不点赞白嫖的都是流氓!!!
首先,要实现将语音转换成字符串,你要做两件事:
第一件事,在IBM网站注册一个账号,创建一个speech to text 应用,得到这个应用的API密钥和URL
第二件事,复制我提供的代码,安装脚本代码所需要的工具包,准备好要转换的音频就可以运行得到结果啦
脚本代码如下:
提前安装工具包语句pip install --upgrade “ibm-watson>=4.1.0”
from ibm_watson import SpeechToTextV1
from ibm_cloud_sdk_core.authenticators import IAMAuthenticator
IDkey = 'nblnZuv5E5A_wo5j9eYC-nQVWHKyY5HxJXuEPnNpJgrr' # API密钥
URL = 'https://api.us-south.speech-to-text.watson.cloud.ibm.com/instances/7e2f69e7-a5e8-4d56-91ae-f4dc7b4a1f0b'
# Music = 'data/audio-file2.flac' # 要转换的音频存放的路径
Music = 'data/1.mp3' # 要转换的音频存放的路径
authenticator = IAMAuthenticator(IDkey)
speech_to_text = SpeechToTextV1(
authenticator=authenticator
)
speech_to_text.set_service_url(URL)
with open(Music, 'rb') as audio_file:
speech_recognition_results = speech_to_text.recognize(
audio=audio_file,
# content_type='audio/flac', # 指定转换的音频是.flac音频格式
# content_type='audio/wav', # 指定转换的音频是.wav音频格式
content_type='audio/mp3', # 指定转换的音频是.mp3音频格式
model='zh-CN_BroadbandModel', # 表示识别中文语音,不指定则默认识别英文
# timestamps=True # 识别内容对应的时间轴(作字幕很重要的一个属性,但是我还不知道具体怎么使用)
).get_result()
