阿里巴巴是如何优雅的处理分布式事务?
码字不易,转载请注明出处
前面废话很多,但是多多少少有点用,嫌我啰嗦的可以直接跳到目录里的实战环节
#前言
博主最近在架构公司项目的过程中,遇到了事务链调用的问题,也就是常常面试里说的分布式事务.
知识点补充
什么是分布式锁与分布式事务?
分布式锁
在单体应用下,我们可以给某些临界资源(不要问我什么是临界资源了,再这样这篇文章写不下去了,请各位看官自行百度)加锁,以防止脏写的情况出现.
但是在分布式场景下,我们在本地项目加锁显然不能锁住所有服务对于该临界资源的访问,这时候就需要分布式的锁来处理这个问题了.
因为我们本文是讨论分布式事务,我这里不再赘述,等到某一天我会专门写一篇分布式锁的实现文章.
分布式事务
如同分布式锁一样,我们以前在单体应用下可以对一组操作进行事务提交,这样这组操作要么都成功,要么都失败.
但是显然在分布式场景下,我们必须引用一个第三方,来告知各个事务别的事务有没有成功执行,如果其中有一个失败了,所有的事务都要回滚,这样才能保证数据的最终一致性.
科普完毕!
那么处理分布式事务都有哪些解决方案呢?
现在业界对于数据的最终一致性有以下的解决方案:
-
逃避型
逃避型顾名思义,既然产生分布式事务的原因是RPC(远程过程调用),那我就把可能产生分布式事务的服务接口整合到一个服务里面,这样就不会产生分布式事务的问题了.
但是这显然违背我们的初衷,拆分的服务又被耦合起来了,这种处理方式只适合业务量小的公司,对于业务复杂的中大型公司显然不现实.
-
经典处理方式
这也是eBay公司处理这种场景的方式,此方案的核心是将需要分布式处理的任务通过消息日志的方式来异步执行。而消息日志可以存储到本地文本、数据库或消息队列,再通过业务规则自动或人工发起重试。人工重试更多的是应用于支付场景,通过对账系统对事后问题的处理。
eBay的架构师Dan Pritchett提出了BASE原则,这个原则我就不细讲了,感兴趣的同学问问Google或者度娘.
他的核心思路就是在多个分布式的事务中间增加一张中间表,而这张表的作用就是用来记录已经处理过的消息.
第一阶段,增加了一张中间表和消息队列,每个本地的事务分别执行
第二阶段,它们分别读出消息队列,通过判断表里的数据来检测相关的记录是否被执行,如果都执行则提交,直到事务执行成功后才删除队列. -
去哪儿网解决方式
幂等有两种方式,一种方式是业务逻辑保证幂等。比如接到支付成功的消息订单状态变成支付完成,如果当前状态是支付完成,则再收到一个支付成功的消息则说明消息重复了,直接作为消息成功处理。
另外一种方式如果业务逻辑无法保证幂等,则要增加一个去重表或者类似的实现。对于 producer 端在业务数据库的同实例上放一个消息库,发消息和业务操作在同一个本地事务里。发消息的时候消息并不立即发出,而是向消息库插入一条消息记录,然后在事务提交的时候再异步将消息发出,发送消息如果成功则将消息库里的消息删除,如果遇到消息队列服务异常或网络问题,消息没有成功发出那么消息就留在这里了,会有另外一个服务不断地将这些消息扫出重新发送
-
还有很多公司,都有自己去处理分布式事务的一套方案,我就不赘述了
但是大家得明白一点,分布式事务解决的核心就是你得制定一套规则或通信机制,让所有的事务"同时"提交(这里的同时不是真正意义上的同时),要么都成功,要么都失败.
#阿里Seata
#Seata用户群
可能不说大家也知道,阿里这个框架就是用来解决分布式事务的问题.
阿里本身的业务就会涉及到大量的支付,支付业务就是很典型的分布式事务.
用户下单>扣钱>扣库存>加订单
这里面有四个系统,要最少保证这四个系统数据的最终一致性,并且不能让用户等太久(我上淘宝买个东西,等5分钟你才告诉我下单成功)
所以除了能保证一致性以外,还要求这个分布式事务的中间件,具备一定的性能.
