08 自然语言处理中的机器学习方法
我们已经看到了特性工程的基本和高级水平。我们还看到了如何使用基于规则的系统来开发NLP应用程序。在本章中,我们将开发NLP应用程序,为了开发应用程序,我们将使用机器学习(ML)算法。我们将从ML的基本知识开始。之后,我们将看到使用ML的NLP应用程序的基本开发步骤。我们将主要了解如何在NLP域中使用ML算法。然后,我们将进入特性选择部分,我们还将了解混合模型和后处理技术。
本章概述如下:
了解机器学习的基础知识
NLP应用程序的开发步骤
了解ML算法和其他概念
NLP应用的混合方法
让我们来探索ML的世界!
8.1 机器学习的基本概念
首先,我们将了解什么是机器学习。传统上,编程就是定义所有的步骤以达到某个预先定义的结果。在这个编程过程中,我们使用一种编程语言来定义每一个微小的步骤,这有助于我们实现我们的结果。为了给你一个基本的理解,我举一个一般的例子,假设你想写一个程序来帮助你画一张脸。您可以先编写绘制左眼的代码,然后编写绘制右眼的代码,再编写绘制鼻子的代码,依此类推。这里,您正在为每个面部属性编写代码,但是ML会翻转这种方法。在ML中,我们定义结果,程序学习实现定义的输出的步骤。因此,我们不为每个面部属性编写代码,而是向机器提供数百个人脸样本。我们希望这台机器能够学习绘制人脸所需的步骤,以便绘制出新的人脸。除此之外,当我们提供新的人脸以及一些动物脸时,它应该能够识别出哪张脸看起来像人的脸。让我们举几个一般的例子。如果要识别某些状态的有效车牌,在传统编程中,需要编写代码,例如车牌的形状、颜色、字体等。如果您试图手动对车牌的每个属性进行编码,则这些编码步骤太长。使用ML,我们将向机器提供一些车牌示例,机器将学习步骤,以便识别新的有效车牌。假设你想制作一个程序来玩超级马里奥游戏并赢得比赛。所以,定义每个游戏规则对我们来说太困难了。我们通常定义一个目标,比如你需要在不死亡的情况下到达终点,机器会学习所有步骤来到达终点。有时,问题太复杂了,甚至我们不知道应该采取什么步骤来解决这些问题。例如,我们是一家银行,我们怀疑有一些欺诈活动正在发生,但我们不确定如何检测它们,或者我们甚至不知道要寻找什么。我们可以提供所有用户活动的日志,并查找行为与其他用户不同的用户。机器自行学习检测异常的步骤。ML在互联网上无处不在。每个大科技公司都在以某种方式使用它。当您看到任何YouTube视频时,YouTube会更新或向您提供您可能喜欢观看的其他视频的建议。甚至你的手机也使用ML为你提供诸如iPhone的Siri、Google援助等设施。ML目前进展非常快。研究人员使用旧的概念,改变其中的一些,或者使用其他研究人员,努力使其更有效和有用。让我们来看看ML的基本传统定义。1959年,一位名叫Arthur Samuel的研究人员给计算机提供了无需显式编程即可学习的能力。他从人工智能模式识别和计算学习理论的研究中发展了ML的概念。1997年,Tom Mitchell给了我们一个准确的定义,这个定义对那些能理解基础数学的人很有用。根据Tom Mitchell的定义,ML的定义是:一个计算机程序据说是从经验E中学习一些任务T和一些性能度量P,如果它在T上的性能,如经验P所测量的那样,随着经验E的提高而提高。让我们将前面的定义与前面的示例链接起来。识别车牌称为任务T。您将使用名为体验E的车牌示例运行一些ML程序,如果它成功学习,那么它可以预测下一个未知的车牌,称为性能度量P。现在是时候探索不同类型的ML以及它如何与人工智能相关了。
8.1.1 ML类型
在本节中,我们将介绍不同类型的ML以及一些有趣的分支和超级分支关系。
