
显示时,有三个参数,前两个必填,第几页,一页多少个size,第三个参数默认可以不填。
但是发现这个方法已经过时了,通过查看它的源码发现,新方法为静态方法PageRequest of(page,size)
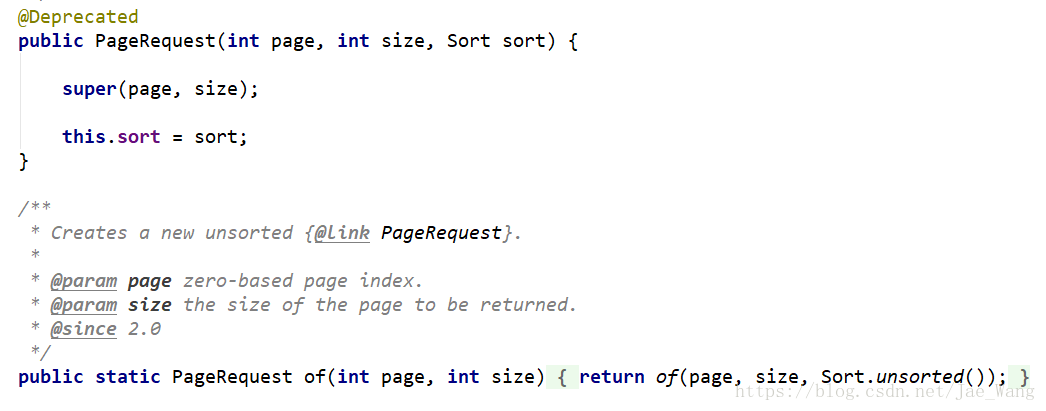
分页是从第0也开始的
Spring项目使用JPA进行数据库操作可以极大的简化开发,下面我将用一个完整的Demo为大家展示分页查询并显示在前台页面
首先来说一下分页和排序所用到的Page、Pageable接口和Sort类都是什么
JpaRepository提供了两个和分页和排序有关的查询
List findAll(Sort sort) 返回所有实体,按照指定顺序排序返回
List findAll(Pageable pageable) 返回实体列表,实体的offest和limit通过pageable来指定
Sort对象用来指示排序,最简单的Sort对象构造可以传入一个属性名列表(不是数据库列名,是属性名),默认采用升序排序。例:
Sort sort = new Sort("id");
//或 Sort sort = new Sort(Direction.ASC,"id");
return userDao.findAll(sort);
程序将查询所有user并按照id进行生序排序。Sort还包括其他一些构造方法,在这里就不一一赘述。
Pageable接口用于构造翻页查询,PageRequest是其实现类,可以通过提供的工厂方法创建PageRequest:
public static PageRequest of(int page, int size)
也可以在PageRequest中加入排序:
public static PageRequest of(int page, int size, Sort sort)
方法中的参数,page总是从0开始,表示查询页,size指每页的期望行数。
Page接口可以获得当前页面的记录、总页数、总记录数、是否有上一页或下一页等。Spring Data翻页查询总是返回Page对象,Page对象提供了以下常用的方法:
int getTotalPages() 总的页数
long getTotalElements() 返回总数
List getContent() 返回此次查询的结果集
代码实现:
1.建立SpringBoot工程,在pom.xml中添加以下依赖
<!--SpringMVC依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--Spring JPA依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- 连接mysql数据库驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
2.创建实体类
package org.gzc.entity;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
@Entity
public class Marker {
@Id
@GeneratedValue
private int id;
private double lng;
private double lat;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public double getLng() {
return lng;
}
public void setLng(double lng) {
this.lng = lng;
}
public double getLat() {
return lat;
}
public void setLat(double lat) {
this.lat = lat;
}
@Override
public String toString() {
return "Marker [id=" + id + ", lng=" + lng + ", lat=" + lat + "]";
}
}
3.编写dao层接口
package org.gzc.dao;
import org.gzc.entity.Marker;
import org.springframework.data.jpa.repository.JpaRepository;
public interface MarkerDao extends JpaRepository<Marker, Integer>{
}
4.编写service层接口
package org.gzc.service;
import java.util.List;
import org.gzc.entity.Marker;
import org.springframework.data.domain.Pageable;
public interface MarkerService {
void saveMarker(Marker marker);
Page<Marker> findMarker(Pageable pageable);
}
5.编写service层实现类
package org.gzc.serviceimpl;
import java.util.List;
import org.gzc.dao.MarkerDao;
import org.gzc.entity.Marker;
import org.gzc.service.MarkerService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Pageable;
import org.springframework.stereotype.Service;
@Service
public class MarkerServiceImpl implements MarkerService{
@Autowired
private MarkerDao markerDao;
@Override
public void saveMarker(Marker marker) {
