导语:这篇文章是蚂蚁金服2018年在WWW大会上投中的一篇paper,介绍如果使用少量标注的异常样本进行模型训练,也就是常说的半监督模型,刚好最近在做这个方面的内容,将其翻译过来备查。
摘要
本文研究了异常检测问题。以往的研究大多依据是否有标签来使用有监督或无监督方法,
可用。但是,总是存在一些不同于这两种标准模式的场景。本文中,我们处理了存在部分观测异常的场景,即我们拥有大量未标记的样本和一些少量人工标注的异常。我们将此问题称为存在部分异常观测下的异常检测,并提出两阶段法–ADOA来解决它。首先,通过处理异常之间的差异,而对未标记的数据进行筛选,以获得潜在的异常和可靠的正常数据。然后,利用上述数据,根据每个标签的置信度,给每个点附加一个权重,并建立一个加权的多类模型,该模型将进一步用于区分不同于正常数据的异常。实验结果表明,在上述条件下,现有方法的性能不理想,本文的方法性能明显优于上述方法,证明了该方法的有效性。
关键词
异常检测,观测异常,两步法
1. 引言
异常检测是一种广泛使用的技术,旨在从数据集中正常的行为识别出不正常的模式(patterns)。这些不正常的模式通常被称为异常或异常值,它们是由某种恶意目的或非法活动导致的。异常检测在入侵检测、欺诈检测、故障检测、可疑事务检测、异常移动检测等各种应用中具有重要的意义和关键的帮助。
为了解决这一问题,近年来机器学习技术得到了广泛的应用,这些技术大致可以分为两类:基于非监督学习的方法和基于监督学习的方法。一般的,基于无监督学习的方法发展较快,它的训练数据不需要标签。例如,基于距离的方法、基于密度的方法和基于隔离的方法都是这一方法的典型代表。
另一方面,如果有足够的标注数据,则基于监督学习的方法,如训练支持向量机、决策树、k近邻等分类模型对不可见样本能进行进一步的分类。注意到,与非监督方法相比,监督方法总是能够在有足够标记数据的帮助下提供更好的性能。此外,本文利用标记数据和非标记数据,探索了基于半监督学习的方法,并结合不同的技术,开发了复合算法来处理这个问题。
然而,在某些情况下,异常样本的获取是困难的,我们在能再打来未标记的样本中获取少量的异常。让我们以恶意URL检测任务为例,在某些场景中,除了大量未标记的URL记录之外,我们只能在现有基于规则的系统的帮助下获得少量标记的恶意URL。与同时提供正样本和负样本的监督设置不同,我们在这里得到的只是一小部分正(恶意)样本,因此不能直接使用监督方法。另一方面,与无监督学习环境相比,我们还增加了一些带标签的(负)样本,如何合理利用这些负样本多模型很有帮组。在本文中,我们将这种特殊的异常检测设置称为部分观测异常的异常检测。