ML本身源于一个叫做人工智能的分支。ML也有一个分支,它正在制造许多流行的话题,叫做深度学习,但是我们将在第9章,NLP和NLG问题的深度学习中详细介绍人工智能和深度学习。
学习技术可以分为不同的类型。在本章中,我们将重点放在ML上。参见图8.1:
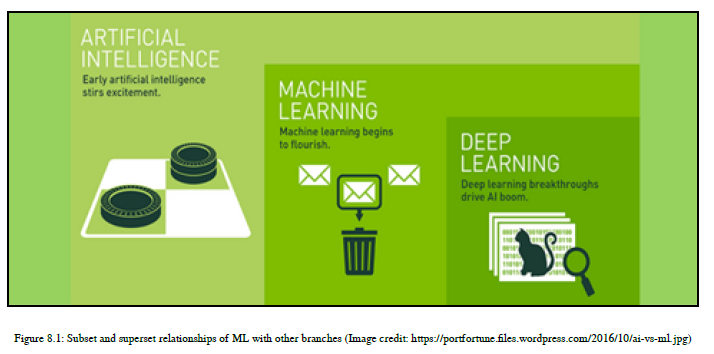
ML技术可以分为三种不同类型,如图8.2所示:
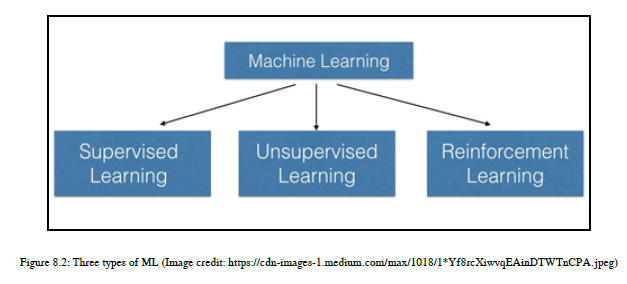
8.1.2 ML 监督学习
在这种类型的ML中,我们将提供一个标记的数据集作为ML算法的输入,并且我们的ML算法知道什么是正确的,什么是不正确的。在这里,ML算法学习标签和数据之间的映射。它生成了ML模型,然后生成的ML模型可以用来解决某些给定的任务。假设我们有一些带有标签的文本数据,比如垃圾邮件和非垃圾邮件。数据集的每个文本流都有这两个标签中的任何一个。当我们应用监督的ML算法时,它使用标记的数据并生成一个ML模型,该模型预测标签为垃圾邮件或非垃圾邮件,用于看不见的文本流。这是一个监督学习的例子。
8.1.3 无监督学习
在这种类型的ML中,我们将提供一个未标记的数据集作为ML算法的输入。所以,我们的算法没有得到任何关于正确与否的反馈。它必须自己学习数据的结构来解决给定的任务。使用未标记的数据集比较困难,但更方便,因为并非每个人都有一个完全标记的数据集。大多数数据都是未标记、混乱和复杂的。
假设我们正在开发一个汇总应用程序。我们可能还没有总结出与实际文档相对应的文档。然后,我们将使用原始文档和实际文本文档为给定的文档创建摘要。在这里,机器不会得到关于ML算法生成的摘要是对还是错的任何反馈。我们还将看到一个计算机视觉应用程序的例子。对于图像识别,我们将一些卡通人物的未标记的图像数据集输入机器,我们期望机器学习如何对每个角色进行分类。当我们提供一个卡通人物的未看到的图像时,它应该识别该角色并将该图像放入T中。他是由机器本身产生的适当的类。
8.1.4 强化学习
第三种类型的ML是强化学习。在这里,ML算法不会在每次预测之后立即给您反馈,但是如果ML模型实现了它的目标,它会生成反馈。这种类型的学习主要用于机器人领域,并开发智能机器人来玩游戏。强化学习与使用试错法与环境交互的思想相联系。为了学习基础知识,让我们举个例子。比如说你想做一个在象棋上打败人类的机器人。这种机器人只有在赢得比赛后才会收到反馈。最近,谷歌Alphago击败了世界上最好的围棋玩家。如果您想了解更多信息,请参阅以下链接:https://techcrunch.com/2017/05/24/alphago-beats-planets-best-human-go-player-ke
-jie/.我知道你一定有兴趣了解每种类型的ML之间的区别。所以,在阅读下一段时要注意。
对于有监督的学习,你会在每一步或每一个预测之后得到反馈。在强化学习中,只有当我们的模型达到目标时,我们才会收到反馈。在无监督的学习中,我们永远不会得到反馈,即使我们实现了我们的目标或者我们的预测是正确的。在强化学习中,它与现有的环境相互作用,使用试错法,而其他两种方法不适用试错法。在有监督的学习中,我们将使用有标记的数据,而在无监督的学习中,我们将使用无标记的数据,在强化学习中,涉及到一系列的目标和决策过程。您可以参考图8.4:
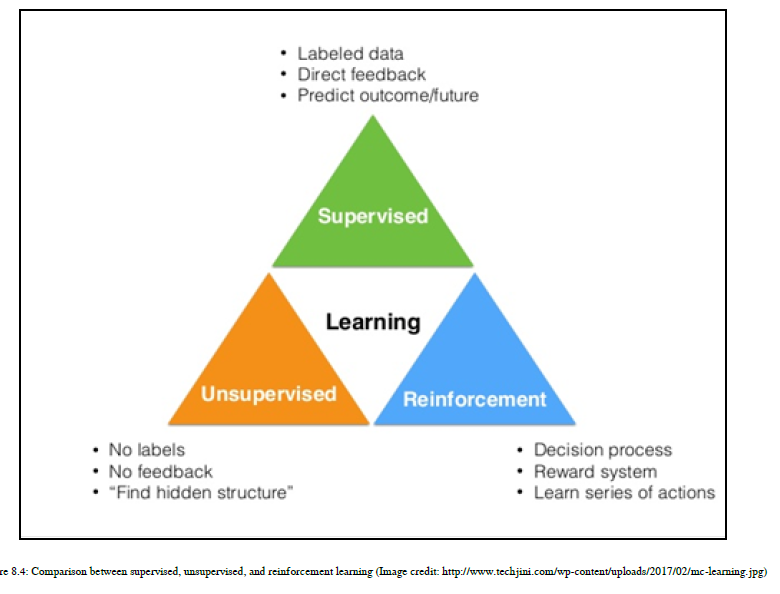
