
一、时间记账
- 所有的调度器都必须对进程运行时间做记账。多数Unix系统,正如我们前面所说,分配一个时间片给每一个进程。那么当每次系统时钟节拍发生时,时间片都会被减少一个节拍周期。当一个进程的时间片被减少到0时,它就会被另一个尚未减到0的时间片可运行进程抢占
调度器实体结构(struct sched_entity)
- CFS不再有时间片的概念,但是它也必须维护每个进程运行的时间记账,因为它需要确保每个进程只在公平分配给它的处理器时间内运行
- CFS使用调度器实体结构(定义在文件<linux/sched.h>中)来追踪进程运行记账:
struct sched_entity {
struct load_weight load;
struct rb_node run_node;
struct list_head groupnode;
unsigned int on_rq;
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;
u64 prev_sum_exec_runtime;
u64 last_wakeup;
u64 avg_overlap;
u64 nr_migrations;
u64 start_runtime;
u64 avg_wakeup;
/ * 这里省略了很多统计变量,只有在设置了CONFIG_SCHEDSTATS时才启用这些变量 */
};
虚拟实时(vruntime变量)
- vruntime变量存放进程的虚拟运行时间,该运行时间(花在运行上的时间和)的计算是经过了所有可运行进程总数的标准化(或者说是被加权的)
- 虚拟时间是以ns为单位的,所以vruntime和定时器节拍不再相关
- 虚拟运行时间可以帮助我们逼近CFS模型所追求的“理想多任务处理器”。如果我们真有这样一个理想的处理器,那么我们就不再需要vruntime了。因优先级相同的所有进程的虚拟运行时都是相同的——所有任务都将接收到相等的处理器份额。但是因为处理器无法实现完美的多任务,它必须依次运行每个任务。因此CFS使用vruntime变景来记录一个程序到底运行了多长时间以及它还应该再运行多久
- 定义在kernel/sched_fair.c文件中的update_curr()函数实现了该记账功能:
static void update_curr(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr;
u64 now = rq_of(cfs_rq)->clock_task;
unsigned long delta_exec;
if (unlikely(!curr))
return;
/*
* Get the amount of time the current task was running
* since the last time we changed load (this cannot
* overflow on 32 bits):
*/
/*获得从最后一次修改负载后当前任务所占用的运行总时间(在32位系统上这不会溢出)*/
delta_exec = (unsigned long)(now - curr->exec_start);
if (!delta_exec)
return;
__update_curr(cfs_rq, curr, delta_exec);
/*更新exec_start*/
curr->exec_start = now;
if (entity_is_task(curr)) {
struct task_struct *curtask = task_of(curr);
trace_sched_stat_runtime(curtask, delta_exec, curr->vruntime);
cpuacct_charge(curtask, delta_exec);
account_group_exec_runtime(curtask, delta_exec);
}
account_cfs_rq_runtime(cfs_rq, delta_exec);
}
- update_curr()计算了当前进程的执行时间,并且将其存放在变量delta_exec中。然后它又将运行时间传给了_update_curr(),由后者再根据当前可运行进程总数对运行时间进行加权计算。最终将上述的权重值与当前运行进程的vruntime相加
/*
更新当前任务的运行时统计数据。跳过不再调度类中的当前任务
*/
static inline void
__update_curr(struct cfs_rq *cfs_rq, struct sched_entity *curr,
unsigned long delta_exec)
{
unsigned long delta_exec_weighted;
schedstat_set(curr->statistics.exec_max,
max((u64)delta_exec, curr->statistics.exec_max));
/*增加进程的总的运行时间*/
curr->sum_exec_runtime += delta_exec;
schedstat_add(cfs_rq, exec_clock, delta_exec);
delta_exec_weighted = calc_delta_fair(delta_exec, curr);
/*随着进程的运行,vruntime会增加,在红黑树中的位置越靠右*/
curr->vruntime += delta_exec_weighted;
update_min_vruntime(cfs_rq);
}
- update_curr()是由系统定时器周期性调用的,无论是在进程处于可运行态,还是被堵塞处于不可运行态。根据这种方式,vruntime可以准确地测量给定进程的运行时间,而且可知道谁应该是下一个被运行的进程
