平均数编码
平均数编码是针对高基数定性特征(类别特征)的数据预处理方法。在本次比赛中例如item_brand_id、item_city_id等等都是属于高基数的类别特征,如果对这些特征使用ONE-HOT编码,特征维数将是一个52万*6万的稀疏矩阵。而sklearn包的LabelEncoding编码默认包含了顺序,例如data中共有2000种item_brand_id,编码后的取值范围就是[1,2,...,2000]。
平均数编码本质上和模型融合里的stacking思想类似。使用了经验贝叶斯Empirical Bayes对is_trade进行编码
换句话说,平均数编码属于有监督学习,根据该特征相对is_trade的先验概率和后验概率进行编码,这里的先验概率和后验概率类似于前面特征工程中交叉特征的点击率和推送次数,如果推送次数较少,那么先验概率的权重就会较小,编码依赖于后验概率,反之同理。显然这是带有穿越特征的,为了防止过拟合需要k折交叉(kfold,stacking核心思想)。
而且catboost对类别型特征的编码方式就是基于平均数编码。
下面是将代码拿过来,在本次比赛环境下的调用:
首先声明类
class MeanEncoder:
def __init__(self, categorical_features, n_splits=5, target_type='classification', prior_weight_func=None):
"""
:param categorical_features: list of str, the name of the categorical columns to encode
:param n_splits: the number of splits used in mean encoding
:param target_type: str, 'regression' or 'classification'
:param prior_weight_func:
a function that takes in the number of observations, and outputs prior weight
when a dict is passed, the default exponential decay function will be used:
k: the number of observations needed for the posterior to be weighted equally as the prior
f: larger f --> smaller slope
"""
self.categorical_features = categorical_features
self.n_splits = n_splits
self.learned_stats = {}
if target_type == 'classification':
self.target_type = target_type
self.target_values = []
else:
self.target_type = 'regression'
self.target_values = None
if isinstance(prior_weight_func, dict):
self.prior_weight_func = eval('lambda x: 1 / (1 + np.exp((x - k) / f))', dict(prior_weight_func, np=np))
elif callable(prior_weight_func):
self.prior_weight_func = prior_weight_func
else:
self.prior_weight_func = lambda x: 1 / (1 + np.exp((x - 2) / 1))
@staticmethod
def mean_encode_subroutine(X_train, y_train, X_test, variable, target, prior_weight_func):
X_train = X_train[[variable]].copy()
X_test = X_test[[variable]].copy()
if target is not None:
nf_name = '{}_pred_{}'.format(variable, target)
X_train['pred_temp'] = (y_train == target).astype(int) # classification
else:
nf_name = '{}_pred'.format(variable)
X_train['pred_temp'] = y_train # regression
prior = X_train['pred_temp'].mean()
col_avg_y = X_train.groupby(by=variable, axis=0)['pred_temp'].agg({'mean': 'mean', 'beta': 'size'})
col_avg_y['beta'] = prior_weight_func(col_avg_y['beta'])
col_avg_y[nf_name] = col_avg_y['beta'] * prior + (1 - col_avg_y['beta']) * col_avg_y['mean']
col_avg_y.drop(['beta', 'mean'], axis=1, inplace=True)
nf_train = X_train.join(col_avg_y, on=variable)[nf_name].values
nf_test = X_test.join(col_avg_y, on=variable).fillna(prior, inplace=False)[nf_name].values
return nf_train, nf_test, prior, col_avg_y
def fit_transform(self, X, y):
"""
:param X: pandas DataFrame, n_samples * n_features
:param y: pandas Series or numpy array, n_samples
:return X_new: the transformed pandas DataFrame containing mean-encoded categorical features
"""
X_new = X.copy()
if self.target_type == 'classification':
skf = StratifiedKFold(self.n_splits)
else:
skf = KFold(self.n_splits)
if self.target_type == 'classification':
self.target_values = sorted(set(y))
self.learned_stats = {'{}_pred_{}'.format(variable, target): [] for variable, target in
product(self.categorical_features, self.target_values)}