从这一节开始,你将学到很多新的东西,如果你一开始不理解一些术语,那么不要担心!请放心,我将在本章中实际地解释每一个概念。所以,让我们开始了解使用ML的NLP应用程序的开发步骤。
8.2 自然语言处理应用的开发步骤
在本节中,我们将讨论使用ML算法开发NLP应用程序的步骤。这些步骤因域而异。对于NLP应用程序,数据可视化并没有发挥那么重要的作用,而对分析应用程序的数据可视化将给您带来很多洞察。因此,它将从应用程序更改为应用程序,从域更改为域。这里,我的重点是NLP域和NLP应用程序,当我们查看代码时,我肯定会记得我在这里描述的步骤,以便您可以连接这些点。我将开发步骤分为两个版本。第一个版本考虑到它是NLP应用程序开发的第一个迭代。第二个版本将帮助您完成NLP应用程序开发的第一次迭代之后可以考虑的可能步骤。参见图8.5:
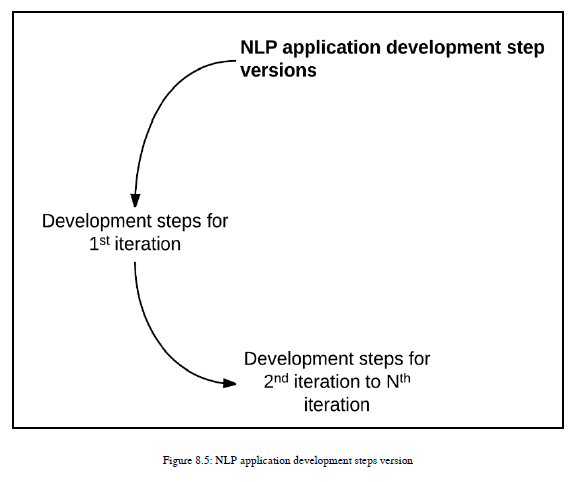
8.2.1 第一次迭代时的开发步骤
首先,我们将了解在使用ML开发第一个版本的NLP应用程序时通常可以使用的步骤。在我的解释过程中,我将参考图8.6,以便您正确理解:
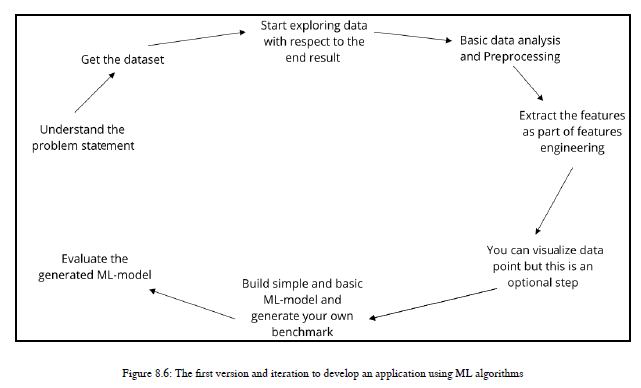
1、这个版本的第一步是理解您的问题陈述、应用程序需求或者您正试图解决的目标。
2、第二步是获取解决目标所需的数据,或者,如果有数据集,则尝试找出数据集包含的内容和构建NLP应用程序所需的内容。如果您需要一些其他数据,那么首先问问您自己;您能在可用数据集的帮助下派生出子数据属性吗?如果是,那么可能不需要获取另一个数据集,但是如果不是,那么尝试获取一个可以帮助您开发NLP应用程序的数据集。
3、第三步是考虑您希望得到什么样的最终结果,并据此开始探索数据集。做一些基本的分析。
4、第四步是在对数据进行一般性分析之后,可以对其应用预处理技术。
5、第五步是从预处理数据中提取特征,作为特征工程的一部分。
6、第六种是,使用统计技术,可以可视化特征值。这是NLP应用程序的可选步骤。
7、第七步是为您自己的基准构建一个简单的基本模型。
8、最后但并非最不重要的是,评估基本模型,如果它符合标准,那么很好;否则,您需要更多的迭代,并且需要遵循另一个版本,我将在下一节中描述这个版本。
8.2.2 从第二次到第N次迭代的开发步骤
我们已经看到了您在第一次迭代中可以采取的步骤;现在我们将看到如何执行第二次迭代,以便提高模型的准确性和效率。在这里,我们还试图使我们的模型尽可能简单。所有这些目标都将是这个开发版本的一部分。
现在,我们将看到在第一次迭代之后可以遵循的步骤。有关基本理解,请参见图8.7:
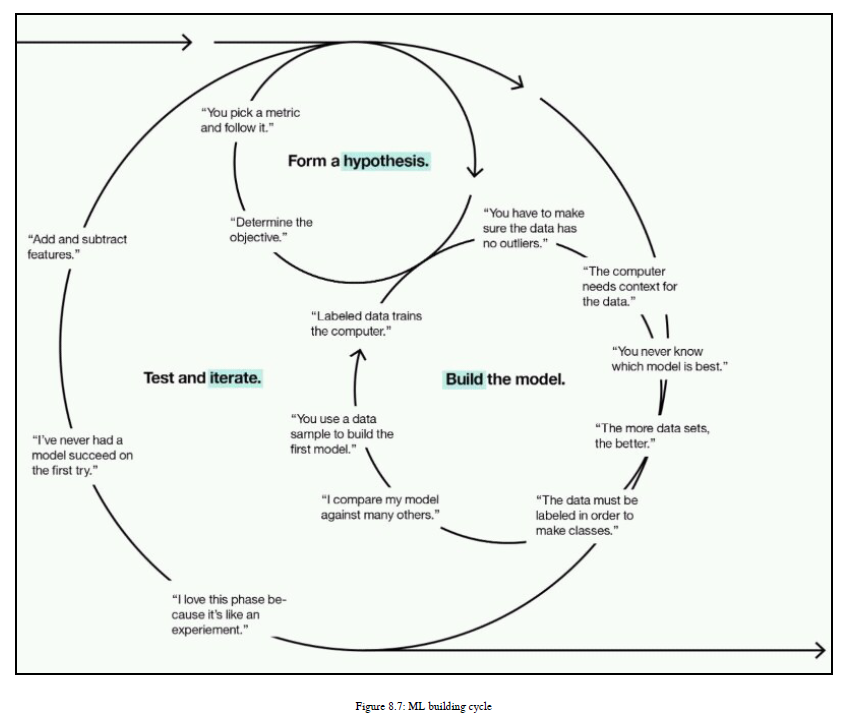
第二次迭代的一些基本步骤如下:1、在第一次迭代之后,您已经构建了一个模型,现在您需要改进它。我建议您尝试不同的ML算法来解决相同的NLP应用程序,并比较其准确性。根据准确度选择最佳的三种ML算法。这将是第一步。
2、作为第二步,通常,您可以对每个选定的ML算法应用超参数调整,以获得更好的精度。
3、如果参数优化对您没有太大的帮助,那么您需要真正专注于特性工程部分,这将是您的第三步。
4、目前,特征工程主要有两个部分:特征提取和特征选择。所以在第一次迭代中,我们已经提取了特征,但是为了优化我们的ML模型,我们需要进行特征选择。我们将在本章后面介绍所有的特性选择技术。
5、在特性选择中,您基本上选择那些特性、变量或数据属性,这些特性、变量或数据属性是非常关键的,或者对获得结果贡献很大。因此,我们只考虑重要的特性并删除其他特性。
6、您还可以删除异常值,执行数据规范化,并对输入数据应用交叉验证,这将帮助您改进ML模型。
