python全栈开发中级班全程笔记
第三章:员工信息增删改查作业代码
作业要求:
员工增删改查表
用代码实现一个简单的员工信息增删改查表
需求:
1、支持模糊查询,
(1、find name ,age form staff_table where age > 22
(查找 staff_fable (文件)内所有 age > 22 的name 和 age全部打印)
(2、find * from staff_table where dept = "IT"
(查找所有部门是 IT的所有列打印出来*代表所有)
(3、find * from staff_table where enroll_date like "2013"
(查找所有 enroll_date (登记日期)为 2013的序列并打印)
2、可创建员工信息记录,以 phone 做唯一键(既不允许表内有手机号重复的情况),staff_id 需自增
语法格式为:add staff Alex Li,25,134435344,IT,2015-10-29
3、可删除指定员工信息记录,输入员工id 即可删除
语法格式:del staff 3
4、可修改员工信息 语法如下:
UPDATE staff_table SET dept = "Market" WHERE dept = "IT"(把部门是 IT 的全部更改成 Market)
UPDATE staff_table SET age = 25 WHERE name = "Alex Li" (把 name = Alex Li 的年龄改成 25 )
以上每条语句执行完毕后,要显示影响了多少条记录,(比如查询,要显示查询出多少条、修改要显示修改多少条
整体思路图:
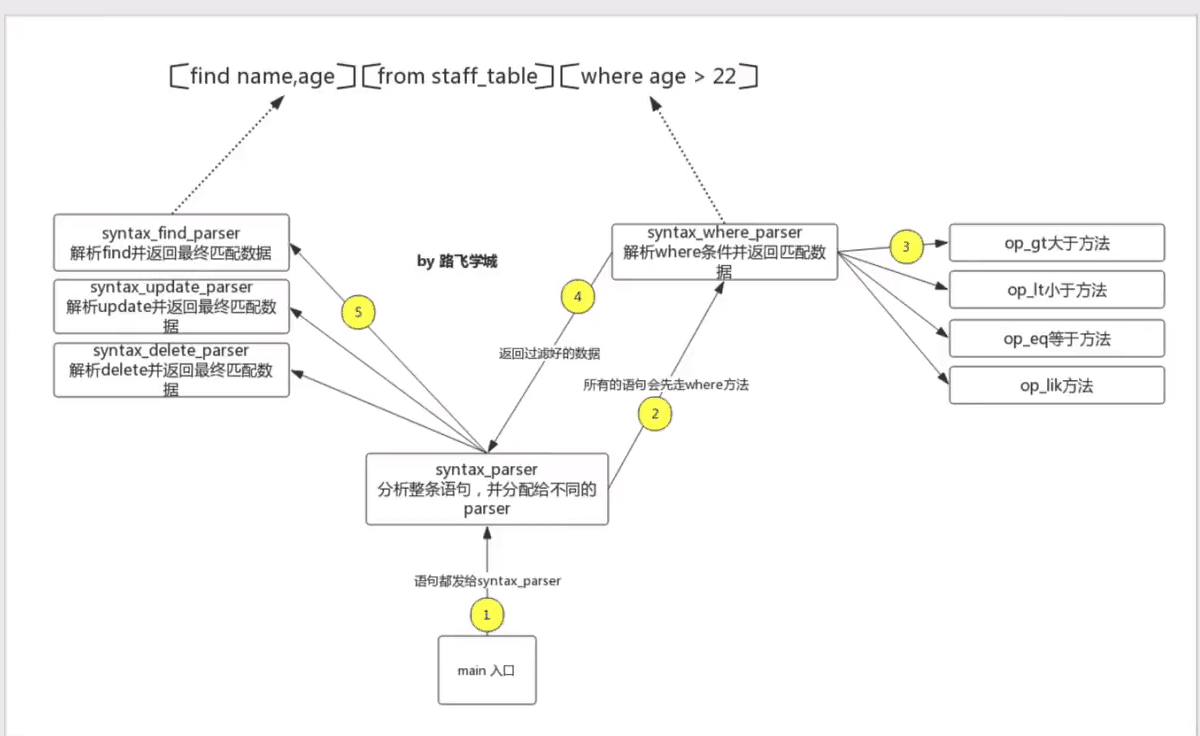
代码奉上:
# -*- coding:utf-8 -*- from tabulate import tabulate import os FILE_NAME = "staff_table" OPTION = ["id", "name", "age", "phone", "dept", "enroll_date"] # 加载员工信息表并转成指定格式 def info(file_name): data = {} for i in OPTION: data[i] = [] with open(file_name, "r", encoding="utf-8") as f: for line in f: staff_id, name, age, phone, dept, enroll_date = line.strip().split(",") data["id"].append(staff_id) data["name"].append(name) data["age"].append(age) data["phone"].append(phone) data["dept"].append(dept) data["enroll_date"].append(enroll_date) return data INFO_DATA = info(FILE_NAME) # 程序启动后就执行 # 把修改的数据写入硬盘 def write_info(): f = open("%s" % FILE_NAME, "w", encoding="utf-8") for index, staff_tb in enumerate(INFO_DATA["id"]): res = [] for col in OPTION: res.append(INFO_DATA[col][index]) f.write(",".join(res)+"\n") # 报错字体颜色 def print_log(calc, log_type = "info"): if log_type == "info": print("\033[33;1m%s\033[0m" % calc) elif log_type == "error": print("\033[31;1m%s\033[0m" % calc) # 自动删除函数 def del_info(del_name, del_term): for index, del_loop in enumerate(INFO_DATA[del_name]): if del_loop == del_term: for del_key in OPTION: del INFO_DATA[del_key][index] write_info() return else: print_log("没有此序号或未检测到关键字[id=NO.]", "error") # 解析条件并返回值 def less(field, term): result = [] for index, cont in enumerate(INFO_DATA[field]): if float(cont) > float(term): whole_article = [] for cont_name in OPTION: whole_article.append(INFO_DATA[cont_name][index]) result.append(whole_article) return result def greater(field, term): result = [] for index, cont in enumerate(INFO_DATA[field]): if float(cont) < float(term): whole_article = [] for cont_name in OPTION: whole_article.append(INFO_DATA[cont_name][index]) result.append(whole_article) return result def equal(field, term): result = [] for index, cont in enumerate(INFO_DATA[field]): if cont == term: whole_article = [] for cont_name in OPTION: whole_article.append(INFO_DATA[cont_name][index]) result.append(whole_article) return result def like(field, term): result = [] for index, cont in enumerate(INFO_DATA[field]): if term in cont: whole_article = [] for cont_name in OPTION: whole_article.append(INFO_DATA[cont_name][index]) result.append(whole_article) return result # 解析 where 条件并过滤数据 def syntax_where(offside): handle = {">": less, "<": greater, "=": equal, "like": like } for _key, func in handle.items(): if _key in offside: field, term = offside.split(_key) match_result = func(field.strip(), term.strip()) return match_result else: print_log("语法错误:where条件只支持[>,<,=,where]", "error") # 解析 find 语句并返回结果 def syntax_find(content, condition): find_name = condition.split("from")[0].split("find")[1].split(",") find_name = [i.strip() for i in find_name] if "*" in find_name[0]: print(tabulate(content, headers=INFO_DATA, tablefmt="grid")) else: title_list = [] for title in content: item_list = [] for item in find_name: item_index = OPTION.index(item) item_list.append(title[item_index]) title_list.append(item_list) print(tabulate(title_list, headers=find_name, tablefmt="grid")) print_log("成功查询到%s条数据" % len(content), "info") # 增加条目函数 def syntax_add(content, codition): codition = codition.split("staff_table")[1].split(",") if codition[2] in INFO_DATA["phone"]: print_log("手机号码重复", "error") else: id_id = [] for add_id in INFO_DATA["id"]: id_id.append(int(add_id)) codition.insert(0, (id_id[-1] + 1)) for last_name, last_info in zip(OPTION, codition): INFO_DATA[last_name].append(str(last_info)) write_info() print_log("成功增加第%s条数据" % int(len(content)+1), "info") # 删除条目函数 def syntax_del(content, codition): codition = [i.strip() for i in codition.split(" ")] if "id" in codition[3]: if "id" in codition[-1]: del_name, del_term = codition[-1].split("=") del_info(del_name, del_term) elif "id" in codition[3]: del_name = codition[-3] del_term = codition[-1] del_info(del_name, del_term) print_log("成功删除第%s条数据" % del_term, "info") else: print_log("没有此序号或未检测到关键字[id=NO.]", "error") elif "id"not in codition and len(content) > 0: del_info(del_name="id", del_term=content[0][0]) print_log("成功删除第%s条数据" % content[0][0], "info") else: print_log("没有此序号或未检测到关键字[id=NO.]", "error") # 修改的函数 def syntax_update(content, codition): codition = codition.split("set") if len(codition) > 1: index_own, number = codition[1].strip().split("=") for index_value in content: ind_index = index_value[0] ind_index_id = INFO_DATA['id'].index(ind_index) INFO_DATA[index_own.strip()][ind_index_id] = number.strip() write_info() # 修改后的数据写进文件 print_log("成功修改%s条数据" % len(content), "info") else: print_log("语法格式错误,不存在 set 关键词", "error") # 解析语句并执行 def syntax_parser(order): syntax_dict = { "find": syntax_find, "add": syntax_add, "del": syntax_del, "update": syntax_update } if order.split(" ")[0] in ("find", "add", "del", "update"): if "where" in order: left_side, offside = order.split("where") final_result = syntax_where(offside) else: final_result = [] for index, info_id in enumerate(INFO_DATA["id"]): info_set = [] for i in OPTION: info_set.append(INFO_DATA[i][index]) final_result.append(info_set) left_side = order order_start = order.split()[0] if order_start in syntax_dict: syntax_dict[order_start](final_result, left_side) else: print_log("语法错误!\n[find/ add/ del/ update [size] from [staff_table] where [term][>,<,=,like][parameter]\n", "error") # 让用户输入语句并执行! def main(): while True: order = input("staff_db:"). strip() if not order: continue syntax_parser(order) main()