PixelNet: Representation of the pixels, by the pixels, and for the pixels.

图1.我们的框架通过对架构(最后一层)和训练过程(历元)的微小修改,将其应用于三个不同的像素预测问题。 请注意,我们的方法为分割(左),表面法线估计(中)和边缘检测(右)的语义边界恢复精细的细节。
Abstract
我们探索了一般像素级预测问题的设计原理,从低级边缘检测到中级表面法线估计到高级语义分割。诸如全卷积网络(FCN)之类的卷积预测因子通过通过卷积处理利用相邻像素的空间冗余而获得了非凡的成功。尽管计算效率高,但我们指出,由于空间冗余限制了从相邻像素学习的信息,因此这些方法在学习过程中在统计上并不是有效的。 我们证明了像素的分层采样可以使(1)在批量更新过程中增加多样性,从而加快学习速度; (2)探索复杂的非线性预测因子,提高准确性; (3)有效地训练最先进的模型tabula rasa(即“从头开始”)以完成各种像素标记任务。 我们的单一体系结构可为PASCAL-Context数据集上的语义分割,NYUDv2深度数据集上的表面法线估计以及BSDS上的边缘检测提供最新结果。
1.Introduction
许多计算机视觉问题可以表述为密集的逐像素预测问题。 其中包括边缘检测[21、64、94]和光流[5、30、86]等低级任务,深度/正常恢复[6、24、25、81、89]等中级任务, 和高级任务,例如关键点预测[13、36、78、91],对象检测[43]和语义分割[16、27、40、62、67、82]。 尽管这种表述由于其通用性而具有吸引力,但一个明显的困难是巨大的相关输出空间。 例如,每个像素具有10个离散类标签的100×100图像产生大小为10的5次方的输出标签空间。 一种策略是将其视为空间不变的标签预测问题,其中使用卷积结构预测每个像素的单独标签。 具有卷积输出预测的神经网络,也称为完全卷积网络(FCN)[16、62、65、77],似乎是朝着这个方向发展的一种有前途的体系结构。
但这是密集像素标记的理想公式吗?虽然在测试时生成预测的计算效率很高,但我们认为对于基于梯度的学习,它在统计上不是有效的。随机梯度下降(SGD)假设训练数据是独立采样的,并且来自相同的分布(i.i.d.)[11]。确实,一种常用的启发式算法可确保大约i.d.样本是训练数据的随机排列,可以显着提高学习性[56]。众所周知,给定图像中的像素是高度相关的而不是独立的[45]。根据这一观察,可能会在学习过程中尝试随机排列像素,但这破坏了卷积架构如此巧妙地利用的空间规则性!在本文中,我们探索了卷积学习的统计效率与计算效率之间的折衷,并针对每个SGD批更新简单地研究了少量图像中少量像素的采样,并在可能的情况下利用了卷积处理。
贡献:(1)我们通过实验验证了由于像素之间的空间相关性,仅对每个图像采样少量像素就足以学习。更重要的是,采样使我们能够训练较早不可能的端到端特定非线性模型,并探索提高基于FCN架构的效率和性能的几种途径。 (2)与使用预训练网络的绝大多数模型相反,我们证明了像素级优化可用于训练模型tabula rasa,或通过简单的随机高斯初始化“从头开始”。直观地讲,像素级标签与图像级标签相比,具有适当的相关性,可提供大量的监督。在不使用任何额外数据的情况下,我们的模型在PASCAL VOC-2012上的语义分割性能优于先前的非监督/自我监督方法[ [26],并且比从用于表面法线估计的预训练模型进行微调更具竞争力。 (3)。使用单一架构且参数没有太多修改,我们展示了BSDS上边缘检测的最新性能[4],NYUDv2深度数据集上的表面法线估计[83]和PASCAL-Context数据集上的语义分割[68]。
2.Background
在本节中,我们将使用将用于描述我们的体系结构的统一符号来回顾相关工作。 我们解决了逐像素预测问题,在给定输入图像X的情况下,我们试图预测输出Y。 对于像素位置p,输出可以是二进制Y p∈{0,1}(例如,边缘检测),多类Y p∈{1,…,K}(例如,语义分割)或实数- 值Y p∈RN(例如,表面法线预测)。 在使用手工设计的特征对该预测问题进行建模的过程中,有很多现有技术(代表性示例包括[3、14、21、38、59、69、80、82、87、88、96])。