二、进程选择
- 在前面内容中我们的讨论中谈到若存在一个完美的多任务处理器,所有可运行进程的vruntime将一致。但事实上我们没有找到完美的多任务处理器,因此CFS试图利用一个简单的规则去均衡进程的虚拟运行时间:当CFS需要选择下一个运行进程时,它会挑一个具有最小vruntime的进程。这其实就是CFS调度算法的核心:选择具有最小vruntime的任务。那么剩下的内容我们就来讨论到底是如何实现选择具有最小vruntime值的进程
- CFS使用红黑树来组织可运行进程队列,并利用其迅速找到最小vruntime值的进程。在Linux中,红黑树称为rbtree,它是一个自平衡二叉搜索树。红黑树是一种以树节点形式存储的数据,这些数据都会对应一个键值。我们可以通过这些键值来快速检索节点上的数据(重要的是,通过键值检索到对应节点的速度与整个树的节点规模成指数比关系)
①挑选下一个任务
- 我们先假设,有那么一个红黑树存储了系统中所有的可运行进程,其中节点的键值便是可运行进程的虚拟运行时间。稍后我们可以看到如何生成该树,但现在我们假定已经拥有它了
- CFS调度器选取待运行的下一个进程,是所有进程中vruntime最小的那个,它对应的便是在树中最左侧的叶子节点。也就是说,你从树的根节点沿着左边的子节点向下找,一直找到叶子节点,你便找到了其vruntime值最小的那个进程(这个是红黑树的特性)。CFS的进程选择算法可简单总结为“运行rbtree树中最左边叶子节点所代表的那个进程”
- 实现这一过程的函数是__pick_next_entity(),它定义在文件kernel/sched_fair.c中:
static struct schedentity *__pick_next_entity(struct cfs_rq *cfs_rq)
{
struct rb_node *left = cfs_rq->rb_leftmost;
if (!left)
return NULL;
return rb_entry(left, struct sched_entity, run_node) ;
}
- 备注:
- __pick_next_entity()函数本身并不会遍历树找到最左叶子节点,因为该值已经缓存在rb_leftmost字段中。虽然红黑树让我们可以很有效地找到最左叶子节点(O(树的高度))等于树节点总数的O(
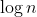 ),这是平衡树的优势),但是更容易的做法是把最左叶子节点缓存起来
),这是平衡树的优势),但是更容易的做法是把最左叶子节点缓存起来
- 这个函数的返回值便是CFS调度选择的下一个运行进程。如果该函数返回值是NULL,那么表示没有最左叶子节点,也就是说树中没有任何节点 了。这种情况下,表示没有可运行进程,CFS调度器便选择idle任务运行
②向树中加入进程
- 现在,我们来看CFS如何将进程加入rbtree中,以及如何缓存最左叶子节点。这一切发生在进程变为可运行状态(被唤醒)或者是通过fork()调用第一次创建进程时
- enqueue_entity()函数实现了这一目的:

- 该函数更新运行时间和其他一些统计数据,然后调用__enqueue_entity()进行繁重的插入操作,把数据项真正插入到红黑树中:

- 来看看上述函数:
- while()循环中遍历树以寻找合适的匹配键值,该值就是被插入进程的vruntime
- 平衡二叉树的基本规则是,如果键值小于当前节点的键值,则需转向树的左分支;相反如果大于当前节点的键值,则转向右分支。如果一旦走过右边分支,哪怕一次,也说明插入的进程不会是新的最左节点,因此可以设置leftmost为0。如果一直都是向左移动,那么lstmost维持1,这说明我们有一个新的最左节点,并且可以更新缓存——设置rb_lestmost指向被插入的进程
- 当我们沿着一个方向和一个没有子节的节点比较后:link如果这时是NULL,循环随之终止
- 当退出循环后,接着在父节点上调用rb_link_node(),以使得新插入的进程成为其子节点
- 最后函数rb_insert_color()更新树的自平衡相关属性
- 关于着色问题,我们会在后面的内存数据结构进行介绍
③从树中删除进程
- 最后我们看看CFS是如何从红黑树中删除进程的。删除动作发生在进程堵塞(变为不可运行态)或终止时(结束运行):

- 和给红黑树添加进程一样,实际工作是由辅助函数__dequeu_entity()完成的

- 从红黑树中删除进程要容易得多。因为rbtree实现了rb_erase()函数,它可完成所有工作。该函数的剩下工作是更新rb_leftmost缓存。如果要删除的进程是最左节点,那么该函数要调用rb_next()按顺序遍历,找到谁是下一个节点,也就是当前最左节点被删除后,新的最左节点
三、调度器入口(schedule())
- 进程调度的主要入口点是函数schedule(),它定义在文件kernel/sched.c中
- 它正是内核其他部分用于调用进程调度器的入口:选择哪个进程可以运行,何时将其投入运行
schedule()函数
- schedule()通常都需要和一个具体的调度类相关联,也就是说,它会找到一个最高优先级的调度类——后者需要有自己的可运行队列,然后问后者谁才是下一个该运行的进程。知道了这个背景,就不会吃惊schedule()函数为何实现得如此简单
- 该函数中唯一重要的事情是,它会调用pick_next_task()(也定义在文件kemel/sched.c中,见下)
- 以下代码来自于Linux 2.6.22/kernel/sched.c
/*
* schedule() is the main scheduler function.