7、在执行了所有这些技巧之后,如果您没有得到准确的结果,那么您需要花费一些时间来获得新特性并使用它们。
8、您可以重复前面的所有步骤,直到获得满意的结果。这就是如何处理NLP应用程序的开发。您应该观察您的结果,然后在下一个迭代中采取明智的、必要的步骤。在你的分析中要聪明,考虑所有的问题,然后再重申解决它们。如果你不彻底分析你的结果,那么重复永远不会帮助你。所以保持冷静,明智地思考,并重申。不用担心,当我们使用ML算法开发NLP应用程序时,我们将看到前面的过程。如果你是研究方面的,那么我强烈建议你理解ML算法背后的数学知识,但是如果你是一个初学者并且不太熟悉数学,那么你可以阅读ML库的文档。那些介于这两个区域之间的人,试着找出数学知识,然后实现它。现在,是时候深入了解ML世界,学习一些真正伟大的算法了。
8.3 机器学习算法和其他概念
在这里,我们将介绍最广泛使用的NLP域的ML算法。我们将根据ML的类型来研究算法。首先,我们将从有监督的ML算法开始,然后是无监督的ML算法,最后是半监督的ML算法。在这里,我们将了解算法及其背后的数学。我会保持简单,让那些不是来自一个强大的数学背景可以理解算法背后的直观概念。之后,我们将看到如何实际地使用这些算法来开发一个NLP应用程序。我们将开发一个很酷的NLP应用程序,它将帮助您理解算法而不会产生任何混淆。
那么,我们开始吧!
8.3.1 有监督机器学习方法
我们在本章前面看到了关于受监督机器学习的介绍。我们看到和使用的任何技术和数据集都包括数据集中已经给出的结果、结果或标签。所以,这意味着无论何时,只要有一个标记的数据集,就可以使用受监控的ML算法。
在开始使用算法之前,我将介绍两个主要的监控ML算法概念。这也将帮助您决定选择哪种算法来解决NLP或任何其他与数据科学相关的问题:
回归
分类
回归
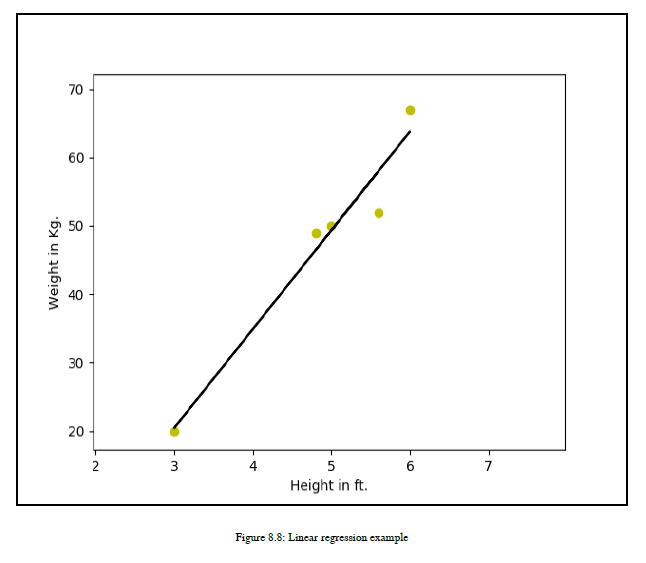
回归是一个统计过程,用来估计变量之间的关系。假设你有一堆变量,你想找出它们之间的关系。首先,你需要找出哪些是因变量,哪些是自变量。回归分析有助于理解因变量如何改变其行为或自变量给定值的值。在这里,因变量依赖于自变量的值,而自变量则采用不依赖于其他变量的值。让我们举一个例子来给你一个清晰的理解。如果你有一个数据集有一个人的身高,你需要根据身高来决定体重,那么这个数据集是有监控的ML,你的数据集中已经有年龄了。所以,你有两个属性,也称为变量:高度和重量。现在,你需要根据给定的高度来预测重量。所以,想几秒钟,让我知道哪个数据属性或变量是依赖的,哪个是独立的。我希望你有一些想法。所以,让我现在回答。这里,权重是依赖于可变高度的相关数据属性或变量。高度是自变量。自变量也称为预测器。因此,如果在因变量和自变量之间有某种映射或关系,那么您也可以预测任何给定高度的权重。
请注意,当输出或因变量取连续值时,使用回归方法。在我们的示例中,重量可以是任何值,例如20千克、20.5千克、20.6千克、60千克等等。对于其他数据集或应用程序,因变量的值可以是任何实数。参见图8.8:
分类
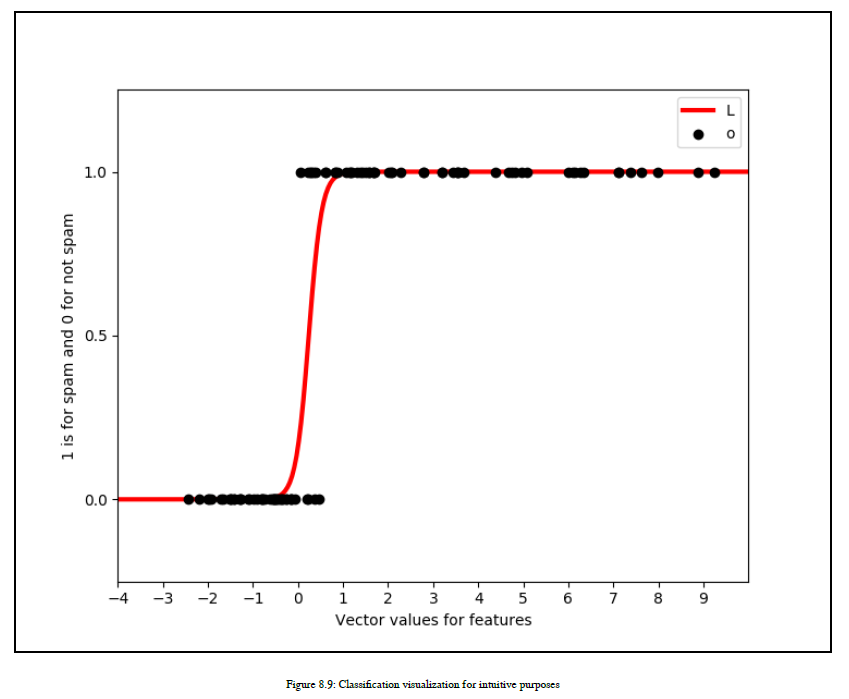
在这一节中,我们将讨论受监督的ML的另一个主要概念,即分类技术。这也被称为统计分类。
统计分类用于确定给定新观察的类别。所以,我们有许多类别可以把新的观察结果放在其中。但是,我们不会盲目地选择任何类别,但是我们将使用给定的数据集,并且基于此数据集,我们将尝试为新观察确定最适合的类别,并将这一类别或类别的观察。