卷积预测:我们探索可在模型参数θ上端对端训练的空间不变预测因子fθ,p(X)。 全卷积和跳过网络[65、77]是说明性示例,已成功应用于例如边缘检测[94]和语义分割[12、16、27、30、62、60、67、71 ,75]。 由于此类架构仍会为每个像素生成单独的预测,因此许多方法探索了后处理步骤,这些步骤可通过例如使用完全连接的高斯CRF [16、52、101]或双边求解器[8]进行双边平滑来在标签之间实现空间一致性。 扩张空间卷积[97],LSTM [12]和卷积伪先验[93]。 相反,我们的工作没有利用这种上下文后处理,而是试图了解纯“像素级”体系结构可以推广到什么程度。
多尺度特征 较高的卷积层通常与捕获高级全局上下文的较大接受域相关。 由于此类特征可能会漏掉底层细节,因此许多方法都基于从CNN的多层中提取的多尺度特征构建了预测器[19,24,25,27,75,89]。 Hariharanetal[40] 使用令人联想起“超级列”的术语是指从对应于同一像素的多层提取的特征。 让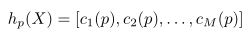
表示针对像素p计算的多尺度超列特征,其中c i(p)表示以像素p为中心的第i层的卷积响应的特征向量(并且其中我们明确依赖X来减少混乱)。 用于上采样的现有技术包括移位和缝合[62],将卷积滤波器转换为扩张运算[16](受算法[63]启发)以及解卷积/解卷积[30、62、71]。 我们同样利用多尺度功能以及稀疏按需对滤波器响应进行上采样,以减少学习过程中的内存占用。
像素预测 可以将像素逐个预测问题转换为对超列特征进行操作
我们写θ来表示超列特征h和像素级预测变量g的两个参数。训练涉及通过SGD向后传播梯度以更新θ。先前的工作已经探索了h和g的不同设计。一种主要趋势是定义超柱特征的线性预测因子,例如g = w·h p。 FCN [62]指出,可以通过对粗略预测(使用反卷积)进行上采样而不是对粗略特征进行上采样,以从粗到精的方式有效地执行线性预测。 DeepLab [16]结合了滤波器膨胀,并应用了类似的去卷积和线性加权融合,此外还降低了全连接层的尺寸以减少内存占用。 ParseNet [60]通过平均合并要素响应(随后进行归一化和串联)为图层的响应添加了空间上下文。 HED [94]输出来自中间层的边缘预测,这些预测受到深度监督,并通过线性加权融合预测。重要的是,[67]和[27]是线性趋势的明显例外,因为使用了非线性预测变量g。这确实在学习过程中带来了困难-[67]由于内存限制,预先计算并存储了超像素特征图,因此无法进行端到端的训练。
采样 我们证明了对超柱特征的稀疏采样允许探索高度非线性的g,这反过来大大提高了性能。我们的见解受到了过去使用采样来训练网络进行表面法线估计[6]和图像着色[55]的方法的启发。 尽管我们通过分析采样对效率,准确性和表格形式学习对各种任务的影响来关注一般设计原则。
加速SGD:有大量关于加速随机梯度下降的文献。 我们推荐读者参考[11]进行出色的介绍。 尽管自然地是一次处理一次数据示例的顺序算法,但最近的工作集中在可以利用GPU架构[18]或集群[18]中的并行性的小批量方法。 一个通用的主题是二阶方法的有效在线逼近[10],它可以对输入特征之间的相关性进行建模。 批次归一化[46]计算批次中样本之间的相关统计量,从而显着提高收敛速度。我们的工作直接在卷积网络中建立了类似的见解,而没有明确的二阶统计量。

图2. PixelNet:我们将图像输入到卷积神经网络,并从多个卷积层提取采样像素的超列描述符。 然后,将超列描述符输入到多层感知器(MLP)进行非线性优化,并且MLP的最后一层输出任务所需的响应。 有关在培训/测试时使用网络的更多详细信息,请参见文本。
** 3.PixelNet**
本节将利用上一节介绍的符号描述我们的像素预测方法。 我们首先将像素化预测架构形式化,然后讨论统计有效的小批量训练。
体系结构:与过去的工作一样,我们的体系结构利用了多尺度卷积特征,我们将其写为超列描述符:
hp = [c1 §,c2 §,…,cM §]
我们学习了非线性预测因子fθ,p = g(hp),它被实现为在超柱特征上定义的多层感知器(MLP)[9]。 我们使用MLP,可以将其实现为一系列“完全连接”的层,再加上ReLU激活功能。 重要的是,最后一层的大小必须为K,要预测类标签或实值输出的数量。 参见图2。
1.稀疏预测:我们现在描述一种生成稀疏像素预测的有效方法,该方法将在训练时使用(用于有效的小批量生成),假设给定了图像X和稀疏集的(采样的)像素位置 P⊂,其中Ω是所有像素位置的集合。
2.执行前向遍历以计算所有层上的密集卷积响应{c i(p):∀i,p∈Ω}
对于每个采样像素p∈P,按需计算其超列特征h p,如下所示:
(a)对于每一层i,计算特征图c i中最接近p的4个离散位置
(b)通过双线性插值计算c i(p)
3.将稀疏的超列特征{h p:p∈P}重新排列为矩阵以进行下游处理(例如MLP分类)。
上面的管道仅计算| P | 超列特征而不是|||大小的全密集。 我们通过实验证明,这种方法在摊销计算(计算c i(p))和减少的存储量(计算h p)之间提供了极好的折衷。 请注意,我们的多尺度采样层意味着充当选择操作,可以轻松定义(子)梯度。 这意味着反向传播还可以利用非线性MLP层的稀疏计算和较低层的卷积处理。
小批量采样: 在SGD训练的每次迭代中,**通过计算训练集中相对较小的一组样本上的梯度,可以近似模型参数θ上的真实梯度。**基于FCN的方法[62]包含小批量图像中所有像素的特征。由于图像中附近的像素高度相关[45],因此对它们进行采样不会损害学习。为了确保像素集的多样性(同时仍享受卷积处理的摊销收益),我们为每个图像使用了适度的像素数量(约2,000个),但每批采样了许多图像。超列描述符的密集网格的朴素计算几乎占用了所有(GPU)内存,而使用我们的稀疏采样层则需要进行2,000个采样。这使我们能够每批探索更多图像,从而大大增加了样品的多样性。
密集预测: 我们现在介绍一种通过网络生成密集像素预测的有效方法,该方法将在测试时使用。密集预测从上方进行以下步骤(1)而不是在上面的(2)中进行采样,我们现在获取所有像素。这产生了一个超列特征的密集网格,然后由实现为1x1滤镜(代表每个完全连接的层)的逐像素MLP处理(3)。此计算的内存密集型部分是超列特征的密集网格。该内存占用空间在测试时是合理的,因为一次可以处理一个图像,但是在训练时,我们希望对包含尽可能多图像的批次进行训练(以确保多样性)。
4.Analysis
在本节中,我们将使用语义分割和表面法线估计来分析像素级优化的属性,以了解像素级体系结构的设计选择。我们选择了两个不同的任务(分类和回归)进行分析,以验证这些发现的一般性。我们使用单比例尺224×224图像作为输入。我们还显示,通过谨慎的批归一化进行增强的采样可以允许从头开始训练模型(无需预先训练的ImageNet模型作为初始化),以进行语义分割和表面法线估计。我们将在第5节中将我们的方法的性能与以前的方法进行显式比较。
默认网络:对于大多数实验,我们都会微调VGG-16网络[84]。 VGG-16具有13个卷积层和3个全连接(fc)层。卷积层被表示为{1 1,1 2,2 1,2 2,3 1,3 2,3 3,4 1,4 2,4 3,5 1,5 2,5 3}。按照[62],我们将最后两个fc层转换为卷积滤波器1,并将它们添加到可以聚合到我们的多尺度超列描述符中的卷积特征集。为避免与MLP中的fc层混淆,此后我们将VGG-16的fc层表示为conv-6和conv-7。我们使用以下网络体系结构(除非另有说明):通过按需插值从conv- {1 2,2 2,3 3,4 3,5 3,7}中提取超列特征。我们在3个大小为4,096的完全连接(fc)层的超列特征上定义MLP,然后进行ReLU [53]激活,其中最后一层输出针对K类的预测(具有softmax /交叉熵损失)或具有回归的欧几里得损失。
