一、问题描述
搭建的canal是高可用模式,在IDEA里面进行消费的,但是在服务端进行切换时,出现了数据重复被消费的问题。salve1:11111开启服务时,往数据库里面插入了一条数据,然后又删除了这条数据,这是Mysql的bin-log会产生两条日志,客户端也获取到了这个两条数据。当我把salve1的服务stop.sh关掉之后,salve2:11111开启了服务,但是在客户端又重新获取到了这两条数据,也就是说在我切换之后数据被重新消费了一遍。之后我又将salve1的服务开启,将salve2的服务关闭,这个两条数据又被我的客户端消费了一遍,也就这两条数据被消费了6次了,,,,,,总之每次切换服务端数据都会再次被客户端消费。
网上:Canal会导致消息重复吗?
答:会,这从两个大的方面谈起。
1)Canal instance初始化时,根据“消费者的Cursor”来确定binlog的起始位置,但是Cursor在ZK中的保存是滞后的(间歇性刷新),所以Canal instance获得的起始position一定不会大于消费者真实已见的position。
2)Consumer端,因为某种原因的rollback,也可能导致一个batch内的所有消息重发,此时可能导致重复消费。
我们建议,Consumer端需要保持幂等,对于重复数据可以进行校验或者replace。对于非幂等操作,比如累加、计费,需要慎重。
二、高可用搭建(HA)
可参考:https://github.com/alibaba/canal/wiki/AdminGuide#user-content-ha%E6%A8%A1%E5%BC%8F%E9%85%8D%E7%BD%AE
1、配置文件修改(两台机器都要下载canal,配置都一样)
① 修改canal.properties,加上zookeeper配置,spring配置选择default-instance.xml
1 canal.zkServers=hadoop:2181 ##zookeeper的ip和端口号
2 canal.instance.global.spring.xml = classpath:spring/default-instance.xml ##开启这个(默认被注释了)② 创建example目录,并修改instance.properties
1 canal.instance.mysql.slaveId = 1234 ##另外一台机器改成1235,保证slaveId不重复即可
2 canal.instance.master.address = hadoop:3306 ##数据库的ip和端口
3 canal.instance.dbUsername=canal ##Mysql的用户名 (这个可以没有)
4 canal.instance.dbPassword=Canal2019! ##Mysql的密码(这个可以没有)2、开启服务(两台都开启)
到安装目录下
./bin/startup.sh (开启服务)
./bin/stop.sh (关闭服务)
tail -F logs/canal/canal.log (查看日志)
有以下三句话表示启动成功
INFO com.alibaba.otter.canal.deployer.CanalStater - ## start the canal server.
INFO com.alibaba.otter.canal.deployer.CanalController - ## start the canal server[*.*.*.*:11111]
INFO com.alibaba.otter.canal.deployer.CanalStater - ## the canal server is running now ...3、到zookeeper的客户端查看
查看在活跃的服务端
get /otter/canal/destinations/example/running
{"active":true,"address":"*.*.*.*:11111","cid":1}
查看在活跃的客户端
get /otter/canal/destinations/example/1001/running
{"active":true,"address":"*.*.*.*:55285","clientId":1001}
查看zookeeper同步的元数据
get /otter/canal/destinations/example/1001/cursor
{"@type":"com.alibaba.otter.canal.protocol.position.LogPosition","identity":{"slaveId":-1,"sourceAddress":{"address":"hadoop","port":3306}},"postion":{"gtid":"","included":false,"journalName":"mysql-bin.000005","position":28477,"serverId":1,"timestamp":1558665144000}}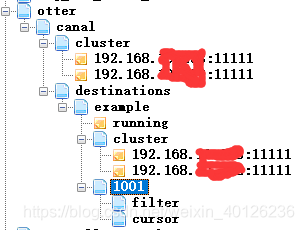
在zookeeper保存 的数据目录,推荐工具:http://www.onlinedown.net/soft/1222234.htm
三、IDEA客户端消费
在idea端编写client消费数据,来回的切换server的时候数据就会不断的重新消费。需要的maven依赖直接来:
https://mvnrepository.com/ 搜索:canal
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry.Entry;
import com.alibaba.otter.canal.protocol.CanalEntry.EntryType;
import com.alibaba.otter.canal.protocol.CanalEntry.EventType;
import com.alibaba.otter.canal.protocol.CanalEntry.RowChange;
import com.alibaba.otter.canal.protocol.CanalEntry.RowData;
import com.alibaba.otter.canal.protocol.CanalEntry.Column;
import com.alibaba.otter.canal.protocol.Message;
import java.net.InetSocketAddress;
