一、系统总的CPU上下文切换情况
vmstat 1 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 3 0 0 2960728 176248 5030840 0 0 1 33 0 0 0 0 99 0 0 0 0 0 2960456 176248 5030840 0 0 0 80 1788 3004 1 0 99 0 0 0 0 0 2960084 176248 5030844 0 0 0 136 1743 3008 0 0 99 0 0 0 0 0 2960084 176248 5030844 0 0 0 64 1595 2917 0 0 100 0 0 0 0 0 2960084 176248 5030844 0 0 0 76 1733 3099 1 0 99 0 0 0 0 0 2960084 176248 5030848 0 0 0 92 1687 3008 0 1 99 0 0

二、案例分析
1、分析环境
机器配置:2 CPU,4GB 内存
预先安装 sysbench
cnetos 7.2
yum -y install sysbench
三、分析操作
终端一
# 以 10 个线程运行 5 分钟的基准测试,模拟多线程切换的问题 $ sysbench --threads=10 --max-time=300 threads run
|
|
|
终端二
# 每隔 1 秒输出 1 组数据(需要 Ctrl+C 才结束)
[root@nfs ~]# vmstat 1 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 6 0 45412 1585156 0 351460 10 38 46 39 118 10 2 8 90 0 0 8 0 45412 1585156 0 351468 0 0 0 0 2023 2208584 17 83 0 0 0 7 0 45412 1585156 0 351468 0 0 0 0 2008 2183632 18 82 1 0 0 8 0 45412 1585156 0 351468 0 0 0 0 2013 2278429 17 83 0 0 0 8 0 45412 1585156 0 351468 0 0 0 0 2008 2251628 18 82 0 0 0 6 0 45412 1585156 0 351468 0 0 0 0 2014 2236468 19 81 0 0 0 7 0 45412 1585156 0 351468 0 0 0 0 2004 2255035 17 83 0 0 0 6 0 45412 1585156 0 351468 0 0 0 0 2020 2212782 18 82 1 0 0 7 0 45412 1585156 0 351468 0 0 0 0 2013 2194160 19 81 0 0 0
你应该可以发现,cs列的上下文切换次数从之前的10骤然上升了220万,同时,注意观察其他几个指标
r 列:就绪队列的长度已经到了 8,远远超过了系统 CPU的个数2,所以肯定会有大量的CPU竞争
us(user)和 sy(system)列:这两列的 CPU使用率加起来上升到了 100%,其中系统CPU使用率,也就是sy列高达90%说明CPU主要被内核占用了
in 列:中断次数也上升到了 1 万左右,说明中断处理也是个潜在的问题
综合这几个指标,我们可以知道,系统的就绪队列过长,也就是正在运行和等待的CPU进程数过多,导致大量的上下文切换,而上下文切换还又导致了系统CPU的占用率升高
终端三
那么到底是是哪个进程导致了这些问题了
[root@nfs ~]# pidstat -w -u 1 Linux 3.10.0-957.12.1.el7.x86_64 (nfs) 05/03/2019 _x86_64_ (2 CPU) 12:58:57 PM UID PID %usr %system %guest %wait %CPU CPU Command 12:58:59 PM 0 9183 31.07 162.14 0.00 0.00 193.20 0 sysbench 12:58:59 PM 0 9196 0.00 0.97 0.00 0.00 0.97 0 kworker/0:0 12:58:57 PM UID PID cswch/s nvcswch/s Command 12:58:59 PM 0 3 1.94 0.00 ksoftirqd/0 12:58:59 PM 0 9 7.77 0.00 rcu_sched 12:58:59 PM 0 103 1.94 0.00 kworker/1:2 12:58:59 PM 0 5823 10.68 0.00 vmtoolsd 12:58:59 PM 0 6969 0.97 0.00 sshd 12:58:59 PM 0 9066 0.97 0.00 kworker/u256:1 12:58:59 PM 0 9195 0.97 0.00 vmstat 12:58:59 PM 0 9196 1.94 0.00 kworker/0:0 12:58:59 PM 0 9198 0.97 0.00 pidstat
从 pidstat 的输出你可以发现,CPU 使用率的升高果然是 sysbench 导致的,它的 CPU 使用率已经达到了 100%但是上下文切换则是来自其他进程,包括非自愿上下文切换频率最高的pidstat
以及自愿上下文切换频率最高的内核线程kworker 和 sshd
不过,细心的你肯定也发现了一个怪异的事儿:pidstat 出的上下文切换次数,加起来也就几百,比 vmstat 的 220万明显小了太多。这是怎么回事呢?难道是工具本身出了错吗?
