Linux高级篇–MYSQL数据库之函数和存储过程、用户和权限管理、存储引擎、服务器选项,系统和状态变量
一、 函数和存储过程
函数
- 函数:系统函数和自定义函数
系统函数:https://dev.mysql.com/doc/refman/5.7/en/func-op-summary-ref.html - 自定义函数(user-defined function UDF)
保存在mysql.proc表中
创建UDF:
CREATE [AGGREGATE] FUNCTION function_name(parameter_nametype,[parameter_nametype,…])
RETURNS {STRING|INTEGER|REAL}
runtime_body
说明:
参数可以有多个,也可以没有参数
必须有且只有一个返回值
自定义函数
- 查看函数列表:
SHOW FUNCTION STATUS; - 查看函数定义
SHOW CREATE FUNCTION function_name - 删除UDF:
DROP FUNCTION function_name - 调用自定义函数语法:
SELECT function_name(parameter_value,…)
示例:无参UDF
CREATE FUNCTION simpleFun() RETURNS VARCHAR(20) RETURN "Hello World!";
示例:有参数UDF
DELIMITER //
CREATE FUNCTION deleteById(uidSMALLINT UNSIGNED) RETURNS VARCHAR(20)
BEGIN
DELETE FROM students WHERE stuid= uid;
RETURN (SELECT COUNT(uid) FROM students);
END//
DELIMITER ;
- 自定义函数中定义局部变量语法:
DECLARE 变量1[,变量2,… ]变量类型[DEFAULT 默认值] - 说明:局部变量的作用范围是在BEGIN…END程序中,而且定义局部变量语句必须在BEGIN…END的第一行定义
示例: 删除一条记录,返回删除后表的总记录的值
DELIMITER //
CREATE FUNCTION addTwoNumber(x SMALLINT UNSIGNED, Y SMALLINT UNSIGNED)
RETURNS SMALLINT
BEGIN
DECLARE a, b SMALLINT UNSIGNED;
SET a = x, b = y;
RETURN a+b;
END//
DELIMITER ;
MariaDB [hellodb]> select deletebyid(26); 调用该函数,student表记录总数为26
+----------------+
| deletebyid(26) |
+----------------+
| 25 | 返回值为25
+----------------+
1 row in set (0.01 sec)
在数据库中,分号表示命令输入结束,开始执行命令,为了不让分号作为命令执行的标记符号,
使用命令DELIMITER把//代替分号作为命令执行的标记,即DELIMITER //,在命令最后再次输入//表示输入命令结束,开始执行命令。
最后的DELIMITER ;表示把命令执行的标记符号从//更改为分号
- 为变量赋值语法
SET parameter_name= value[,parameter_name= value…]
SELECT INTO parameter_name
示例:
...
DECLARE x int;
SELECT COUNT(id) FROM tdb_nameINTO x;
RETURN x;
END//
select addtwonumber(10,20) as sum 给函数定义别名
存储过程
- 存储过程:存储过程保存在mysql.proc表中
- 创建存储过程
CREATE PROCEDURE sp_name ([ proc_parameter [,proc_parameter …]])
routime_body
其中:proc_parameter : [IN|OUT|INOUT] parameter_name type
其中IN表示输入参数,OUT表示输出参数,INOUT表示既可以输入也可以输出;param_name表示参数名称;type表示参数的类型 - 查看存储过程列表
SHOW PROCEDURE STATUS - 查看存储过程定义
SHOW CREATE PROCEDURE sp_name - 调用存储过程
CALL sp_name ([ proc_parameter [,proc_parameter …]])
CALL sp_name
说明:当无参时,可以省略"()",当有参数时,不可省略"()” - 存储过程修改
ALTER语句修改存储过程只能修改存储过程的注释等无关紧要的东西,不能修改存储过程体,所以要修改存储过程,方法就是删除重建 - 删除存储过程
DROP PROCEDURE [IF EXISTS] sp_name
