参考:https://blog.csdn.net/JNingWei/article/details/80064451(全局池化)
https://blog.csdn.net/williamyi96/article/details/77530995(Global Average Pooling对全连接层的可替代性分析)
https://blog.csdn.net/WuLex/article/details/78577662
全局池化
全局池化是降低维度,从3维降低到1维,为每个特征图输出1个响应操作。
global pooling在滑窗内的具体pooling方法可以是任意的,所以就会被细分为“global avg pooling”、“global max pooling”等。
全连接层的缺点
全连接层有一个非常致命的弱点就是参数量过大,特别是与最后一个卷积层相连的全连接层。一方面增加了Training以及testing的计算量,降低了速度;另外一方面参数量过大容易过拟合。虽然使用了类似dropout等手段去处理,但是毕竟dropout是hyper-parameter, 不够优美也不好实践。
GAP(Global Average Pooling)可以取代全连接层
我们要明确以下,全连接层将卷积层展开成向量之后不还是要针对每个feature map进行分类吗,GAP的思路就是将上述两个过程合二为一,一起做了。如图所示:
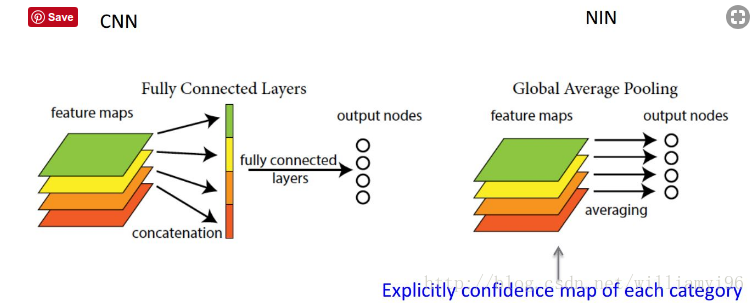
GAP可以实现任意图像大小的输入。但值得注意的是,使用gap可能会造成收敛速度减慢。