今天遇到一个极为神奇的问题。
改了名字就报错,不改就正确。
定位到错误代码

注意我黑色圈出来的东西。ioc是一个HashMap,ioc.values()返回的是一个Collection,在进行迭代的过程,我对ioc里面的内容进行了修改,看一下括号括起来的东西,我进行了remove和put,这就会引发fail-fast,即快速错误,就是知道后面肯定会报错,提前中断,抛出错误原因。
出错的原因在于我改了一个类的名字,这个类的对象在ioc中放着,为了找出错误原因,我把ioc的内容分别打印出来。
改名前

改名后

改名后就报错,这也太神奇了,仔细观察可以发现,我改名之后,ioc里面的对象位置发生了变化,被改名的类DemoAspect由最后一个,变到了最后一个。所以不应该是名字的问题,而是ioc索引顺序的问题,至于为什么改名会引起顺序变化,因为hashmap是按照hash值排序的,名字改变一定会引起hash值的改变。
所以代码本来就有问题,只是我刚好避开了问题的抛出,改了名字之后才让问题浮现了出来。
那么为什么在第一个就报错,在最后一个就不报错呢。
需要看一下hashmap的源码
/**
* The number of times this HashMap has been structurally modified
* Structural modifications are those that change the number of mappings in
* the HashMap or otherwise modify its internal structure (e.g.,
* rehash). This field is used to make iterators on Collection-views of
* the HashMap fail-fast. (See ConcurrentModificationException).
*/
transient int modCount;在hashMap中有这样一个变量(其实不光是hashMap,所有的Collection,Map都有),通过注释我们知道这是来记录修改次数的,目的是为了让迭代器快速失败。
为什么呢?
Iterator是工作在一个独立的线程中,并且拥有一个mutex锁。
Iterator被创建之后会建立一个指向原来对象的单链索引表,当原来的对象数量发生变化时,这个索引表的内容不会同步改变。
当索引指针往后移的时候就找不到要迭代的对象,所以按照fail-fast原则Iterator会马上抛出java.util.concurrentModficationException
所以Iterator在工作的时候是不允许被迭代的对象发生改变的,但是你可以用Iterator本身的方法remove()来删除对象,Iterator.remove()方法会在删除当前迭代对象的同时维护索引的一致性进入 hashmap的remove方法
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
/**
* Implements Map.remove and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to match if matchValue, else ignored
* @param matchValue if true only remove if value is equal
* @param movable if false do not move other nodes while removing
* @return the node, or null if none
*/
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;****************看这里
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
看一下我用*标记的地方,每次remove modCount会发生变化
final class Values extends AbstractCollection<V> {
public final int size() { return size; }
public final void clear() { HashMap.this.clear(); }
public final Iterator<V> iterator() { return new ValueIterator(); }
public final boolean contains(Object o) { return containsValue(o); }
public final Spliterator<V> spliterator() {
return new ValueSpliterator<>(HashMap.this, 0, -1, 0, 0);
}
public final void forEach(Consumer<? super V> action) {
Node<K,V>[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;******看这里
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next)
action.accept(e.value);
}
if (modCount != mc)******看这里
throw new ConcurrentModificationException();
}
}
}在迭代的过程中会判断modCount,如果发生变化就会抛出异常
我们在看一下hashmap内部实现的迭代器的remove方法
public final void remove() {
Node<K,V> p = current;
if (p == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null;
K key = p.key;
removeNode(hash(key), key, null, false, false);
expectedModCount = modCount;*****看这里
}注意我*号标记的地方,他在移除了Node之后,重新修改了expectedModCount,相当于把modCount重置,就是这次修改没有被记录进去。
(hashmap所有的操作都是基于node)
所有我的代码把remove删去就运行正常了,为什么put不会报异常呢,这里就要讲一下我代码的逻辑了,我是根据key判断ioc里面有没有这个key,如果有就删去这个节点,然后put新的,key还是原来的key,value发生了改变,刚开始我不知道,hashmap.put可以直接替换旧值,就用了remove。
还是那个问题put也算是修改为什么不报错呢
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key******看这里
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;******看这里
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}注意我用*号标记的地方,如果存在key的话,就直接用新值替换旧值,并直接return,并不执行++modCount这一步
到此,所以得疑惑都解决了,请注意不光是hashmap,map collection都是这样,因为他们都内部实现了迭代器这个接口
我们看一迭代器的工作流程
迭代器方法: 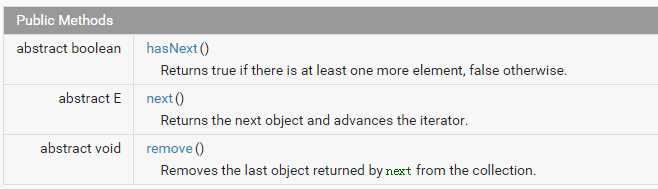
迭代器的工作原理:
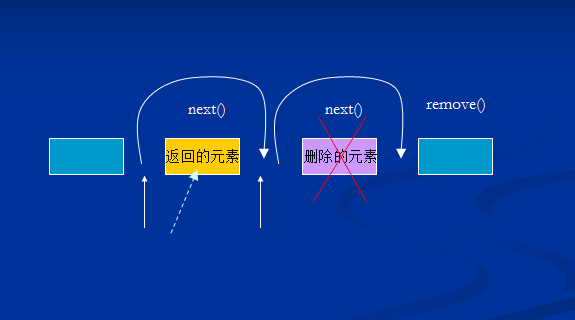
迭代器是指向两个元素之间的位置,如果后面有元素则hasNext()返回真,当我们调用next()方法时,返回黄色的元素,如上图,当我们调用remove方法是要先调用一次next(),调用remove将返回的元素删除.