markerDao.save(marker);
}
@Override
public Page<Marker> findMarker(Pageable pageable) {
return markerDao.findAll(pageable);
}
}
6.编写controller
package org.gzc.controller;
import org.gzc.entity.Marker;
import org.gzc.service.MarkerService;
import org.gzc.util.Result;
import org.gzc.util.ResultUtil;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class MapHandlerController {
@Autowired
private MarkerService markerService;
@SuppressWarnings("rawtypes")
@PostMapping("/saveMarker")
public Result saveMarkerController(@RequestBody Marker marker){
System.out.println(marker);
if (marker!=null) {
markerService.saveMarker(marker);
return ResultUtil.success();
}
return ResultUtil.error(1, "保存失败", "/saveMarker");
}
@SuppressWarnings("rawtypes")
@GetMapping("/showMarkerCount")
public Result returnMarkerCount(){
long count = markerService.markerCount();
System.out.println("count------------------->"+count);
return ResultUtil.success(count, "/showMarkerCount");
}
@SuppressWarnings("rawtypes")
@GetMapping("/showMarkerByPage/{page}")
public Result showMarkerController(@PathVariable("page") int page){
PageRequest pageRequest = PageRequest.of(page, 5);
Page<Marker> markerPage = markerService.findMarker(pageRequest);
for (int i = 0; i < markerPage.getContent().size(); i++) {
System.out.println(markerPage.getContent().get(i));
System.out.println(markerPage.getTotalElements());
}
if (markerPage.getContent()!=null) {
return ResultUtil.success(markerPage.getContent(), "/showMarker");
}else {
return ResultUtil.error(1, "查询失败", "/showMarker");
}
}
}
后台先给前台传过去数据总量,前台计算完显示第几页,再将第几页传送给后台,后台进行查询并返回数据
---------------------
作者:来日可期
来源:CSDN
原文:https://blog.csdn.net/qq_40715775/article/details/83153808
版权声明:本文为博主原创文章,转载请附上博文链接!
springboot jpa 多条件查询(多表)
https://www.cnblogs.com/arrrrrya/p/7865090.html
2)在StudentService中findByDynamicCases()方法中具体的实现。这里先解释这几个对象是什么意思。
Specification:规则、标准。该对象主要是告诉JPA查询的过滤规则是什么。
Predicate:谓语、断言。该对象主要是定义具体的判断条件。如predicate1 = cb.like(sex,"男");即判断条件为性别为男性。
Root: Root<Student> root就是定义引用root指向Student的包装对象。Path<String> sex = root.get("sex");即通过root来获取Student的具体属性。
CriteriaQuery:查询条件的组装。query.where(predicate1,predicate2,predicate3);表示按条件predicate1 and predicate2 and predicate3进行组合条件查询。
CriteriaBuilder:用来构建CritiaQuery的构建器对象;如:predicate2 = cb.between(age,25,35);表示判断条件为Student.age between 25 and 25;
我这里的实现是为了演示基于JPA动态查询(性别为男,年龄在25-25之间,吴国人)我们具体该如何实现。很明显的看到这段代码把查询条件写死了,不易于扩展。通常情况下是把Specification定义为工具类,每一个判断条件Predicate定义为Spefication的一个方法,查询时再将不同的Predicate进行组装。有兴趣的可以自己实现。
---------------------
作者:_artoria_
来源:CSDN
原文:https://blog.csdn.net/UtopiaOfArtoria/article/details/78087494
版权声明:本文为博主原创文章,转载请附上博文链接!