示例1:创建无参存储过程
delimiter //
CREATE PROCEDURE showTime()
BEGIN
SELECT now();
END//
delimiter ;
CALL showTime; #调用函数
示例2:创建含参存储过程:只有一个IN参数
delimiter //
CREATE PROCEDURE selectById(IN uid SMALLINT UNSIGNED)
BEGIN
SELECT * FROM students WHERE stuid = uid;
END//
delimiter ;
call selectById(2); 调用函数
示例3:
delimiter //
CREATE PROCEDURE dorepeat(n INT)
BEGIN
SET @i = 0;
SET @sum = 0;
REPEAT SET @sum = @sum+@i; SET @i = @i + 1;
UNTIL @i > n END REPEAT;
END//
delimiter ;
CALL dorepeat(100);
SELECT @sum;
示例4:创建含参存储过程:包含IN参数和OUT参数
delimiter //
CREATE PROCEDURE deleteById(IN uid SMALLINT UNSIGNED, OUT num SMALLINT UNSIGNED) #num的值为删除的函数
BEGIN
DELETE FROM students WHERE stuid = uid; #删除stuid=uid的记录
SELECT row_count() into num; #把修改过行的记录数传给num
#row_count() 系统内置函数,修改过的行的记录数
END//
delimiter ;
call deleteById(2,@Line); #调用存储过程并对IN和OUT进行赋值
SELECT @Line; #显示@Line的值
说明:创建存储过程deleteById,包含一个IN参数和一个OUT参数.
调用时,传入删除的ID和保存被修改的行数值的用户变量@Line.
select @Line;是指输出被影响行数
- 存储过程优势
存储过程把经常使用的SQL语句或业务逻辑封装起来,预编译保存在数据库中,当需要时从数据库中直接调用,省去了编译的过程
提高了运行速度
同时降低网络数据传输量 - 存储过程与自定义函数的区别
存储过程实现的过程要复杂一些,而函数的针对性较强
存储过程可以有多个返回值,而自定义函数只有一个返回值
存储过程一般独立的来执行,而函数往往是作为其他SQL语句的一部分来使用
流程控制
- 存储过程和函数中可以使用流程控制来控制语句的执行
- 流程控制:
IF:用来进行条件判断。根据是否满足条件,执行不同语句
CASE:用来进行条件判断,可实现比IF语句更复杂的条件判断
LOOP:重复执行特定的语句,实现一个简单的循环
LEAVE:用于跳出循环控制
ITERATE:跳出本次循环,然后直接进入下一次循环
REPEAT:有条件控制的循环语句。当满足特定条件时,就会跳出循环语句
WHILE:有条件控制的循环语句
触发器
- 触发器的执行不是由程序调用,也不是由手工启动,而是由事件来触发、激活从而实现执行
- 创建触发器
CREATE
[DEFINER = { user | CURRENT_USER }]
TRIGGER trigger_name
trigger_time trigger_event
ON tbl_name FOR EACH ROW
trigger_body - 说明:
trigger_name:触发器的名称
trigger_time:{ BEFORE | AFTER },表示在事件之前或之后触发
before 在事件发生之前执行某操作,该操作完成后,原有事件的操作将不会执行,即触发器执行的操作代替事件的操作
after 在事件发生之后执行某操作,该操作完成后,原有事件的操作将继续进行
trigger_event::{ INSERT |UPDATE | DELETE },触发的具体事件
tbl_name:该触发器作用在表名
示例1:
CREATE TABLE student_info (
stu_id INT(11) NOT NULL AUTO_INCREMENT,
stu_name VARCHAR(255) DEFAULT NULL,
PRIMARY KEY (stu_id)
);
CREATE TABLE student_count (
student_count INT(11) DEFAULT 0
);
INSERT INTO student_count VALUES(0);
示例2:创建触发器,在向学生表INSERT数据时,学生数增加,DELETE学生时,学生数减少
CREATE TRIGGER trigger_student_count_insert
AFTER INSERT
ON student_info FOR EACH ROW
UPDATE student_count SET student_count=student_count+1;
