这里我用的python工具是anaconda。
1.首先创建一个scrapy工程:
打开anaconda promt命令行(注意这里不是使用cmd打开windows下的命令行),进入到需要创建工程的目录下,执行“scrapy startproject dmoz“”创建工程

注意这里进入创建工程的目录时,不可直接"cd d:\python\workspace",需要将原来的目录返回到根目录下,才可以切换磁盘。
创建完工程后,进入到工程目录下,可以看到如下目录结构:

进入到tuturial目录:

2.在items.py文件中定义需要用到的变量
import scrapy class DmozItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title=scrapy.Field() link=scrapy.Field() # desc=scrapy.Filed()
3.进入到spider文件夹下,创建用于爬取数据的文件dmoz_spider.py
首先要确定爬取网站的地址,这里我们爬取dmoz网站中的新闻媒体及字典的目录网页:
http://dmoztools.net/Computers/Software/Shareware/News_and_Media/
http://dmoztools.net/Computers/Software/Shareware/Directories/
需要限定爬虫的爬取范围,否则爬取工作结束后,它可能会爬取未知网址的信息,限定爬虫范围的代码为:
allowed_domains=['dmoztools.net']
以“”http://dmoztools.net/Computers/Software/Shareware/Directories/为例展示网页中的信息”:
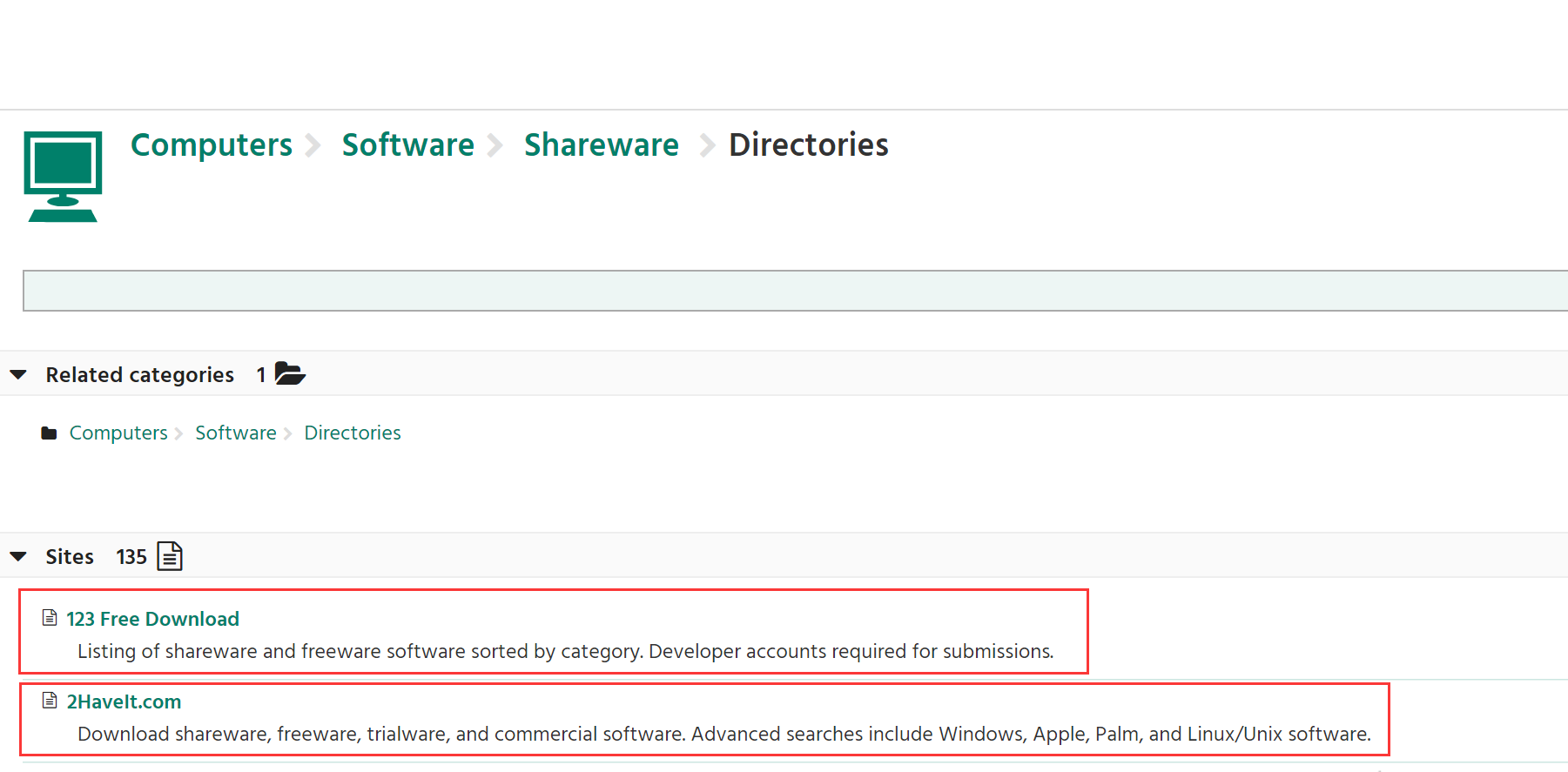