让我们以NLP域本身为例。您有一个包含大量电子邮件的数据集,这些电子邮件已经有了一个类标签,即垃圾邮件或非垃圾邮件。所以,我们的数据集分为两类——垃圾邮件和非垃圾邮件。现在,如果我们收到一封新的电子邮件,那么我们可以将特定的电子邮件分类为垃圾邮件类还是非垃圾邮件类?答案是肯定的。因此,为了对新的电子邮件进行分类,我们使用数据集和ML算法,
为新邮件提供最适合的类。实现分类的算法称为分类器。有时,术语分类器也指由分类器算法实现的将输入数据映射到类别的数学函数。
请注意,这一点有助于您识别回归和分类之间的差异。在分类中,输出变量采用基本上是离散或分类值的类标签。在回归中,我们的输出变量取一个连续值。参见图8.9:
既然我们已经了解了回归和分类的概念,那么让我们经常使用的基本术语,同时解释专门用于分类的ML算法:
实例:这被称为输入,通常是向量的形式,这些是属性的向量。在pos-tagger示例中,我们使用从每个单词派生的特性,并使用scikit-learns API dictvectorizer将它们转换为向量。向量值被输入到ML算法中,因此这些输入向量就是实例。
概念:概念是指将输入映射到输出的函数。因此,如果我们有一个电子邮件内容,并且我们正在努力查明该电子邮件内容是垃圾邮件还是非垃圾邮件,那么我们必须关注实例或输入中的某些特定参数,然后生成结果。如何从某些输入中识别某些输出的过程称为概念。例如,你有一些关于人身高的数据。在看到数据后,你可以决定这个人是高还是矮。在这里,这个概念或函数帮助你找到一个给定输入或实例的输出。所以,如果我把它放在数学格式中,那么这个概念就是一个世界上的一个对象和一个集合中的成员之间的映射。
目标概念:目标概念指的是实际的答案或具体的功能,或我们试图找到的某些特定的概念。作为人类,我们在头脑中已经了解了很多概念,例如通过阅读电子邮件,我们可以判断它是垃圾邮件还是非垃圾邮件,如果您的判断是正确的,那么您就可以得到实际的答案。你知道什么叫垃圾邮件,什么不是,但除非我们把它写在某个地方,否则我们不知道它是对还是错。如果我们注意到数据集中每个原始数据的这些实际答案,那么我们就更容易确定哪些电子邮件应被视为垃圾邮件,哪些不应被视为垃圾邮件。这将帮助您找到新实例的实际答案。
假设类:是可以帮助我们对实例进行分类的所有可能函数的类。我们刚刚看到了目标概念,我们试图找出一个特定的函数,但是这里我们可以想到所有可能的和潜在的函数的子集,这些函数可以帮助我们找出分类问题的目标概念。在这里,我要指出的是,我们看到分类任务的这个术语,所以不要考虑x2函数,因为它是一个线性函数,我们执行的是分类而不是回归。
训练数据集:在分类中,我们试图找到目标概念或实际答案。现在,我们如何才能得到最终的答案呢?为了使用ML技术得到最终的答案,我们将使用一些样本集、训练集或训练数据集来帮助我们找到实际的答案。让我们看看训练集是什么。训练集包含与标签配对的所有输入。监督分类问题需要用实际答案或实际输出标记的训练数据集。所以,我们不仅仅是将我们的知识传递给机器,告诉它什么是垃圾邮件,什么是非垃圾邮件;我们还向机器提供了很多例子,比如这是垃圾邮件,这是非垃圾邮件,等等。因此,对于机器来说,很容易理解目标概念。
ML模型:我们将使用训练数据集,并将这些数据输入到ML算法中,然后,ML算法将尝试使用大量的训练示例来学习这个概念,并生成输出模型。此输出模型稍后可用于预测或决定给定的新邮件是否为垃圾邮件。生成的输出称为ML模型。我们将使用一个生成的ML模型并将新邮件作为输入,这个ML模型将生成关于给定邮件是否属于垃圾邮件类别的答案。