import java.util.List;
/**
* @ClassName: NetTest
* @Description: TODO
* @Author: *******
* @Data: 2019/5/15 10:16
* @Version: 1.0
**/
public class NetTest {
public static void main(String args[]) {
String destination = "example";
String username = "canal";
String password = "Canal2019!";
InetSocketAddress inetSocketAddress = new InetSocketAddress("hadoop", 11111);
// 创建链接
CanalConnector connector = CanalConnectors.newClusterConnector("hadoop:2181",destination, username, password);
int batchSize = 1000;
int emptyCount = 0;
try {
connector.connect();
connector.subscribe(".*\\..*");
connector.rollback();
int totalEmptyCount = 120;
while (emptyCount < totalEmptyCount) {//120*2秒还没有数据就断开
Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
emptyCount++;
System.out.println("empty count : " + emptyCount);
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
}
} else {
emptyCount = 0;
printEntry(message.getEntries());
}
connector.ack(batchId); // 提交确认
}
} finally {
connector.disconnect();
}
}
//输出数据
private static void printEntry(List<Entry> entrys) {
for (Entry entry : entrys) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {
continue;
}
RowChange rowChage = null;
try {
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),
e);
}
EventType eventType = rowChage.getEventType();
System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s , ",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType));
for (RowData rowData : rowChage.getRowDatasList()) {
if (eventType == EventType.DELETE) {
printColumn(rowData.getBeforeColumnsList());
} else if (eventType == EventType.INSERT) {
printColumn(rowData.getAfterColumnsList());
} else {
System.out.println("-------> before");
printColumn(rowData.getBeforeColumnsList());
System.out.println("-------> after");
printColumn(rowData.getAfterColumnsList());
}
}
}
}
private static void printColumn(List<Column> columns) {
for (Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
}
四、问题解决
问题1、数据重复消费
上文提到数据重复消费,不断的切换server数据就不断地重新被消费,之所以被会这样就是zookeeper没有同步client的meta数据,两个服务器在zookeeper中保存的元数据不一样,所以在互相切换的时候,服务端不认为是一个客户端在消费(其实每个server有且只能有一个client)。问题的根源找到了,就是在配置高可用的时候,有配置问题。
原来是一个服务器,我直接将所有的文件拷贝过去,所有的配置都是一样的,后来拷贝的连接数据库连接不上,查看发现数据的配置canal.instance.master.address 是localhost拷贝过来的文件,后来将localhost改成了数据的真实的ip:*.*.*.*,改完之后高可用就可以用,在使用的过程中出现了数据重复。
排查找到了zookeeper元数据问题,核对发现get /otter/canal/destinations/example/1001/cursor ,一个服务端的元数据中"address":"hadoop",而另一个的address 是localhost,就是因为这两个切换,导致数据重复消费。
解决:
修改conf/example/instance.properties文件,将canal.instance.master.address的值都改成真实的ip,不要用主机映射的名字
例:canal.instance.master.address =192.168.123.45:3306
问题2、canal的服务开启了,但是连接不上
canal的服务开启了,查看日志文件,里面也确实是启动了,但是就是连接不上
解决:修改conf/canal.properties 文件,将canal.ip改成本机真实的ip,如果用主机的映射开启的服务就是:主机名:11111,而你在代码里面连接的时候输入的主机名在解析的时候会被解析成真实的ip,根据这个ip去找相关的服务。而服务端并非ip+端口
建议:canal里面的所有关于ip的配置最好不要用ip映射的名字(例如:127.0.0.1,localhost,映射名等等),最好都用真实的ip