CREATE TRIGGER trigger_student_count_delete
AFTER DELETE
ON student_info FOR EACH ROW
UPDATE student_count SET student_count=student_count-1;
- 查看触发器
SHOW TRIGGERS
查询系统表information_schema.triggers的方式指定查询条件,查看指定的触发器信息。
mysql> USE information_schema;
Database changed
mysql> SELECT * FROM triggers WHERE trigger_name='trigger_student_count_insert';
- 删除触发器
DROP TRIGGER trigger_name;
二、 MySQL用户和权限管理
- 元数据数据库:mysql
系统授权表:
db, host, user
columns_priv, tables_priv, procs_priv, proxies_priv - 用户账号:
‘USERNAME’@‘HOST’:
@‘HOST’:
主机名;
IP地址或Network;
通配符: % _
示例:172.16.%.%
用户管理
- 创建用户:CREATE USER
CREATE USER ‘USERNAME’@‘HOST’ [IDENTIFIED BY ‘password’];
默认权限:USAGE
create user test@'192.168.32.129' identified by 'centos';
知识扩展:
在192.168.32.129主机的/etc/hosts文件中写入192.168.32.130主机的ip与域名的对应关系
vim /etc/hosts
192.168.32.130 centos7.localdomain centos7.localdomain为130主机的主机名
则可以使用以下方式连接数据库
mysql -utest -pcentos123456 -hcentos7.localdomain 说明数据库把主机名解析为192.168.32.130连接数据库
- 用户重命名:RENAME USER
RENAME USER old_user_name TO new_user_name - 删除用户:
DROP USER ‘USERNAME’@‘HOST’
示例:删除默认的空用户
DROP USER ‘’@‘localhost’;
- 修改密码:
mysql>SET PASSWORD FOR ‘user’@‘host’ = PASSWORD(‘password’);
mysql>UPDATE mysql.user SET password=PASSWORD(‘password’) WHERE clause;
此方法需要执行下面指令才能生效:
mysql> FLUSH PRIVILEGES;
#mysqladmin -u root -poldpass password ‘newpass’ - 忘记管理员密码的解决办法:
启动mysqld进程时,为其使用如下选项:
--skip-grant-tables
--skip-networking
使用UPDATE命令修改管理员密码
关闭mysqld进程,移除上述两个选项,重启mysqld
实验:破解mysql数据库管理员密码
如何破解mysql管理员密码
(1)更改配置文件
vim /etc/my.cnf
[mysqld]
skip-grant-tables 启动数据库服务时,不检查授权表
skip-networking 生产环境中,为了防止其他用户在破解口令时连接数据库,处于维护模式,禁止其他用户登录
(2)重启数据库服务
systemctl restart mariadb
(3)再次连接数据库,无需密码
[root@centos7-1 ~]#mysql
清除或更改密码
update mysql.user set password = ''; 设置密码为空
flush privileges; update命令通过更改表的方式清空密码,因此需要刷新策略
(4)删除配置文件/etc/my.cnf中的skip-grant-tables和skip-networking,回复原有配置信息
重启数据库服务,再次连接数据库
如果是多实例配置数据库,只需在服务脚本中增加--skip-grant-tables即可
${cmd_path}/mysqld_safe --skip-grant-tables --defaults-file=${mysql_basedir}/${port}/etc/my.cnf &> /dev/null
MySQL权限管理
- 权限类别:
管理类
程序类
数据库级别
表级别
字段级别 - 管理类
CREATE TEMPORARY TABLES
CREATE USER
FILE
SUPER
SHOW DATABASES
RELOAD
SHUTDOWN
REPLICATION SLAVE
REPLICATION CLIENT
