一:通用套路
无论哪门语言,基本都是
- 变量开始,
- 数据类型,
- 运算符,
- 控制语句,
- 函数,
- 面向对象,
- 并发,
- 网络,
- 框架,
基本都是这么个套路下来
二:变量
变量就是为临时数据起个名字,方便后面改动数据和调用数据,否则你总不能拿着数据的内存地址的二进制操作吧
函数名是变量,类名也是变量,都只是为不同的数据起个名字,这个数据可能只是一个字面量,也可能是一小段代码,也可能是一大段代码
命名规则:数字 字母 下划线组成,数字不能做开头,大神已经用的关键字你不能用作你的变量名.
三:常量
和变量基本无异,只不过约定是变量名全大写,定义后不能再修改值,非要改也没人拦的住,就像类中的私有,只是在namespace中修改了名字,让你找不到它了,但是你非要_类型.__私有名字去改它的值也没有人拦你.
四:注释
#单行注释 """ 多行注释 """ ''' 多行注释 '''
五:字符编码
python3默认的字符编码utf8,
内存中数据都是unicode编码形式存在,无论哪个国家的人输入的内容到内存中都是unicode,不会乱码.
unicode默认所有一个字母也用4bytes,232个符号标记完全可以枚举世界一切文字,原ascii一个字母就1bytes,这样扩充了4倍,当从内存存放到硬盘的时候IO压力变大了,
出现了弹性的utf8编码,英文还和ascii一样1bytes,中文占3bytes,且utf8基本98%都是这个保存,期待有一天内存中数据编码全部变成utf8.
键盘输入代码以unicode的形式进入内存,看到的确实是输入的内容,因为os把内存中的0101,又变成了输入内容显示到屏幕.
保存为utf8,说明os中有unicode到utf8的二进制转换对照表
打开文件编码格式为utf8,到内存是unicode说明os中还有utf8到unicode的转换对照表
其他编码方式也可以说明,os中保存了很多编码方式和unicode互转的对照表.
乱码:1.编辑器输入了中文,到内存中是unicode编码,保存时用了韩语编码,他不认识你输入的中文,保存时就是乱码,下次打开肯定还是乱码.
2.保存时用utf8编码,打开时用gbk,也会乱码.
六:数据类型
之所以有数据类型一说,映射现实世界当中的数字 成语 段落,之所以一眼就能看出这是一个数字或者这是一个段落,是因为我们进行了学习,后天的条件反射
计算机是不认识数字和str的,除非你告诉他,怎么告诉他?数据类型就是告诉他这是什么数据,怎么处理.
数据类型在python就是内置对象,都是小写的类形式存在,封装了处理数据的方法.
int:python3中只有int,对python2中的长整型进行了整合.
float:用的比较少,6//5=1 6/5=1.2后者常见为小数,divmod(7,3)=(2,1),(除,余)
str list tuple dict set后面详解
可变数据类型:id变为前提,通过方法改变了value
不可变类型:就没有封装方法改变value,一旦value变了,就意味着id变了
重新赋值不是改变value,而是改变了id
id变了value
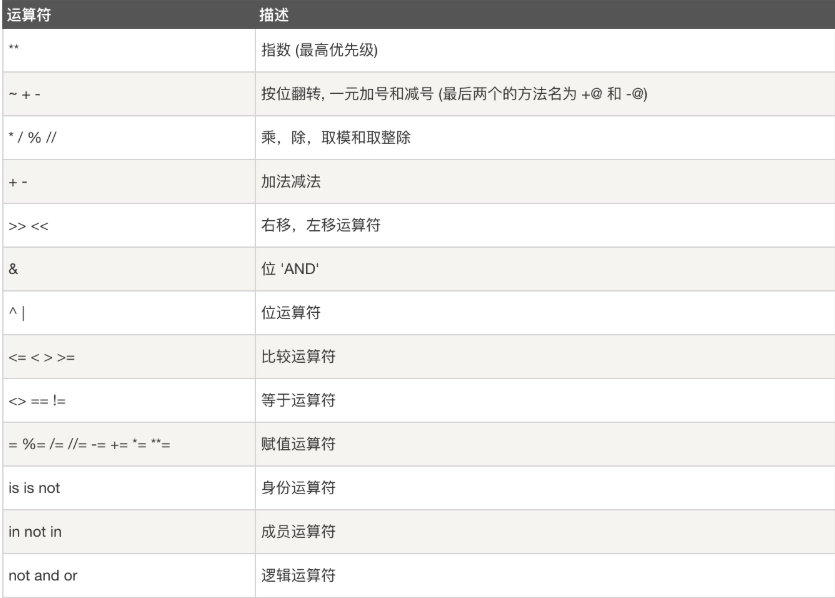
七:运算符
- 算数运算

- 赋值运算= += *= //= **=等
- 逻辑运算
优先级:not>and>or - 比较运算符:结果是bool a>b
三元运算a=true if a>b else false - 成员运算符
in , not in
运算符优先级