for variable, target in product(self.categorical_features, self.target_values):
nf_name = '{}_pred_{}'.format(variable, target)
X_new.loc[:, nf_name] = np.nan
for large_ind, small_ind in skf.split(y, y):
nf_large, nf_small, prior, col_avg_y = MeanEncoder.mean_encode_subroutine(
X_new.iloc[large_ind], y.iloc[large_ind], X_new.iloc[small_ind], variable, target, self.prior_weight_func)
X_new.iloc[small_ind, -1] = nf_small
self.learned_stats[nf_name].append((prior, col_avg_y))
else:
self.learned_stats = {'{}_pred'.format(variable): [] for variable in self.categorical_features}
for variable in self.categorical_features:
nf_name = '{}_pred'.format(variable)
X_new.loc[:, nf_name] = np.nan
for large_ind, small_ind in skf.split(y, y):
nf_large, nf_small, prior, col_avg_y = MeanEncoder.mean_encode_subroutine(
X_new.iloc[large_ind], y.iloc[large_ind], X_new.iloc[small_ind], variable, None, self.prior_weight_func)
X_new.iloc[small_ind, -1] = nf_small
self.learned_stats[nf_name].append((prior, col_avg_y))
return X_new
def transform(self, X):
"""
:param X: pandas DataFrame, n_samples * n_features
:return X_new: the transformed pandas DataFrame containing mean-encoded categorical features
"""
X_new = X.copy()
if self.target_type == 'classification':
for variable, target in product(self.categorical_features, self.target_values):
nf_name = '{}_pred_{}'.format(variable, target)
X_new[nf_name] = 0
for prior, col_avg_y in self.learned_stats[nf_name]:
X_new[nf_name] += X_new[[variable]].join(col_avg_y, on=variable).fillna(prior, inplace=False)[
nf_name]
X_new[nf_name] /= self.n_splits
else:
for variable in self.categorical_features:
nf_name = '{}_pred'.format(variable)
X_new[nf_name] = 0
for prior, col_avg_y in self.learned_stats[nf_name]:
X_new[nf_name] += X_new[[variable]].join(col_avg_y, on=variable).fillna(prior, inplace=False)[
nf_name]
X_new[nf_name] /= self.n_splits
return X_new然后进行调用
MeanEnocodeFeature = ['item_city_id','item_brand_id'] #声明需要平均数编码的特征 ME = MeanEncoder(MeanEnocodeFeature) #声明平均数编码的类 trans_train = ME.fit_transform(X,y)#对训练数据集的X和y进行拟合 test_trans = ME.transform(X_test)#对测试集进行编码
PCA降维
同样是在网络上找到的代码,本次比赛中由于交叉特征维度太大,超过500维电脑就带不动了,想通过PCA降维来减少维度,画出来的曲线十分陡峭,代码可以成功运行,但是笔记本运行起来太慢了。这个是下次比赛可以尝试的地方。
class PCA(object):
"""定义PCA类"""
def __init__(self, x, n_components=None):
"""x的数据结构应为ndarray"""
self.x = x
self.dimension = x.shape[1]
if n_components and n_components >= self.dimension:
raise DimensionValueError("n_components error")
self.n_components = n_components
def cov(self):
"""求x的协方差矩阵"""
x_T = np.transpose(self.x) #矩阵转秩
x_cov = np.cov(x_T) #协方差矩阵
return x_cov
def get_feature(self):
"""求协方差矩阵C的特征值和特征向量"""
x_cov = self.cov()
a, b = np.linalg.eig(x_cov)
m = a.shape[0]
c = np.hstack((a.reshape((m,1)), b))
c_df = pd.DataFrame(c)
c_df_sort = c_df.sort(columns=0, ascending=False) #按照特征值大小降序排列特征向量
return c_df_sort
def explained_varience_(self):
c_df_sort = self.get_feature()
return c_df_sort.values[:, 0]
def paint_varience_(self):
explained_variance_ = self.explained_varience_()
plt.figure()
plt.plot(explained_variance_, 'k')
plt.xlabel('n_components', fontsize=16)
plt.ylabel('explained_variance_', fontsize=16)
plt.show()
def reduce_dimension(self):
"""指定维度降维和根据方差贡献率自动降维"""
c_df_sort = self.get_feature()
