已。我目前还没看到input一个声音讯号,比Fourier transform结果比这要好的。
图像识别
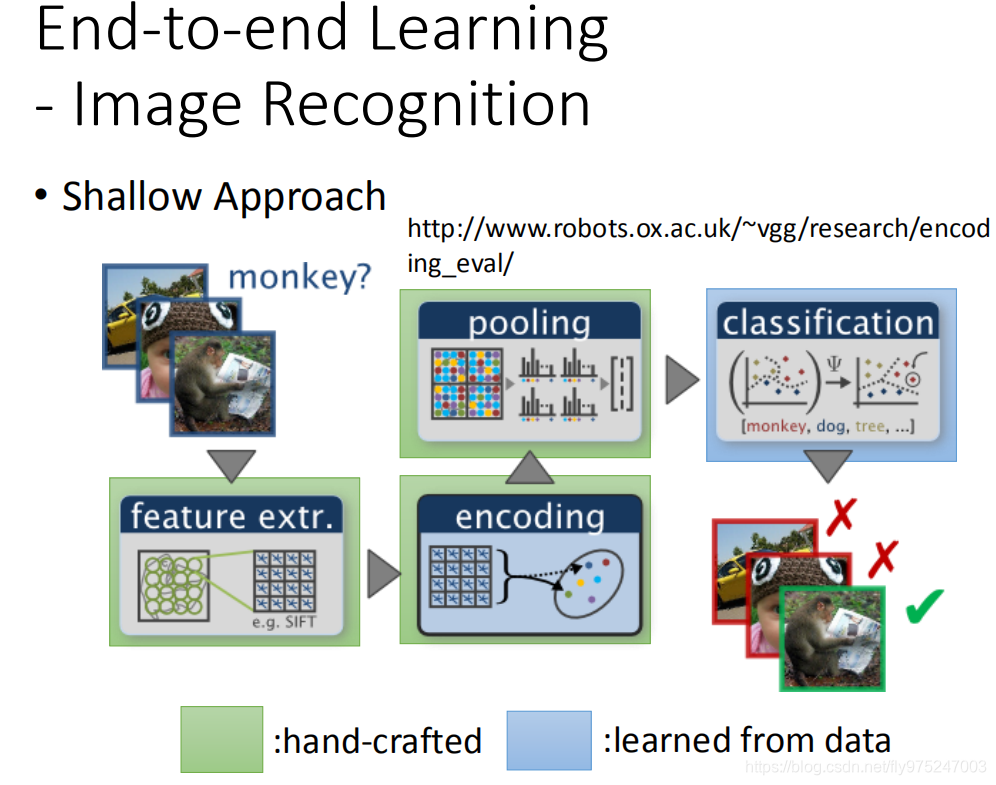
刚刚都是讲语音的例子,影像也是差不多的。大家也都知道,我们就跳过去(过去影像也是叠很多很多的graph在最后一层用比较简单的classifier)
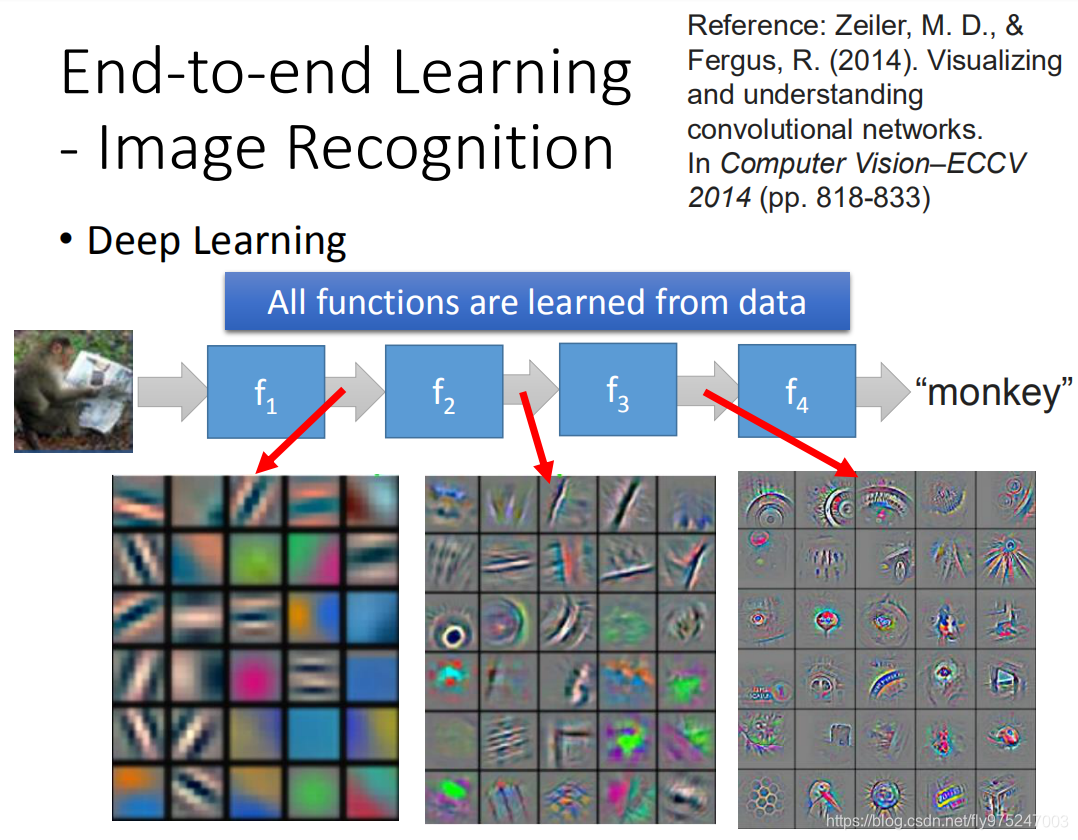
那现在用一个很深的neural,input直接是piexel,output里面是影像是什么
更复杂的任务
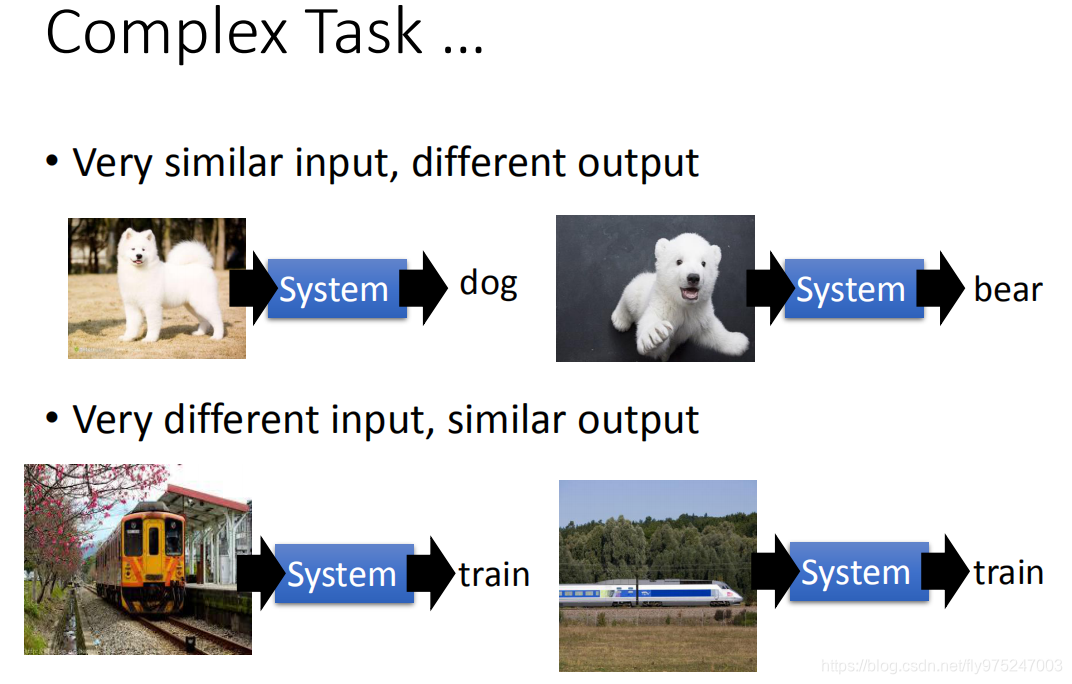
那deep learning还有什么好处呢。通常我们在意的task是非常复杂的,在这非常复杂的task里面,有非常像的input,会有很不同的output。举例来说,在做影视辨识的时候,白色的狗跟北极熊看起来很像,但是你的machine左边要outp dog,右边要output bear。有时候很不一样的东西,其实是一样的,横着看火车和侧面看火车,他们其实是不一样,但是output告诉我说一样的。
今天的neural只有一层的话(简单的transform),你没有办法把一样的东西变成很不一样,把不一样的东西变的很像,原来input很像的东西结果看起来很不像,你要做很多层次的转换。
 举例来说,看这个例子(这个是语言的例子)。在这个图上,把MFCC投影到二维上,不同颜色代表的是不同的人说的话。在语音上你会发现说,同样的句子,不同人的说,它的声音讯号,看起来是不一样的(这个红色看起来跟蓝色看起来没关系,蓝色跟绿色没有关系)。有人看这个图,语音辨识不能做呀。不同的人说话太不一样了。