而阿里的Seata,现在有很多公司都将其作为分布式事务的解决方案,给大家几张图感受下




多的我就不放了,想必大家也感受出来这个框架的火爆程度了.
#Seata的前世今生
Seata的前身是Fescar,而Fescar的前身是GTS
那么GTS又是什么呢?
#Seata基本概念
我们再来看看阿里官方是怎么介绍Seata的
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。
这里提到了几种事务模式:
- AT
- TCC
- SAGA
- XA
我们分别说下这几种模式都有什么区别:摘自Seata官网
AT: 二阶段提交
-
一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。
-
二阶段:提交异步化,非常快速地完成。回滚通过一阶段的回滚日志进行反向补偿。
并且是读写隔离的
具体可以查看上面seata官网的链接
TCC:支持分支事务的二阶段提交
相对于AT模式,TCC是在其基础上加入了更多的可定制逻辑
AT 模式(参考链接 TBD)基于 支持本地 ACID 事务 的 关系型数据库:
- 一阶段 prepare 行为:在本地事务中,一并提交业务数据更新和相应回滚日志记录。
- 二阶段 commit 行为:马上成功结束,自动 异步批量清理回滚日志。
- 二阶段 rollback 行为:通过回滚日志,自动 生成补偿操作,完成数据回滚。
相应的,TCC 模式,不依赖于底层数据资源的事务支持:
- 一阶段 prepare 行为:调用 自定义 的 prepare 逻辑。
- 二阶段 commit 行为:调用 自定义 的 commit 逻辑。
- 二阶段 rollback 行为:调用 自定义 的 rollback 逻辑。
所谓 TCC 模式,是指支持把 自定义 的分支事务纳入到全局事务的管理中。
Saga:长事务解决方案
当一个事务调用链很长的时候,我们就可以使用长事务提交的解决方案.
这里不再赘述,如果有特殊场景需要用到长事务提交,建议大家到seata官网读一下文档.
但是这里需要注意一点:
Seaga模式下不保证隔离性!对应解决方案官网上有
XA:官网也没有具体说明XA模式,实际上选择哪种模式取决于你的应用程序使用何种资源,你愿意在性能、安全、系统稳健性、数据完整方面做出何种权衡。
如果对于XA模式感兴趣的同学可以移步至这篇博文
下面是摘自官网的术语表
TC - 事务协调者
维护全局和分支事务的状态,驱动全局事务提交或回滚。
TM - 事务管理器
定义全局事务的范围:开始全局事务、提交或回滚全局事务。
RM - 资源管理器
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
#实战
好了,上面说了这么多,我们已经知道seata是一个什么样的中间件了.
接下来,我带大家简单做个demo体验下seata是怎么去管理分布式事务的
-
首先我们要下载一个seata-server,用作我们的分布式事务管理中心
我下载的是0.8版本的
因为上面下载地址是github的,如果遇到被墙而不能下载的情况我在百度网盘同样准备了一份
链接:https://pan.baidu.com/s/1Zq5LalfQK9bR5WoQNOJnTQ
提取码:hg0d -
接下来我们解压到本地

得到以上三个文件夹
我们首先进入到conf文件夹
然后修改file.conf文件如下
transport {
# tcp udt unix-domain-socket
type = "TCP"
#NIO NATIVE
server = "NIO"
#enable heartbeat
heartbeat = true
#thread factory for netty
thread-factory {
boss-thread-prefix = "NettyBoss"
worker-thread-prefix = "NettyServerNIOWorker"
server-executor-thread-prefix = "NettyServerBizHandler"
share-boss-worker = false
client-selector-thread-prefix = "NettyClientSelector"
client-selector-thread-size = 1
client-worker-thread-prefix = "NettyClientWorkerThread"
# netty boss thread size,will not be used for UDT
boss-thread-size = 1
#auto default pin or 8
worker-thread-size = 8
}
shutdown {
# when destroy server, wait seconds
wait = 3
}
serialization = "seata"
compressor = "none"
}
service {
#vgroup->rgroup
vgroup_mapping.fsp_tx_group = "default" #修改这里,fsp_tx_group这个事务组名称是我自定义的,一定要与client端的这个配置一致!否则会报错!
