昨日内容回顾
进程
multiprocess
Process —— 进程 在python中创建一个进程的模块
start
daemon 守护进程
join 等待子进程执行结束
锁 Lock
acquire release
锁是一个同步控制的工具
如果同一时刻有多个进程同时执行一段代码,
那么在内存中的数据是不会发生冲突的
但是,如果涉及到文件,数据库就会发生资源冲突的问题
我们就需要用锁来把这段代码锁起来
任意一个进程执行了acquire之后,
其他所有的进程都会在这里阻塞,等待一个release
信号量 semaphore
锁 + 计数器
同一时间只能有指定个数的进程执行同一段代码
事件 Event
set clear is_set 控制对象的状态
wait 根据状态不同执行效果也不同
状态是True ---> pass
状态是False --> 阻塞
一般wait是和set clear放在不同的进程中
set/clear负责控制状态
wait负责感知状态
我可以在一个进程中控制另外一个或多个进程的运行情况
IPC通信
队列 Queue
管道 PIPE
一、进程间通信(队列和管道)
判断队列是否为空
from multiprocessing import Process,Queue q = Queue() print(q.empty())
执行输出:True
判断队列是否满了
from multiprocessing import Process,Queue q = Queue() print(q.full())
执行输出:False
如果队列已满,再增加值的操作,会被阻塞,直到队列有空余的
from multiprocessing import Process,Queue
q = Queue(10) # 创建一个只能放10个value的队列
for i in range(10):
q.put(i) # 增加一个value
print(q.qsize()) # 返回队列中目前项目的正确数量
print(q.full()) # 如果q已满,返回为True
q.put(111) # 再增加一个值
print(q.empty())
执行输出:
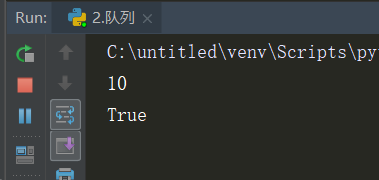
可以看出程序并没有结束,q.put(111)之后的代码被阻塞了。
总结:
队列可以在创建的时候指定一个容量
如果在程序运行的过程中,队列已经有了足够的数据,再put就会发生阻塞
如果队列为空,再get就会发生阻塞
为什么要指定队列的长度呢?是为了防止内存爆炸。
一个队列,不能无限制的存储。毕竟内存是有限制的。
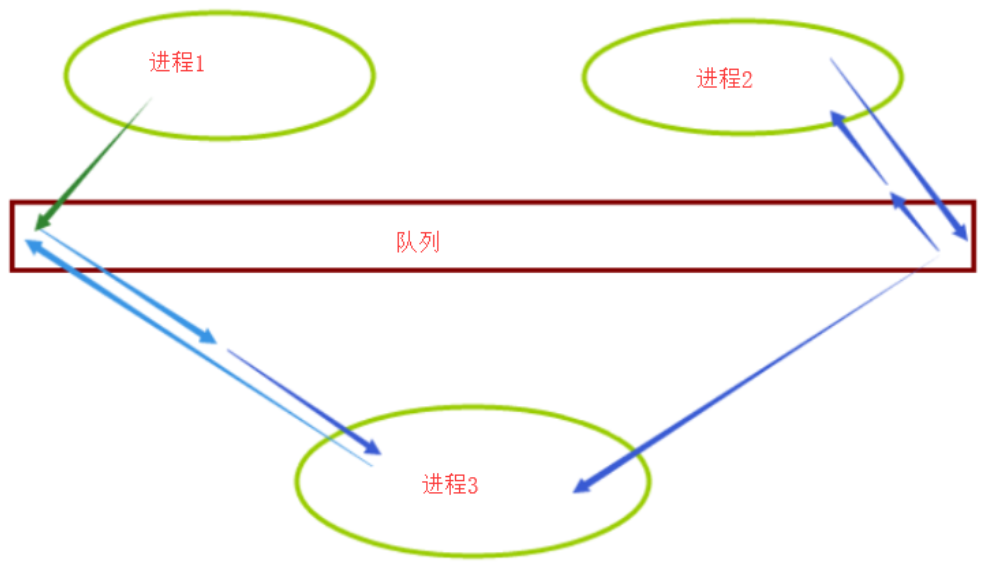
上面提到的put、get、qsize、full、empty都是不准的。
因为在返回结果和在稍后程序中使用结果之间,队列中可能添加或删除了项目。在某些系统上,此方法可能引发NotImplementedError异常。
如果其它进程或线程正在往队列中添加项目,结果是不可靠的。也就是说,在返回和使用结果