1、其中optimizer的作用,其主要起到的作用就是进行权重的更新,如下:
net=models.resnet50(pretrained=False)
learning_rate=0.01
# 权重更新 如果使用自带的optimizer函数进行梯度更新,效率更好,因为其还可以引入梯度
#下降的方法,例如动量等方法
for f in net.parameters():
f.data.sub_(f.grad.data*learning_rate)
# 使用optimizer进行更新的方法
import torch.optim as optim
inputdata=[1,2,3]
criterion=torch.nn.CrossEntropyLoss()
optimizer=optim.SGD(net.parameters(),lr=0.01)
optimizer.zero_grad()
output=net(inputdata)
loss=criterion(output,inputdata)
# 进行反向梯度计算
loss.backward()
# 进行权重更新
optimizer.step()注意:如果想在权重更新时加入权重衰减(weight_decay)、动量(momentum)功能,则可以在声明optimizer时如下定义:
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.03, momentum=0.9)2、自动求导autograd函数功能
A、
# 自动求导
# 自动求导
from torch.autograd import Variable
x = torch.ones(1)
x = Variable(x, requires_grad=True)
y = x * 2
y.backward()
print(x.grad)
其输出结果为:
tensor([2.])在pytorch里的每个变量都有一个标记:requires_grad,允许从梯度计算中细分排除子图,并可以提高效率。
如果一个输入变量定义requires_grad,那么他的输出也可以哦那个requires_grad;相反,只有所有的输入变量都不定义requires_grad梯度,才不会输出梯度。如果其中所有的变量都不需要计算梯度,在子图中则不会执行向后操作计算。如下:
x=Variable(torch.randn(2,2))
y=Variable(torch.randn(2,2))
z=Variable(torch.randn(2,2),requires_grad=True)
a=x+y
print(a.requires_grad)
b=x+z
print(b.requires_grad)其输出结果为:
False
True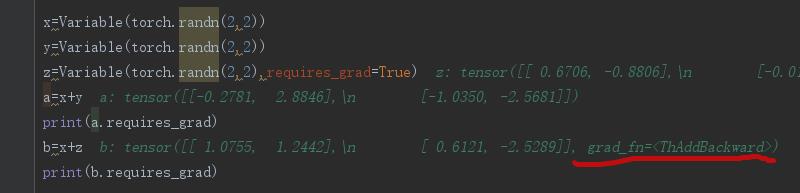
注意:从断点可以看出,当有梯度计算的时候其后面有个grad_fn参数,如果要是没有这个参数,例如a拿去进行方向梯度计算backward则会报错,如下:
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn此时只要把损失值加上一个requires_grad参数即可,如下:
out_selected_a = Variable(torch.from_numpy(out_a.cpu().data.numpy()[hard_triplets]).cuda(),requires_grad=True)
out_selected_p = Variable(torch.from_numpy(out_p.cpu().data.numpy()[hard_triplets]).cuda(),requires_grad=True)
out_selected_n = Variable(torch.from_numpy(out_n.cpu().data.numpy()[hard_triplets]).cuda(),requires_grad=True)
triplet_loss = TripletMarginLoss(args.margin).forward(out_selected_a, out_selected_p, out_selected_n).cuda()
triplet_loss.backward()既可以正确的进行反向梯度计算。
B、
当使用预训练的模型时,这个标志特别有用,其可以用来冻结部分层,这个需要事先知道有哪些层,哪些层需要冻结。
例如:如果想调整预训练的CNN,只要设置requires_grad标志即可。如下:
model = models.resnet50(pretrained=True)
# 冻结部分的层的权重
for params in model.parameters():
params.requres_grad = False
# 替换最后的全连层,新的网路构造层的requires_grad默认是True
model.fc = torch.nn.Linear(512, 1000)
# 定义优化器,这里虽然传了全部模型的参数,但是其由于上面冻结了一些层,所以这里只会更新最后的全连层
optomizer = torch.optim.SGD(model.parameters(), lr=1e-2, momentum=0.9)另外一种只更新特定层的权重参数方法为:
# 另一种冻结模型的方法:传给优化器需要更新的网络参数即可
model=models.resnet50(pretrained=True)
optomizer=torch.optim.SGD(model.fc.parameters(),lr=1e-2,momentum=0.9)3、关于numpy与torch里的数据类型转换问题:
n1 = np.array([1., 2.], dtype=np.float32)
n2 = np.array([1., 2.], dtype=np.int32)
# 其中from_numpy不会进行数据的深拷贝
t1 = torch.from_numpy(n1)
# 这里的是把float型转换为torch里的float型,由于数据类型相同不会进行深拷贝
t2 = torch.FloatTensor(n1)
#这里把int型转换为torch里的float型,由于数据类型不同会进行深拷贝
t3 = torch.FloatTensor(n2)
print("n1:", n1)
print("n2", n2)
print("t1", t1)
print("t2", t2)
print("t3", t3)
n1[0] = 5.