#only support single node
default.grouplist = "127.0.0.1:8091" #此配置作用参考:https://blog.csdn.net/weixin_39800144/article/details/100726116
#degrade current not support
enableDegrade = false
#disable
disable = false
#unit ms,s,m,h,d represents milliseconds, seconds, minutes, hours, days, default permanent
max.commit.retry.timeout = "-1"
max.rollback.retry.timeout = "-1"
}
client {
async.commit.buffer.limit = 10000
lock {
retry.internal = 10
retry.times = 30
}
report.retry.count = 5
}
## transaction log store
store {
## store mode: file、db
mode = "db" #修改这里,表明事务信息用db存储
## file store 当mode=db时,此部分配置就不生效了,这是mode=file的配置
file {
dir = "sessionStore"
# branch session size , if exceeded first try compress lockkey, still exceeded throws exceptions
max-branch-session-size = 16384
# globe session size , if exceeded throws exceptions
max-global-session-size = 512
# file buffer size , if exceeded allocate new buffer
file-write-buffer-cache-size = 16384
# when recover batch read size
session.reload.read_size = 100
# async, sync
flush-disk-mode = async
}
## database store mode=db时,事务日志存储会存储在这个配置的数据库里
db {
## the implement of javax.sql.DataSource, such as DruidDataSource(druid)/BasicDataSource(dbcp) etc.
datasource = "dbcp"
## mysql/oracle/h2/oceanbase etc.
db-type = "mysql"
driver-class-name = "com.mysql.jdbc.Driver"
url = "jdbc:mysql://127.0.0.1/seat-server" #修改这里
user = "你的数据库用户名" #修改这里
password = "你的数据库密码" #修改这里
min-conn = 1
max-conn = 3
global.table = "global_table"
branch.table = "branch_table"
lock-table = "lock_table"
query-limit = 100
}
}
lock {
## the lock store mode: local、remote
mode = "remote"
local {
## store locks in user's database
}
remote {
## store locks in the seata's server
}
}
recovery {
#schedule committing retry period in milliseconds
committing-retry-period = 1000
#schedule asyn committing retry period in milliseconds
asyn-committing-retry-period = 1000
#schedule rollbacking retry period in milliseconds
rollbacking-retry-period = 1000
#schedule timeout retry period in milliseconds
timeout-retry-period = 1000
}
transaction {
undo.data.validation = true
undo.log.serialization = "jackson"
undo.log.save.days = 7
#schedule delete expired undo_log in milliseconds
undo.log.delete.period = 86400000
undo.log.table = "undo_log"
}
## metrics settings
metrics {
enabled = false
registry-type = "compact"
# multi exporters use comma divided
exporter-list = "prometheus"
exporter-prometheus-port = 9898
}
然后修改同目录下的registry.conf如下
registry {
# file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
type = "eureka" #修改这里,指明注册中心使用什么
nacos {
serverAddr = "localhost"
namespace = ""