@Query(value = "select * from xxx where if(?1 !='',x1=?1,1=1) and if(?2 !='',x2=?2,1=1)" +
"and if(?3 !='',x3=?3,1=1) ",nativeQuery = true)
List<XXX> find(String X1,String X2,String X3);
工作的时候需求有搜索功能,有三个参数,但是网上找了很多关于jpa多条件查询的代码要么在调dao的时候用了大量if判断,那么需要写很多查询方法,要么说的不知所云,我结合jpa和mysql原语句研究了半天才弄出了这个方法。
xxx是数据库表名,x1、x2、x3为查询的字段名。
下面的大写的XXX是实体类的名,X1X2X3为查询的参数。
if(?1 !='',x1=?1,1=1) 代表传入的参数X1如果不为""(Spring类型空是""而不是null)将参数传入x1,如果为空时显示1=1 代表参数为真,对查询结果不产生作用。
---------------------
作者:小宁萌的多肉
来源:CSDN
原文:https://blog.csdn.net/qq_36802726/article/details/81208853
版权声明:本文为博主原创文章,转载请附上博文链接!
这里,spring data jpa为我们提供了JpaSpecificationExecutor接口,只要简单实现toPredicate方法就可以实现复杂的查询
@Repository
public interface MonitorRepository extends JpaRepository<Monitor, Long>, JpaSpecificationExecutor {
}
ctrl类
@GetMapping("/api/listPage")
@ResponseBody
public Map<String, Object> listPage(@RequestParam(value = "pageNumber", defaultValue = "1") Integer pageNumber,
@RequestParam(value = "pageSize", defaultValue = "100") Integer pageSize,
@RequestParam("searchName") String searchName, @RequestParam("searchUrl") String searchUrl) {
//Pageable默认从0开始
pageNumber = pageNumber <= 0 ? 0 : pageNumber - 1;
Pageable pageable = new PageRequest(pageNumber, pageSize);
// Page<Monitor> monitorList = monitorRepository.findMonitorByNameOrUrl(pageable, searchName, urlPath);
Specification specification = new Specification() {
@Override
public Predicate toPredicate(Root root, CriteriaQuery query, CriteriaBuilder cb) {
List<Predicate> predicates = new ArrayList<>();
if (StringUtils.isNotBlank(searchName)) {
predicates.add(cb.like(root.get("name"), "%" + searchName + "%"));
}
if (StringUtils.isNotBlank(searchUrl)) {
predicates.add(cb.like(root.get("url"), "%" + searchUrl + "%"));
}
return cb.and(predicates.toArray(new Predicate[predicates.size()]));
}
};
Page<Monitor> monitorList = monitorRepository.findAll(specification, pageable);
Map<String, Object> result = new HashMap<>();
result.put("total", monitorList.getTotalElements());
result.put("rows", monitorList.getContent());
return result;
}
bean类
import com.fasterxml.jackson.annotation.JsonFormat;
import org.hibernate.annotations.CreationTimestamp;
import javax.persistence.*;
import java.io.Serializable;
import java.util.Date;
@Entity
@Table(name = "monitor")
public class Monitor implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "m_id", length = 11)
private Long id;
@Column(name = "m_name", length = 64)
private String name;
@Column(name = "m_group", length = 64)
private String group;
@Column(name = "m_url", length = 200)
private String url;
@Temporal(TemporalType.TIMESTAMP)
@Column(name = "create_time")
@JsonFormat(pattern = "yyyy-MM-dd HH:mm:ss", timezone = "GMT+08:00")
@CreationTimestamp
private Date createTime;
}
---------------------
作者:elvesfish
来源:CSDN
原文:https://blog.csdn.net/l2000h_ing/article/details/78830769
版权声明:本文为博主原创文章,转载请附上博文链接!
