Table of Contents
《5G系统中BBU与RRU之间前传接口(CPRI)带宽计算》
1 ,5G系统中前传(Fronthaul)的含义及考虑因素 (R3-160754)
2 ,5G系统中前传(Fronthaul)带宽计算 (R3-160986/ R3-161012)
3,5G系统中前传(Fronthaul)带宽结论 (R3-162102)
8,TR38.801中BBU与RRU之间CPRI接口带宽计算
《微软研究员:fork() 成为负担,需要淘汰 》
作者:Linux爱好者
微软研究人员发表论文称用于创建进程的 fork 系统调用方式已经很落后,并且对操作系统的研究与发展产生了极大的负面影响,需要淘汰,作者同时提出了替代方案。
相信每位开发者都对操作系统中的 fork() 有一定的了解,至少知道它是用来创建进程的。fork 系统调用方式在 20 世纪 70 年代被创造出来,它通常与 exec() 组合使用,非常简单却很强大,被认为是一种天才式的设计、Unix 的伟大思想,至今 50 余年一直作为 POSIX 操作系统的原语存在,同时几乎每个 Unix shell、主要 Web 和数据库服务器、Google Chrome、Redis 甚至 Node.js 都使用 fork。
然而微软系统研究实验室 Redmond 的研究人员 3 月份却发表了一篇论文,表示 fork 作为操作系统原语继续存在,阻碍了对操作系统的研究,“它是来自另一个时代的遗物,不适合现代系统,并且会带来一系列负面影响”,研究人员认为是时候将 fork 淘汰了。
fork 简单已成神话
论文中承认了 fork API 的优点,包括简单与缓解并发性,也肯定了 fork 在历史上的重要贡献,但更多地是列出了它在现代操作系统研究与发展中的弊端。
研究人员认为 fork 本身就存在许多问题,另一方面,fork 在操作系统的研究与发展上也起了限制作用,论文指出有明确的证据表明支持 fork 限制了 OS 体系结构的变化,并限制了操作系统适应硬件演进的能力。
乍一看可能会觉得 fork 很简单,而这也是它的一大特征,但是实际上,“这是一个具有欺骗性的神话”。
fork 的语义已经影响了每个创建进程状态的新 API 的设计,POSIX 规范现在列出了关于如何将父状态复制到子进度的 25 个特殊情况,包括文件锁定、定时器、异步 IO 操作与跟踪等。此外,许多系统调用标志控制 fork 关于内存映射(Linux madvise() 标记 MADV_DONTFORK/DOFORK/WIPEONFORK 等)、文件描述符(O_CLOEXEC、FD_CLOEXEC)和线程(pthread_atfork())的行为。任何重要的操作系统工具都必须通过 fork 记录其行为,并且用户模式库必须做好准备,以便随时 fork 它们的状态。fork 已经不再简单。
fork 不是线程安全的,Unix 进程支持线程,但 fork 创建的子进程只有一个线程(调用线程的副本),当一个线程在 fork 时,如果另一个线程此时进行内存分配并持有堆锁,任何在子进程中分配内存的尝试(从而获得相同的锁)都将立即发生死锁。
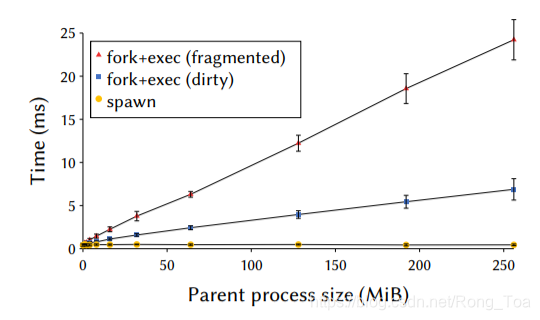
fork 很慢,fork 的性能一直是个问题,此前使用写时复制技术使其性能可接受,但是在今天,建立写时复制映射本身都成了一个性能问题,比如 Chrome 在 fork 时会经历了长达 100 毫秒的延迟,Node.js 应用在 exec 之前 fork 时,可以被阻塞几秒钟。fork+exec 与 spawn 的性能对比情况可以通过本文开头的图片直观看到。
fork 无法扩展,系统规模的设计首先要避免不必要的共享,但 fork 进程会与其父进程共享所有内容,由于 fork 复制了进程操作系统状态的各个方面,这样复制与引用计数成本会比较低,所以 fork 其实是趋向于将状态集中在单片内核中,这就使得难以实现一些新技术,比如用于安全性和可靠性的内核划分。
fork 与异构硬件不兼容,它将进程的抽象与包含它的硬件地址空间混为一谈。fork 将进程的定义限制为单个地址空间,并且是在某个核心上运行的单个线程。但现代硬件和在其上运行的程序并不是这样,硬件异构化越来越严重,使用有内核旁路 NIC 的 DPDK 或带有 GPU 的 OpenCL 的进程无法安全地 fork,因为操作系统无法复制 NIC/GPU 上的进程状态。这个问题至少已经困扰了 GPU 程序员十年,而随着未来的芯片上系统包含越来越多的状态加速器,情况只会变得更糟。
“GET THE FORK OUT OF MY OS!”