通过运行 man pidstat ,你会发现,pidstat默认显示进程的指标数据,加上 -t 参数后,才会输出线程的指标
我们还是在第三个终端里, Ctrl+C 停止刚才的 pidstat 命令,然后运行下面的命令,观察中断的变化情况.
[root@nfs ~]# pidstat -wt 1 Linux 3.10.0-957.12.1.el7.x86_64 (nfs) 05/03/2019 _x86_64_ (2 CPU) 01:00:35 PM UID TGID TID cswch/s nvcswch/s Command 01:00:36 PM 0 3 - 0.93 0.00 ksoftirqd/0 01:00:36 PM 0 - 3 0.93 0.00 |__ksoftirqd/0 01:00:36 PM 0 9 - 17.76 0.00 rcu_sched 01:00:36 PM 0 - 9 17.76 0.00 |__rcu_sched 01:00:36 PM 0 14 - 3.74 0.00 ksoftirqd/1 01:00:36 PM 0 - 14 3.74 0.00 |__ksoftirqd/1 01:00:36 PM 0 103 - 1.87 0.00 kworker/1:2 01:00:36 PM 0 - 103 1.87 0.00 |__kworker/1:2 01:00:36 PM 0 5823 - 10.28 0.00 vmtoolsd 01:00:36 PM 0 - 5823 10.28 0.00 |__vmtoolsd 01:00:36 PM 0 - 6755 0.93 0.00 |__tuned 01:00:36 PM 0 - 6666 0.93 0.00 |__in:imjournal 01:00:36 PM 0 6969 - 0.93 0.00 sshd 01:00:36 PM 0 - 6969 0.93 0.00 |__sshd 01:00:36 PM 0 9066 - 0.93 0.00 kworker/u256:1 01:00:36 PM 0 - 9066 0.93 0.00 |__kworker/u256:1 01:00:36 PM 0 - 9184 37752.34 157714.02 |__sysbench 01:00:36 PM 0 - 9185 43673.83 153500.00 |__sysbench 01:00:36 PM 0 - 9186 32598.13 150383.18 |__sysbench 01:00:36 PM 0 - 9187 31631.78 179364.49 |__sysbench 01:00:36 PM 0 - 9188 43047.66 129503.74 |__sysbench 01:00:36 PM 0 - 9189 25115.89 170748.60 |__sysbench 01:00:36 PM 0 - 9190 40545.79 179413.08 |__sysbench 01:00:36 PM 0 - 9191 48101.87 157711.21 |__sysbench 01:00:36 PM 0 - 9192 31725.23 164217.76 |__sysbench 01:00:36 PM 0 - 9193 37538.32 159869.16 |__sysbench 01:00:36 PM 0 9195 - 0.93 0.00 vmstat 01:00:36 PM 0 - 9195 0.93 0.00 |__vmstat 01:00:36 PM 0 9196 - 1.87 0.00 kworker/0:0 01:00:36 PM 0 - 9196 1.87 0.00 |__kworker/0:0 01:00:36 PM 0 9200 - 0.93 0.93 pidstat 01:00:36 PM 0 - 9200 0.93 0.93 |__pidstat
现在你就能看到了,虽然 sysbench 进程(也就是主线程)的上下文切换次数看起来并不多,但它的子线程的上下文切换粗疏却又很多,
看来,上下文切换醉魁祸首,还是过多的线程
[root@nfs ~]# tail -15 /proc/interrupts IWI: 6600 5405 IRQ work interrupts RTR: 0 0 APIC ICR read retries RES: 22360 25295 Rescheduling interrupts CAL: 1158 647 Function call interrupts TLB: 23862 8639 TLB shootdowns TRM: 0 0 Thermal event interrupts THR: 0 0 Threshold APIC interrupts DFR: 0 0 Deferred Error APIC interrupts MCE: 0 0 Machine check exceptions MCP: 35 35 Machine check polls ERR: 0 MIS: 0 PIN: 0 0 Posted-interrupt notification event NPI: 0 0 Nested posted-interrupt event PIW: 0 0 Posted-interrupt wakeup event
观察一段时间,你可以发现,变化速度最快的是重调度中断,这中断类似表示,唤醒空闲状态的CPU来调度新的任务运行,这是多处理器中,调度器用来分散任务到不同CPU的机制,通常也被称为处理间中断
cswch过多说明资源IO问题,nvcswch过多说明调度争抢cpu过多,中断次数变多说明cpu被中断程序调用
四、小结
1、每秒上下文奇幻多少次才算正常呢?