@Query注解的用法(Spring Data JPA)
参考文章:http://www.tuicool.com/articles/jQJBNv
1. 一个使用@Query注解的简单例子
@Query(value = "select name,author,price from Book b where b.price>?1 and b.price<?2") List<Book> findByPriceRange(long price1, long price2);
2. Like表达式
@Query(value = "select name,author,price from Book b where b.name like %:name%")
List<Book> findByNameMatch(@Param("name") String name);
3. 使用Native SQL Query
所谓本地查询,就是使用原生的sql语句(根据数据库的不同,在sql的语法或结构方面可能有所区别)进行查询数据库的操作。
@Query(value = "select * from book b where b.name=?1", nativeQuery = true) List<Book> findByName(String name);
4. 使用@Param注解注入参数
@Query(value = "select name,author,price from Book b where b.name = :name AND b.author=:author AND b.price=:price")
List<Book> findByNamedParam(@Param("name") String name, @Param("author") String author,
@Param("price") long price);
5. SPEL表达式(使用时请参考最后的补充说明)
'#{#entityName}'值为'Book'对象对应的数据表名称(book)。
public interface BookQueryRepositoryExample extends Repository<Book, Long>{
@Query(value = "select * from #{#entityName} b where b.name=?1", nativeQuery = true)
List<Book> findByName(String name);
}
6. 一个较完整的例子

public interface BookQueryRepositoryExample extends Repository<Book, Long> {
@Query(value = "select * from Book b where b.name=?1", nativeQuery = true)
List<Book> findByName(String name);// 此方法sql将会报错(java.lang.IllegalArgumentException),看出原因了吗,若没看出来,请看下一个例子
@Query(value = "select name,author,price from Book b where b.price>?1 and b.price<?2")
List<Book> findByPriceRange(long price1, long price2);
@Query(value = "select name,author,price from Book b where b.name like %:name%")
List<Book> findByNameMatch(@Param("name") String name);
@Query(value = "select name,author,price from Book b where b.name = :name AND b.author=:author AND b.price=:price")
List<Book> findByNamedParam(@Param("name") String name, @Param("author") String author,
@Param("price") long price);
}
7. 解释例6中错误的原因:
因为指定了nativeQuery = true,即使用原生的sql语句查询。使用java对象'Book'作为表名来查自然是不对的。只需将Book替换为表名book。
@Query(value = "select * from book b where b.name=?1", nativeQuery = true) List<Book> findByName(String name);
补充说明(2017-01-12):
有同学提出来了,例子5中用'#{#entityName}'为啥取不到值啊?
先来说一说'#{#entityName}'到底是个啥。从字面来看,'#{#entityName}'不就是实体类的名称么,对,他就是。
实体类Book,使用@Entity注解后,spring会将实体类Book纳入管理。默认'#{#entityName}'的值就是'Book'。
但是如果使用了@Entity(name = "book")来注解实体类Book,此时'#{#entityName}'的值就变成了'book'。
到此,事情就明了了,只需要在用@Entity来注解实体类时指定name为此实体类对应的表名。在原生sql语句中,就可以把'#{#entityName}'来作为数据表名使用。
https://www.cnblogs.com/zj0208/p/6008627.html
- 14.1. Case Sensitivity
- 14.2. The from clause
- 14.3. Associations and joins
- 14.4. Forms of join syntax
- 14.5. Referring to identifier property
- 14.6. The select clause
- 14.7. Aggregate functions
- 14.8. Polymorphic queries
- 14.9. The where clause
- 14.10. Expressions
- 14.11. The order by clause
- 14.12. The group by clause
- 14.13. Subqueries
- 14.14. HQL examples
- 14.15. Bulk update and delete
- 14.16. Tips & Tricks
- 14.17. Components
- 14.18. Row value constructor syntax
Hibernate uses a powerful query language (HQL) that is similar in appearance to SQL. Compared with SQL, however, HQL is fully object-oriented and understands notions like inheritance, polymorphism and association.