已经存在一种学习模式叫做PU (Positive and unlabel)算法,它的做法与前面提到的模式类似。然而,在PU学习中,正样本总是属于一个中心,这意味着正样本之间是相似的,而在异常检测中,正样本之间通常是不相似的,且可能存在严重的差异性。换句话说,我们不能直接假设说,两个异常之间的差异一定是小于正常样本和异常样本直接的差异的。因此,直接应用基于PU学习的异常检测技术可能无法获得满意的性能
另外还有一种半监督聚类的方法,处理那些部分标注的数据或者有先验信息的数据,其目标是将未标记的样本聚类到合适的类。似乎半监督学习处理的任务与我们描述的类似。然而,就像PU学习一样,在半监督聚类中,标记在同一个聚类中的样本应该是相似的,而在异常检测中,观测到的异常并不符合这一点。
本文考虑了部分观测异常异常检测的设置问题,提出了一种基于部分观测异常的异常检测方法ADOA来解决这一问题。ADOA算法有两个阶段。
- step1: 我们认为异常数据不应简单地看成一个中心,假设异常属于k个不同的中心,首先将异常聚类为k个中心。然后根据孤立度和与最近异常类中心的相似性,从未标记的样本中选取潜在异常和可靠正样本。
- step2:依据所附标签的置信度,对各个点进行赋权,然后,利用原始异常样本和所选的样本,建立加权的多分类模型,将异常与正常样本区分开来。
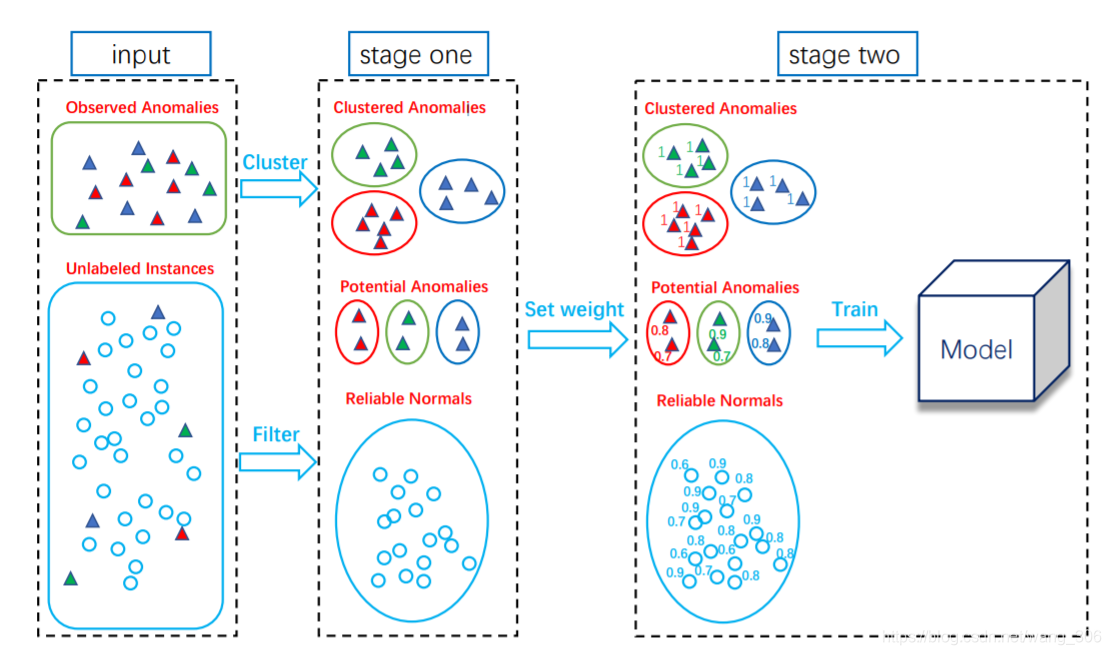
本文在不同数据集和实际应用任务上的实验中证明了该方法的有效性。
本文的其余部分组织如下。在第2节中,我们回顾了相关工作。在第3节中,我们陈述了问题的设定,并提出了所提出的方法。在第4节中,我们报告了在不同数据集上的实验结果。在第5节中,我们将该方法应用于恶意URL检测问题,并验证了该方法的有效性。最后,我们在第六部分对本文进行了总结。
2. 具体工作
异常检测用于处理从正常行为中识别意外模式的任务。异常的检测具有重要的影响,可以在许多不同的领域提供关键的帮助。在实际应用中,针对问题提出了许多基于机器学习的方法,并被广泛应用于入侵检测、欺诈检测、故障检测、可疑事务检测、异常移动活动检测等诸多应用中。
在已有的方法中,基于无监督学习的方法使用无标记数据构建模型。举几个具有代表性的例子,基于距离的方法,基于密度的方法,基于隔离的方法,等等。这些方法可以广泛使用,因为不需要对数据进行标记。然而,在许多应用领域,非监督方法可能无法达到要求的性能。