LOCK TABLES
PROCESS - 程序类: FUNCTION、PROCEDURE、TRIGGER
CREATE
ALTER
DROP
EXCUTE - 库和表级别:DATABASE、TABLE
ALTER
CREATE
CREATE VIEW
DROP
INDEX
SHOW VIEW
GRANT OPTION:能将自己获得的权限转赠给其他用户 - 数据操作:
SELECT
INSERT
DELETE
UPDATE - 字段级别:
SELECT(col1,col2,…)
UPDATE(col1,col2,…)
INSERT(col1,col2,…) - 所有权限:ALL PRIVILEGES 或 ALL
授权
参考:https://dev.mysql.com/doc/refman/5.7/en/grant.html
- 语法:
GRANT priv_type [(column_list)],... ON [object_type] priv_level TO 'user'@'host' [IDENTIFIED BY 'password'] [WITH GRANT OPTION];
priv_type: ALL [PRIVILEGES]
object_type:TABLE | FUNCTION | PROCEDURE
priv_level: *(所有库) | *.* | db_name.* | db_name.tbl_name | tbl_name(当前库的表) | db_name.routine_name(指定库的函数,存储过程,触发器)
with_option: GRANT OPTION
| MAX_QUERIES_PER_HOUR count
| MAX_UPDATES_PER_HOUR count
| MAX_CONNECTIONS_PER_HOUR count
| MAX_USER_CONNECTIONS count
示例:GRANT SELECT (col1), INSERT (col1,col2) ON mydb.mytbl TO ‘someuser’@‘somehost’;
- 回收授权:REVOKE priv_type [(column_list)] [, priv_type [(column_list)]] … ON [object_type] priv_level FROM user [, user] …
示例:
REVOKE DELETE ON testdb.* FROM 'testuser'@'%' - 查看指定用户获得的授权:
Help SHOW GRANTS
SHOW GRANTS FOR ‘user’@‘host’;
SHOW GRANTS FOR CURRENT_USER[()]; - 注意:MariaDB服务进程启动时会读取mysql库中所有授权表至内存
(1) GRANT或REVOKE等执行权限操作会保存于系统表中,MariaDB的服务进程通常会自动重读授权表,使之生效
(2) 对于不能够或不能及时重读授权表的命令,可手动让MariaDB的服务进程重读授权表:mysql> FLUSH PRIVILEGES
注意:grant all on . to test@‘192.168.32.129’; 授权test用户可以查询所有数据库中的所有表
在192.168.32.129主机上测试,发现并不能查看所有数据库,这时需要退出重新登录才能具有该权限,这是因为被授权用户在线时不能获取到权限,因此需要重新登录
撤销权限时也需要被撤销权限用户重新登陆数据库才能生效
三、 MySQL体系结构
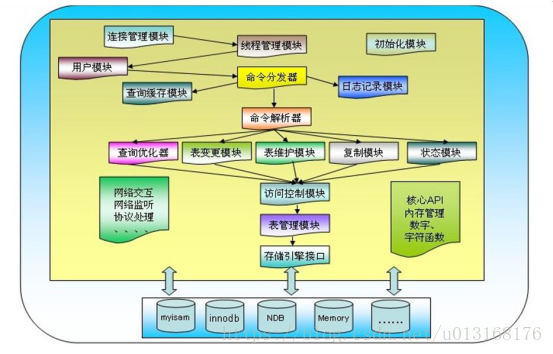
术语解释:
事务:多个操作的完整集合,这几个操作必须作为一个整体出现,一次性全部做完,myisam不支持此特性
加锁:当对数据库中的表操作时,对该表或表中的内容进行加锁,防止多个人同时操作,会影响数据库的并发性,myisam支持表级锁(更改表时,对整个表加锁),innodb支持行级锁(更改表时,只对某一行加锁),innodb并发性更高,更加灵活
MVCC 多版本并发控制机制
多个事务对某个表同时进行操作时如t1事务进行写操作,t2事务进行查询操作,此时写操作尚未完成,操作过程中形成的数据我们称之为脏数据,为了防止t2事务查看到脏数据,我们可以使用表锁进行控制,但这样一来就需要等待写操作完成后才能进行查询,这样一来就降低了效率。mvcc机制是当t2事务查询表时,查询到的表的状态为写操作之前的表状态,即查看的是表的某一时间点的一个快照。这样就形成了多个版本的并存,如果有更多事务同时进行读操作,也就形成了多版本的并发控制
select查到记录的insert事务编号比当前事务编号要小(早),delete事务编号比当前事务编号要大(晚)
mysisam使用场景:速度快,存放不重要的数据,并发性差
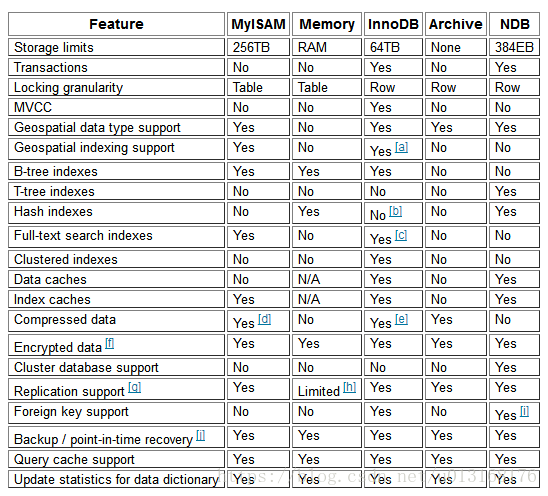
四、存储引擎
存储引擎
注意:InnoDB support for FULLTEXT indexes is available in MySQL 5.6.4 and later.