http://docs.jboss.org/hibernate/core/3.3/reference/en/html/queryhql.html
JPA 组合查询之AND和OR组合查询
public Page<FinanceBorrow> getUserBorrowByPage(Pageable pageable,JSONObject whereObj,JSONObject userPermission){ Page<FinanceBorrow> results=financeBorrowRepository.findAll(new Specification<FinanceBorrow>() { @Override public Predicate toPredicate(Root<FinanceBorrow> root,CriteriaQuery<?>query,CriteriaBuilder cb){ // 查询条件 List<Predicate> listWhere=new ArrayList<>(); if(whereObj!=null) for (Map.Entry<String, Object> entry : whereObj.entrySet()) { try { listWhere.add(cb.like(root.get(entry.getKey()).as(String.class), "%"+entry.getValue()+"%")); } catch (IllegalArgumentException e) { log.error("--参数["+entry.getKey()+"]不存在"); continue; } } Predicate[] predicatesWhereArr=new Predicate[listWhere.size()]; Predicate predicatesWhere= cb.and(listWhere.toArray(predicatesWhereArr)); //用户限制条件 List<Predicate> listPermission=new ArrayList<>(); if(userPermission!=null) for (Map.Entry<String, Object> entry : userPermission.entrySet()) { try { listPermission.add(cb.equal(root.get(entry.getKey()).as(String.class), entry.getValue())); log.info(" -- "+entry.getValue()); } catch (IllegalArgumentException e) { log.error("--参数["+entry.getKey()+"]不存在"); continue; } } Predicate[] predicatesPermissionArr=new Predicate[listPermission.size()]; Predicate predicatesPermission= cb.or(listPermission.toArray(predicatesPermissionArr)); return query.where(predicatesWhere,predicatesPermission).getRestriction(); } },pageable); return results; }
https://blog.csdn.net/langyan122/article/details/80608383
ExampleMatcher用于创建一个查询对象,上面的代码就创建了一个查询对象。withIgnorePaths方法用来排除某个属性的查询。withIncludeNullValues方法让空值也参与查询,就是我们设置了对象的姓,而名为空值.
1、概念定义:
上面例子中,是这样创建“实例”的:Example<Customer> ex = Example.of(customer, matcher);我们看到,Example对象,由customer和matcher共同创建。
A、实体对象:在持久化框架中与Table对应的域对象,一个对象代表数据库表中的一条记录,如上例中Customer对象。在构建查询条件时,一个实体对象代表的是查询条件中的“数值”部分。如:要查询名字是“Dave”的客户,实体对象只能存储条件值“Dave”。
B、匹配器:ExampleMatcher对象,它是匹配“实体对象”的,表示了如何使用“实体对象”中的“值”进行查询,它代表的是“查询方式”,解释了如何去查的问题。如:要查询FirstName是“Dave”的客户,即名以“Dave"开头的客户,该对象就表示了“以什么开头的”这个查询方式,如上例中:withMatcher("name", GenericPropertyMatchers.startsWith())
C、实例:即Example对象,代表的是完整的查询条件。由实体对象(查询条件值)和匹配器(查询方式)共同创建。