语义分割:我们使用来自PASCAL VOC-2012 [26]的训练图像进行语义分割,以及Hariharan等人在8498图像上收集的其他标签。 [41]。我们使用保留(非重叠)验证集来显示大多数分析。但是,在某些地方,我们使用了测试集,希望与以前的方法进行比较。我们使用在类上平均的区域交叉联合(IoU)的标准指标来报告结果(越高越好)。当使用验证集进行评估时,我们将其称为IoU(V),在测试集上显示时,我们将其称为IoU(T)。
表面法线估计:NYU Depth v2数据集[83]用于评估表面法线贴图。
有1449张图像,其中795张为训练图像,其余654张用于评估。 此外,还有从原始Kinect数据中提取的220,000帧。 我们使用根据Kinect的深度数据计算得出的Ladickyetal。[54]和Wangetal。[89]的法线分别作为1449张图像和220K张图像的地面真实性。 我们针对预测的法线与基于深度的法线之间的角度误差计算了六个统计信息,以前由[6,24,31,32,33,89]使用过,以评估性能–均值,中位数,RMSE,11.25和22.5 ◦和30◦-前三个条件捕获角度误差的平均值,中位数和RMSE,其中越低越好。 最后三个条件捕获给定角度误差内的像素百分比,越高越好。

图3.给定每SGD批次固定(5)张图像,我们使用所有像素与随机采样4%或2,000个像素进行语义分割和表面法线估计来分析会聚属性。 该实验表明采样不会损害收敛。
4.1Sampling
我们研究了从一组固定的图像中采样几个像素如何不会损害收敛。给定每批(5)张图像的固定数量,我们发现对每张图像采样一小部分像素(4%)不会影响可学习性(图3和表1)。这证实了我们的假设,即一个像素级任务的许多训练数据在图像中相关,这意味着随机采样几个像素就足够了。我们的结果与Long等人报道的结果一致。 [62],他类似地检查了每个训练图像采样一小部分(25-50%)补丁的效果。
Long等。 [62]还执行了一个额外的实验,其中当比较不同的采样策略时,一批像素的总数保持恒定。虽然这可以确保每个批次包含更多不同的像素,但是每个批次还将处理大量图像。如果由于采样而没有显着的计算节省,则其他图像将增加时钟时间并降低收敛速度。在下一节中,我们展示了在采样后添加额外的计算(通过用多层感知器替换线性分类器)从根本上改变了这种权衡(表4)。

4.2. Linear vs. MLP
先前的大多数方法都集中于将来自不同卷积层(也称为“跳过连接”)的信息进行组合的线性预测变量。在这里,我们将通过MLP的非线性模型与相应的线性模型的性能进行对比。对于此分析,我们使用VGG-16(在ImageNet上进行了预训练)作为初始化,并使用来自conv- {1 2,2 2,3 3,4 3,5 3,7}层的跳过连接以显示其好处我们在每个SGD迭代中从五个224×224图像的集合中随机采样每个图像2,000个像素,以进行优化。
使用跳过连接的主要挑战是如何随着动态范围在不同层上的变化而合并信息。表2的首行显示了在线性模型中“天真”地连接来自不同卷积层的要素时,该模型如何导致退化的语义分割输出。 [60]也有类似的观察。为了解决这个问题,以前的工作探索了归一化[60],缩放[40]等。我们在对卷积层进行串联之前使用批归一化[46],以使用线性预测变量正确地训练模型。表2的中间行显示了添加批归一化如何使我们能够训练线性模型进行语义分割,并提高表面法线估计的性能。虽然我们必须注意线性模型的归一化,但在使用MLP时不需要它们,并且可以天真地连接来自不同层的要素。表2的最后一行显示了使用MLP时不同任务的性能。请注意,线性模型的性能(具有批归一化)与Hypercolum [40](62.7%)和FCN [62](62%)获得的性能相似。
反卷积与按需计算:我们方法的一个简单实现是使用反卷积层对卷积层进行升采样,然后进行特征级联,并掩盖像素级输出。这类似于Long等人的抽样实验。 [62]。虽然对于线性模型是合理的,但是如果在超列描述符中包含conv-7(数组维数超过INT MAX),则天真地计算密集的超列描述符网格并使用MLP处理它们是不可能的。实用目的,如果我们考虑跳过连接仅从conv- {1 2,2 2,3 3,4 3,5 3}层中以牺牲一些性能为代价,与我们的方法相比,幼稚的反卷积仍将占用超过12倍的内存。稍好一点的是在MLP处理之前掩盖超列描述符的密集网格,这仍然要贵8倍。大多数计算节省是由于不需要保留去卷积和串联运算符所需的数据的额外副本。表3突出显示了反卷积与按需计算之间的计算要求差异(对于{1 2,3 3,5 3}层超柱特征的更宽容设置)。显然,按需计算需要更少的资源。
