接口java.util.Map,包括3个实现类:HashMap、Hashtable、TreeMap。当然还有LinkedHashMap、ConcurrentHashMap 、WeakHashMap。
Map是用来存储键值对的数据结构,键值对在数组中通过数组下标来对其内容索引的,而键值对在Map中,则是通过对象来进行索引,用来索引的对象叫做key,其对应的对象叫value。
一、Map的两种取值方式KeySet、entrySet
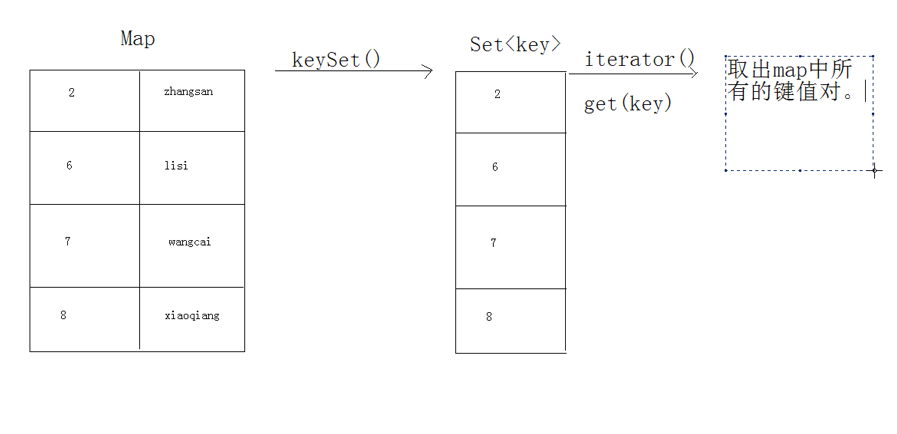
(一)KeySet
先获取所有键的集合,再根据键获取对应的值。(即先找到丈夫,再去找妻子)
keySet的演示图解
(二)entrySet
先获取map中的键值关系封装成一个个的entry对象, 存储到一个Set集合中,再迭代这个Set集合, 根据entry获取对应的key和value。向集合中存储自定义对象(entry类似于是结婚证)
entrySet的演示图解

HashMap : 内部结构是哈希表,不是同步的。允许null作为键,null作为值。
TreeMap : 内部结构是二叉树,不是同步的。可以对Map集合中的键进行排序。
二、HashMap
(一)HashMap概述
HashMap是基于哈希表的Map接口的非同步实现,此实现提供所有可选的映射操作,并允许使用null值和null键
它不保证映射的顺序,HashMap是Hashtable的轻量级实现(非线程安全的实现),它们都完成了Map接口。
(二)HashMap的工作原理
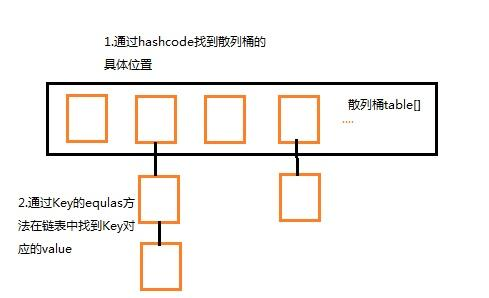
1.HashMap是基于hashing的原理,我们使用put(key, value)存储对象到HashMap中,使用get(key)从HashMap中获取对象。当我们给put()方法传递键和值时,我们先对键调用hashCode()方法,计算并返回的hashCode是用于找到Map数组的bucket位置来储存Node 对象。这里关键点在于指出,HashMap是在bucket中储存键对象和值对象,作为Map.Node 。
2.以下是HashMap初始化 ,简单模拟数据结构
Node[] table = new Node[16] //散列桶初始化 table class Node{ hash; key; value; node next; //用于指向链表的下一层(产生冲突,用拉链法) }
3.一下是具体的put过程(JDK1.8)
对Key求Hash值,然后再计算下标
如果没有碰撞,直接放入桶中(碰撞的意思是计算得到的Hash值相同,需要放到同一个bucket中)
如果碰撞了,以链表的方式链接到后面
如果链表长度超过阀值( TREEIFY THRESHOLD==8),就把链表转成红黑树,链表长度低于6,就把红黑树转回链表
如果节点已经存在就替换旧值
如果桶满了(容量16*加载因子0.75),就需要 resize(扩容2倍后排)
4.一下是具体get过程(考虑特殊情况如果两个键的hashcode相同,你如何获取值对象?)
当我们调用get()方法,HashMap会使用键对象的hashcode找到bucket位置,找到bucket位置之后,会调用keys.equals()方法去找到链表中正确的节点,最终找到要找的值对象。
(三)有什么办法可以减少碰撞
开放定址法。
当冲突发生时,使用某种探查技术在散列表中形成一个探查(测)序列。沿此序列逐个单元地查找,直到找到给定的地址。
按照形成探查序列的方法不同,可将开放定址法区分为线性探查法、二次探查法、双重散列法等。
下面给一个线性探查法的例子
问题:已知一组关键字为(26,36,41,38,44,15,68,12,06,51),用除余法构造散列函数,用线性探查法解决冲突构造这组关键字的散列表。
解答:为了减少冲突,通常令装填因子α由除余法因子是13的散列函数计算出的上述关键字序列的散列地址为(0,10,2,12,5,2,3,12,6,12)。
前5个关键字插入时,其相应的地址均为开放地址,故将它们直接插入T[0],T[10),T[2],T[12]和T[5]中。
当插入第6个关键字15时,其散列地址2(即h(15)=15%13=2)已被关键字41(15和41互为同义词)占用。故探查h1=(2+1)%13=3,此地址开放,所以将15放入T[3]中。
当插入第7个关键字68时,其散列地址3已被非同义词15先占用,故将其插入到T[4]中。
当插入第8个关键字12时,散列地址12已被同义词38占用,故探查hl=(12+1)%13=0,而T[0]亦被26占用,再探查h2=(12+2)%13=1,此地址开放,可将12插入其中。
类似地,第9个关键字06直接插入T[6]中;而最后一个关键字51插人时,因探查的地址12,0,1,…,6均非空,故51插入T[7]中。
(四)如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?有什么问题?
默认的负载因子大小为0.75,也就是说,当一个map填满了75%的bucket时候,和其它集合类(如ArrayList等)一样,将会创建原来HashMap大小的两倍的bucket数组,来重新调整map的大小,并将原来的对象放入新的bucket数组中。这个过程叫作rehashing,因为它调用hash方法找到新的bucket位置。这个值只可能在两个地方,一个是原下标的位置,另一种是在下标为<原下标+原容量>的位置
当重新调整HashMap大小的时候,确实存在条件竞争,因为如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小。在调整大小的过程中,存储在链表中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在链表的尾部,而是放在头部,这是为了避免尾部遍历(tail traversing)。如果条件竞争发生了,那么就死循环了。(多线程的环境下不使用HashMap)
为什么多线程会导致死循环,它是怎么发生的?
HashMap的容量是有限的。当经过多次元素插入,使得HashMap达到一定饱和度时,Key映射位置发生冲突的几率会逐渐提高。这时候,HashMap需要扩展它的长度,也就是进行Resize。1.扩容:创建一个新的Entry空数组,长度是原数组的2倍。2.ReHash:遍历原Entry数组,把所有的Entry重新Hash到新数组。
三、TreeMap
https://blog.csdn.net/chenssy/article/details/26668941
四、HashTable