论文提出了替代 fork 的方案:包括一个高级 Spawn API 和一个低级类微内核 API 的组合。涉及到 posix_spawn()、vfork()、跨进程操作、clone()、改进写时复制内存等内容。
fork 的问题越来越严重,作者最后总结出必须做三件事来纠正这种情况,不仅要弃用 fork,还要改善替代方案,同时纠正我们关于 fork 的教学内容,不能再错误地宣扬 fork 的能力与设计水平。
论文地址:https://www.microsoft.com/en-us/research/publication/a-fork-in-the-road
《网络协议》
作者:程序员最幽默

《5G系统中BBU与RRU之间前传接口(CPRI)带宽计算》
1 ,5G系统中前传(Fronthaul)的含义及考虑因素 (R3-160754)
在RAN3 #91bis会议的R3-160754:Fronthauling: Motivations and Constraints中,Mitsubishi Electric分析了Fronthauling的基本概念,对其动因和局限进行了简单分析。
5G系统中采用C-RAN架构,它可以通过网络功能虚拟化实现硬件资源的共用和扩展。
C-RAN下,小区间的移动性多在CU内部完成,而不再需要通过外部接口。如果传输网提供路由和复用特性,则BBU和RRU之间不再是1对1 的关系了,它们之间可以动态影射,实现资源的动态复用。C-RAN下,通过CU/DU功能切分,实现BBU资源的集中化,可以降低OPEX和CAPEX。具体体现在以下几个方面:降低站址需求降低安全风险共享机房资源(空调/电源)Mitsubishi认为Fronthualing包括CU与DU之间的接口,以及支撑该接口的底层网络。“Fronthauling is a mean enabling to split RAN functions and locate them partly in a Central Office and partly distribute them. It includes the interfaces between central and distributed functions, and the underlying network that transports the interfaces.”需要说明的是,早期规范讨论过程中,CU/DU切分考虑高层和底层等多种选项。目前高层(1~3层)确定选用选项2,底层仍需进一步讨论,但是物理层BBU与RRU之间的带宽资源需求最大,因此Fronthaul多集中在分析BBU与RRU之间的传统的CPRI接口。举例来说,目前LTE系统中,2x2 MIMO,20MHz小区带宽,峰值速率170Mbps,所需的CPRI带宽约为2.5Gbps。随着载波数和MIMO流数的增加,CPRI带宽资源也几乎成倍增长。5G系统中,峰值速率增加n x100倍,会导致CPRI链路的带宽需求高达250Gbps。虽然可以采用传输压缩,但是毋庸置疑的是,C-RAN模式下RAN功能切分对接入网带宽资源的要求相当高。
2 ,5G系统中前传(Fronthaul)带宽计算 (R3-160986/ R3-161012)
在RAN3 #91bis会议上,Mitsubishi在R3-160754及其修改稿R3-160986中,对前传提供了明确的计算方法,提出了“614.4Mbps/10MHz/天线端口”的基本结论,并在此基础上对不同天线端口和带宽进行了估算分析。具体说明如下。R3-160986中提到,如果在BBU与RRH之间进行切分,则其接口上传送的是I/Q信号。5G系统中如果也采用同样的切分方式,则计算表明,每个天线端口下,每10MHz就需要614.4Mbps的传输资源。当频率带宽和天线端口都增加时,所需的传输带宽线形增加,如下表所示。RAN架构PHY/RF分离的最大传输带宽需求举例

R3-160986附录A中提供了计算方法,整理如下:

天线阵子数 (编者注:原文是antenna elements,如上图所示)CPRI采样比特宽度:按15比特考虑。
每个子帧中的OFDM符号数:20MHz下为14,如果考虑CP,则为15。
FFT数目:2048 (原文注:每个子帧中的OFDM符号数和FFT数目的乘积与系统带宽成比例) 。
同时考虑I/Q支路时,传输带宽需乘以2。
传输带宽计算方法:
下行:接口带宽峰值比特率 = 基站天线阵子数 x 比特宽度 x 每个子帧中的OFDM符号数 x FFT数目 X 2(I/Q支路) ? 1ms
上行:接口带宽峰值比特率 = 基站天线阵子数 x 比特宽度 x 每个子帧中的OFDM符号数 x FFT数目 X 2(I/Q支路) ? 1ms
在后续R3-161012修改稿中,在表格下方明确标注了计算方法:
接口带宽峰值比特率 = 基站天线阵子数 x 采样频率(与系统带宽成比例) x 比特宽度(每个采样) + 开销
3,5G系统中前传(Fronthaul)带宽结论 (R3-162102)
在RAN3 #92会议上,Ericsson在R3-162422 Clarifications on fronthaul bit rate requirements中提议,传输部分强调为最大理论值,且建议明确增加采样率等备注信息,即:The calculation is made for sampling frequency of 30.72 Mega Sample per second for each 20MHz and for a Bit Width equal to 30。(译文:计算基于20MHz,每秒30.72M的采用频率,比特宽度为30)此建议被采纳并在TR 38801-060中体现了出来。TR 38801-060中,表格题目和文字描述都有部分变化。值得注意的是,此版定型后一直没再变过。具体描述请参见本文最后的附录部分。
4 ,TR38.801(V14.0.0)中结论
在RAN3 #91bis的Mitsuibishi提案讨论和修改的基础上,结合RAN3 #92上Ericsson的提议,记录在TR 38801-060中,并一直沿用至今。亦即对于BBU与RRU之间的传输带宽需求,自TR 38801-060定型后,一直就没再变过。具体描述请参见本文最后的附录部分。
5,BBU与RRU之间CPRI接口简介
BBU与RRU之间采用CPRI接口传输基带信号。上图中,右侧无线设备控制器(REC)即指BBU,左侧无线设备(RE)相当于RRU。
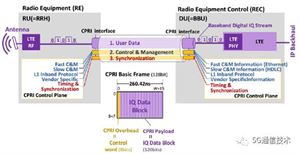
BBU进行基带信号处理,并形成I/Q数据流,经CPRI接口传送出去。

RRU将CPRI接口上传送的I/Q数据接收下来,并转变成模拟信号,经由天线发射出去。
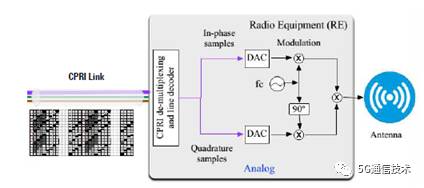
6,LTE系统中CPRI接口带宽详细计算方法分析
结合R3-160986以及TR38.801中信息,对LTE系统CPRI带宽计算举例如下。
6.1 CPRI接口带宽计算公式
接口带宽峰值比特率 = 基站天线阵子数 x 采样频率(与系统带宽成比例) x 比特宽度(每个采样) + 开销
TR38.801中表格下标注的计算条件为:基于20MHz,每秒30.72M的采用频率,比特宽度为30。
假设LTE载波带宽为20MHz,采用2天线,则:
- 基带带宽:20MHz
- IFFT点数:2048
- 子载波间隔:15KHz
- 基带I/Q采样率:30.72MHz (=2048 * 15KHz)
- 采样位宽:30bit (CPRI I/Q 采样位宽,各15比特)
每AxC上I/Q采样数据流:921.6 Mbps (=30 bits*30.72MHz)
添加控制字(W0):983.04Mbps (=16/15*921.6Mbps)
添加8B/10B线路编码的开销:1.2288Gbps (=983.04*10/8)
2x2 MIMO: 2.4576Gbps (= 2 x 1.2288Gbps)
8x8 MIMO:9.8304Gbps (= 8 x 1.2288Gbps)
简单说明如下。
6.2, CPRI接口I/Q采样位宽
CPRI链路采用复数方式传送AxC的数字化的RF信号,每个样值都采用I/Q向量来表示。CPRI规范中,主要处理这种信号格式。I/Q样值交织在一起形成单个word。这些word一起组成满足采样率和比特宽度需求的信号。根据空口需求和上下行特性,CPRI可以采用不同的比特宽度。下行方向上,比特宽度为8到20比特,为了获取较高的采样速率,上行比特宽度为4到20比特。另外,I/Q采样值较小时,也可以采用信号扩展或者采用预留比特填充的方式来对空闲位进行填充,以获取较大的比特宽度。对于上下行采用不同比特宽度时,这种处理方法比较有用,但在CPRI上进行影射时,通常上下行都会采用相同的采样宽度。
简单来讲,I/Q信号到CPRI接口的影射遵循以下规则:
上行I/Q采样宽度:4~20 bits,常用值为12,15和16。
下行I/Q采样宽度:8~20 bits,常用值为12,15和16。
