课程网址:https://www.coursera.org/learn/machine-learning
Week 1 —— Introduction and Linear Regression
目录
一 介绍
1-1 机器学习概念及应用
(1)Arthur Samuel 将其描述为:the field of study that gives computers the ability to learn without being explicitly programme.
让计算机有学习的能力,而不是明确的程序。
(2)另一种更为现代化的定义是:A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
一个计算机程序被定义为从经验E学习一些分类任务T和性能测量P,如果它在任务T中的性能(由P测量)随着经验E提升。
机器学习有下面几种定义: “机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能”。 “机器学习是对能通过经验自动改进的计算机算法的研究”。 “机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。” 一种经常引用的英文定义是:A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
机器学习已经有了十分广泛的应用,例如:数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、医学诊断、检测信用卡欺诈、证券市场分析、DNA序列测序、语音和手写识别、战略游戏和机器人运用。
1-2 机器学习分类
监督学习 Supervised learning (已知经验数据E的对错标签“p”)
1.回归问题 regression(输入、**输出:连续值**)
predict continuous valued output,即需要预测的变量是连续的。
例如:已知一组数据,包含房屋的面积(x)和对应的价格(y),预测当房屋面积为特定值时(x=x0)对应的价格为多少。
2.分类问题 classification(输入、**输出:离散值**)
discrete valued output,即需要预测的变量的离散的(0 or 1)。
例如:已知一组数据,包含肿瘤的大小(size)和对应的性质(良性/恶性)(0/1),当给出肿瘤的大小时,判断其为良性还是恶性。
非监督学习 Unsupervised learning(有以往数据,但不知道他们的分类)
1.聚类 clustering
网页将每天发生的各类新闻分类,相似的新闻会归到一类。
将数据按照其内部存在的某种属性关系就行归类,是一种无监督学习方式,不需要提供预测的标签信息。
2.非聚类 non-clustering
The “Cocktail Party Algorithm”,将人说话的声音与背景音乐分离。
异常点检测等问题!也是属于非监督学习,但是可以认为其为聚类的问题
二 单变量的线性回归
2-1 假设函数(hypothesis)
首先我们定义几个符号:

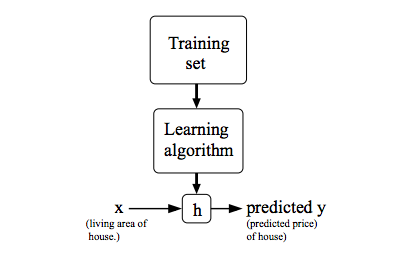
对于监督学习,我们的目标是,给定一个数据集,通过学习算法得到一个函数 h:X→Y,使得可以从 h(x) 中很好的预测出与x相对应的y值。函数h被称之为假设函数(hypothesis)。
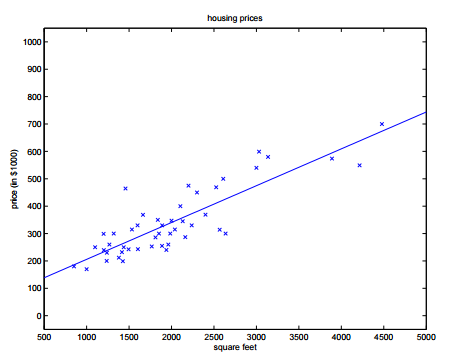
以房价预测为例,房屋面积为x,预计房价值为y,对于单变量线性回归,我们可以设假设函数(hypothesis function)为:hθ(x)=θ0+θ1x。hθ(x)可以简写为h(x)。整个过程可以用下图表示:
2-2 线性回归的表示
预测房价的例子。 像这样用一条直线来模拟房价走势,就叫做线性回归。
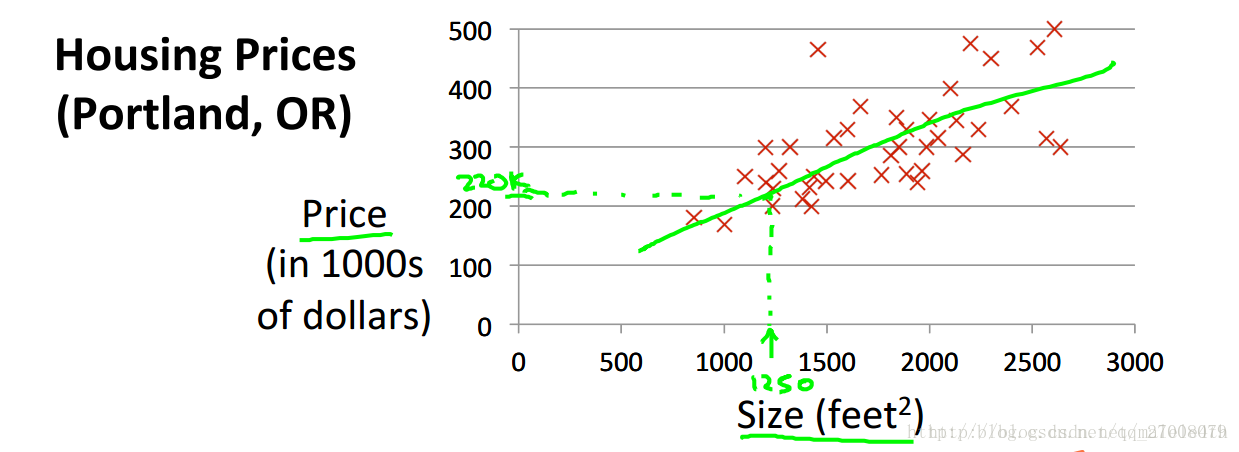
这个问题属于监督问题,每个样本都给出了准确的答案。
同时因为房价是连续值,所以这是一个回归问题,对给定值预测实际输出。
公式:
hθ(x)=θ0+θ1∗x
其中两个θ是位置参数,我们的目的是求出他俩的值。
2-3 Cost function (代价函数)
我们取怎样的θ值可以使预测值更加准确呢?
想想看,我们应使得每一个预测值hθ和真实值y差别不大,可以定义代价函数如下:
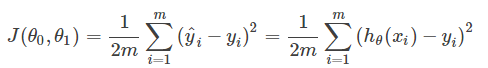
这样,只需要通过使J值取最小,即可满足需求,那么怎么使J最小化呢?
看图:误差与两个参数的关系。
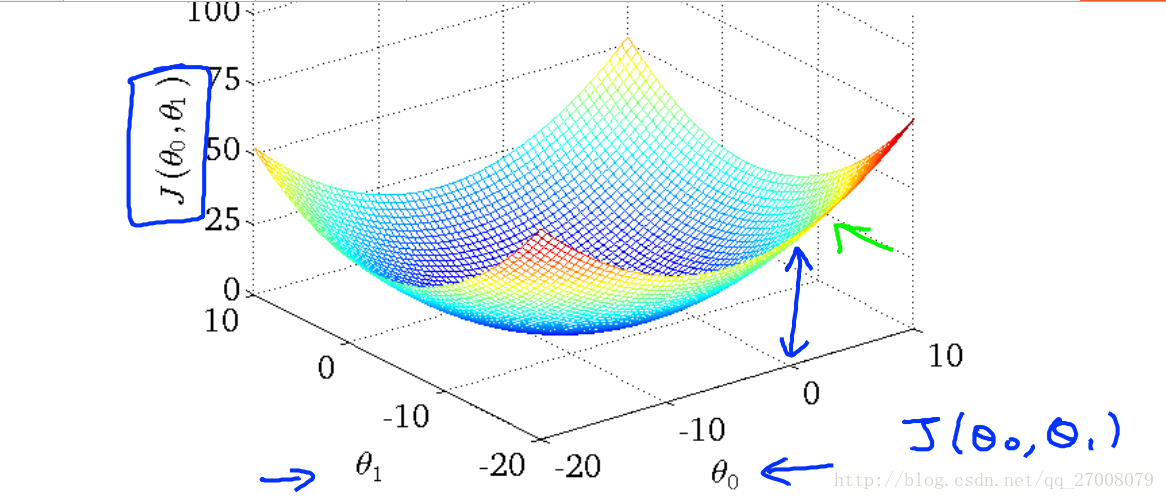
我们看到通过改变斜线的斜率 误差变得很小。也就是选择了上图的中心圈子里。
下面为了方便讲解,我们不使用这样的三维曲面,而是用轮廓图(contour plots)来代替。如下图所示:
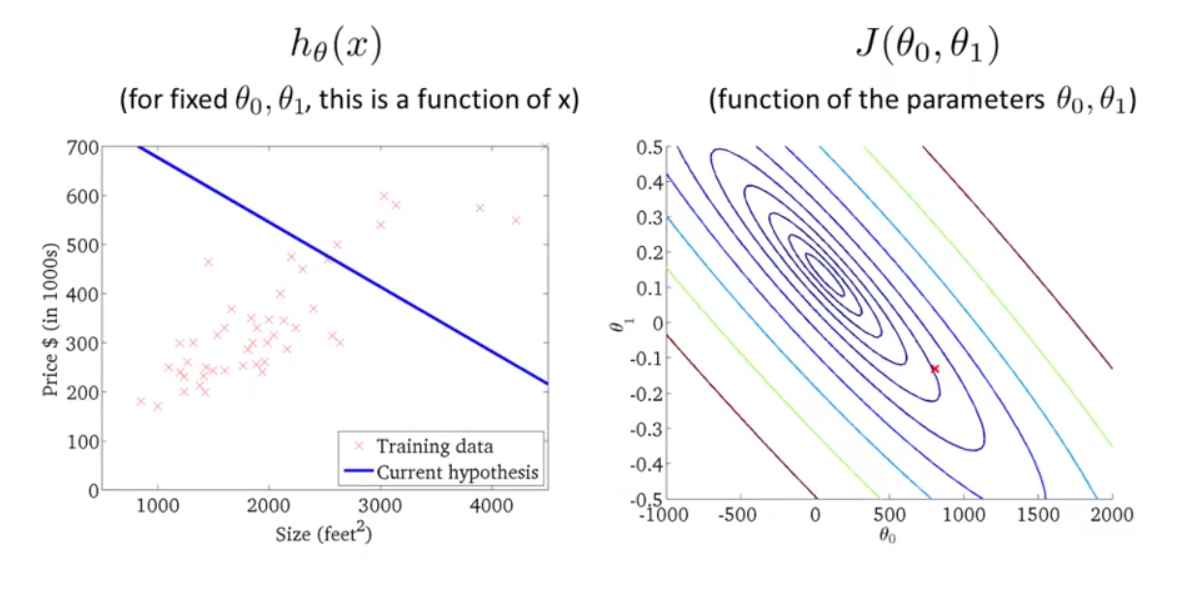
右图J(θ0,θ1)的轮廓图,每一个圆圈代表J(θ0,θ1)值相同的所有点的集合。最小值是中心点。
图中红色的交叉点代表某个(θ0,θ1)数值组的集合,θ0=800,θ1=−0.15,同时,也对应与左边的一条直线。可以看出,它并不能很好地拟合左图的训练数据。而越接近中心的点(θ0,θ1)越能很好地拟合训练数据。
这里只有两个参数,而通常我们会遇到更多参数,更加复杂的代价函数,并不能将其可视化,但是我们要做的工作都是一样的,即找出使代价函数最小的参数值θ0、θ1。
2-4 参数求解(梯度下降法: Gradient Descent)
现在,我们有了假设函数(hypothesis)以及衡量其是否拟合数据的方法——代价函数(cost function),现在我们需要做的就是估计出假设函数(hypothesis)中的参数,即找出使代价函数最小化的参数(θ0,θ1),梯度下降(gradient descent)是一种常用的方法。
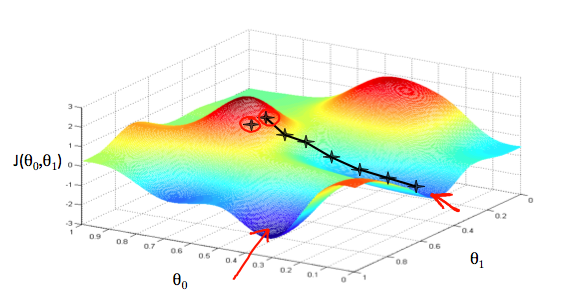
一般情况下,我们会从出发点开始环顾四周,找到最快的方向,每走一步,就环顾四周判断一次,再走下一步,直到达到局部最小值。而这种方法的特点是从不同的出发点出发,我们最终到达的可能是不同的局部最优解,如图。关于这个问题,我们之后再进行讨论。
红色箭头显示图中的最小点。我们这样做的方式是通过我们的代价函数的导数(函数的切线)。切线的斜率是那个点的导数,它会给我们一个走向的方向。我们降低代价函数的方向与最陡的下降方向一致。每一步的大小由参数α决定,称为学习率。