存储引擎比较:https://docs.oracle.com/cd/E17952_01/mysql-5.5-en/storage-engines.html
-
MyISAM引擎特点:
不支持事务
表级锁定
读写相互阻塞,写入不能读,读时不能写
只缓存索引
不支持外键约束
不支持聚簇索引
读取数据较快,占用资源较少
不支持MVCC(多版本并发控制机制)高并发
崩溃恢复性较差
MySQL5.5.5前默认的数据库引擎 -
MyISAM存储引擎适用场景
只读(或者写较少)、表较小(可以接受长时间进行修复操作) -
MyISAM引擎文件
tbl_name.frm 表格式定义
tbl_name.MYD 数据文件
tbl_name.MYI 索引文件 -
InnoDB引擎特点
行级锁
支持事务,适合处理大量短期事务
读写阻塞与事务隔离级别相关
可缓存数据和索引
支持聚簇索引
崩溃恢复性更好
支持MVCC高并发
从MySQL5.5后支持全文索引
从MySQL5.5.5开始为默认的数据库引擎 -
InnoDB数据库文件
所有InnoDB表的数据和索引放置于同一个表空间中
表空间文件:datadir定义的目录下
数据文件:ibddata1, ibddata2, …
每个表单独使用一个表空间存储表的数据和索引
启用:innodb_file_per_table=ON
参看:https://mariadb.com/kb/en/library/xtradbinnodb-server-system-variables/#innodb_file_per_table
ON (>= MariaDB 5.5)
两类文件放在数据库独立目录中
数据文件(存储数据和索引):tb_name.ibd
表格式定义:tb_name.frm
其他存储引擎
- Performance_Schema:Performance_Schema数据库
- Memory :将所有数据存储在RAM中,以便在需要快速查找参考和其他类似数据的环境中进行快速访问。适用存放临时数据。引擎以前被称为HEAP引擎
- MRG_MyISAM:使MySQL DBA或开发人员能够对一系列相同的MyISAM表进行逻辑分组,并将它们作为一个对象引用。适用于VLDB(Very Large Data Base)环境,如数据仓库
- Archive :为存储和检索大量很少参考的存档或安全审核信息,只支持SELECT和INSERT操作;支持行级锁和专用缓存区
- Federated联合:用于访问其它远程MySQL服务器一个代理,它通过创建一个到远程MySQL服务器的客户端连接,并将查询传输到远程服务器执行,而后完成数据存取,提供链接单独MySQL服务器的能力,以便从多个物理服务器创建一个逻辑数据库。非常适合分布式或数据集市环境
其他数据库引擎
- BDB:可替代InnoDB的事务引擎,支持COMMIT、ROLLBACK和其他事务特性
- Cluster/NDB:MySQL的簇式数据库引擎,尤其适合于具有高性能查找要求的应用程序,这类查找需求还要求具有最高的正常工作时间和可用性
- CSV:CSV存储引擎使用逗号分隔值格式将数据存储在文本文件中。可以使用CSV引擎以CSV格式导入和导出其他软件和应用程序之间的数据交换
- BLACKHOLE :黑洞存储引擎接受但不存储数据,检索总是返回一个空集。该功能可用于分布式数据库设计,数据自动复制,但不是本地存储
- example:“stub”引擎,它什么都不做。可以使用此引擎创建表,但不能将数据存储在其中或从中检索。目的是作为例子来说明如何开始编写新的存储引擎
其他存储引擎
- MariaDB支持的其它存储引擎:
OQGraph
SphinxSE
TokuDB
Cassandra
CONNECT
SQUENCE
管理存储引擎
- 查看mysql支持的存储引擎:
show engines; - 查看当前默认的存储引擎:
show variables like ‘%storage_engine%’; - 设置默认的存储引擎:
vim /etc/my.conf
[mysqld]
default_storage_engine= InnoDB;
innodb_file_per_table=on 数据分开存放,便于管理,如果不加此项,5.5之前版本数据会集中存放,不利于管理
- 查看库中所有表使用的存储引擎
show table status from db_name; - 查看库中指定表的存储引擎
show table status like ’ tb_name ';
show create table tb_name; - 设置表的存储引擎:
CREATE TABLE tb_name(… ) ENGINE=InnoDB;
ALTER TABLE tb_name ENGINE=InnoDB;
MySQL中的系统数据库
- mysql数据库