不过通常上下行都采用15比特的采样宽度。如华为'BBU-RRU IR接口说明书(2012-7)'中规定,下行I/Q位宽为15bit,其中业务有效I/Q数据位宽占高13bit,低2bit无效。上行I/Q位宽为15bit,无DAGC(DAGC即数字自动增益控制)。
6.3 CPRI帧结构和帧长度
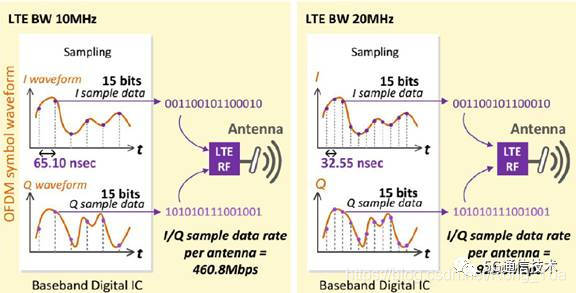
LTE系统中,子载波间隔为15KHz,其符号长度与子载波间隔成反比,为1/(15KHz)。2048个IFFT采样点落入一个符号内(即1/(15KHz)),故采样频率相当于15KHz * 2048 = 30.72MHz。
CPRI链路上传送多个基带I/Q数据流,每个I/Q数据流对应一个载波和一个天线。AxC是指一个天线上所传送的单个载波的I/Q数据。
CPRI基本帧长度Tc=1/fc=1/3.84MHz= 260.41667ns。一个基本帧包含16个word。其中第一个word为控制word,其余15个word为用户面I/Q数据。每个word中8个比特。
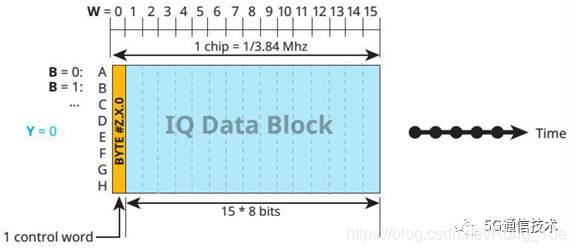
根据单个word上影射的比特长度,CPRI可分为不同类型,对应不同的有效载荷。比如,每个word中影射8比特时,有效载荷为120bit。同理,每个word中影射16/32/64比特时,则有效载荷分别对应240/480/960比特。它们分别对应CPRI选项1/2/3/5,如下图所示。
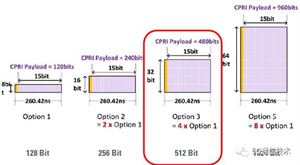
CPRI基本帧长度为260.41667ns(=1/3.84MHz),故上述不同有效载荷下,对应的速率分别计算如下:

6.4 CPRI线路编码
CPRI线路编码可以采用8B/10B或者64B/66B两种方式。
8B/10B编码表示将8比特的码字影射到10比特的符号上,64B/66B同理。
8B/10B编码的特性之一是保证DC 平衡,采用8B/10B编码方式,可使得发送的“0”、“1”数量保持基本一致,连续的“1”或“0”不超过5位,即每5个连续的“1”或“0”后必须插入一位“0”或“1”,从而保证信号DC平衡,也就是说,在链路超时时不致发生DC失调。通过8B/10B编码,可以保证传输的数据串在接收端能够被正确复原。
6.5 CPRI带宽计算
总结根据上述分析和计算结果可知,LTE带宽为20MHz时,采用15bit的I/Q采样位宽每AxC上I/Q采样数据流为921.6 Mbps,添加控制字后为983.04Mbps,采用8b/10b编码后为1.2288Gbps,对应CPRI速率选项2,亦即每个AxC可以影射到CPRI选项2模式下进行传送。而采用2天线端口(即2x2 MIMO模式)时,则需要2.4576Gbps的CPRI带宽。
- 基带带宽: 20MHz
每AxC上I/Q采样数据流: 921.6Mbps (=30 bits*30.72MHz)
添加控制字(W0):983.04Mbps (= 16/15*921.6Mbps)
添加8B/10B线路编码的开销:1.2288Gbps (=983.04*10/8)
2x2 MIMO:2.4576Gbps (= 2 x 1.2288Gbps)
8x8 MIMO:9.8304Gbps (= 8 x 1.2288Gbps)
如果考虑10MHz带宽,则CPRI速率需求降低一半,对应TR38.801的结论:
“每个天线端口下,每10MHz就需要614.4Mbps的传输资源”。
另外,不同采样位宽条件下,各个CPRI选项下所能承载的天线端口x载波(AxC)的数目有所不同。比如,CPRI选项7速率为9830.4Mbps,9/12/15比特采样位宽下,对应的AxC分别为13/10/8。
上述计算结果中,LTE 20MHz下,2天线端口对应的CPRI带宽为2457.6Mbps,对应选项3,亦即2个AxC可以影射到此模式中。

7,5G 新空口下CPRI接口带宽估算
5G系统新空口中,采用新的无线参数集。2017年3月中国移动在巴塞罗那通信展上发布的样机规范中,对5G新空口的参数规定如下:
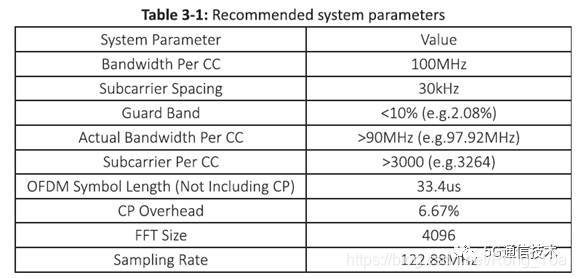
采用与LTE类似的计算方法,计算5G系统CPRI带宽如下:
基带带宽:100MHz
IFFT点数: 4096
子载波间隔:30KHz
基带I/Q采样率:122.88MHz (=4096 * 30KHz)
采样位宽:15bit (I和Q样点)
每AxC上I/Q采样数据流:3686.4 Mbps (=30bits*122.88MHz)
添加控制字(W0):3932.16Mbps (= 16/15*3686.4Mbps)
