之前的numpy可以说是一个针对矩阵运算的库,这个Pandas可以说是一个实现数据处理的库,Pandas底层的许多函数正是基于numpy实现的
一、Pandas数据读取
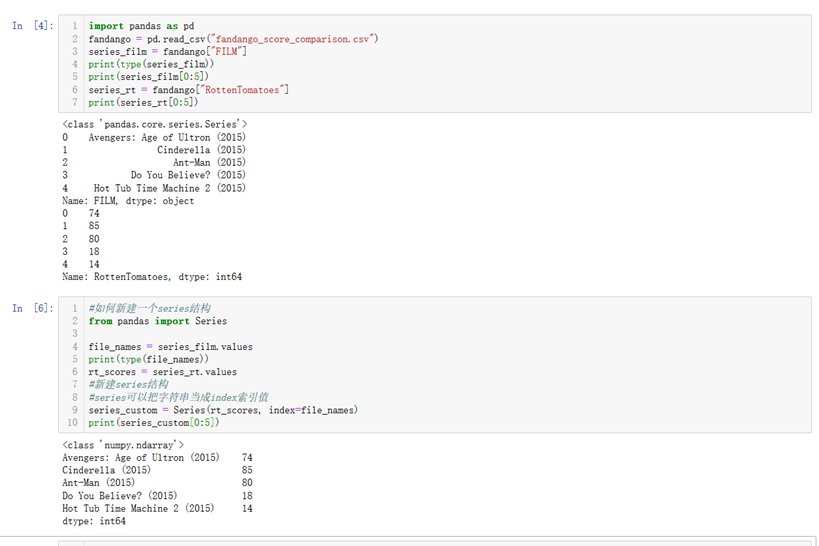
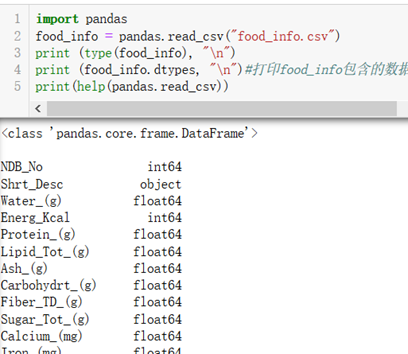
1.pandas.read_csv("文件路径"):读取一个csv文件并把数据储存为一个DataFram结构。如feed_info = pandas.read_csv("food_info.csv")
2.pandas中的核心结构叫DataFram,以下简称df见下图所示
注意在pandas中,字符型值被描述为object类型
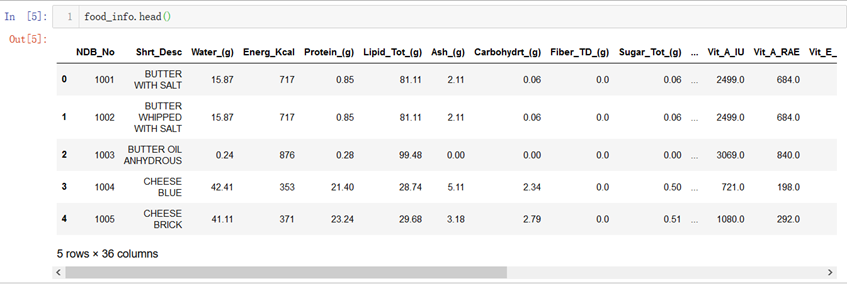
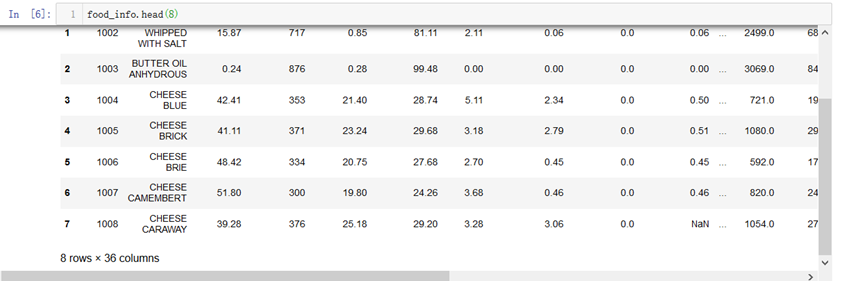
3.df.head():打印出df的数据,如果没有参数,默认打印出前5行数据。也可以把它赋值给一个变量,如a=food_info.head(3),那么a就是一个小的df
df.tail():打印后几行
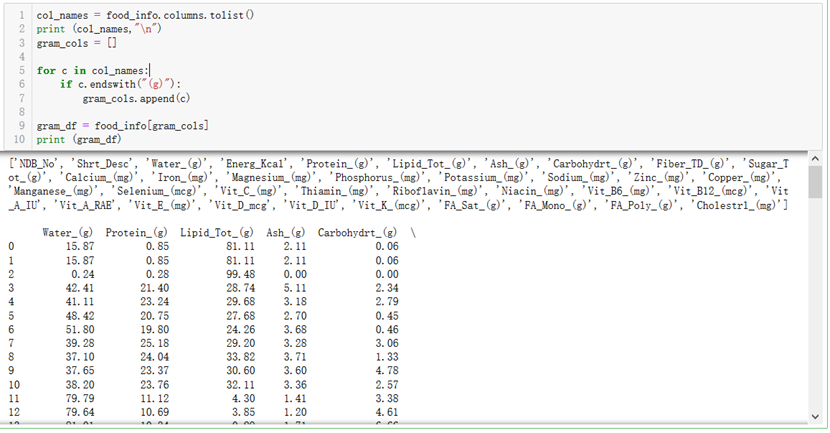
4.df.columns:获取df的列名
5.df.shape:这个就不多说了
二、Pandas索引与计算
6.df.loc[0]:取第一条数据;df.loc[3:4]取第3、4、5、6条数据;
7.df["列名"]:取对应列的数据,取多个列时df[]里接一个列表,列表元素是列名
8.df.columns.tolist():把列名制作成list。下面给出一个小例子。
9.要想对整列进行加减乘除操作,跟numpy一样直接进行,如:a = df["列名"]/1000;如果两列结构相同,可做一样的操作,对应位会实现相应的运算,如:b = df["col1"]*[df["col2"]
10.新建列的操作:df["新列名"]=new_df,相当于给每个样本添加了一个特征
11.求一列的最大值、最小值、均值:df["col_name"].max()、df["col_name"].min()、df["col_name"].mean()
三、Pandas数据预处理实例
12.df.sort_values("col_name", inplace = True):把指定列从小到大排序,inplace=True时,用排序好的列替换原来的列,否则返回一个新列,缺省默认时返回新列。
13.df.sort_values("col_name", ascending = False):从大到小排列
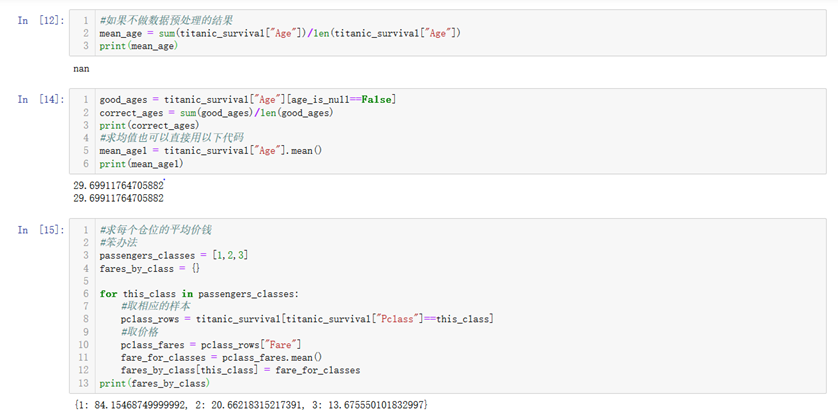
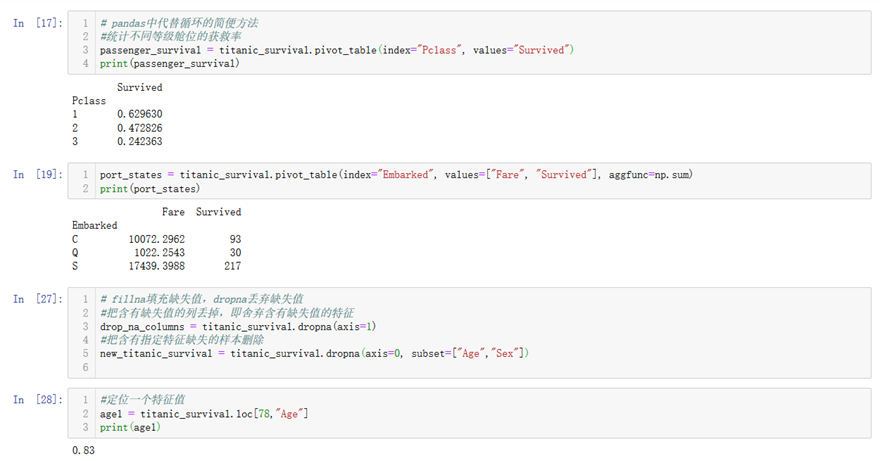
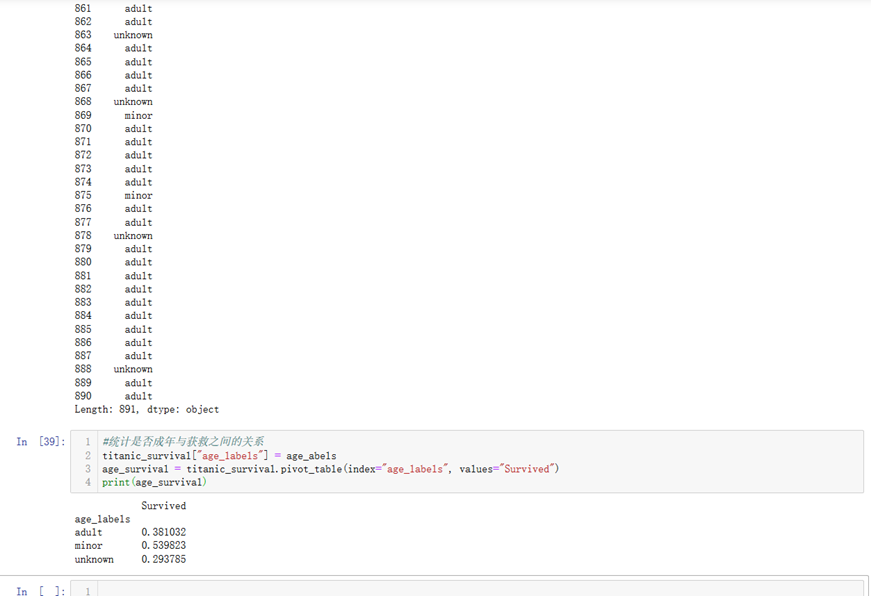
14.df.pivot_table(index="cn1", values="cn2", aggfunc=):pivot_tables是一个统计数据的方法,以index为基准,统计index与value之间的关系,其中values的数据由aggfunc做处理。比如说index为pclass(货舱等级),values为survived(是否获救),aggfunc为np.mean(平均处理),即统计不同货舱的平均获救率。当aggfunc缺省时默认是求平均。
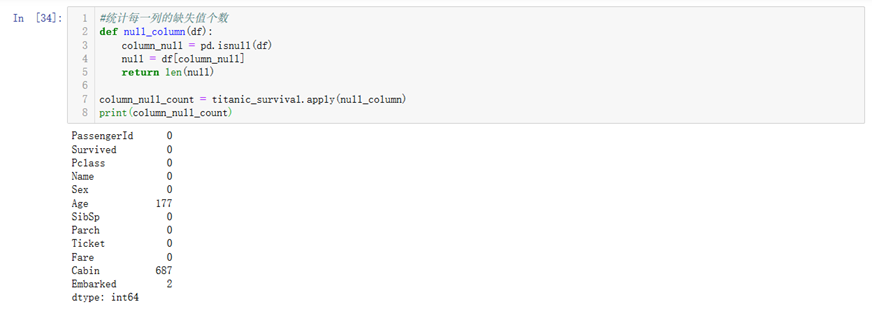
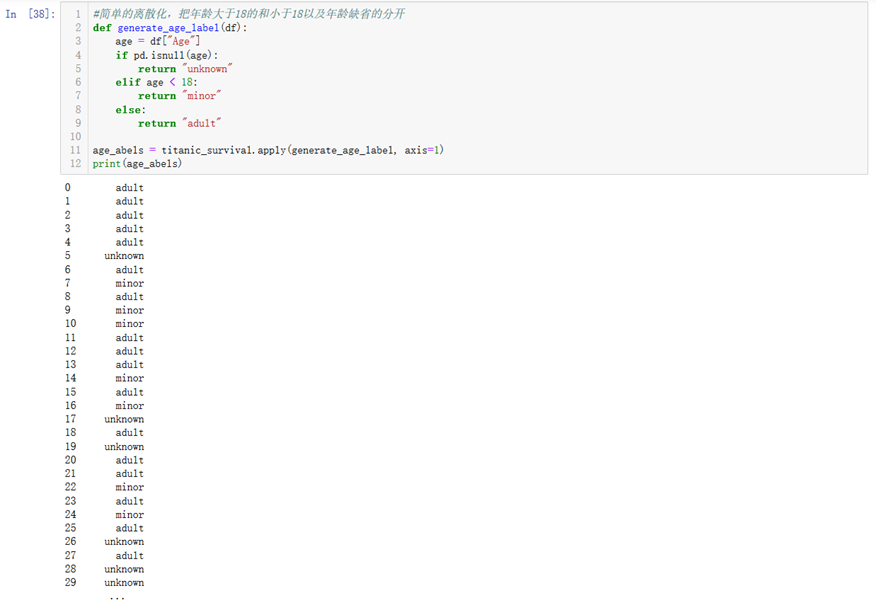
15.一些其他基本函数和pandas中函数的定义见下面的小例子



三、Series结构
16.DataFrame中的一行或者一列被称为Series结构,是Pandas内部定义的结构。Series里数据的结构是ndarray