result = speech_recognition_results
print(result) #
print(result['results'][0]['alternatives'][0]['transcript']) # 将结果提取出来(不保证任何音频都是这样提取,依据result来看)
pass
第一件事的具体流程:打开网站,用邮箱注册完账号登录就能看到下面的界面啦
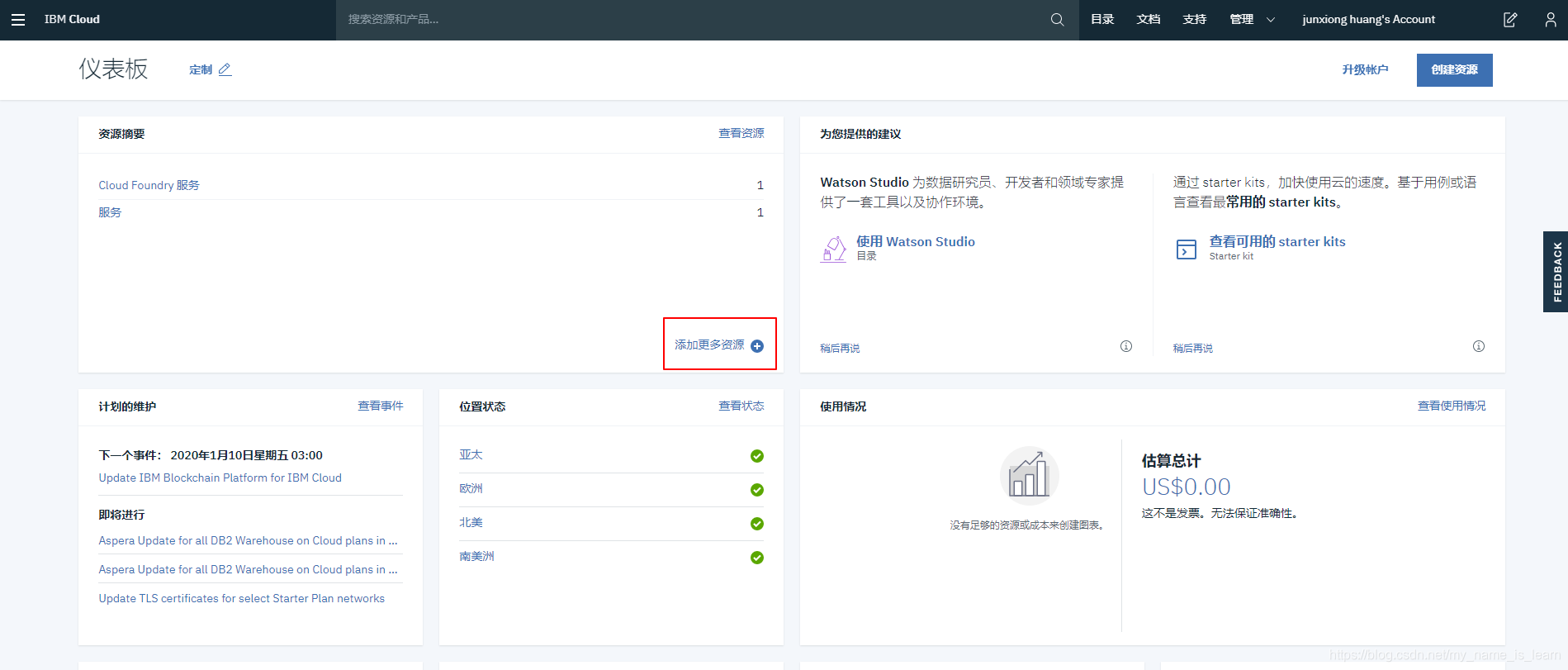
点击”添加更多服务“,就出现下面这个界面啦
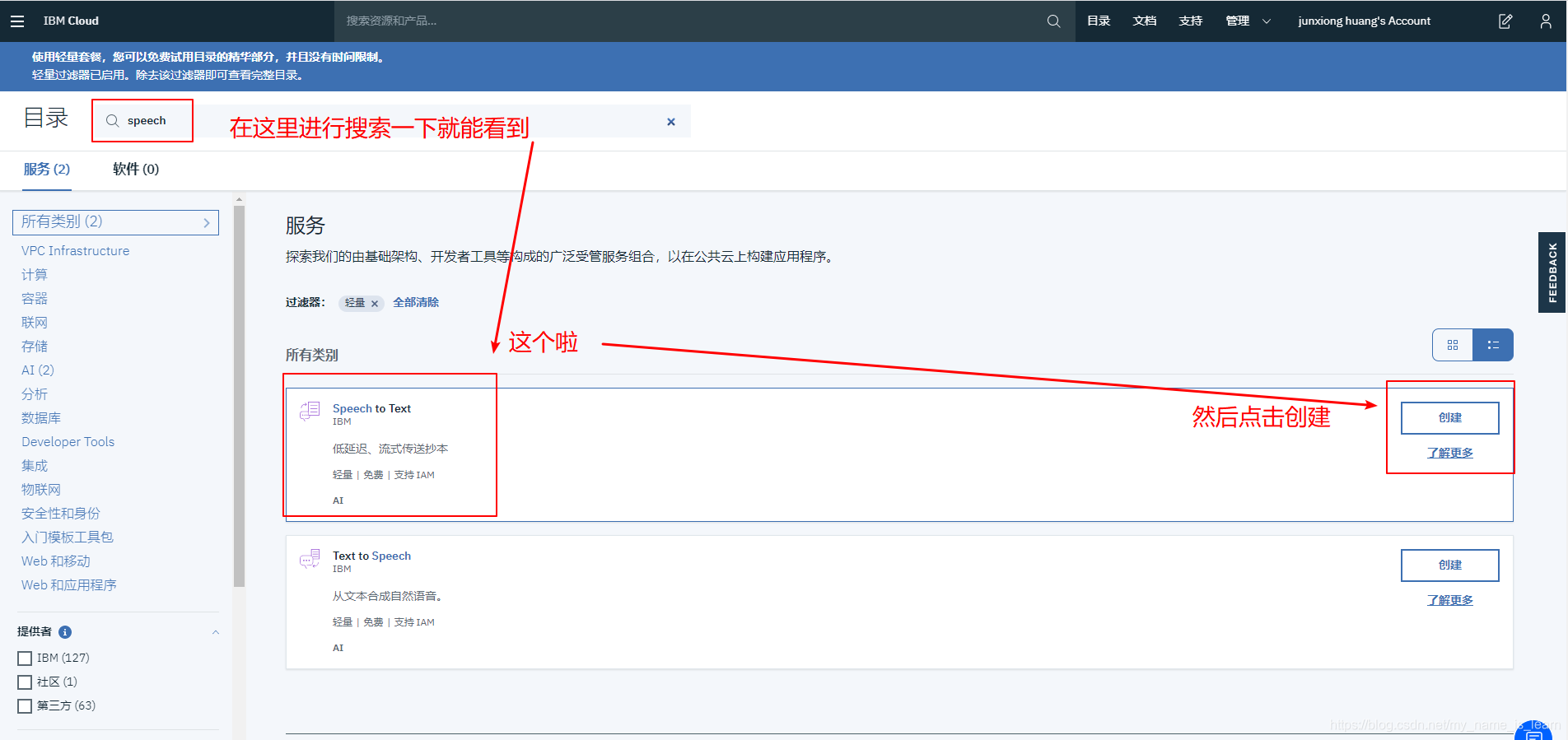
点击”创建“之后按照提示创建应用即可,然后找到该应用的API密钥和URl,如下图所示,找不到?别开玩笑了,发挥你的聪明才智用鼠标点一点就能找到啦
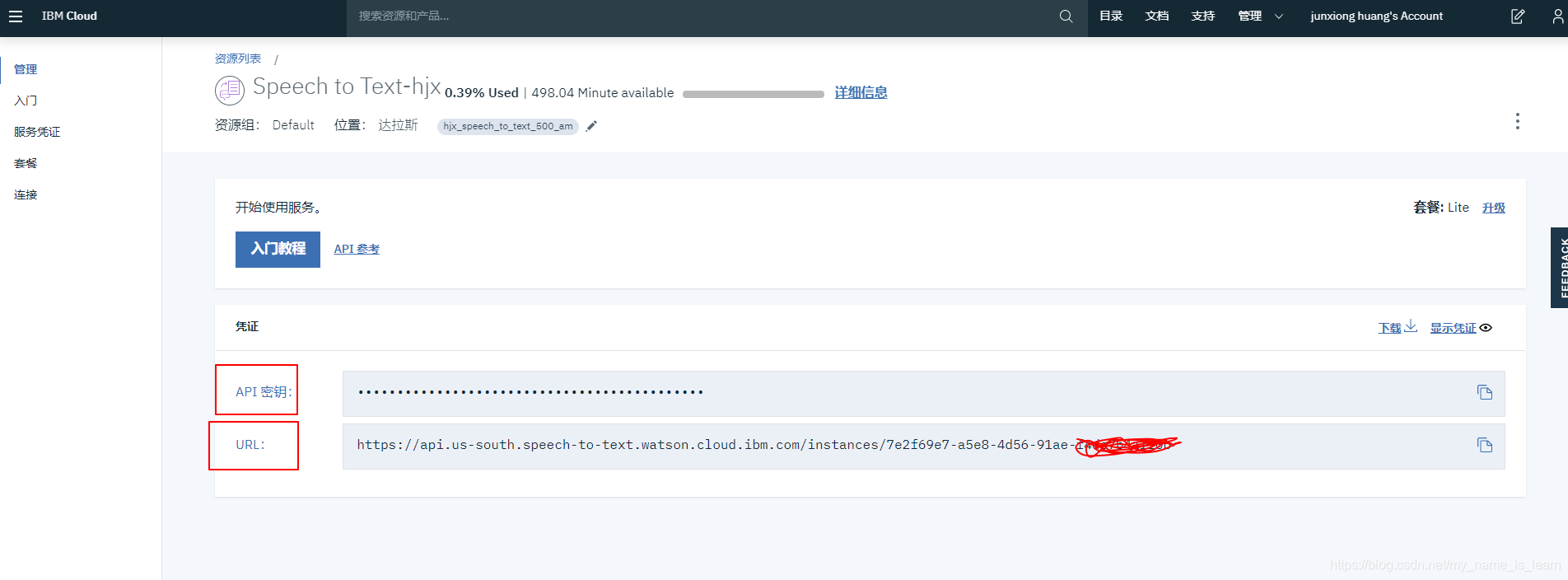
然后复制到代码中去代替我的代码中的IDkey和URL,大功告成(撒花撒花撒花)
怕你们这些小懒猪不想注册,我就将自己的密钥和URl分享出来了,但是别总是用我的哦,乖乖自己去注册一个,爱你们么么哒,点个赞吧