候选者:候选者是我们的ML模型为新示例告诉我们的潜在目标概念。所以,你可以说候选者是机器的预测目标概念,但是我们不知道这里的候选者的预测或生成的输出是否是正确的答案。那么,让我们举个例子。我们向机器提供了许多电子邮件示例。机器可以概括垃圾邮件的概念,而不是垃圾邮件。我们将提供一封新的电子邮件,我们的ML模型会说它不是垃圾邮件,但是,我们需要检查我们的ML模型的答案是对还是错。这个答案被称为候选人。如何检查ML模型生成的答案是否与目标概念匹配?为了回答您的问题,我将介绍下一个术语,即测试集。
测试集:测试集类似于训练数据集。我们的训练数据集包含带有垃圾邮件或非垃圾邮件等标签的电子邮件。因此,我将采用被认为是候选者的答案,并且我们将检查我们的测试集是否是非垃圾邮件或垃圾邮件。我们将把我们的答案与测试集的答案进行比较,并试图找出候选人的答案是正确的还是错误的。假设不是垃圾邮件是正确的答案。现在,您将收到另一封电子邮件,ML模型将再次生成一个非垃圾邮件答案。我们将用我们的测试集再次检查这个问题,这次ML模型生成了一个错误的答案——邮件实际上是垃圾邮件,但是ML模型将其错误地分类为非垃圾邮件类别。因此,测试集帮助我们验证MLModel。请注意,训练和测试集不应相同。这是因为,如果您的机器使用训练数据集学习概念,并且在训练数据集上测试MLModel,那么您就没有公平地评估ML模型。这在ML中被认为是作弊。因此,您的训练数据集和测试集应该总是不同的;测试集是您的机器从未见过的数据集。我们这样做是因为我们需要检查机器的能力,看看给定的问题能推广多少。这里,广义的意思是ML模型如何对未知和未知的例子做出反应。如果你还是很困惑,那我再举一个例子。你是个学生,老师教你一些事实,给你举了一些例子。起初,你只是记住了事实。为了检查你是否有正确的概念,老师会给你一个测试,并给你一个新的例子,在那里你需要应用你的学习。如果您能够将您的学习完美地应用到测试中的新示例中,那么您实际上就得到了这个概念。这证明了我们可以概括出老师教过的概念。我们用机器做同样的事情。
ML算法
我们已经充分了解了ML的基本概念,现在我们将探讨ML算法。首先,我们将看到在NLP域中主要使用的监控ML算法。我不打算在这里介绍所有受监控的ML算法,但我将解释在NLP领域中最广泛使用的那些算法。
在NLP应用程序中,我们主要使用各种ML技术执行分类。所以,在这里,我们主要关注的是算法的分类类型。其他领域,如分析使用各种类型的线性回归算法,以及分析应用程序
但是我们不会去看这些算法,因为这本书是关于NLP域的。由于线性回归的一些概念有助于我们理解深度学习技术,我们将通过第9章“NLP和NLG问题的深度学习”中的示例,详细介绍线性回归和梯度下降。
我们将使用各种算法开发一些NLP应用程序,这样您就可以看到算法的工作原理以及NLP应用程序如何使用ML算法开发。我们将研究垃圾邮件过滤等应用程序。

逻辑回归
我知道你一定很困惑,为什么我把逻辑回归放在分类类别中。让我告诉你,这只是这个算法的名字,但它是用来预测离散输出的,所以这个算法属于分类类别。
对于这个分类算法,我将给你一个逻辑回归算法是如何工作的概念,我们将看看与之相关的一些基础数学。然后,我们将查看垃圾邮件过滤应用程序。
首先,我们将考虑二进制类,如垃圾邮件与否、好坏、得失、0或1等,以了解算法及其应用。假设我想将电子邮件分类为垃圾邮件,而不是垃圾邮件类别。垃圾邮件和非垃圾邮件是离散的输出标签或目标概念。我们的目标是预测新电子邮件是否是垃圾邮件。非垃圾邮件也被称为火腿。为了构建这个NLP应用程序,我们将使用逻辑回归。
