本篇以实例介绍selenium下的webdriver模块提供的定位页面元素(也可以称为对象)的方法和使用技巧,在此注意:在做WEB自动化测试前,需要对前端相关的技术有所了解,如HTML、XML、Xpath、CSS、JS等,另外还需要学习Pyhton基础语法和编程规范,比如python代码块的缩进。
1 前端技术名词解释
(1) HTML:超文本标记语言(英语:HyperText Markup Language,简称:HTML)是一种用于创建网页的标准标记语言。可以理解为千姿百态的网页最原始的形态。
(2) XML:扩展标记语言,设计用来传输和存储数据。HTML可以看成是XML的一种呈现。
(3) Xpath:一种在XML文档中查找信息的语言,通常为路径表达式。
(4) CSS:层叠样式表。
(5) JS:即JavaScript,web编程语言,现代软件网页JS脚本都会嵌入到HTML的标签中。
想要学习Python?Python学习交流群:984632579满足你的需求,资料都已经上传群文件,可以自行下载!
2 Selenium-webdriver定位元素
下面以博客园注册页面为例,如下图:

大家都知道页面上有输入框、文本信息、按钮等,这些是什么?这些都是一个个元素,在软件中都可以看做是一个个对象。怎么通过自动化来识别并定位到这些元素或者对象呢?
Selenium-webdriver模块库提供了8种定位元素的方法:
(1) find_element_by_id ()
(2) find_element_by_name()
(3) find_element_by_class_name()
(4) find_element_by_tag_name()
(5) find_element_by_link_text()
(6) find_element_by_partial_link_text()
(7) find_element_by_xpath()
(8) find_element_by_css_selector()
接下来我们就要将鼠标移动到邮箱的输入框准备输入用户了,可是自动化工具没你聪明啊!它不知道这个输入框在哪啊,这个时候我们来看下网页的真实面目,通过按F12或者右键选择【查看源】来看看网页原始的面貌,如下图:
没错它就是网页最原始的HTML形态,我们可以看到页面上的每一个元素都是一行HTML代码。
上图定位的就是邮箱输入框所在的HTML代码行,HTML代码都是以标签对的形式存在,我们可以看到输入框是一个input的标签,嘿嘿,我们看到了id,没错,这个标签中描述的就是【邮箱】这个输入框的属性,有name、class、id等属性,就好像一个人一样,有名称、性别、体重等属性一样。有了这些我们就可以使用webdriver提供的方法来找到它。
一. 通过id定位
webdriver提供的方法为find_element_by_id()
我们在Pycharm中新建一个register_page.py文件,通过id的方法定位到【邮箱】输入框这个元素并输入邮箱,然后退出浏览器,脚本如下:

二. 通过name定位
上面的【邮箱】输入框的元素HTML中也提供了name的属性了,这样我们只需要把上面的脚本文件的email = driver.find_element_by_id(‘Email’)改为对应的name属性方法即可:
email = driver.find_element_by_name(‘Email’),如果HTML没有提供该元素的name属性,那我们就没法使用name来定位它
三. 通过class定位
Class也是网页很多元素都有的一个属性,它的定位和id/name类似,注册页面的【注册】按钮,查看HTML可知其class属性值,如下图:
因此我们定位该按钮元素是可以使用:driver.find_element_by_class_name('btn ladda-button center-block cnblogs-btn-blue')来定位到该元素。
但该方法不建议经常使用,因为页面很多元素都会有class属性,如果网页复杂,通过class定位难免会出现class属性值一样的元素,那就无法完全定位到该元素,还是注册页面:我们看看【密码】和【确认密码】两个元素属性,如下面HTML中这两个元素的class属性:

没错,它们的class属性完全一样,这样,在定位这两个元素时是不能用class属性来定位的
四. 通过tag定位
tag 定位是取的该元素的HTML中描述该元素的标签的名称,如上面的【邮箱】输入框,它的tag标签就是一个input,我们可以写为email=driver.find_element_by_tag_name(‘input’),可想而知一个网页一般会有很多input标签,此方法也是不建议单独使用,该方法只是针对非常简单的页面才有那么点用
五. 通过link定位
link_text()方法是通过元素标签对间的的文本信息定位,如上面的【注册】按钮我们除了使用class、id等定位外,还可以使用link定位:
这样我们定位【注册】这个元素还可以写成:driver.find_element_by_link_text(‘注册’)
六. 通过partial_link定位
Partial_link其实只是对link方法的一种补充,也就是部分标签对文本信息定位。适用于标签对之间文本信息比较长的情况,我们只需选取一部分文本就行。
我们可以将上面定位的【注册】元素那行代码改为:
driver.find_element_by_partial_link(“注”)也是可以定位的
七. 通过Xpath定位
Xpath是一种在XML文档中查找信息的语言,一般为一段路径表达式,在学习Xpath定位前请务必先学习下XML、HTML以及Xpath的基本语法,这个方法也是最重要的准确定位元素的方法,这样会对以后页面元素定位更加游刃有余。
学习可以参考W3SChool网站:
http://www.w3school.com.cn/index.html
Selenium-webdriver提供了find_element_by_xpath()的方法
(1) 通过绝对路径定位
由于HTML网页源代码也是一层一层的,通过Xpath绝对路径查找,就如找一个人一样,这个人一定存在某个唯一的空间地理位置,比如xx 省xx 市xx 区xx 路xx 号,同样我们要找的这个输入框也是在HTML的一个位置,上图可以看到HTML是有很多层级的,这样我们可以一层一层像剥笋一样找到它,如下为【邮箱】这个元素在HTML的层级位置
那么我们的脚本定位【邮箱】输入框可以写成这样:

这就是Xpath方法绝对路径写法,使用绝对路径你是完全可以找到该元素的,只不过,你懂得,现代的网页多复杂多绚丽,可想而知HTML层级会很多,难道你还傻不拉几的从源头的html标签对开始写起吗?接下来,我们使用xpath的相对路径写法来照样找到这个【邮箱】输入框的位置
(2) 通过相对路径定位
在使用相对路径定位前,需要去学习下HTML代码的相关知识和特点以及Xpath路径表达式的语法编写特点,多学点总是好的。
下面使用相对路径来定位它,如下代码:
【邮箱】输入框的xpath表达式为//*[@id=’Email’]
这个表达式什么意思?双斜杠//表示从当前HTML文档中查找而不考虑它的位置,*匹配整个HTML,@表示获取元素属性,最后id=表示该元素的属性id值,这样我们合理的使用Xpath的相对路径语法来定位元素将会起到事半功倍的效果。
后续的Xpath相关的步语法、轴语法以及相关的函数功能方法得学习灵活使用哦。
如果有使用Chrome浏览器的,还可以copy相关的Xpath路径哦,打开Chrome,按F12,如下图:
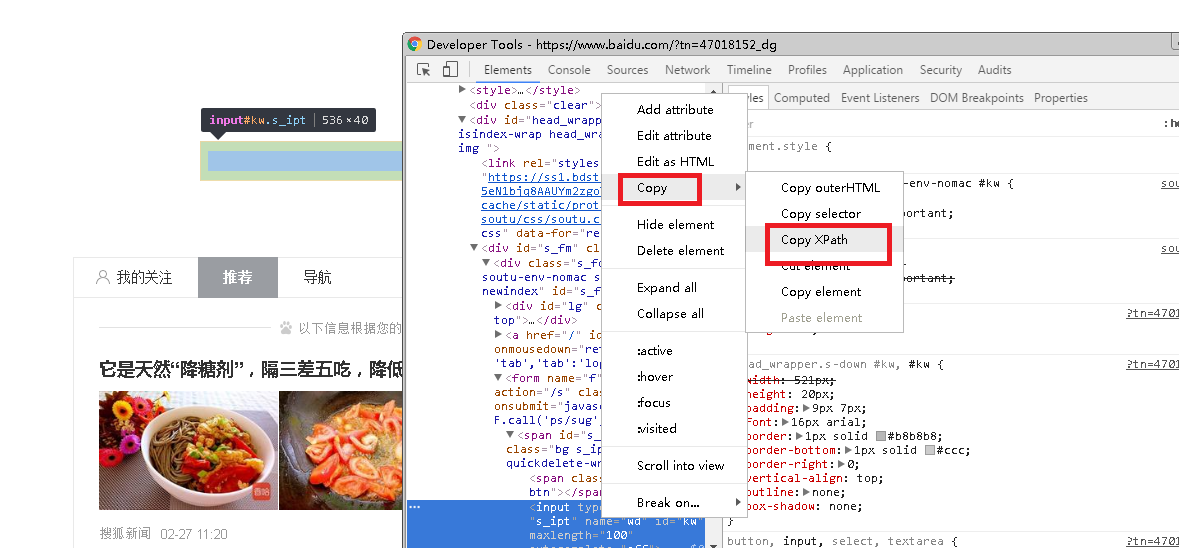
八. 通过CSS定位
此种方法其实和xpath类似,看个人习惯和爱好,也是需要我们学习css的语法,这里不介绍。selenium-webdriver提供的方法为:find_element_by_css_selector()
总结:这样我们了解selenium-webdriver模块提供的元素定位方法,这里LZ首推的方法:Xpath定位,然后再是id、name、link等定位,这些方法需要不断地学习和实践方才能运用的游刃有余,如果写多了元素定位的方法就知道Xpath一定是要掌握的,另外这些定位方法也可以结合起来共同定位给一个元素,目的就是要在一个网页中唯一定位到该元素。