添加8B/10B线路编码的开销:4915.2Mbps (= 3932.16Mbps*10/8)
64TRX MIMO:314.57Gbps (= 64 x 4915.2Mbps)
采用5G新空口参数计算,100MHz下,单天线端口所需CPRI带宽为4.9Gbps。
LTE系统中,10MHz下,单天线端口所需CPRI带宽为614.4Mbps。进行对比可知,5G系统频带宽度为LTE系统的10倍,但是5G所需的CPRI带宽却只有LTE系统的8倍。这和5G系统中采用新的载波间隔和IFFT点数都有关系。更为重要的是,5G系统中采用64TRX,其CPRI速率要求更高,如100MHz下约需320Gbps。
8,TR38.801中BBU与RRU之间CPRI接口带宽计算
TR38.801提供了不同天线端口和带宽下的CPRI最大带宽信息,如下表所示。

可以根据TR38.801中提供的结果“每个天线端口下,每10MHz就需要614.4Mbps的传输资源”进行验证,也可以采用5G新空口结果进行验证。
采用LTE计算结果估算,则10MHz下单天线端口需求614Mbps的CPRI带宽,则2端口10MHz约需1Gbps,2端口20MHz约需2Gbps,依次类推,粗略估算。
根据5G新空口计算验证上述结果,100MHz单天线端口下对应4915.2Mbps,则对应结果的准确信息如下,接近但绝不超过TR38.801中表格中所提供的最大值。

上表希望理解正确,如有错误,还请大家多加指正,多谢。
附录:
TR38.801(V14.0.0)中BBU与RRU之间传输带宽需求的描述:11.1.4.2 Transport network requirements for an example New RAN architectureAccording to TR 38.913 [5], the NR shall support up to 1GHz system bandwidth, and up to 256 antennas. A calculation relative to one of several possible transport deployments applied to a possible RAN architecture example shows that transmission between base band part and radio frequency part requires a theoretical maximum bit rate over the transport network of about 614.4Mbps per 10MHz mobile system bandwidth per antenna port.When the system bandwidth is increasing as well as the number of antenna ports, the required bit rate is linearly increasing. An example with rounded numbers is shown in the following table. Note that the figures in Table 6.1.2.2.2-1 are a maximisation of the needed bandwidth per number of antenna ports and frequency bandwidth.Table 6.1.2.4.2-1 Examplesof maximum required bitrate on a transmission link for one possible PHY/RF based RAN architecture split

NOTE 1: Peak bit rate requirement on a transmission link = Number of BS antenna elements *Sampling frequency (proportional to System bandwidth) * bit width (per sample)+ overhead. The calculation is made for sampling frequency of 30.72 Mega Sample per second for each 20MHz and for a Bit Width equal to 30.