首先让我们了解算法的技术性。
在这里,我以一种非常简单的方式陈述与数学和这个算法有关的事实。理解该算法的一般方法如下。如果你知道ml的某些部分,那么你可以把这些点连接起来,如果你是ml的新手,那么不要担心,因为我们将了解每个部分:
我们正在定义我们的假设函数,帮助我们生成目标输出或目标概念。
我们定义了成本函数或误差函数,我们选择误差函数的方式是,我们可以导出误差函数的偏导数,这样我们就可以方便地计算梯度下降。
我们正努力将误差降到最低,以便生成更准确的标签,并对数据进行准确分类。在统计学中,逻辑回归又称为逻辑回归或逻辑模型。该算法主要是作为一个二元类分类器来使用的,这意味着应该有两个不同的类来对数据进行分类。二元逻辑模型用于估计二元响应的概率,它基于一个或多个预测因子或独立变量或特征生成响应。这是一个ML算法,在深度学习中也使用了基本的数学概念。
首先,我想解释一下为什么这个算法被称为逻辑回归。原因是该算法使用了一个逻辑函数或sigmoid函数。逻辑功能和sigmoid函数是同义词。
我们用sigmoid函数作为假设函数。你所说的假设函数是什么意思?好吧,正如我们前面看到的,机器必须学习数据属性和给定标签之间的映射,这样它才能预测新数据的标签。如果机器通过数学函数学习这种映射,就可以实现这一点。数学函数是机器用来分类数据和预测标签或目标概念的假设函数。我们想要构建一个二进制分类器,所以我们的标签要么是垃圾邮件,要么不是。所以,在数学上,我可以为正常指定0,或者不为垃圾邮件指定1,或者反之亦然。这些数学上指定的标签是我们的因变量。现在,我们需要输出标签为0或1。数学上,标签是y和yε0,1。所以我们需要选择一个假设函数,将我们的输出值转换为0或1。logistic函数或sigmoid函数就是这样做的,这也是logistic回归使用sigmoid函数作为假设函数的主要原因。
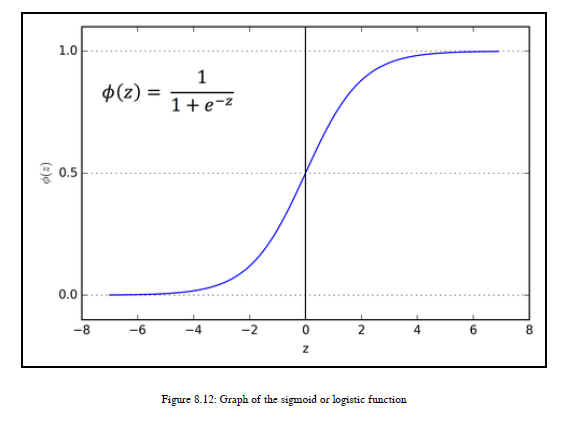
从上图中,您可以发现以下事实:
如果z值大于或等于零,那么logistic函数给出输出值1。
如果z值小于零,那么logistic函数将生成输出0
这个sigmoid函数如何表示为假设函数:
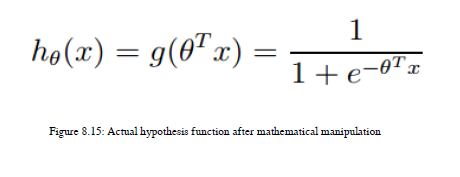
使用假设方程,机器实际上尝试学习输入变量或输入特征和输出标签之间的映射。我们来谈谈这个假设函数的解释。你能想出预测类标签的最佳方法吗?根据我的观点,我们可以使用概率概念来预测目标类标签。我们需要为这两个类生成概率,并且任何具有高概率的类都将被分配给特性的特定实例。在二进制分类中,y或目标类的值要么是零,要么是一。如果您熟悉概率,那么可以表示图8.16中给出的概率方程:
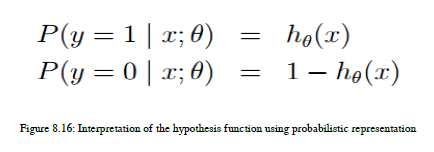
- 逻辑回归的成本或误差函数
首先,让我们了解成本函数或错误函数。在ML中,成本函数、损失函数或误差函数是一个非常重要的概念,因此我们将了解成本函数的定义。成本函数用于检查我们的ML分类器执行的准确性。在我们的训练数据集中,我们有数据和标签。当我们使用假设函数并生成输出时,我们需要检查离实际预测的距离。如果我们预测实际的输出标签,那么我们的假设函数输出和实际标签之间的差异是零或最小的,如果我们的假设函数输出和实际标签不相同,那么我们在它们之间有很大的差异。如果电子邮件的实际标签是垃圾邮件,即垃圾邮件,并且我们的假设函数也生成结果1,那么实际目标值和预测输出值之间的差异为零,因此预测中的错误也为零。如果我们的预测输出为1,而实际输出为零,那么我们的实际目标概念和预测之间的误差最大。所以,在我们的预测中有最小的误差是很重要的。这是误差函数的基本概念。我们将在一段时间内学习数学。有几种类型的错误函数可用,如r2错误、平方和错误等。根据ML算法和假设函数,我们的误差函数也发生了变化。逻辑回归的误差函数是什么?什么是θ,如果我需要选择θ的某个值,我如何处理它?所以,在这里,我会给出所有的答案。