是mysql的核心数据库,类似于Sql Server中的master库,主要负责存储数据库的用户、权限设置、关键字等mysql自己需要使用的控制和管理信息 - performance_schema数据库
MySQL 5.5开始新增的数据库,主要用于收集数据库服务器性能参数,库里表的存储引擎均为PERFORMANCE_SCHEMA,用户不能创建存储引擎为PERFORMANCE_SCHEMA的表 - information_schema数据库
MySQL 5.0之后产生的,一个虚拟数据库,物理上并不存在information_schema数据库类似与“数据字典”,提供了访问数据库元数据的方式,即数据的数据。比如数据库名或表名,列类型,访问权限(更加细化的访问方式)
五、 服务器选项,系统和状态变量
服务器配置
- mysqld选项,服务器系统变量和服务器状态变量
https://dev.mysql.com/doc/refman/5.7/en/mysqld-option-tables.html
https://mariadb.com/kb/en/library/full-list-of-mariadb-options-system-and-status-variables/ - 注意:其中有些参数支持运行时修改,会立即生效;有些参数不支持,且只能通过修改配置文件,并重启服务器程序生效;有些参数作用域是全局的,且不可改变;有些可以为每个用户提供单独(会话)的设置
- 获取mysqld的可用选项列表:
mysqld --help –verbose
mysqld --print-defaults 获取默认设置 - 服务器系统变量:分全局和会话两种
- 服务器状态变量:分全局和会话两种
- 获取运行中的mysql进程使用各服务器参数及其值
mysql> SHOW GLOBAL VARIABLES;
mysql> SHOW [SESSION] VARIABLES; - 设置服务器选项方法:
在命令行中设置:
shell> ./mysqld_safe –-skip-name-resolve=1;
在配置文件my.cnf中设置:
skip_name_resolve=1;
服务器端设置
- 修改服务器变量的值:
mysql> help SET - 修改全局变量:仅对修改后新创建的会话有效;对已经建立的会话无效
mysql> SET GLOBAL system_var_name=value;
mysql> SET @@global.system_var_name=value; - 修改会话变量:
mysql> SET [SESSION] system_var_name=value;
mysql> SET @@[session.]system_var_name=value; - 状态变量(只读):用于保存mysqld运行中的统计数据的变量,不可更改
mysql> SHOW GLOBAL STATUS;
mysql> SHOW [SESSION] STATUS;
示例:
set global character_set_results=gb2312 更改全局变量,对全部用户有效
show global variables like '%char%'; 查看全局变量
set character_set_results=gb2312 更改会话变量,只对当前会话有效
show variables like '%char%'; 查看会话变量
注意:会话级别变量优先级高于全局级别变量,而且一旦重启服务变量设置会恢复默认
服务器选项和服务器变量的区别:
服务器选项:可以加入配置文件中/etc/my.cnf,以-作为分隔符,重启服务才能生效
mysqld --verbose --help 查看服务器选项列表
服务器变量:不支持加入配置文件,以_作为分隔符,如果支持动态dynamic,则可以不重启服务生效,使用set命令设置,查询命令show variables like ' '
服务器变量SQL_MODE
- SQL_MODE:对其设置可以完成一些约束检查的工作,可分别进行全局的设置或当前会话的设置,参看:https://mariadb.com/kb/en/library/sql-mode/
- 常见MODE:
NO_AUTO_CREATE_USER
禁止GRANT创建密码为空的用户
NO_ZERO_DATE
在严格模式,不允许使用‘0000-00-00’的时间
ONLY_FULL_GROUP_BY
对于GROUP BY聚合操作,如果在SELECT中的列,没有在GROUP BY中出现,那么将认为这个SQL是不合法的
NO_BACKSLASH_ESCAPES
反斜杠“\”作为普通字符而非转义字符
PIPES_AS_CONCAT
将"||"视为连接操作符而非“或运算符”
知识扩展:
查看状态变量
show status like '';
show status like '%select%';
MariaDB [hellodb]> show status like '%select%';