在这里会显示对应分类的诸多网址信息,我们需要爬取的就是红色框标出来的网址名称以及对应的链接。
需要查看红色框对应代码中的位置:
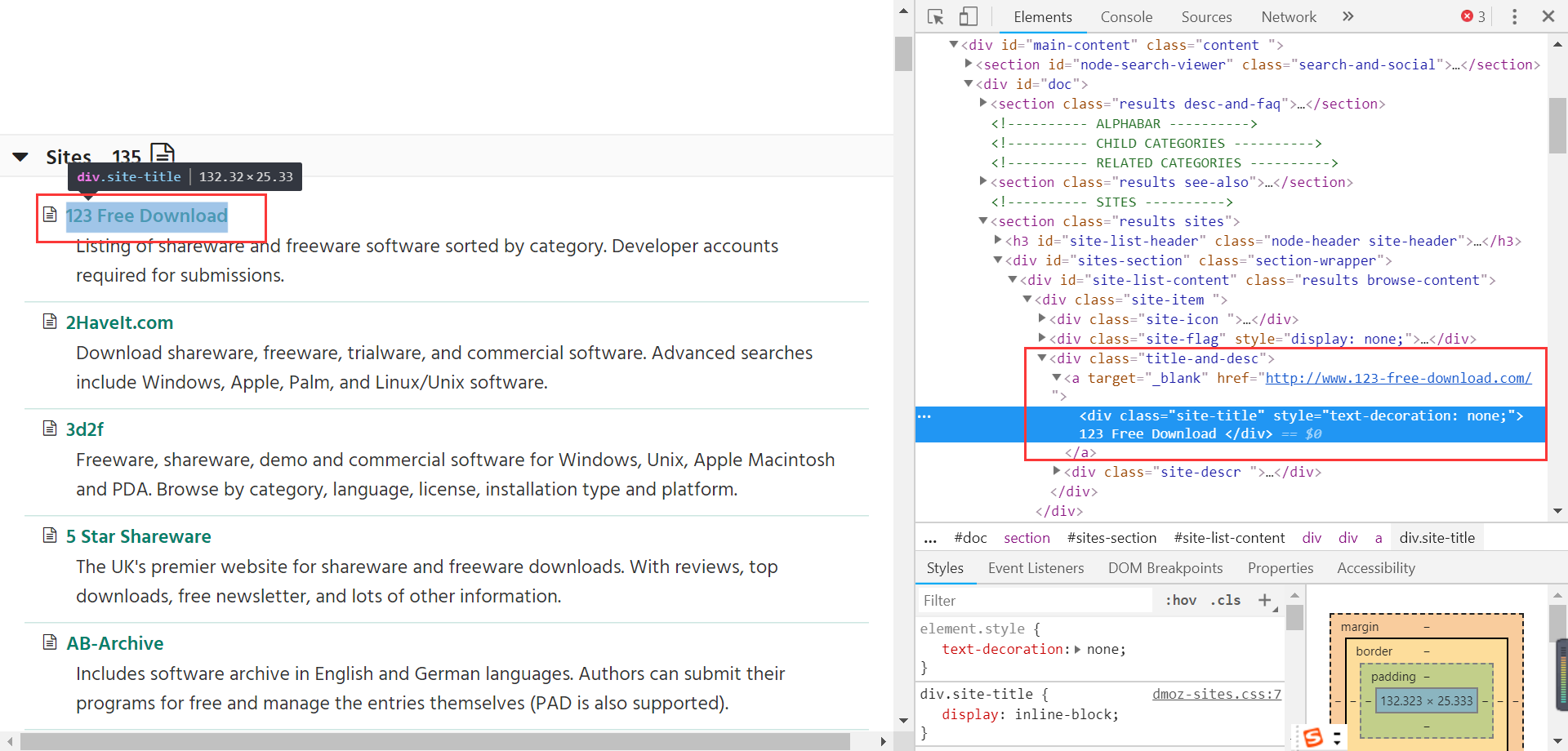
可以看到链接对应的页面源码的位置为:div标签下的a标签。但是有很多div标签,又如何定位到a标签所在的div标签呢?通过标签对应的css样式来定位。
这里使用了xpath函数来爬取到指定标签的数据。
sites=sel.xpath('//div[@class="title-and-desc"]')
[@class="title-and-desc"]用于指定对应的div样式。
import scrapy from tuturial.items import DmozItem class DmozSpider(scrapy.Spider): name="dmoz" allowed_domains=['dmoztools.net']#爬取范围,防止爬虫在爬取完指定网页之后去爬取未知的网页 #爬取的初始地址 start_urls=[ 'http://dmoztools.net/Computers/Software/Shareware/News_and_Media/', 'http://dmoztools.net/Computers/Software/Shareware/Directories/' ] #当根据爬取地址下载完内容后,会返回一个response,调用parse函数 def parse(self,response): # filename=response.url.split('/')[-2] # with open(filename,'wb') as f: # f.write(response.body) sel=scrapy.selector.Selector(response) #查看网页中的审查元素,确定需要爬取的数据在网页中的位置,根据所在的标签进行爬取 #在我们需要爬取的这两个网页中,列出的目录网址都在div标签中,但是网页中有很多div标签,需要根据div标签的css #样式进行进一步确定,使用[@class=""]来指定对应的css样式 sites=sel.xpath('//div[@class="title-and-desc"]') items=[] #对div中的每一条记录进行处理 for site in sites: #实例化items.py指定的类,用于存储爬取到的数据 item=DmozItem() #刚刚查询到的div下的a标签下的div标签下存储着对应的链接的名称 item['title']=site.xpath('a/div/text()').extract() #刚刚查询到的div下的a标签下的href属性下存储着对应的链接 item['link']=site.xpath('a/@href').extract() # desc=site.xpath('text()').extract() #将爬取出来的数据存储到items中 items.append(item) # print(title,link) return items
注意需要引入到items文件:
from tuturial.items import DmozItem
该文件的name指定爬虫的名称,所以该名称必须是唯一的,这样才可以根据爬虫的名称找到对应的执行代码。
在anaconda prompt进入到爬虫工程下执行爬虫文件,并将爬取到的数据存储到json文件中
![]()
-o指定存储的文件,-t指定存储的格式。
在工程目录下就可以看到item.json文件了。
items.json文件的内容为:

对应的链接名称和网址就存储到文件中了。