再来理解“实例查询”,顾名思义,就是通过一个例子来查询。要查询的是Customer对象,查询条件也是一个Customer对象,通过一个现有的客户对象作为例子,查询和这个例子相匹配的对象。
2、特点及约束(局限性):
A、支持动态查询。即支持查询条件个数不固定的情况,如:客户列表中有多个过滤条件,用户使用时在“地址”查询框中输入了值,就需要按地址进行过滤,如果没有输入值,就忽略这个过滤条件。对应的实现是,在构建查询条件Customer对象时,将address属性值置具体的条件值或置为null。
B、不支持过滤条件分组。即不支持过滤条件用 or(或) 来连接,所有的过滤查件,都是简单一层的用 and(并且) 连接。
C、仅支持字符串的开始/包含/结束/正则表达式匹配 和 其他属性类型的精确匹配。查询时,对一个要进行匹配的属性(如:姓名 name),只能传入一个过滤条件值,如以Customer为例,要查询姓“刘”的客户,“刘”这个条件值就存储在表示条件对象的Customer对象的name属性中,针对于“姓名”的过滤也只有这么一个存储过滤值的位置,没办法同时传入两个过滤值。正是由于这个限制,有些查询是没办法支持的,例如要查询某个时间段内添加的客户,对应的属性是 addTime,需要传入“开始时间”和“结束时间”两个条件值,而这种查询方式没有存两个值的位置,所以就没办法完成这样的查询。
3、ExampleMatcher的使用 :
一些问题:
(1)Null值的处理。当某个条件值为Null,是应当忽略这个过滤条件呢,还是应当去匹配数据库表中该字段值是Null的记录?
(2)基本类型的处理。如客户Customer对象中的年龄age是int型的,当页面不传入条件值时,它默认是0,是有值的,那是否参与查询呢?
(3)忽略某些属性值。一个实体对象,有许多个属性,是否每个属性都参与过滤?是否可以忽略某些属性?
(4)不同的过滤方式。同样是作为String值,可能“姓名”希望精确匹配,“地址”希望模糊匹配,如何做到?
(5)大小写匹配。字符串匹配时,有时可能希望忽略大小写,有时则不忽略,如何做到?
一些方法:
1、关于基本数据类型。
实体对象中,避免使用基本数据类型,采用包装器类型。如果已经采用了基本类型,
而这个属性查询时不需要进行过滤,则把它添加到忽略列表(ignoredPaths)中。
2、Null值处理方式。
默认值是 IGNORE(忽略),即当条件值为null时,则忽略此过滤条件,一般业务也是采用这种方式就可满足。当需要查询数据库表中属性为null的记录时,可将值设为INCLUDE,这时,对于不需要参与查询的属性,都必须添加到忽略列表(ignoredPaths)中,否则会出现查不到数据的情况。
3、默认配置、特殊配置。
默认创建匹配器时,字符串采用的是精确匹配、不忽略大小写,可以通过操作方法改变这种默认匹配,以满足大多数查询条件的需要,如将“字符串匹配方式”改为CONTAINING(包含,模糊匹配),这是比较常用的情况。对于个别属性需要特定的查询方式,可以通过配置“属性特定查询方式”来满足要求。
4、非字符串属性
如约束中所谈,非字符串属性均采用精确匹配,即等于。
5、忽略大小写的问题。
忽略大小的生效与否,是依赖于数据库的。例如 MySql 数据库中,默认创建表结构时,字段是已经忽略大小写的,所以这个配置与否,都是忽略的。如果业务需要严格区分大小写,可以改变数据库表结构属性来实现,具体可百度。
一些例子:
---------------------
作者:缄默的果壳
来源:CSDN
原文:https://blog.csdn.net/qq_30054997/article/details/79420141
版权声明:本文为博主原创文章,转载请附上博文链接!
https://github.com/spring-projects/spring-data-book/tree/master/jpa
5.6. Query by Example
5.6.1. Introduction
This chapter provides an introduction to Query by Example and explains how to use it.
Query by Example (QBE) is a user-friendly querying technique with a simple interface. It allows dynamic query creation and does not require you to write queries that contain field names. In fact, Query by Example does not require you to write queries by using store-specific query languages at all.
5.6.2. Usage
The Query by Example API consists of three parts:
-
Probe: The actual example of a domain object with populated fields.