《互联网架构“高并发”到底怎么玩?》
作者:58沈剑 架构师之路
什么是高并发?
高并发(High Concurrency)是互联网分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计保证系统能够同时并行处理很多请求。
高并发相关的常见指标有哪些?
-
响应时间(Response Time)
-
吞吐量(Throughput)
-
每秒查询率QPS(Query Per Second)
-
并发用户数
什么是响应时间?
系统对请求做出响应的时间。
例如:系统处理一个HTTP请求需要200ms,这个200ms就是系统的响应时间。
什么是吞吐量?
单位时间内处理的请求数量。
什么是QPS?
每秒响应请求数。在互联网领域,这个指标和吞吐量区分的没有这么明显。
什么是并发用户数?
同时承载正常使用系统功能的用户数量。
例如:一个即时通讯系统,同时在线量一定程度上代表了系统的并发用户数。
如何提升系统的并发能力?
互联网分布式架构设计,提高系统并发能力的方式,方法论上主要有两种:
-
垂直扩展(Scale Up)
-
水平扩展(Scale Out)
什么是垂直扩展?
垂直扩展是指,提升单机处理能力,垂直扩展的方式又有两种:
(1)增强单机硬件性能,例如:增加CPU核数如32核,升级更好的网卡如万兆,升级更好的硬盘如SSD,扩充硬盘容量如2T,扩充系统内存如128G;
(2)提升单机架构性能,例如:使用Cache来减少IO次数,使用异步来增加单服务吞吐量,使用无锁数据结构来减少响应时间;
画外音:在互联网业务发展非常迅猛的早期,如果预算不是问题,强烈建议使用“增强单机硬件性能”的方式提升系统并发能力,因为这个阶段,公司的战略往往是发展业务抢时间,而“增强单机硬件性能”往往是最快的方法。
垂直扩展有什么瓶颈?
不管是提升单机硬件性能,还是提升单机架构性能,都有一个致命的不足:单机性能总是有极限的。
如何突破单机的极限?
互联网分布式架构设计,高并发终极解决方案还是水平扩展。
什么是水平扩展?
只要增加服务器数量,就能线性扩充系统性能。
常见的互联网分层架构如何?
各层该如何落地水平扩展?
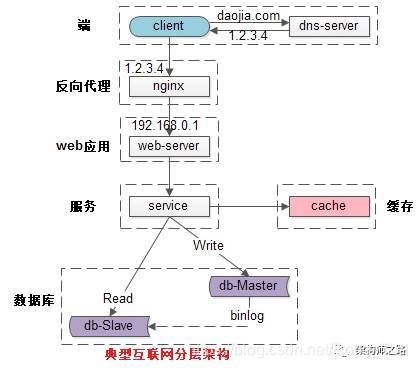
常见互联网分布式架构如上,分为:
(1)客户端层:典型调用方是浏览器browser或者手机应用APP;
(2)反向代理层:系统入口,反向代理;
(3)站点应用层:实现核心应用逻辑,返回html或者json;
(4)服务层:如果实现了服务化,就有这一层;
(5)数据-缓存层:缓存加速访问存储;
(6)数据-数据库层:数据库固化数据存储;
要想真个系统支持水平扩展,就必须每一层都支持水平扩展。
反向代理层如何进行水平扩展?
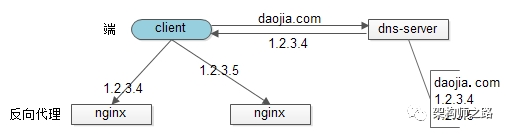
反向代理层的水平扩展,是通过“DNS轮询”实现的:dns-server对于一个域名配置了多个解析ip,每次DNS解析请求来访问dns-server,会轮询返回这些ip。
当nginx成为瓶颈的时候,只要增加服务器数量,新增nginx服务的部署,增加一个外网ip,就能扩展反向代理层的性能,做到理论上的无限高并发。
站点层如何进行水平扩展?