*/
asmlinkage void __sched schedule(void)
{
struct task_struct *prev, *next;
struct prio_array *array;
struct list_head *queue;
unsigned long long now;
unsigned long run_time;
int cpu, idx, new_prio;
long *switch_count;
struct rq *rq;
/*
* Test if we are atomic. Since do_exit() needs to call into
* schedule() atomically, we ignore that path for now.
* Otherwise, whine if we are scheduling when we should not be.
*/
if (unlikely(in_atomic() && !current->exit_state)) {
printk(KERN_ERR "BUG: scheduling while atomic: "
"%s/0x%08x/%d\n",
current->comm, preempt_count(), current->pid);
debug_show_held_locks(current);
if (irqs_disabled())
print_irqtrace_events(current);
dump_stack();
}
profile_hit(SCHED_PROFILING, __builtin_return_address(0));
need_resched:
preempt_disable();
prev = current;
release_kernel_lock(prev);
need_resched_nonpreemptible:
rq = this_rq();
/*
* The idle thread is not allowed to schedule!
* Remove this check after it has been exercised a bit.
*/
if (unlikely(prev == rq->idle) && prev->state != TASK_RUNNING) {
printk(KERN_ERR "bad: scheduling from the idle thread!\n");
dump_stack();
}
schedstat_inc(rq, sched_cnt);
now = sched_clock();
if (likely((long long)(now - prev->timestamp) < NS_MAX_SLEEP_AVG)) {
run_time = now - prev->timestamp;
if (unlikely((long long)(now - prev->timestamp) < 0))
run_time = 0;
} else
run_time = NS_MAX_SLEEP_AVG;
/*
* Tasks charged proportionately less run_time at high sleep_avg to
* delay them losing their interactive status
*/
run_time /= (CURRENT_BONUS(prev) ? : 1);
spin_lock_irq(&rq->lock);
switch_count = &prev->nivcsw;
if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) {
switch_count = &prev->nvcsw;
if (unlikely((prev->state & TASK_INTERRUPTIBLE) &&
unlikely(signal_pending(prev))))
prev->state = TASK_RUNNING;
else {
if (prev->state == TASK_UNINTERRUPTIBLE)
rq->nr_uninterruptible++;
deactivate_task(prev, rq);
}
}
cpu = smp_processor_id();
if (unlikely(!rq->nr_running)) {
idle_balance(cpu, rq);
if (!rq->nr_running) {
next = rq->idle;
rq->expired_timestamp = 0;
goto switch_tasks;
}
}
array = rq->active;
if (unlikely(!array->nr_active)) {
/*
* Switch the active and expired arrays.