这个数值其实取决于系统本身的CPU性能,在我看来,如果系统上下文切换次数比较稳定,那么从数百一万以内,都有应该算是正常的,
但当上下文奇幻次数超过一万次,或者切换次数出现数量级的增长时,就很可能已经出现性能问题
2、根据上下文切换类型再具体分析
自愿上下文切换变多了,说明进程都在等待自愿,有可能发生了I/O等其他问题;
非自愿上下文切换变多了,说明进程都在被强制调动,也就是在争抢CPU,说明CPU的确成了瓶颈
中断次数变多了了,说明CPU被中断处理程序占用,还需要通过查看/proc/interrupts 文件来分析具体的中断类型。
3、假设我现在有一台Linux服务器负载变高了,如何找到原因?如何排查分析
Step1: 首先通过uptime看下最近一段时间的负载怎么样,能够得出是徒然变高还是变高已经有一段时间了,比较5min和15min系统负载的数据
Step2: 分析系统负载高的原因有哪些?根据前面学习的,可能是计算密集型任务导致,IO密集型任务导致,还有可能是大量线程等待调度导致,还有可能是几种情况的组合同时存在。这里要怎么分析可以通过mpstat工具来区分,主要关注的几个指标是%idle %iowait %wait
Step3: 如果通过上一步确认是大量线程等待调度导致,那么可以通过vmstat来查看系统整体的上下文切换情况,主要关注cs/in/r/b 四个指标
Step4: 我们已经知道了系统负载高的原因,进一步通过pidstat 查看具体是那一个线程导致的详细原因
4、拍错思路总结
登录到服务器,现在系统负载怎么样 。 高的话有三种情况,首先是cpu使用率 ,其次是io使用率 ,之后就是两者都高 。
cpu 使用率高,可能确实是使用率高, 也的可能实际处理不高而是进程太多切换上下文频繁 , 也可能是进程内线程的上下文切换频繁
io 使用率高 , 说明 io 请求比较大, 可能是 文件io 、 网络io 。
工具 :
系统负载 : uptime ( watch -d uptime)看三个阶段平均负载
系统整体情况 : mpstat (mpstat -p ALL 3) 查看 每个cpu当前的整体状况,可以重点看用户态、内核态、以及io等待三个参数
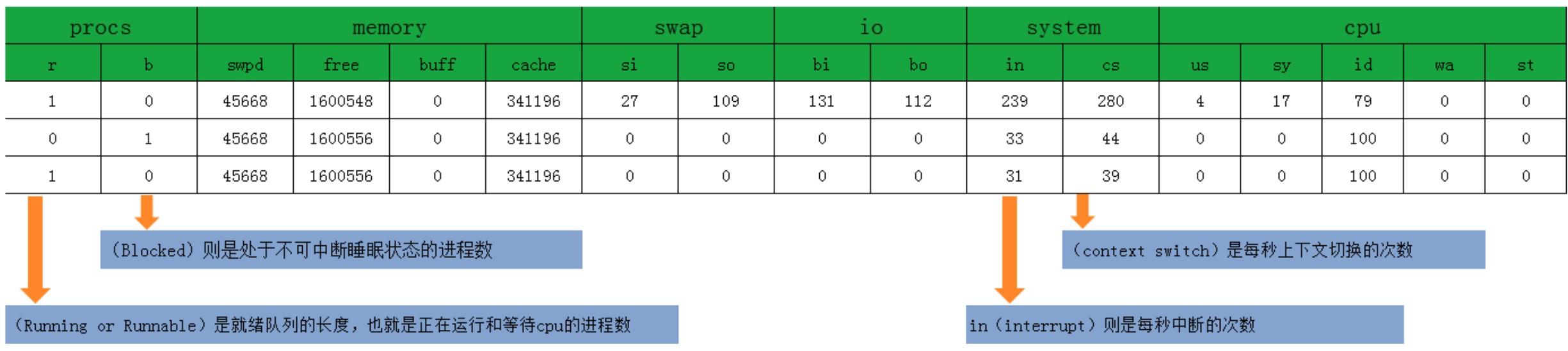
系统整体的平均上下文切换情况 : vmstat (vmstat 3) 可以重点看 r (进行或等待进行的进程)、b (不可中断进程/io进程) 、in (中断次数) 、cs(上下文切换次数)
查看详细的上下文切换情况 : pidstat (pidstat -w(进程切换指标)/-u(cpu使用指标)/-wt(线程上下文切换指标)) 注意看是自愿上下文切换、还是被动上下文切换
io使用情况 : iostat