站点层的水平扩展,是通过“nginx”实现的,通过修改nginx.conf,可以设置多个web后端。
画外音:nginx是个例子,有可能是LVS或者F5等反向代理。
当web后端成为瓶颈的时候,只要增加服务器数量,新增web服务的部署,在nginx配置中配置上新的web后端,就能扩展站点层的性能,做到理论上的无限高并发。
服务层如何进行水平扩展?
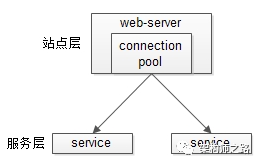
服务层的水平扩展,是通过“服务连接池”实现的。
站点层通过RPC-client调用下游的服务层RPC-server时,RPC-client中的连接池会建立与下游服务多个连接,当服务成为瓶颈的时候,只要增加服务器数量,新增服务部署,在RPC-client处建立新的下游服务连接,就能扩展服务层性能,做到理论上的无限高并发。
画外音:如果需要优雅的进行服务层自动扩容,这里可能需要配置中心里服务自动发现功能的支持。
数据层如何进行水平扩展?
在数据量很大的情况下,数据层(缓存,数据库)涉及数据的水平扩展,将原本存储在一台服务器上的数据(缓存,数据库)水平拆分到不同服务器上去,以达到扩充系统性能的目的。
互联网数据层常见的水平拆分方式有这么几种,以数据库为例:
一、按照范围水平拆分
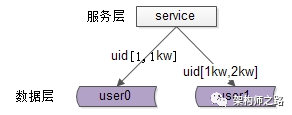
每一个数据服务,存储一定范围的数据,上图为例:
-
user0库,存储uid范围1-1kw
-
user1库,存储uid范围1kw-2kw
这个方案的好处是:
(1)规则简单,service只需判断一下uid范围就能路由到对应的存储服务;
(2)数据均衡性较好;
(3)比较容易扩展,可以随时加一个uid[2kw,3kw]的数据服务;
不足是:
(1)请求的负载不一定均衡,一般来说,新注册的用户会比老用户更活跃,大range的服务请求压力会更大;
二、按照哈希水平拆分

每一个数据库,存储某个key值hash后的部分数据,上图为例:
-
user0库,存储偶数uid数据
-
user1库,存储奇数uid数据
这个方案的好处是:
(1)规则简单,service只需对uid进行hash能路由到对应的存储服务;
(2)数据均衡性较好;
(3)请求均匀性较好;
不足是:
(1)不容易扩展,扩展一个数据服务,hash方法改变时候,可能需要进行数据迁移;
通过水平拆分来扩充系统性能,与主从同步读写分离来扩充数据库性能,有什么本质的不同?
画外音:这两个方案千万别搞混。
通过水平拆分扩展数据库性能:
(1)每个服务器上存储的数据量是总量的1/n,所以单机的性能也会有提升;
(2)n个服务器上的数据没有交集,那个服务器上数据的并集是数据的全集;
(3)数据水平拆分到了n个服务器上,理论上读性能扩充了n倍,写性能也扩充了n倍(其实远不止n倍,因为单机的数据量变为了原来的1/n);
通过主从同步读写分离扩展数据库性能:
(1)每个服务器上存储的数据量是和总量相同;
(2)n个服务器上的数据都一样,都是全集;
(3)理论上读性能扩充了n倍,写仍然是单点,写性能不变;
缓存层的水平拆分和数据库层的水平拆分类似,也是以范围拆分和哈希拆分的方式居多,就不再展开。
总结
高并发(High Concurrency)是互联网分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计保证系统能够同时并行处理很多请求。
提高系统并发能力的方法主要有两种:
-
垂直扩展(Scale Up)
-
水平扩展(Scale Out)
前者垂直扩展可以通过提升单机硬件性能,或者提升单机架构性能,来提高并发性,但单机性能总是有极限的,互联网分布式架构设计高并发终极解决方案还是后者:水平扩展。
互联网分层架构中,各层次水平扩展的实践又有所不同:
(1)反向代理层可以通过“DNS轮询”的方式来进行水平扩展;
(2)站点层可以通过nginx来进行水平扩展;
(3)服务层可以通过服务连接池来进行水平扩展;
(4)数据库可以按照数据范围,或者数据哈希的方式来进行水平扩展;
