二、MySQL数据库为什么要用innodb:1、支持事务;2、实现了MySQL的mvcc;3、支持行级锁;
三、启动springboot的那个注解:
默认扫描包路径:main方法所在的类下面的所有包和子包
四、@RequestParam 怎么回事,这个居然都忘记了,不过也不能说忘记,因为确实不怎么用,因为这个一般都是get请求的,而我一般都是post,request请求的:SpringCloud
@PathVariable:这个真的没有用过,什么“映射 URL 绑定的占位符”,不懂;
五、redis的优点:
1)基于内存,操作速度快;
2)丰富的数据类型,有STRING,LIST,HASH,SET,SORTEDSET,二那个什么mach的什么什么只支持单一的数据类型STRING;
3)支持事务;
4)原子性操作;
5)支持持久化策略:AOF和RDB
缺点:数据不一致;代码维护成本
六、使用redis应该注意什么,其实就是问 缓存穿透、缓存雪崩、缓存击穿;接着问这三个是怎么回事,以及各自的解决方法;我回答了缓存穿透的解决方法:那个布隆过滤bitmap的厉害之处,对方接着问,如果那个bitmap的hashcode一样(即hash冲突了,怎么解决),我回答了equal方法,对方说不是这样子,然后我就被问死了。
你有什么解决方案来防止缓存雪崩?
1、加锁排队 key: whiltList value:1000w个uid 指定setNx whiltList value nullValue
mutex互斥锁解决,Redis的SETNX去set一个mutex key,
当操作返回成功时,再进行load db的操作并回设缓存;
否则,就重试整个get缓存的方法
2、数据预热
缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,
先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
可以通过缓存reload机制,预先去更新缓存,再即将发生大并发访问前手动触发加载缓存不同的key
3、双层缓存策略
C1为原始缓存,C2为拷贝缓存,C1失效时,可以访问C2,C1缓存失效时间设置为短期,C2设置为长期。
4、定时更新缓存策略
失效性要求不高的缓存,容器启动初始化加载,采用定时任务更新或移除缓存
5、设置不同的过期时间,让缓存失效的时间点尽量均匀
缓存穿透:
1、缓存空值
如果一个查询返回的数据为空(不管是数据不 存在,还是系统故障)我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。 通过这个直接设置的默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库
2、采用布隆过滤器BloomFilter 优势占用内存空间很小,bit存储。性能特别高。
将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个
bitmap 拦截掉,从而避免了对底层存储系统的查询压力
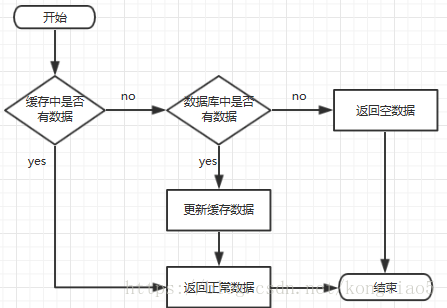
七、如果给7亿数据你,你怎么处理这些数据;我回答了集群,多主多从,一主对多从,读写分离的架构模式;然后对方问在多主的情况下,这7亿数据,你应该怎么分配到这若干台主机上面,(中间配一个Nginx代理服务器,利用反向代理,结合一定的hash算法,分发到这若干台主机上面),如果业务突然要求要额外导3亿数据进来,允许你增加机器,比如说增加了3台,你怎么很好地结合本来的七亿数据;1)hashmap的rehash原理,将这10亿数据重新hash分配(时间充足,建议);2)先把这3亿数据放在这三个机器,然后到时候来两边的机器都重新查一遍(时间不充足);
八、vue的特点,以及优缺点
九、什么时候用到多线程;谈谈你对锁的理解(我主要是回答了synchronized关键字,和readwritelock接口),然后那个面试官就说能否用synchronized实现读写锁功能,看我疑惑了一下,说不会很正常,这个有点偏门了,大部分人都不会;
十、wait状态和runnable状态之间是什么?我当时很懵逼,不应该是写业务代码吗?
十一、请设计一下电商秒杀系统的实现方式?
十二、springmvc如何实现异步响应?
十三、MySQL根据一组id查结果如何保证顺序?redis如何批量查询多个key?
十四、如何实现分布式锁?(SETNX)
十五、cron表达式 0/15 * * * *?如何解释
十六、至少列出三种rpc方式,并具体到具体所使用的场景
十七、乐观锁的实现方式(版本号,cas,自旋,ABA问题)
十八、try代码块中有return,又有finally代码块:先执行finally代码块里面的,再执行try代码块里面的return语句
十九、关于JAVA中String类以形参传递到函数里面,修改后外面引用不能获取到更改后的值
首先得明白为什么会有线程安全这个问题,之所以要考虑线程安全,是因为变量是可变的,可以被其他线程修改。如果这种情况发生了,就是线程不安全了。
如果这个变量本身都不可以变了,也就谈不上那个什么线程安全不安全了,或者说肯定是线程安全的。比如String,因为根本改不了啊。
二、redis为什么这么快:
1)完全基于内存操作;
2)数据结构数据操作简单,也对数据结构进行了专门的优化;
3)采用单线程,避免了不必要的上下文切换以及竞争条件(采用单线程操作就已经很快了,所以就不必要采用多线程了);
4)采用了多路复用IO
四、Redis 内存淘汰机制:在redis.conf里面配:maxmemory <bytes>;
默认:当内存使用达到阈值的时候,所有引起申请内存的命令会报错
在带有过期时间的键中选择最近最少使用的。(推荐)
在所有的键中选择最近最少使用的。(不区分是否携带过期时间)(一般推荐)
六、乐观锁、悲观锁:我们平时看到的:synchronized 以及 就是悲观锁ReentrantLock
乐观锁的版本号方法:当我们要从数据库中读取数据的时候,同时把这个version字段也读出来,如果要对读出来的数据进行更新后写回数据库,则需要将version加1,同时将新的数据与新的version更新到数据表中,且必须在更新的时候同时检查目前数据库里version值 是不是之前的那个version,如果是,则正常更新。如果不是,则更新失败,说明在这个过程中有其它的进程去更新过数据了。
七、分布式锁过程当中,怎么解决setnx,setex的问题:1)用lua脚本,里面就是原子性了;2)后来的新本来setnx,setex可以用一条命令来替代了;
八、你知道Redis读写分离是怎么做数据同步的吗(数据的一致性)


redis2.8版本之前使用旧版复制功能SYNC SYNC是一个非常耗费资源的操作 主服务器需要执行BGSAVE命令来生成RDB文件,这个生成操作会耗费主服务器大量的的 CPU、内存和磁盘读写资源 主服务器将RDB文件发送给从服务器,这个发送操作会耗费主从服务器大量的网络带宽和流 量,并对主服务器响应命令 请求的时间产生影响:接收到RDB文件的从服务器在载入文件的过程是阻塞的,无法处理命令 请求 2.8之后使用PSYNC PSYNC命令具有完整重同步(full resynchronization)和部分重同步(partial resynchronization1)两 种模式 部分重同步功能由以下三个部分构成: 主服务的复制偏移量(replication offset)和从服务器的复制偏移量 主服务器的复制积压缓冲区(replication backlog),默认大小为1M 服务器的运行ID(run ID),用于存储服务器标识,如从服务器断线重新连接,取到主服务器 的运行ID与重接后的主服务器运行ID进行对比,从而判断是执行部分重同步还是执行完 整重同步
end!