cluster = "default"
}
eureka {
serviceUrl = "http://localhost:8761/eureka" #修改这里
application = "default"
weight = "1"
}
redis {
serverAddr = "localhost:6379"
db = "0"
}
zk {
cluster = "default"
serverAddr = "127.0.0.1:2181"
session.timeout = 6000
connect.timeout = 2000
}
consul {
cluster = "default"
serverAddr = "127.0.0.1:8500"
}
etcd3 {
cluster = "default"
serverAddr = "http://localhost:2379"
}
sofa {
serverAddr = "127.0.0.1:9603"
application = "default"
region = "DEFAULT_ZONE"
datacenter = "DefaultDataCenter"
cluster = "default"
group = "SEATA_GROUP"
addressWaitTime = "3000"
}
file {
name = "file.conf"
}
}
config {
# file、nacos 、apollo、zk、consul、etcd3
type = "file"
nacos {
serverAddr = "localhost"
namespace = "public"
cluster = "default"
}
consul {
serverAddr = "127.0.0.1:8500"
}
apollo {
app.id = "seata-server"
apollo.meta = "http://192.168.1.204:8801"
}
zk {
serverAddr = "127.0.0.1:2181"
session.timeout = 6000
connect.timeout = 2000
}
etcd3 {
serverAddr = "http://localhost:2379"
}
file {
name = "file.conf"
}
}
在conf目录下,我们会看到这两个文件
没错,这两个文件就是我们的sql建表语句
首先我们创建seat-server数据库
然后使用db_store.sql文件创建对应表
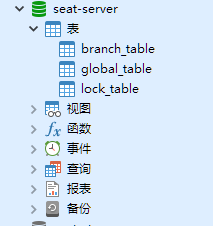
创建成功后如图所示
然后我们自己有三个服务,分别是
- order 订单服务
- storage 库存服务
- account 账户服务
并且我们有一个eureka注册中心
- eureka 注册中心
这三个服务对应的数据库中都需要创建一个undo_log数据表
数据表的建表文件就是conf目录下的db_undo_log.sql
最后数据库如下图
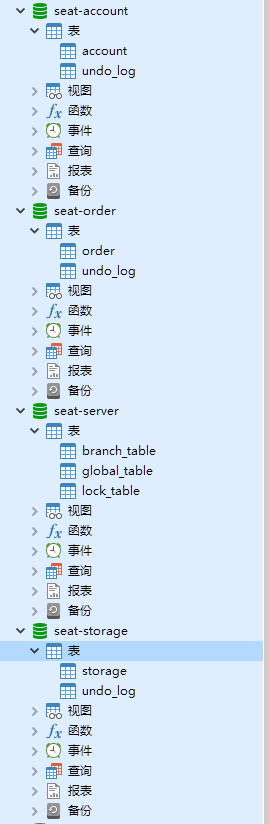
接下来我们将项目克隆下来
修改每个项目中的数据源信息,并用每个项目resources目录下的建表语句生成对应表
最后生成的数据库结构如下图所示
然后就可以启动项目啦!
启动顺序如下:
- 启动eureka
- 启动seata-server bin目录下的bat文件
- 启动剩下的三个服务
启动后我们访问 http://localhost:8180/order/create?userId=1&productId=1&count=10&money=100
然后我们得到了成功执行的结果
然后我们修改AccountServiceImpl中的decrease方法如下
/**
* 扣减账户余额
* @param userId 用户id
* @param money 金额
*/
@Override
public void decrease(Long userId, BigDecimal money) {
LOGGER.info("------->扣减账户开始account中");
//模拟超时异常,全局事务回滚
try {
Thread.sleep(30*1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
accountDao.decrease(userId,money);
LOGGER.info("------->扣减账户结束account中");
//修改订单状态,此调用会导致调用成环
LOGGER.info("修改订单状态开始");
String mes = orderApi.update(userId, money.multiply(new BigDecimal("0.09")),0);
LOGGER.info("修改订单状态结束:{}",mes);
}
我们通过sleep模拟了请求超时的情况
然后再次测试

得到了一个500(服务器内部错误的响应)
但是我们去看数据库,发现数据表里一切正常,说明我们的事务回滚成功了!
seat-storage
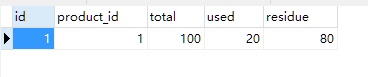
seat-order(两条数据是因为我之前执行过一次)

seat-account

以上就是Seata分布式事务管理中间件的实战.
相对于别的分布式事务中间件,阿里的这个对代码侵入性小,性能高,并且社区也很活跃,如果对于这个中间件感兴趣的同学可以尝试.
一定要按照步骤将项目clone到本地练习,光看是看不会的.
以上的例子摘自官网给出的sample,我将我自己部署到本地运行成功的代码也托管到了github,感兴趣的同学可以克隆后在本地跑跑看
本篇文章github项目地址: https://github.com/huanqwer/seata-sample.git
码字不易,对分布式,微服务,架构等内容感兴趣的看官可以点个关注,我会不定时的更新一些架构干货,基本都是在实际生产中遇到的问题