公式如下:
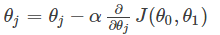
重复计算这个公式,直到函数收敛。
注意更新theta值应同时更新

其中的α称之为步长,在最优化课中我们有好几种方法来确定这个α的值。
比如:我们可以使用一些优化算法来进行学习率的超参数的搜索与学习。如:粒子群算法,蚁群算法,遗传算法等
我们还可以自定义一些规则,使得该参数可以自动适应训练的过程,如:定义随着迭代步数增加而指数衰减的学习率等。
这个α如果过小,则收敛很慢;
如果过大,则可能导致不收敛。
对于J(θ)的偏导数学推导过程如下:
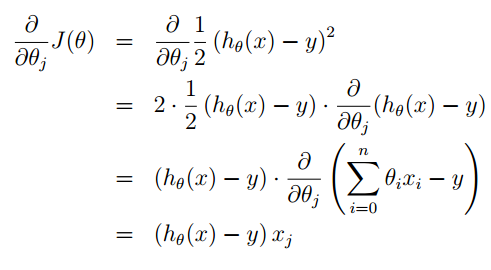
在这里你就看到,我们在构造J(θ)时1/2的出现就是为了与指数的在求导时抵消。
其中x是向量,xi是单个样本。
经过简单的替换之后我们就可以得到θ新的迭代公式:
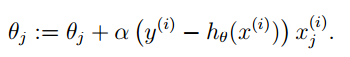
2-5 梯度下降如何实现最小化代价函数
那么为什么梯度下降可以用于最小化代价函数呢?
梯度下降如何实现一步步更新后,J(θ)越来越靠近最小值(山底)呢?
为了方便说明,我们假设θ0=0,则:

1、若θ1在局部最优解的右边
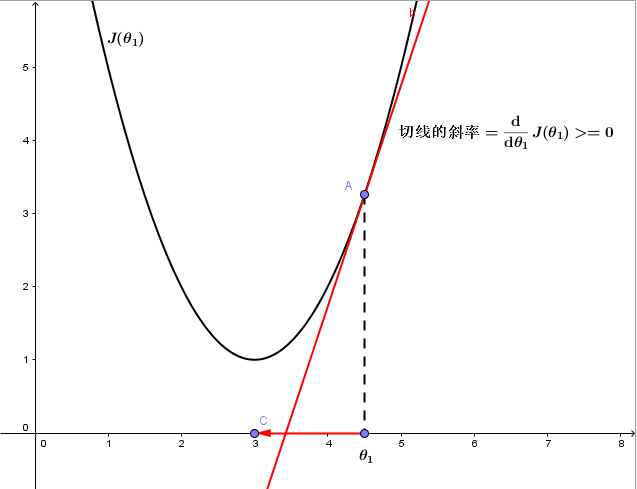
dJ(θ1)/dθ1永远大于等于0,且α永远为正,所以θ1将减小,向坐标轴左侧移动,即向代价函数J(θ1)更小的方向更新。
2、若θ1在局部最优解的左边
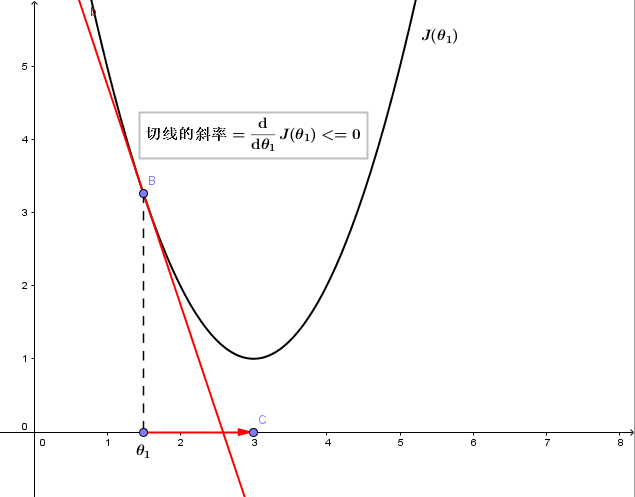
dJ(θ1)/dθ1永远小于等于0,且α永远为正,所以θ1将增大,向坐标轴右侧移动,即向代价函数J(θ1)更小的方向更新。
3、若θ1已经处于局部最优位置
由于该点切线的斜率为0,故θ1将保持不变,此时即使还存在其他θ1的值使代价函数更小,也只能收敛于该局部最小值,而无法收敛于全局最小值。
2-6 学习率(learning rate)
我们再来看学习率α:
1、 如果α太小,则因为每次更新θ1的幅度太小导致梯度下降收敛很慢,如下图:
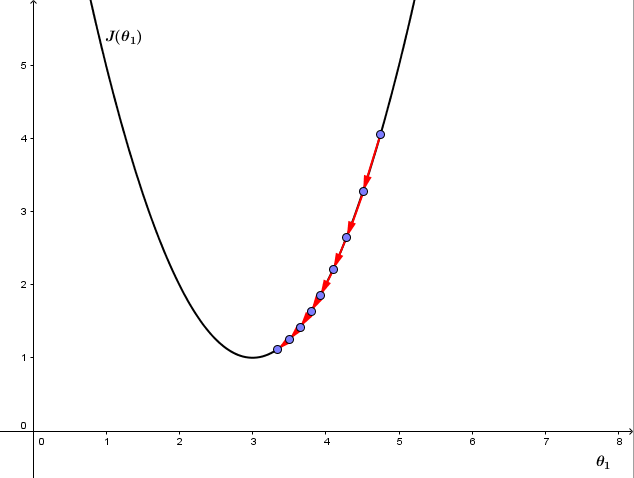
2、如果α太大,则梯度下降可能会跨过最小值不能收敛,甚至离收敛点越来越远,如下图:
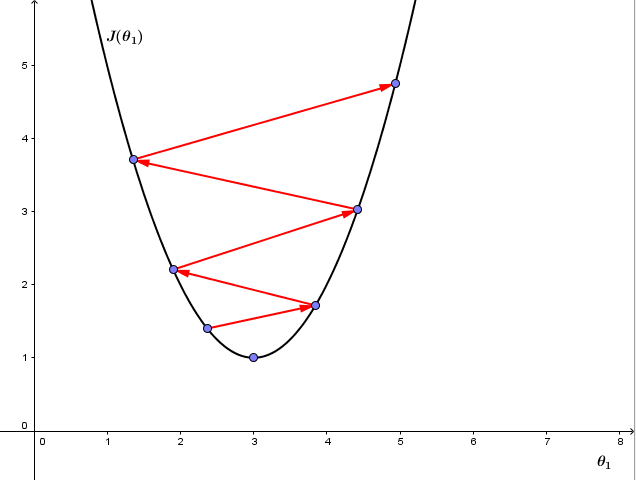
有趣的是,我们并不需要改变α的值,即使α值固定,梯度下降也能收敛到一个局部最小值。原因是代价函数在接近局部最小值的过程中,切线的斜率越来越小,即使α固定,梯度下降的步距也会越来越小,最终也能收敛到局部最小值。
2-7 三种梯度下降方式
1、批量梯度下降(batch gradient descent)
上述方法在每一步都会用到所有的训练数据(∑),所以被称为批量梯度下降(batch gradient descent)。在我们用的这个特殊例子(单变量线性回归)中,J(θ0,θ1)除了全局最优解(global optima)没有局部最优解(local optima)。
将梯度下降用于这种线性回归,总会收敛到全局最优。批量梯度下降由于是一次性的额导入全部的数据,所以学习速度比较慢,而且对于大数据不适合
2、随机梯度下降( stochastic gradient descent)
(1)上面的梯度下降算法每次计算梯度都需要遍历所有的样本点,这是因为梯度是 J(θ) 的导数,而 J(θ) 是需要考虑所有样本的误差和 ,这个方法问题就是,扩展性问题,当样本点很大的时候,基本就没法算了。
(2)所以接下来又提出了随机梯度下降算法(stochastic gradient descent )。随机梯度下降算法,每次迭代只是考虑让该样本点的 J(θ) 趋向最小,而不管其他的样本点,这样算法会很快,但是收敛的过程会比较曲折,整体效果上,大多数时候它只能接近局部最优解,而无法真正达到局部最优解。所以适合用于较大训练集的情况。
3、小批量梯度下降(mini batch gradient descent)
后续会讲到,选择mini batch,可以实现快速学习,也利用了向量化,cost下降处于上两者之间
三 总结
到这里,我们就学习了一个最最简单的机器学习模型求解的全部内容。我们梳理一下,一共有三个层次 的 三个公式。

就这么简单 ,就可以求出一个预测房价的线性回归模型。