Python 操作Excel之写操作
人总会去追求更好的,分享也是一样,有更好的,怎么能够不分享呢!
下面为大家送来python操作Excel的神来之笔----pandas库
废话不多逼逼,直接上干货分享
准备操作:
- 导入python库中的pandas库,这只需一句话便可搞定
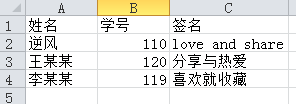
import pandas as pd- 事先准备好一张Excel表,本操作的表为test8.xls,表内容看下图
表格内容:
如下:
pandas操作Excel的常用方法:
直接上代码:
#此处用来学习pandas中的一些常用方法
import pandas as pd
path = 'test8.xls'
#读取表格将其转化成DataFrame的结构类型
df = pd.DataFrame(pd.read_excel(path))
各操作方法及结果展示:
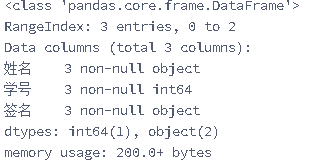
#输出表格的结构信息
df.info()
#查看索引
df.index

#查看列名
df.columns

#查看数据值
df.values
#还可查看类型
print(type(df.values))

#描述性统计
df.describe

#查看前几行数据,默认是前5行
df.head()
#查看后几行数据,默认是后5行
df.tail()
#以上的截图就省略了
# 删除指定列
df = df.drop(["学号"], axis=1) #需要删除多列,直接在中括号里加
#删完后再查看列名
df.columns

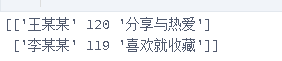
#读取指定的单行,数据会存在列表里面
#读取指定多行的话,就要在ix[]里面嵌套列表指定行数
data=df.ix[[1,2]].values
print(data)
# 输出列名
col_title = df.columns.values
print(col_title)

# 输出指定列的值(如姓名列)
name_value = df['姓名'].values
print(name_value)

# 输出行号并打印
row_num = df.index.values
print(row_num)

# 读取指定行并打印
values = df.ix[0].values #表头列名那行不算,序号下标从0开始
print(values)

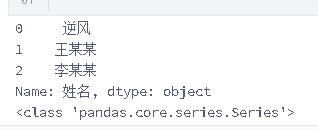
#直接用print(df['列名'])这样输出的是Series数据结构的类型
name = df['姓名']
print(name)
#查看类型
print(type(name))
# 某一列各个计数(合并相同值)
col_counts = df['姓名'].value_counts()
print(col_counts)
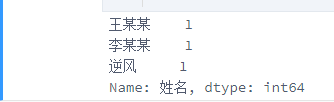
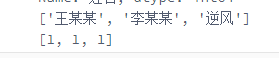
#接上图,比如要输出左右侧的列,并将其转化成列表,需要如何操作呢?(左侧是index,右侧一般是value值)
# 我们要将Series结构类型转化成列表,只需用tolist()方法
name = col_counts.index.tolist()
print(name)
counts_list = col_counts.tolist()
print(counts_list)
pandas操作Excel的方法还有很多,不可能在这里把所有都罗列出来,但是上面的都是很常用的,当遇到不会的时,要学会查看官网
官网链接:https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html
此次分享到这就结束了。