+------------------------+-------+
| Variable_name | Value |
+------------------------+-------+
| Com_insert_select | 0 |
| Com_replace_select | 0 |
| Com_select | 2 |
| Select_full_join | 0 |
| Select_full_range_join | 0 |
| Select_range | 0 |
| Select_range_check | 0 |
| Select_scan | 8 |
+------------------------+-------+
其中的com_select对应的值为当前用户select查询次数
MariaDB [hellodb]> show status like '%insert%';
+-------------------------------+-------+
| Variable_name | Value |
+-------------------------------+-------+
| Com_insert | 0 |
| Com_insert_select | 0 |
| Delayed_insert_threads | 0 |
| Innodb_ibuf_discarded_inserts | 0 |
| Innodb_ibuf_merged_inserts | 0 |
| Innodb_rows_inserted | 0 |
| Qcache_inserts | 0 |
+-------------------------------+-------+
其中的com_insert对应的值为当前用户insert插入数据次数
查看当前用户连接数
MariaDB [hellodb]> show variables like '%connect%';
+--------------------------+-----------------+
| Variable_name | Value |
+--------------------------+-----------------+
| character_set_connection | utf8 |
| collation_connection | utf8_general_ci |
| connect_timeout | 10 |
| extra_max_connections | 1 |
| init_connect | |
| max_connect_errors | 10 |
| max_connections | 151 |
| max_user_connections | 0 |
+--------------------------+-----------------+
其中max_connections为当前数据库最大连接数为151
调整最大连接数:查看该变量是否也是服务器选项,是否能够写入配置文件
去官方网站查询https://dev.mysql.com/doc/refman/5.7/en/mysqld-option-tables.html,发现既是选项又是变量
如果使用set命令更改只是临时更改,重启服务就会失效
set global max_connections = 1000 只支持global
永久更改需要写入配置文件
vim /etc/my.cnf
global max_connections = 1000
查看当前有多少用户正在连接
MariaDB [hellodb]> show status like 'threads%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Threads_cached | 0 |
| Threads_connected | 1 |
| Threads_created | 2 |
| Threads_running | 1 |
+-------------------+-------+
4 rows in set (0.00 sec)
Threads_connected表示连接数据库的线程数为1
Threads_connected表示连接数据库且正在工作的线程数为1
skip_name_resolve 是否支持反向解析ip地址
OFF 不忽略名字解析
ON 忽略名字解析
show variables like 'skip_name_resolve'; 查看该选项的设置
默认情况下为OFF,即不忽略名字解析,会尝试把ip地址解析为名字,可能会导致连接数据库失败,如做集群时会用到该选项
该选项不支持动态更改,为global级别变量
vim /etc/my.cnf
skip_name_resolve=ON 设置为忽略名字解析
重启数据库服务
skip_networking 进入维护模式