varience = self.explained_varience_()
if self.n_components: #指定降维维度
p = c_df_sort.values[0:self.n_components, 1:]
y = np.dot(p, np.transpose(self.x)) #矩阵叉乘
return np.transpose(y)
varience_sum = sum(varience) #利用方差贡献度自动选择降维维度
varience_radio = varience / varience_sum
varience_contribution = 0
for R in xrange(self.dimension):
varience_contribution += varience_radio[R] #前R个方差贡献度之和
if varience_contribution >= 0.99:
break
p = c_df_sort.values[0:R+1, 1:] #取前R个特征向量
y = np.dot(p, np.transpose(self.x)) #矩阵叉乘
return np.transpose(y)
下面是调用,具体还是去看网上博客。
pca = PCA(X.fillna(0)) X_reduce_feature = pca.reduce_dimension()
catboost
这个包是毛熊那边出的包,可以直接训练类别型数据(包括字符串,xgb,lgb都不能输入字符型特征),
在实际调试过程中:
运行速度:lgb>cat>xgb
结果精度:xgb>cat>=lgb
在使用这三个包时没有调参,catbost如果指定哪些列是属性类特征也许会有更好的表现效果。留在下次比赛中再熟悉了。
lr+xgboost
xgb+lr参考资料这个是CTR预估类比赛常用的方法,网上有成熟的代码。但是在lr+xgboost、lr单模型或者stacking的第二层模型使用lr,效果都不尽人意,应该前期特征工程没有做好的原因。
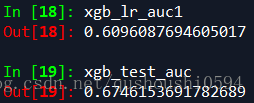
在lr+xgboost中,如果把xgboost的叶子结点放入lr模型中训练然后再预测,得到的AUC值将从原来只用xgb训练的0.6746降到0.6096,效果变差了。核算logloss也是如此。有可能使用方法不对,期待在下一次比赛时候的表现。
def lgb_lr(data):
'''Descr:输入:已经构建好特征的数据data
输出:xgb,xgb+lr模型的AUC比较,logloss比较
'''
train= data[(data['day'] >= 18) & (data['day'] <= 23)]
test= data[(data['day'] == 24)]
drop_name = ['is_trade',
'item_category_list', 'item_property_list',
'predict_category_property',
'realtime'
]
col = [c for c in train if
c not in drop_name]
X_train = train[col]
y_train = train['is_trade'].values
X_test = test[col]
y_test = test['is_trade'].values
xgboost = xgb.XGBClassifier(n_estimators=300,max_depth=4,seed=5,
learning_rate=0.11,subsample=0.8,
min_child_weight=6,colsample_bytree=.8,
scale_pos_weight=1.6, gamma=10,
reg_alpha=8,reg_lambda=1.3,silent=False,
eval_metric='logloss')
xgboost.fit(X_train, y_train)
y_pred_test = xgboost.predict_proba(X_test)[:, 1]
xgb_test_auc = roc_auc_score(y_test, y_pred_test)
print('xgboost test auc: %.5f' % xgb_test_auc)
#y_tes = test['is_trade'].values
# xgboost编码原有特征
X_train_leaves = xgboost.apply(X_train)
X_test_leaves = xgboost.apply(X_test)
# 合并编码后的训练数据和测试数据
All_leaves = np.concatenate((X_train_leaves, X_test_leaves), axis=0)
All_leaves = All_leaves.astype(np.int32)
# 对所有特征进行ont-hot编码
xgbenc = OneHotEncoder()
X_trans = xgbenc.fit_transform(All_leaves)
(train_rows, cols) = X_train_leaves.shape
# 定义LR模型
lr = LogisticRegression()
# lr对xgboost特征编码后的样本模型训练
lr.fit(X_trans[:train_rows, :], y_train)
# 预测及AUC评测
y_pred_xgblr1 = lr.predict_proba(X_trans[train_rows:, :])[:, 1]
xgb_lr_auc1 = roc_auc_score(y_test, y_pred_xgblr1)
print('基于Xgb特征编码后的LR AUC: %.5f' % xgb_lr_auc1)
# 定义LR模型
lr = LogisticRegression(n_jobs=-1)
# 组合特征
X_train_ext = hstack([X_trans[:train_rows, :], X_train])
X_test_ext = hstack([X_trans[train_rows:, :], X_test])
# lr对组合特征的样本模型训练
lr.fit(X_train_ext, y_train)
# 预测及AUC评测
y_pred_xgblr2 = lr.predict_proba(X_test_ext)[:, 1]
xgb_lr_auc2 = roc_auc_score(y_test, y_pred_xgblr2)
print('基于组合特征的LR AUC: %.5f' % xgb_lr_auc2)
#-------------------计算logloss
pred = pd.DataFrame()
pred['is_trade'] = y_test
pred['xgb_pred'] = y_pred_test
pred['xgb_lr_pred'] = y_pred_xgblr1
logloss1 = log_loss(pred['is_trade'],pred['xgb_pred'])
logloss2 = log_loss(pred['is_trade'],pred['xgb_lr_pred'])
print 'xgb logloss:'+str(logloss1)
print 'xgb+lr logloss:'+str(logloss2)