统计多样性重要吗?现在,我们在给定固定计算预算(NVIDIA TITAN-X上为7GB内存)的情况下分析统计多样性对优化的影响。我们使用1张图像×40,000像素/每张图像5张图像×2,000像素/每张图像来训练非线性模型。表4显示,从更多图像中采样更少的像素胜过从更少图像中提取更多像素。这表明使用MLP分类器时,统计多样性超过了卷积处理中的计算节省。


4.3. Training from scratch

训练深层模型的主要方法是使用预先训练的模型(例如ImageNet [79])作为初始化,以便对当前任务进行微调。大多数网络体系结构(包括我们的网络体系结构)都通过预训练的模型提高了性能。一个主要的问题是是否有足够的数据来训练用于像素级预测问题的深度模型。但是,由于我们的优化基于随机采样的像素而不是图像,因此SGD可能会有更多唯一数据可用于从随机初始化中学习模型。我们展示了采样和批处理规范化如何使模型从头开始训练。这使我们的网络可用于训练数据有限或自然图像数据不适用的问题(例如,分子生物学,组织分割等[70,95])。我们将证明我们的结果也对无监督的表示学习有影响[1,20,23,34,37,48,57,55,66,72,73,74,76,90,99,100]。
随机初始化:我们从高斯分布中随机初始化VGG16网络的参数。训练VGG-16网络架构不是直截了当的,并且需要对图像分类任务进行阶段性的训练[84]。从头开始为像素级任务训练这样的模型似乎很艰巨,在此我们要学习粗略和精细的信息。在我们的实验中,我们发现批量归一化是收敛从头开始训练的模型的有效工具。
我们训练语义分割和表面法线估计的模型。表5的中间行显示了从头开始训练的语义分割和表面法线估计的性能。从头开始训练的用于表面法线估计的模型在当前最新执行方法的2-3%之内。从头开始训练时,语义分段模型在PASCAL VOC-2012测试集中达到了48.7%。据我们所知,这些是从头开始训练时在这两个任务上报告的最好的数字,并且超过了需要额外ImageNet数据的其他非监督/自我监督方法[20、55、74、90、99]的性能[79]。
通过几何进行自我监督:我们简要介绍了在自我监督的情况下通过像素级优化训练的模型的性能。表面法线估计的任务不需要任何人工标记,并且主要是有关捕获几何信息的。在本节中,我们探讨了微调几何模型(从头开始训练)对更多语义任务(例如语义分割和对象检测)的适用性。表5(最后一行)和表6显示了我们的方法在以下方面的性能:分别是语义分割和对象检测。请注意,NYU深度数据集是一个小的室内场景数据集,并且不包含PASCAL VOC数据集中存在的大多数类别。尽管如此,相对于原始的刮擦模型,它显示了4%(细分)和9%(检测)的改进。以无监督/自我监督的方式进行语义分割的最佳结果是众所周知的,并且与使用ImageNet(无标签)的对象检测2的先前无监督工作[20](特别是在室内场景家具类别(例如椅子)上)具有竞争优势,沙发,桌子,电视,瓶子)。我们认为,几何图形是无监督表示学习的一个很好的提示,因为它可以从一些示例中学习,甚至可以推广到以前看不见的类别。未来的工作可能会利用视频中的深度信息(参见[98]),并使用它们来训练用于表面法线估计的模型。最后,我们可以通过对基于几何的模型进行微调以进行细分,然后对其进行微调以进行对象检测来添加氨基监督。我们比性能提高了5%。
5.Generalizability概括性
在本节中,我们演示了PixelNet的可推广性,并将其(进行了较小的修改)应用于语义分割的高级任务,中级表面法线估计和边缘检测的低级任务。 这些任务中的每一个都在附录中。


5.1. Semantic Segmentation

