为了方便后面的学习,在学习Hive的过程中先学习一个工具,那就是Sqoop,你会往后机会发现sqoop是我们在学习大数据框架的最简单的框架了。
Sqoop是一个用来将
Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型
数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
对于某些
NoSQL数据库它也提供了连接器。
Sqoop,类似于其他ETL工具,使用元数据模型来判断数据类型并在数据从数据源转移到Hadoop时确保类型安全的数据处理。
Sqoop专为
大数据批量传输设计,能够分割数据集并创建Hadoop任务来处理每个区块。
尽管有以上的优点,在使用Sqoop的时候还有一些事情需要注意。
首先,对于默认的并行机制要小心。默认情况下的并行意味着Sqoop假设大数据是在分区键范围内均匀分布的。这在当你的源系统是使用一个序列号发生器来生成主键的时候工作得很好。
打个比方,当你有一个10个节点的集群,那么工作负载是在这10台服务器上平均分配的。但是,如果你的分割键是基于字母数字的,拥有比如以“A”作为开头的键值的数量会是“M”作为开头键值数量的20倍,那么工作负载就会变成从一台服务器倾斜到另一台服务器上。
如果你最担心是性能,那么可以研究下直接加载。直接加载绕过通常的Java数据库连接导入,使用数据库本身提供的直接载入工具,比如
MySQL的mysqldump。
但是有特定数据库的限制。比如,你不能使用MySQL或者PostgreSQL的连接器来导入BLOB和CLOB类型。也没有驱动支持从视图的导入。Oracle直接驱动需要特权来读取类似dba_objects和v_$parameter这样的
元数据。请查阅你的数据库直连驱动程序局限性的相关文档。
进行增量导入是与效率有关的最受关注的问题,因为Sqoop专门是为大数据集设计的。Sqoop支持增量更新,将新记录添加到最近一次的导出的数据源上,或者指定上次修改的时间戳。
由于Sqoop将数据移入和移出关系型数据库的能力,其对于Hive—
Hadoop生态系统里的著名的类SQL数据仓库—有专门的支持不足为奇。命令“create-hive-table”可以用来将数据表定义导入到
Hive。
版本:(两个版本完全不兼容,sqoop1使用最多)
sqoop1:1.4.x
sqoop2:1.99.x
同类产品
DataX:阿里顶级数据交换工具
注意,这里的导入和导出是相对于Hadoop来说的 !!!!!
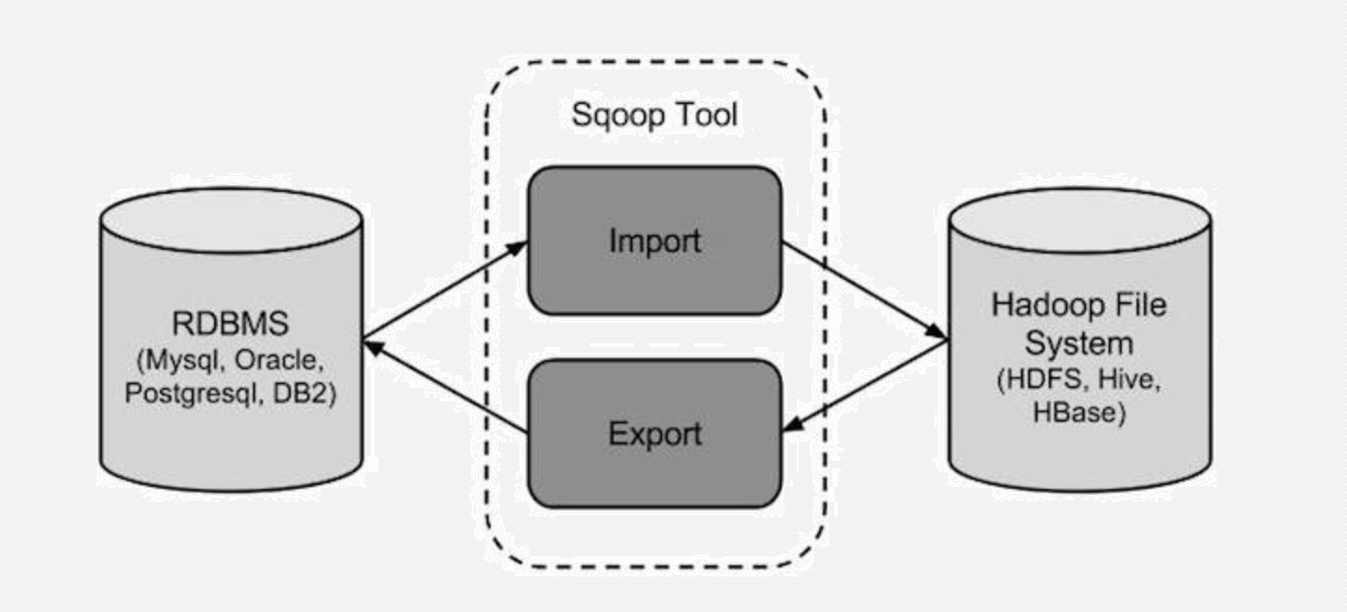

数据导入到Hadoop中的HDFS中:

把HDFS中的数据导出来到关系数据库中去:
