本教程用于记录solr入门路上的一些爬坑的方法,毕竟好记性不如烂笔头。
问题一:什么是Solr?
Solr是基于lucene的企业级全文检索、搜索引擎框架。
运行流程:对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定参数的POST,生成索引;也可以通过HttpGet操作提出查找请求,并得到返回结果。这部分后面将会进行详细学习。
Lucene:是一个开放源代码的全文检索引擎工具包。
问题二:solr能做什么?
全文检索。也就是网站应用中的搜索功能
例如:我们在京东搜索java


在结果集中就能看到包含关键字java的商品,并且java被高亮显示。
再比如百度上搜索一段文字:

同样会根据你输入的关键字匹配N多结果集,并根据一定的顺序排列起来
问题三:solr是怎么做到的?
简单理解:查新华字典,不会查的人,一页一页的翻。而一般人都是根据汉字的拼音索引或者偏旁笔画索引经行查询。solr中首先将需要建立检索的数据导入到solr服务器中,并在solr服务器中建立基于表字段的field,也就是域。这一步相当于把数据库的数据缓存到redis中。
当输入字符进行检索时,字符经过分词器,被拆分成不同的词组,solr将分别检索这些词组在服务器字典中的位置编号。比如搜索:Lucene solr hadoop,如图:

搜先将Lucene solr hadoop分词成 Lucene、solr、hadoop最后取交集后最匹配的就是位置编号为3的数据。而真实的分词往往复杂的多,在英文中需要将部分单词的过去式、复数形式、动词形式、名词形式等转换成一个标准形式,同时将定冠词a、an、the等去掉等等。而中文分词时候,某些特定的词组不需要拆分,比如网络词:高富帅、屌丝、骚猪等作为一个词组去进行检索,像:我、的、是等直接过滤掉。
问题四:怎么使用?
1.首先下载对应版本的solr:http://archive.apache.org/dist/lucene/solr/
早期的solr版本[solr4.x]下载的文件解压后会有一个war包,可以将此war包放在tomcat里运行。cas6.x和cas7.x取消了war包,但提供了丰富的脚本文件。下载完毕解压到电脑上:
Tips:用到的目录只有server,bin目录下是启动项目的脚本,api说明在docs中的index.html,example下有一些demo,但是不够具体。

2.启动solr
在bin目录下启动cmd,输入solr start -p 8088:

发现会出现一个文件找不到的异常,但是项目已经启动成功了:

作为强迫症患者,虽然不影响solr的运行,但每次启动出现这样的报错还是不能忍受,并且这个是log4j的文件找不到,会直接导致看不到运行日志,对于后面学习十分友好。
异常解决方法:
打开bin/solr.cmd,将file:全部替换成file:///

感谢这位老哥提供的方法:https://blog.csdn.net/yqwang75457/article/details/82805008
替换完毕后,在刚才启动的cmd,输入 solr stop -p 8088或者solr stop -all,关闭刚才启动的solr。
然后重新打开一个cmd,输入:solr start -p 8088,注意加-p 端口号代表以指定端口启动,不加-p参数代表以默认的8983端口启动,stop的时候则代表停止指定端口号的solr。
重启启动后:

这次,不加-p参数则就代表了以默认的端口号8983启动,并且启动异常也没有出现了。
进入solr管理主页:http://127.0.0.1:8983/solr/#/

发现,提示没有core,让我们去创建,在solr4.x的时候,叫做collection,现在这个版本叫core。core/collection这个东西根据我的理解:相当于工作空间、orcl的用户空间。在一个指定的core/collection中去配置分词器配置、数据库配置、filed的配置等等。
点击红框后:

可以给core的各个文件一个自定义的名字,一般name和instanceDir保持一致,也就是core的名字和存放core的文件夹名字。
dataDir是保存导入到solr中的数据,用户将数据库的数据导入到solr后,solr在此目录下进行保存/建立词典等。
config很明显就是core的核心配置文件。
schema是用来存放索引的配置文件。比如:有一个商品表(goods,包含字段:name【商品名字】、desc【商品描述】),其中name和desc需要建立索引,因为当用户在应用网页中可能会搜索商品名字,也可能是相关商品的描述。这个时候solr就会根据搜索的内容分别在name和desc的索引里高效的筛选出商品的结果。
当然也可以在cmd窗口中通过输入:solr create -c core名字 进行创建:

此时,进入server/solr/就能看到生成的core文件夹了:

同时刷新 http://127.0.0.1:8983/solr/#/
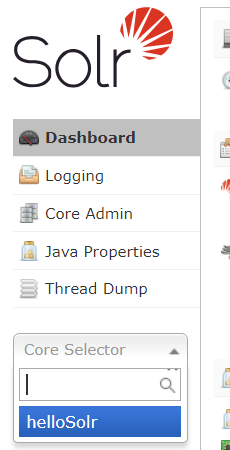
core中出现了刚才创建的helloSolr:
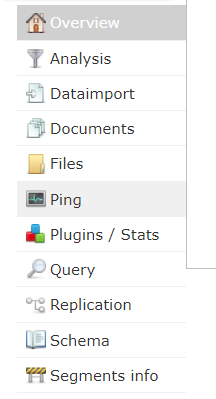
- Analysis是分词测试
- Dataimport是数据导入
- Query可以模拟查询
- Schema中可以看到创建的索引
中文分词
点击Analysis,输入任意内容尝试分词:

在没有添加Ik分词器时候,会把搜索内容打断成一个一个汉字书检索,这就十分的低效。因此需要添加中文分词器
1.下载ik分词器
推荐一个老哥贡献的分词器:http://www.cnblogs.com/liang1101/articles/6395016.html
下载地址:https://github.com/Siwash/rpf-solr-study
github也有很多可以选择
下载后将jar包放到solr-7.4.0\server\solr-webapp\webapp\WEB-INF\lib下,并在WEB-INF下创建classes文件用户存放ik分词器的配置文件:

推荐直接下载,也可以自行创建无BOM格式的UTF-8的文件,IKAnalyzer.cfg.xml内容:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<entry key="ext_dict">/ext.dic;</entry>
<entry key="ext_stopwords">/stopwords.dic</entry>
</properties>
其中ext.dic是不需要分词的词组,stopwords.dic是要过滤出去的词组,格式如下:
高富帅
黑马程序员
电科
死肥宅
一个
我们
时间
中国
最后打开创建的core下的managed-schma.xml(solr-7.4.0\server\solr\helloSolr\conf)
在结尾处加入如下代码,让IK分词器生效:
<!--配置中文分词器-->
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
<!--配置几个域,这几个就支持中文分词了,当然自己根据需求进行创建即可-->
<field name="title_ik" type="text_ik" indexed="true" stored="true"/>
<field name="content_ik" type="text_ik" indexed="true" stored="false" multiValued="true"/>
最后重新启动测试运行效果:

可以发现死肥宅作为一个词组没有被拆分下来。
Tips若添加分词后出现如下问题,更换ik-Analysis的版本,我这个版本是兼容solr7.x的
看异常信息应该是solr7修改了某些方法名或者取消了某些方法导致分词器出现bug
2018-12-03 08:12:13.738 ERROR (qtp817348612-17) [ x:helloSolr] o.a.s.s.HttpSolrCall null:java.lang.RuntimeException: java.lang.AbstractMethodError
at org.apache.solr.servlet.HttpSolrCall.sendError(HttpSolrCall.java:662)
at org.apache.solr.servlet.HttpSolrCall.call(HttpSolrCall.java:530)
at org.apache.solr.servlet.SolrDispatchFilter.doFilter(SolrDispatchFilter.java:377)