各层实施水平扩展后,能够通过增加服务器数量的方式来提升系统的性能,做到理论上的性能无限。
思路比结论重要。
相关文章:
《从MCU到FPGA:第2部分》
最近,我在做一个项目,该项目要求我这个MCU迷,转向FPGA开发。在这个系列博客中,我将介绍如何将现有的MCU知识和经验运用到FPGA的开发中。在第一部分中,我介绍了FPGA的优缺点,以及Terasic DE10 nano开发套件,并且探讨了影响FPGA设计的关键因素。现在,在第2部分,我将分析示例代码并发现更多的有用的资源。
MCU和FPGA之间的区别类似于摩托车和汽车之间的差异:尽管两者都可以让你从A点到达B点,但是机制却有着根本的不同。我认为这个类比在描述MCU和FPGA的引脚模式、引脚类型以及串并行处理时非常贴切,在这些方面,两者是完全不同的。
最初,我从Terasic的设置和指导实践开始,但是一直处于困境中。每次编译过程都会以错误结束。为了坚持下去,我会再喝一杯咖啡,并开始查阅英特尔开发人员专区网站。这个网站提供了更简单的例子,我惊讶于复杂度的降低,在这里,示例很容易理解,这些示例甚至已经被编译和运行了。一旦理解了基础知识,完成Terasic的示例就会相当简单,我认为开始觉得困难的一部分原因是由于编译器的建立,另一部分原因是现在我对它们更加熟悉了。
硬核处理器系统
Terasic DE10-Nano将MCU--即硬核处理器系统(HPS)与FPGA相结合,因此我决定从熟悉的领域即MCU开始研究。ARM(“我的第一个HPS”)的开发熟悉而简单,在Eclipse IDE中运行没有任何阻碍,并且英特尔SoC开发工具使编程系统变得更简单。我改进了“Hello World”这个范例,多加了一行,除了测试编译器的功能外,不会改变其他的功能。幸运的是,我编译成功了。IDE非常棒,非常像我过去处理过的大多数HPS IDE。
FPGA
最终,我不得不转到FPGA部分,在这一部分,我可以同时(并行)做很多事情,这与MCU的串行方式不同。这个概念可能一时难以接受,但是,考虑到这个概念较为新颖,理解起来其实也不是很困难。由于预先的配置和安装指导,Intel Developer Zone无疑是最好的一套学习指南。
Intel Developer Zone安装文件提供了基础知识,然后Terasic建立在这些新技能的基础上,增加了更多的功能并提供了完整的流程,所以这套指南教给我们的并不是寻找,复制和粘贴的学习方法。英特尔推出了我的应用程序所需的知识库,包括构建模块图,时序配置文件和I / O编程。在复杂的程序开发中,方框图能够提供清晰的视觉流程,时序配置文件则可以处理串并行协议和总线时序协议等问题。
每一个引脚都可以完成任意功能,这可能是FPGA最著名的特点了。(引脚编程是一个旅行!)引脚分配管理器非常炫酷,但查找表的工作量也是相当艰巨的。值得庆幸的是,在Quartus的最新版本中,Terasic使用详尽的命名模式,为所有端口和引脚提供了完整的映射。这使得编码部分更加简单。
遇到的挑战
在新的开发环境中工作很不舒服。新的处理过程和快捷键都需要调整。当然,新IDE的创建也会出现一些常规的设置问题。但是,文档很清晰,图像也有很大的帮助。因特尔已经拓展其性能以创建Linux系统和Windows系统,并为编程提供了Linux仿真,这些都极大的简化了原始的处理过程。但是,在设置Linux时我仍然遇到了问题,并且不再尝试自己编译的Linux IDE。后来,我找到了一个120页的指南才得以正确的设置它。下面就让我们搞清楚具体是怎么操作的吧!
Takeaways
我很喜欢这个练习,并且对此充满信心。但是,下载、配置并且弄清楚下一步要做什么是相当繁杂的。我对下一阶段的任务感到兴奋,我计划引入不同的硬件,使用示例代码来开发自己的软件,并利用HPS和FPGA技术。我的计划是利用HPS(使用外部硬件)来运行OpenCV软件,同时利用FPGA来加速视频处理过程。
请继续关注第3部分!同时,如果您是一位正在向FPGA过渡的MCU开发人员,请在评论中分享您的经验,技巧和建议!
声明:本文由贸泽电子供稿,本公众号对文中陈述、观点保持中立。