-
ExampleMatcher: TheExampleMatchercarries details on how to match particular fields. It can be reused across multiple Examples. -
Example: AnExampleconsists of the probe and theExampleMatcher. It is used to create the query.
Query by Example is well suited for several use cases:
-
Querying your data store with a set of static or dynamic constraints.
-
Frequent refactoring of the domain objects without worrying about breaking existing queries.
-
Working independently from the underlying data store API.
Query by Example also has several limitations:
-
No support for nested or grouped property constraints, such as
firstname = ?0 or (firstname = ?1 and lastname = ?2). -
Only supports starts/contains/ends/regex matching for strings and exact matching for other property types.
Before getting started with Query by Example, you need to have a domain object. To get started, create an interface for your repository, as shown in the following example:
public class Person { @Id private String id; private String firstname; private String lastname; private Address address; // … getters and setters omitted }The preceding example shows a simple domain object. You can use it to create an Example. By default, fields having nullvalues are ignored, and strings are matched by using the store specific defaults. Examples can be built by either using the offactory method or by using ExampleMatcher. Example is immutable. The following listing shows a simple Example:
Person person = new Person(); person.setFirstname("Dave"); Example<Person> example = Example.of(person);| Create a new instance of the domain object. | |
| Set the properties to query. | |
Create the Example. |
Examples are ideally be executed with repositories. To do so, let your repository interface extend QueryByExampleExecutor<T>. The following listing shows an excerpt from the QueryByExampleExecutor interface:
QueryByExampleExecutor
public interface QueryByExampleExecutor<T> { <S extends T> S findOne(Example<S> example); <S extends T> Iterable<S> findAll(Example<S> example); // … more functionality omitted. }5.6.3. Example Matchers
Examples are not limited to default settings. You can specify your own defaults for string matching, null handling, and property-specific settings by using the ExampleMatcher, as shown in the following example:
Person person = new Person(); person.setFirstname("Dave"); ExampleMatcher matcher = ExampleMatcher.matching() .withIgnorePaths("lastname") .withIncludeNullValues() .withStringMatcherEnding(); Example<Person> example = Example.of(person, matcher);| Create a new instance of the domain object. | |
| Set properties. | |
Create an ExampleMatcher to expect all values to match. It is usable at this stage even without further configuration. |
|
Construct a new ExampleMatcher to ignore the lastname property path. |
|
Construct a new ExampleMatcher to ignore the lastname property path and to include null values. |
|
Construct a new ExampleMatcher to ignore the lastname property path, to include null values, and to perform suffix string matching. |
|
Create a new Example based on the domain object and the configured ExampleMatcher. |
By default, the ExampleMatcher expects all values set on the probe to match. If you want to get results matching any of the predicates defined implicitly, use ExampleMatcher.matchingAny().
You can specify behavior for individual properties (such as "firstname" and "lastname" or, for nested properties, "address.city"). You can tune it with matching options and case sensitivity, as shown in the following example:
ExampleMatcher matcher = ExampleMatcher.matching() .withMatcher("firstname", endsWith()) .withMatcher("lastname", startsWith().ignoreCase()); }Another way to configure matcher options is to use lambdas (introduced in Java 8). This approach creates a callback that asks the implementor to modify the matcher. You need not return the matcher, because configuration options are held within the matcher instance. The following example shows a matcher that uses lambdas:
ExampleMatcher matcher = ExampleMatcher.matching() .withMatcher("firstname", match -> match.endsWith()) .withMatcher("firstname", match -> match.startsWith()); }Queries created by Example use a merged view of the configuration. Default matching settings can be set at the ExampleMatcher level, while individual settings can be applied to particular property paths. Settings that are set on ExampleMatcher are inherited by property path settings unless they are defined explicitly. Settings on a property patch have higher precedence than default settings. The following table describes the scope of the various ExampleMatcher settings:
| Setting | Scope |
|---|---|
| Null-handling |
|
| String matching |
|
| Ignoring properties |
Property path |
| Case sensitivity |
|
| Value transformation |
Property path |
5.6.4. Executing an example
In Spring Data JPA, you can use Query by Example with Repositories, as shown in the following example:
public interface PersonRepository extends JpaRepository<Person, String> { … } public class PersonService { @Autowired PersonRepository personRepository; public List<Person> findPeople(Person probe) { return personRepository.findAll(Example.of(probe)); } }Currently, only SingularAttribute properties can be used for property matching. |
The property specifier accepts property names (such as firstname and lastname). You can navigate by chaining properties together with dots (address.city). You can also tune it with matching options and case sensitivity.