举例来说,看这个例子(这个是语言的例子)。在这个图上,把MFCC投影到二维上,不同颜色代表的是不同的人说的话。在语音上你会发现说,同样的句子,不同人的说,它的声音讯号,看起来是不一样的(这个红色看起来跟蓝色看起来没关系,蓝色跟绿色没有关系)。有人看这个图,语音辨识不能做呀。不同的人说话太不一样了。
如果你今天learn 一个neural network,如果你只要第一层的hidden layer的output,你会发现说,不同的人讲的同样的句子还是很不一样的。
但是你看第8个hidden layer output的时候, 你会发现说,不同的人说着同样的句子,它自动的被line在一起了,也就是说这个DNN在经过很多hidden layer转换的时候,它把本来看起来很不像的东西,它知道应该是一样的(map在一起了)。在右边的这个图上,你会看到一条一条的线,在这些线中你会看到不同颜色的声音讯号。也就是说不同的人说着同样的话经过8个hidden layer的转换以后,对neural network来说,它就变得很像。

手写数字辨识的例子,input feature是左上角这张图(28*28 pixel,把28 *28pixel project到二维平面的话就是左上角的图),在这张图上,4跟9几乎是叠在一起的(4跟9很像,几乎没有办法把它分开)。但是我们看hidden layer的output,这时候4跟9还是很像(离的很近),我们看第2个hidden layer的output(4,7,9)逐渐被分开了,到第三个hidden layer,他们会被分的更开。所以你今天要原来很像的input 最后要分的很开,那你就需要好多hidden layer才能办到这件事情
