题目:Evaluating False Transfer Rates from the Match-between-Runs Algorithm with a Two-Proteome Model
期刊:Journal of Proteome Research
发表时间:September 23, 2019
DOI:10.1021/acs.jproteome.9b00492
分享人:任哲
内容与观点:
大家好,本次分享的是发表在Journal of Proteome Research上的一篇关于蛋白DDA非标定量中常用技术Match between run(简称MBR)技术的文章,题目是Evaluating False Transfer Rates from the Match-between-Runs Algorithm with a Two-Proteome Model,利用混合蛋白质组模型对MBR算法中错误转移鉴定率的评估,通讯作者是大名鼎鼎的来自哈佛医学院的Steven Gygi教授,他长期从事蛋白质组学的研究,在蛋白质组学定量领域有过很多里程碑式的贡献。
在相互独立的质谱上机之间的随机性一直是困扰蛋白质组学研究的一个难题,这种随机性会带来定量时大规模的肽段定量值的缺失。为了能解决这一问题,研究者开发了一系列计算方法,例如MaxQuant中引入的MBR方法就是其中的佼佼者。通常情况下,MBR会同时考虑同时考虑若干个上机数据,利用它们之间任一一个数据中存在的峰来迁移鉴定其他数据。为了评估这些迁移鉴定事件,作者建立了一个包含两个蛋白质组/两个样品的测试方法,具体来讲,即用样品中不含有酵母裂解液的20个样品来评估另外含有酵母裂解液的20个样品在鉴定时候发生的迁移鉴定事件。实验中,MBR提升了约40%的谱图鉴定,同时,我们发现约44%鉴定到的酵母蛋白在至少一个不含有酵母裂解液的样品中发生了迁移鉴定的情况,但是通过MaxQuant的LFQ算法之后,仅有2.7%的结果出现在了最终的结果中。由以上事实,我们发现利用MBR算法确实会出现大量假的迁移鉴定,但经过LFQ算法后很少会出现在最终结果中。
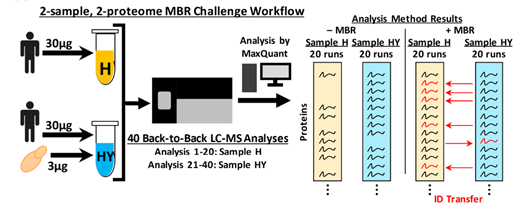
文章中使用人HCT116细胞系和酵母样品构建了20个细胞系样品和20个细胞系与酵母样品的混合样品,接着将他们背靠背地上机并用MaxQuant进行分析,分别开启MBR和关闭MBR,利用开启MBR的结果计算迁移鉴定的结果。具体实验流程见下图:
最终结果可以见下图,在蛋白水平两者相等,而在肽段水平,开启MBR可以有效地提升谱图鉴定率。

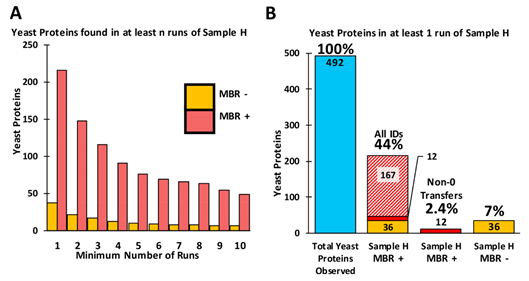
更加精细的结果可以见下表,可以发现开启MBR,主要提升的部分是在酵母蛋白部分,这部分结果就可以用来衡量MBR结果的假阳性情况。

精细地检视酵母蛋白如下图所示,约一半的酵母蛋白仅在一个样品中发现,证明通过限制鉴定到蛋白的样品数目可以一定程度上降低假阳性结果。而在所有鉴定到的酵母蛋白中,有约44%的蛋白来自至少一个人细胞系样品,这部分结果应为假的迁移鉴定。
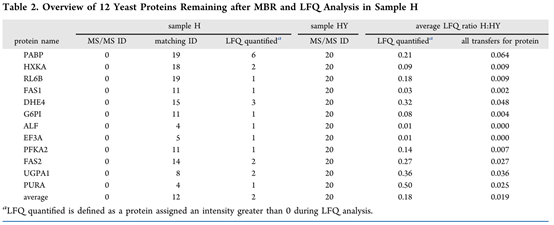
利用MaxQuant内置的LFQ方法可以有效地降低错误的迁移鉴定,经过LFQ方法后仍然存留的12个酵母蛋白列表如下, 可以发现大部分蛋白在含酵母和不含酵母样品之间的差异都很大,这也能一定程度上区分错误的迁移鉴定。
最后,作者总结MBR方法,虽然它会很大程度上引入错误的迁移鉴定,但是通过LFQ方法可以有效地降低错误的迁移鉴定,而且即使通过了最终的LFQ方法,蛋白的定量值依然能够区分这部分错误鉴定,后续依然需要开发对MBR结果进行假阳性率控制的方法。