*/
schedstat_inc(rq, sched_switch);
rq->active = rq->expired;
rq->expired = array;
array = rq->active;
rq->expired_timestamp = 0;
rq->best_expired_prio = MAX_PRIO;
}
idx = sched_find_first_bit(array->bitmap);
queue = array->queue + idx;
next = list_entry(queue->next, struct task_struct, run_list);
if (!rt_task(next) && interactive_sleep(next->sleep_type)) {
unsigned long long delta = now - next->timestamp;
if (unlikely((long long)(now - next->timestamp) < 0))
delta = 0;
if (next->sleep_type == SLEEP_INTERACTIVE)
delta = delta * (ON_RUNQUEUE_WEIGHT * 128 / 100) / 128;
array = next->array;
new_prio = recalc_task_prio(next, next->timestamp + delta);
if (unlikely(next->prio != new_prio)) {
dequeue_task(next, array);
next->prio = new_prio;
enqueue_task(next, array);
}
}
next->sleep_type = SLEEP_NORMAL;
switch_tasks:
if (next == rq->idle)
schedstat_inc(rq, sched_goidle);
prefetch(next);
prefetch_stack(next);
clear_tsk_need_resched(prev);
rcu_qsctr_inc(task_cpu(prev));
update_cpu_clock(prev, rq, now);
prev->sleep_avg -= run_time;
if ((long)prev->sleep_avg <= 0)
prev->sleep_avg = 0;
prev->timestamp = prev->last_ran = now;
sched_info_switch(prev, next);
if (likely(prev != next)) {
next->timestamp = next->last_ran = now;
rq->nr_switches++;
rq->curr = next;
++*switch_count;
prepare_task_switch(rq, next);
prev = context_switch(rq, prev, next);
barrier();
/*
* this_rq must be evaluated again because prev may have moved
* CPUs since it called schedule(), thus the 'rq' on its stack
* frame will be invalid.
*/
finish_task_switch(this_rq(), prev);
} else
spin_unlock_irq(&rq->lock);
prev = current;
if (unlikely(reacquire_kernel_lock(prev) < 0))
goto need_resched_nonpreemptible;
preempt_enable_no_resched();
if (unlikely(test_thread_flag(TIF_NEED_RESCHED)))
goto need_resched;
}
schedule()函数
- pick_next_task()会以优先级为序,从高到低,依次检查每一个调度类,并且从最高优先级的调度类中,选择最高优先级的进程
- 注意该函数开始部分的优化。因为CFS是普通进程的调度类,而系统运行的绝大多数进程都是普通进程,因此这里有一个小技巧用来加速选择下一个CFS提供的进程,前提是所有可运行进程数量等于CFS类对应的可运行进程数(这样就说明所有的可运行进程都是CFS类的)
- 该函数的核心是for()循环,它以优先级为序,从最高的优先级类开始,遍历了每一个调度类。每一个调度类都实现了 pick_next_task()函数,它会返回指向下一个可运行进程的指针,或者没有时返回NULL。我们会从第一个返回非NULL值的类中选择下一个可运行进程。CFS中pick_next_task()实现会调用pick_next_entity(),而该函数会再来调用我们上面讨论过的__pick_next_entity()函数
- Linux 2.6.22中以无此函数

四、睡眠和唤醒
- 休眠(被阻塞)的进程:这种进程处于一个特殊的不可执行状态。这点非常重要,如果没有这种特殊状态的话,调度程序就可能选出一个本不愿意被执行的进程,更糟糕的是,休眠就必须以轮询的方式实现了
- 进程休眠有多种原因,但肯定都是为了等待一些事件:
- 事件可能是一段时间从文件I/O读更多数据,或者是某个硬件事件,一个进程还有可能在尝试获取一个已被占用的内核信号量时被迫进入休眠
- 休眠的一个常见原因就是文件I/O——如read()操作。还有,进程在获取键盘输入的时候也需要等待。
- 睡眠与唤醒:
- 睡眠:无论哪种情况,内核的操作都相同:进程把自己标记成休眠状态,从可执行红黑树中移出, 放入等待队列,然后调用schedule()选择和执行一个其他进程
- 唤醒:唤醒的过程刚好相反:进程被设置为可执行状态,然后再从等待队列中移到可执行红黑树中
- 睡眠的两种状态:
- 下图描述了每个调度程序状态之间的关系:

①等待队列
- 休眠通过等待队列进行处理。等待队列是由等待某些事件发生的进程组成的简单链表
- 内核用wake_queue_head_t来代表等待队列
- 等待队列可以通过DECLARE_WAITQUEUE()静态创建,也可以由init_waitqueue_head()动态创建
- 进程把自己放入等待队列中并设置成不可执行状态。当与等待队列相关的事件发生的时候,队列上的进程会被唤醒。为了避免产生竞争条件,休眠和唤醒的实现不能有纰漏
②进程的休眠
- 针对休眠,以前曾经使用过一些简单的接口。但那些接口会带来竞争条件:有可能导致在判定条件变为真后,进程却开始了休眠,那样就会使进程无限期地休眠下去。所以,在内核中进行休眠的推荐操作就相对复杂了一些
- 进程通过执行下面几个步骤将自己加入到一个等待队列中:
- 1.调用宏DEFINE_WAIT创建一个等待队列的项
- 2.调用add_wait_queue()把自己加入到队列中。该队列会在进程等待的条件满足时唤醒它。 当然我们必须在其他地方撰写相关代码,在事件发生时,对等待队列执行wake_up()操作
- 3.调用prepare_to_wait()方法将进程的状态变更为TASK_INTERRUPTIBLE或TASK_ UNINTERRUPTIBLE。而且该函数如果有必要的话会将进程加回到等待队列,这是在接下来的循环遍历中所需要的
- 4.如果状态被设置为TASK_INTERRUPTIBLE,则信号唤醒进程。这就是所谓的伪唤醒(唤醒不是因为事件的发生),因此检査并处理信号
- 5.当进程被唤醒的时候,它会再次检査条件是否为真。如果是,它就退出循环;如果不是 ,它再次调用schedule()并一直重复这步操作
- 6.当条件满足后,进程将自己设置为TASK_RUNNING并调用finish_wait()方法把自己移处出等待队列

- 如果在进程开始休眠之前条件就已经达成了,那么循环会退出,进程不会存在错误地进入休眠的倾向。需要注意的是,内核代码在循环体内常常需要完成一些其他的任务,比如,它可能在调用schedule()之前需要释放掉锁,而在这以后再重新获取它们,或者响应其他事件
inotify_read函数
- 函数inotify_read()负责从通知文件描述符中读取信息,它的实现无疑是等待队列的一个典型用法
- 这个函数遵循了我们例子中的使用模式,主要的区别是它在while循环检査了状态,而不是在while循环条件语句中。原因是该条件的检测更复杂些,而且需要获得锁。也正因为如此,循环退出是通过break完成的
- 以下代码来自于Linux 2.6.22/fs/inotfy_user.c
static ssize_t inotify_read(struct file *file, char __user *buf,
size_t count, loff_t *pos)
{
size_t event_size = sizeof (struct inotify_event);
struct inotify_device *dev;
char __user *start;
int ret;
DEFINE_WAIT(wait);
start = buf;
dev = file->private_data;
while (1) {
int events;
prepare_to_wait(&dev->wq, &wait, TASK_INTERRUPTIBLE);
mutex_lock(&dev->ev_mutex);
events = !list_empty(&dev->events);
mutex_unlock(&dev->ev_mutex);
if (events) {
ret = 0;
break;
}
if (file->f_flags & O_NONBLOCK) {
ret = -EAGAIN;
break;
}
if (signal_pending(current)) {
ret = -EINTR;
break;
}
schedule();
}
finish_wait(&dev->wq, &wait);
if (ret)
return ret;
mutex_lock(&dev->ev_mutex);
while (1) {
struct inotify_kernel_event *kevent;
ret = buf - start;
if (list_empty(&dev->events))
break;
kevent = inotify_dev_get_event(dev);
if (event_size + kevent->event.len > count) {
if (ret == 0 && count > 0) {
/*
* could not get a single event because we
* didn't have enough buffer space.
*/
ret = -EINVAL;
}
break;
}
if (copy_to_user(buf, &kevent->event, event_size)) {
ret = -EFAULT;
break;
}
buf += event_size;
count -= event_size;
if (kevent->name) {
if (copy_to_user(buf, kevent->name, kevent->event.len)){
ret = -EFAULT;
break;
}
buf += kevent->event.len;
count -= kevent->event.len;
}
remove_kevent(dev, kevent);
}
mutex_unlock(&dev->ev_mutex);
return ret;
}
③唤醒(wake_up()函数)
- 唤醒操作通过函数wake_up()进行,它会唤醒指定的等待队列上的所有进程
- wake_up()函数:
- 它会调用try_to_wake_up(),该函数负责将进程设置为TASK_RUNNING状态
- 它还会调用enqueue_task()将此进程放入红黑树中,如果被唤醒的进程优先级比当前正在执行的进程的优先级高,还要设置need_resched标志
- 通常哪段代码促使等待条件达成,它就要负责随后调用wake_up()函数。举例来说,当磁盘数据到来时,VFS就要负责对等待队列调用wake_up(),以便唤醒队列中等待这些数据的进程
- 虚假的唤醒:有时进程被唤醒并不是因为它所等待的条件达成了才需要用一个循环处理来保证它等待的条件真正达成