print("t1_size:", t1.size())
print("n2:", n2)
print("t1:", t1)
print("t2:", t2)
print("t3", t3)
print("计算完成")注意:这里的如果数据类型相同则不会进行深拷贝,如果不同则会进行深拷贝。
b、关于tensor转换成numpy,其情况主要分为两类:
如果当tensor是在GPU上使用的指令是:
#其中data主要是为了再train模式不报错。而在valid模式下要不要data都无所谓,所以统一都加data.
data1=out_a.cpu().data.numpy()如果上面的在train模式下不加data,则会报如下错误:
RuntimeError: Can't call numpy() on Variable that requires grad.
Use var.detach().numpy() instead.如果当tensor是在CPU上的指令是即可以使用上面的也可以使用下面的:
data1=out_a.numpy()注意:由于网络是再GPU上运行的其输出数据也是在GPU上,要先使用cpu()拷贝到CPU上,
4、模型训练的时候报cuda rumtime error(2): out of memory
如错误消息所示,您的GPU上的内存不足。由于我们经常在PyTorch中处理大量数据,因此小错误可能会迅速导致程序耗尽所有 GPU;幸运的是,这些情况下的修复通常很简单。这里有几个常见的事情要检查:
不要在训练循环中累积历史记录。默认情况下,当计算涉及到有需要梯度的变量时,此计算过程将保留运算的历史记录。这意味着您应该避免在计算中使用这些变量,这些变量的生存期将超出您的训练循环(例如在跟踪统计数据时)。您应该分离该变量或访问其底层数据。
有时,当可微分变量可能发生时,它可能并不明显。考虑以下训练循环(从源代码节选):
total_loss = 0
for i in range(10000):
optimizer.zero_grad()
output = model(input)
loss = criterion(output)
#进行反向传播的时候要用具有历史记录的loss进行传播
loss.backward()
optimizer.step()
#这里记录的total_loss是为了计算平均损失的,所有这里要改为total_loss += float(loss)
total_loss += loss在本例中,由于 loss 是具有 autograd 历史记录的可微分变量,所以 total_loss 将在整个训练循环中累积历史记录。你可以替换成 total_loss + = float(loss) 来解决这个问题。为什么这个方法可以进行减少内存,因为其通过float后转换的类型是不具有历史记录的可微分变量。
这个问题的另一个例子:1
删除你不需要的张量和变量。如果将一个张量或变量分配到一个局部栈,在局部栈超出作用域之前,Python 都不会将其释放。您可以使用 del x 释放该引用。同样,如果将一个张量或变量赋值给对象的成员变量,直到该对象超出作用域之前,它将不会释放。如果你及时删除你不需要的临时变量,你将获得最佳的内存使用率。
作用域的范围可能比你想象的要大。例如:
for i in range(5):
intermdeiate = f(input[i])
result += g(intermediate)
output = h(result)
return output在本段代码中,即使当 h 在执行时,intermediate 仍然存在,因为它的作用域延伸出了循环的末尾。为了尽早释放它,当你不需要它时,你应该用 del intermediate 删除这个中间值。