另一方面,在提供标注数据的情况下,探索了基于监督学习的方法。先后采用支持向量机、决策树、k近邻等多种监督算法进行异常检测。适当利用标签信息,基于监督学习的方法总能取得更好的效果。除了这两种标准范式之外,基于半监督学习方和混合方法等其他方法也在这些技术的基础上进行了研究。
有些情况下,只有正常的样本数据,异常数据无法获取,这种情况下 one-class learning ,SVM 可应用于这种情形,这些方法主要是通过学习超球面来描述正态样本,或者通过学习超平面来最大限度地从原点分割数据点。
PU算法是半监督学习里面的一个特例,它主要用来解决当只有正样本和未标注的样本的数据的时候。过去几年,里,非常多的方法被提出来用以解决这种问题,大致来说,可以分为三类,两步法尝试从未标记的数据中识别出一些可靠的负样本,然后应用传统的监督学习或半监督学习技术。代价敏感学习技术用于不相等误分类代价的二元分类,也可以很容易地用于处理这个问题。针对这一问题,还提出了凸方法。注意,如果我们在这里将异常视为正样本,那么PU学习与部分观测异常的异常检测(ADOA)有些相似。然而,最显著的区别是,正样本在PU学习彼此相似,因此我们可以只找到一个中心,在异常检测,异常总是多样化,他们很少能将其只看做一类,使标准PU学习技术不适合处理异常检测的任务。
3. 部分异常观测的异常检测
这一章中,我们先描述我们的问题,然后描述我们的的方法(ADOA)
3.1 问题描述和符号标记
描述的是数据属于实数空间, 描述的是标签的范围,其中y=+1指的是异常,-1位正常样本,假设有m个训练样本 ,其中 ,前 个样本的标记是异常,另外 个样本为未标记样本,尽管前 个样本已经标记为异常,但是他们直接还是不同的。目标是建立模型: ,从而进一步利用该方法对未来数据进行各种异常与正常的识别。
3.2 本文的方法
ADOA 安装如下两步来进行:
- step1:对于已经标注异常的数据,我们将其分为不同的类,所以这样不同的类里面他们的特征就比较近似,对于未标注的数据,我们的目标是充分挖掘他的价值。所以我们尝试将其分为潜在的异常数据和可靠的正常数据,区分的条件就是isolation score和他们的similarity score。直接原因是这样:一方面,潜在的异常应该和正常样本不一样,另一方法,他们应该可以已观测到的异常近似。
- step2:建立一个加权多分类模型,对于已经标注的异常,赋权为1,对于过滤出来的数据,其权重依据它所带的标签的置信度。
下面是数学描述:
stage1:我们将观测的异常
分为k个中心
,我们可以使用不同的聚类方法,这里只是简单的使用了k-means方法(需要先标准化数据),特别的,两个样本之间的距离直接使用了欧式距离