训练:对于所有实验,我们使用了公开可用的Caffe库[49]。所有训练有素的模型和代码都将发布。我们对所有卷积层都使用ImageNet预训练的值,但是使用高斯初始化(σ= 10 -3)和辍学[85](r = 0.5)“从头开始”训练MLP层。在整个微调过程中,我们将动量定为0.9,重量衰减定为0.0005。我们使用以下更新时间表(除非另有说明):我们以固定的学习速率(10 -3)将网络调整80个时期,每8个时期将速率降低10倍两次,直到达到10 -5为止。
数据集:PASCAL-Context数据集[4]将PASCAL VOC 2010分段注释的原始稀疏集[26](为20个类别定义)扩展为整个场景的像素标签。尽管这需要400多个类别,但我们遵循标准协议并评估了59类和33类子集。 PASCAL VOC-2012数据集的结果[26]在附录A中。
评估指标:我们报告各类平均值的像素准确性(AC)和区域相交联合(IU)的标准度量结果(越高越好)。两者均使用DeepLab评估工具3进行计算。
结果:表12显示了与以前的工作相比,我们的方法的性能。我们没有CRF的方法比以前基于CRF的方法做得更好。由于篇幅所限,我们在图6中仅显示了一个示例输出,并与FCN-8进行了比较[62]。请注意,我们捕获了精细的细节,例如鸟的腿。更多分析和细节在附录A中。
5.2. Surface Normal Estimation表面法线估计


我们使用NYU-v2深度数据集,并使用与第4节中定义的评估标准相同的评估标准。我们使用一般像素级优化分析提高了表面法线估计的最新技术[6]。 而Bansal等人[6] 从VGG-16的1×1×4096 conv-7中提取超列特征,我们在conv-6处提供了足够的填充以具有4×4×4096 conv-7。 这为图像中的不同像素提供了conv-7功能的多样性,而不是先前的相同conv-7。 此外,我们使用多尺度预测来改善结果。
培训:我们使用与前面所述相同的网络体系结构。 MLP的最后一个fc层具有(σ= 5 * 10 -3)。我们将初始学习速率设置为10 -3,在50K SGD迭代后将学习速率降低10倍。 该网络经过了60K次迭代训练。
结果:表13将我们的改进结果与以前的最新方法进行了比较[6,24]。 更多分析和细节在附录B中。
5.3. Edge Detection

数据集:用于边缘检测的标准数据集是BSDS-500 [4],它由200个训练,100个验证和200个测试图像组成。每幅图像均由约5个人注释,以标记轮廓。我们使用相同的增强数据(旋转,翻转,总计9600张图像而无需调整大小)来训练最新的整体嵌套边缘检测器(HED)[94]。我们在测试图像上报告数字。在训练期间,我们遵循HED,并且仅在达成共识(≥5分之3)的情况下使用阳性标签。
培训:我们使用第5.1节中定义的相同基准网络和培训策略。使用S形交叉熵损失来确定像素是否属于边缘。由于类别分布高度偏斜,我们还标准化了每批中正负的梯度(如[94]中所示)。如果分类标签分布不正确,采样将提供灵活性,使模型更多地关注稀有分类。
结果:表16显示了PixelNet在边缘检测方面的性能。表16中的最后两行对比了均匀采样和有偏采样之间的性能。定性地,我们发现我们的网络倾向于在语义轮廓(例如围绕对象)方面取得更好的结果,特别是在包含conv-7功能之后。图9显示了将我们的网络与HED模型进行比较的一些定性结果。有趣的是,我们的模型明确删除了斑马内部的边缘,但是当模型无法识别出斑马时(例如其头部不在画面中),它仍然在黑白条纹上标记了边缘。与过去的边缘检测工作相比,我们的模型似乎在利用更多的高级信息。更多分析和细节在附录C中。
6.Discussion
我们描述了一种卷积像素级体系结构,该体系结构经过细微修改,可以在各种高级,中级和低级任务上产生最新的准确性。 我们展示了高基准语义分割,表面法线估计和边缘检测数据集的结果。 通过仔细分析与卷积预测因子相关的计算和统计考虑因素,我们的结果成为可能。 卷积利用像素邻域的空间冗余来进行有效的计算,但是这种冗余也会阻碍学习。 我们提出了一个基于分层采样的简单解决方案,该方法在利用分摊卷积处理的同时注入多样性。 最后,我们的有效学习方案使我们能够探索对高级上下文和低级空间细节都进行编码的多尺度特征的非线性函数,这似乎与大多数像素预测任务有关。