The following table shows the various StringMatcher options that you can use and the result of using them on a field named firstname:
| Matching | Logical result |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
https://docs.spring.io/spring-data/jpa/docs/2.0.13.RELEASE/reference/html/#query-by-example
参考文章:http://www.tuicool.com/articles/jQJBNv
1. 一个使用@Query注解的简单例子
@Query(value = "select name,author,price from Book b where b.price>?1 and b.price<?2") List<Book> findByPriceRange(long price1, long price2);
2. Like表达式
@Query(value = "select name,author,price from Book b where b.name like %:name%")
List<Book> findByNameMatch(@Param("name") String name);
3. 使用Native SQL Query
所谓本地查询,就是使用原生的sql语句(根据数据库的不同,在sql的语法或结构方面可能有所区别)进行查询数据库的操作。
@Query(value = "select * from book b where b.name=?1", nativeQuery = true) List<Book> findByName(String name);
4. 使用@Param注解注入参数
@Query(value = "select name,author,price from Book b where b.name = :name AND b.author=:author AND b.price=:price")
List<Book> findByNamedParam(@Param("name") String name, @Param("author") String author,
@Param("price") long price);
5. SPEL表达式(使用时请参考最后的补充说明)
'#{#entityName}'值为'Book'对象对应的数据表名称(book)。
public interface BookQueryRepositoryExample extends Repository<Book, Long>{
@Query(value = "select * from #{#entityName} b where b.name=?1", nativeQuery = true)
List<Book> findByName(String name);
}
6. 一个较完整的例子
public interface BookQueryRepositoryExample extends Repository<Book, Long> {
@Query(value = "select * from Book b where b.name=?1", nativeQuery = true)
List<Book> findByName(String name);// 此方法sql将会报错(java.lang.IllegalArgumentException),看出原因了吗,若没看出来,请看下一个例子
@Query(value = "select name,author,price from Book b where b.price>?1 and b.price<?2")
List<Book> findByPriceRange(long price1, long price2);
@Query(value = "select name,author,price from Book b where b.name like %:name%")
List<Book> findByNameMatch(@Param("name") String name);
@Query(value = "select name,author,price from Book b where b.name = :name AND b.author=:author AND b.price=:price")
List<Book> findByNamedParam(@Param("name") String name, @Param("author") String author,
@Param("price") long price);
}
7. 解释例6中错误的原因:
因为指定了nativeQuery = true,即使用原生的sql语句查询。使用java对象'Book'作为表名来查自然是不对的。只需将Book替换为表名book。
@Query(value = "select * from book b where b.name=?1", nativeQuery = true) List<Book> findByName(String name);
补充说明(2017-01-12):
有同学提出来了,例子5中用'#{#entityName}'为啥取不到值啊?
先来说一说'#{#entityName}'到底是个啥。从字面来看,'#{#entityName}'不就是实体类的名称么,对,他就是。
实体类Book,使用@Entity注解后,spring会将实体类Book纳入管理。默认'#{#entityName}'的值就是'Book'。
但是如果使用了@Entity(name = "book")来注解实体类Book,此时'#{#entityName}'的值就变成了'book'。
到此,事情就明了了,只需要在用@Entity来注解实体类时指定name为此实体类对应的表名。在原生sql语句中,就可以把'#{#entityName}'来作为数据表名使用。