Isolation score 的计算:孤立的概念第一次被提出来。他们展示随机树林可以用来分离样本,森林里的每棵决策树都使用随机的特征来分割子样本,并不断的分裂节点,知道无法再分割样本。由于异常样本很少,他们总是很贴近于树的根节点,且正常的样本会处于树中比较深的节点。为了计算isolation score,每个样本被送到一颗树的叶子节点上,则可以获得节点的深度,然后计算样本的平均深度。通过计算样本在树中的平均深度,可以认为是样本为异常的概率
,使
表示样本x的平均深度,
表示样本在所有孤立树中的平均深度,假设我们有n个样本,则使
表示为二进制搜索树中的平均深度,其中
是指定参数,可以是
,
是用来规范化IS的:
则
的分数越高(越接近1),样本x就越有可能是异常。
Similarity score 的计算:另一方面,一个样本如果越靠近异常的中心,则它越有可能是潜在的异常,所以我们可以计算样本x和他相近的异常中心的相似分
,其计算公式如下:
其中,
是第i个异常的中心,k是总的异常中心的个数。
Total score 的计算:为了从未标注的样本中区分潜在的异常和正常样本,我们同时考虑Isolation score和Similarity score,总的得分计算:
其中,
,用于平衡两种分数的重要程度。
令
表示异常的平均分数,所以我们选择
作为潜在的异常样本,并把它们放到最近的异常中心中。我们选择
作为可靠的正常样本,其中
是预定义的参数,
越小,选择的样本为正常的可能性就越大。
至此,我们不仅有了可以观测的异常,潜在的异常和可靠的正常样本,且异常被分到了k个类中。
然后,我们为所有的样本赋权,其中,所有标注的异常的权重直接为1,其他的样本中,
分越高,则权重越大,对于潜在的异常样本,计算公式为:
对于可靠的正常样本,越小的
分,则权重需要越高:
通过上述的样本和他们对应的权重,可以构建一个K+1的分类模型用来从正常样本中区分不同的异常。则我们的目标是最小化如下方程:
其中
是指样本
的权重,
是损失函数,
是正则项,这篇文章中使用的是SVM,所以使用的是L2正则。
在构建完多分类模型后,新来的样本就可以进行分类了。当应用模型在无法观测的样本上时,不管新的样本属于哪个异常类别,都将其作为异常看待。
实验(略)
大致描述了几种不同方法在不同数据集上的效果,直接贴些图。
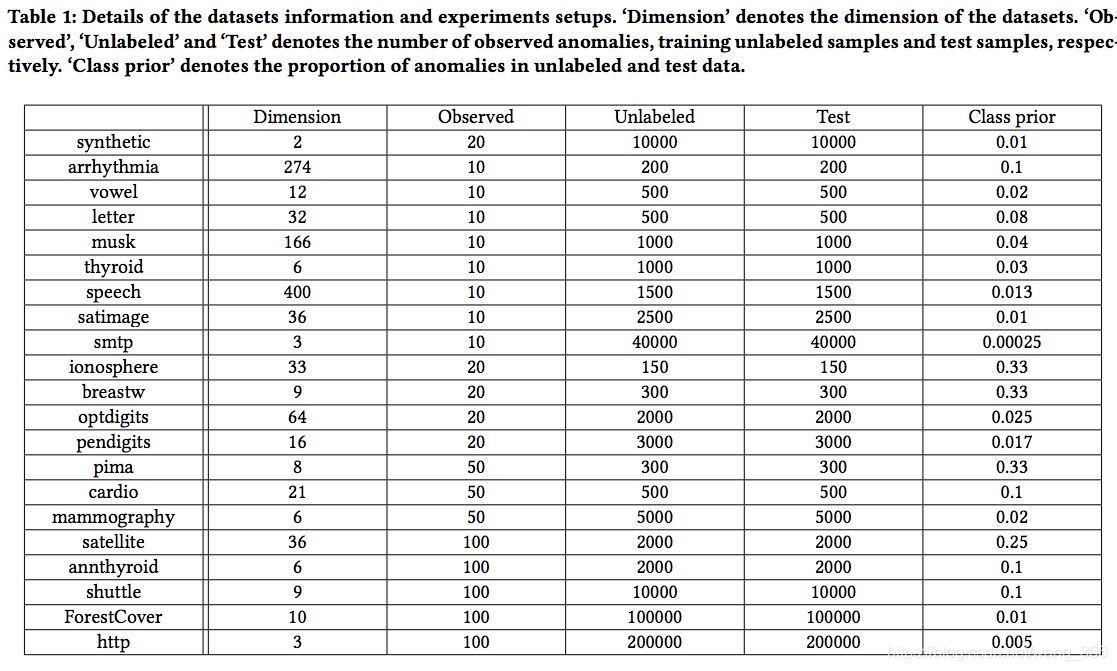
- 实验的数据集规模
- 第一个数据集的异常分布情况

- 不同方法的对比效果图