让我给你一些线性回归的背景知识。在线性回归中,一般采用平方误差和或残差之和作为成本函数。在线性回归中,我们试图生成最适合我们的数据集的线。在前面的例子中,给定高度,我想预测重量。我们首先画一条线,测量从每个数据点到线的距离。我们将平方这些距离,求和并尽量减小误差函数。参见图8.17:
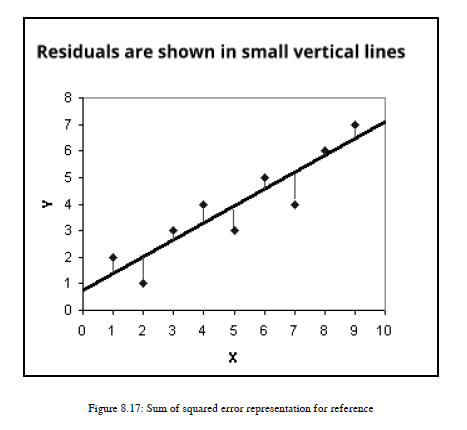
您可以看到每个数据点与线之间的距离是用小的垂直线表示的。我们将把这些距离平方,然后求和。我们将使用这个错误函数。我们已经生成了关于m线和截距b的斜率的偏导数。在图8.17中,b约为0.9,m约为三分之二。每次计算误差,更新m和b的值,生成最佳拟合线。更新m和b的过程称为梯度下降。利用梯度下降法对m和b进行更新,使误差函数具有最小的误差值,从而生成最佳拟合线。梯度下降给我们一个需要画线的方向。您可以在第9章深入学习NLP和NLG问题中找到一个详细的例子。因此,通过定义误差函数并生成偏导数,我们可以应用梯度下降算法,帮助我们最小化误差或成本函数。现在回到主要问题:我们可以使用误差函数进行逻辑回归吗?如果你对函数和微积分很了解,那么你的答案可能是否定的,这是正确的答案。让我为那些不熟悉函数和微积分的人解释一下。在线性回归中,我们的假设函数是线性的,所以我们很容易计算平方误差之和,但是在这里,我们将使用一个非线性函数sigmoid函数。如果你应用我们在线性回归中使用的相同的函数,结果会不好,因为如果你使用的是sigmoid函数,输入平方误差函数之和,并尝试可视化所有可能的值,那么你会得到一条非凸曲线。
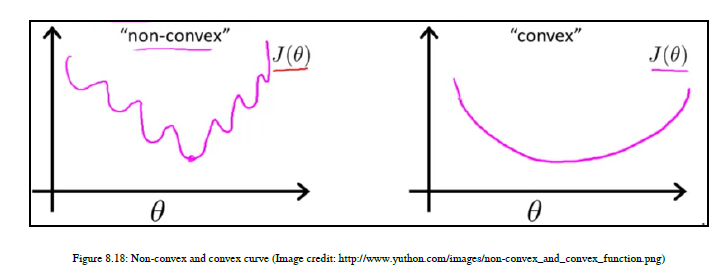
在ML中,我们主要使用能够提供凸曲线的函数,因为我们可以使用梯度下降算法来最小化误差函数并达到全局最小值。如图8.18所示,非凸曲线有许多局部极小值,因此要达到全局极小值是非常困难和耗时的,因为需要应用二阶或第n阶优化来达到全局最小值,而在凸曲线中,您可以确定地快速地达到全局最小值。所以,如果我们把我们的sigmoid函数代入平方误差之和,就得到了非凸函数,这样我们就不会定义线性回归中使用的相同的误差函数。我们需要定义一个不同的凸优化函数,这样我们就可以应用梯度下降算法并生成一个全局最小值。我们将使用称为可能性的统计概念。为了推导似然函数,我们将使用图8.16中给出的概率方程,并考虑训练数据集中的所有数据点。所以,我们可以得到下面的方程,叫做似然函数。参见图8.19:
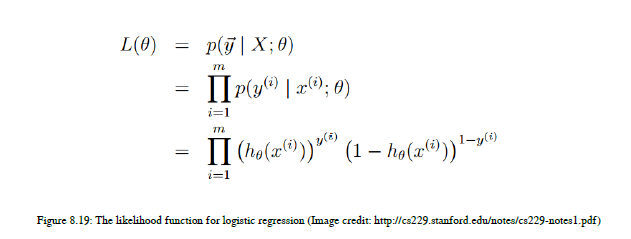
现在,为了简化导数过程,我们需要将似然函数转换为单调递增函数。这可以通过取似然函数的自然对数来实现,称为对数似然。这个对数可能性是我们进行逻辑回归的成本函数。参考图8.20中的以下方程式:
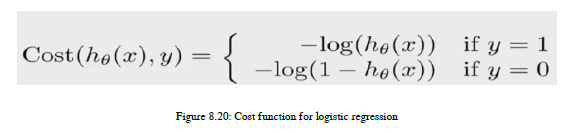
我们将绘制成本函数并了解它为我们提供的好处。在x轴上,我们有假设函数。假设函数的范围是0到1,所以我们在x轴上有这两点。从第一个案例开始,其中y=1。您可以在图8.21中看到右上方生成的曲线:
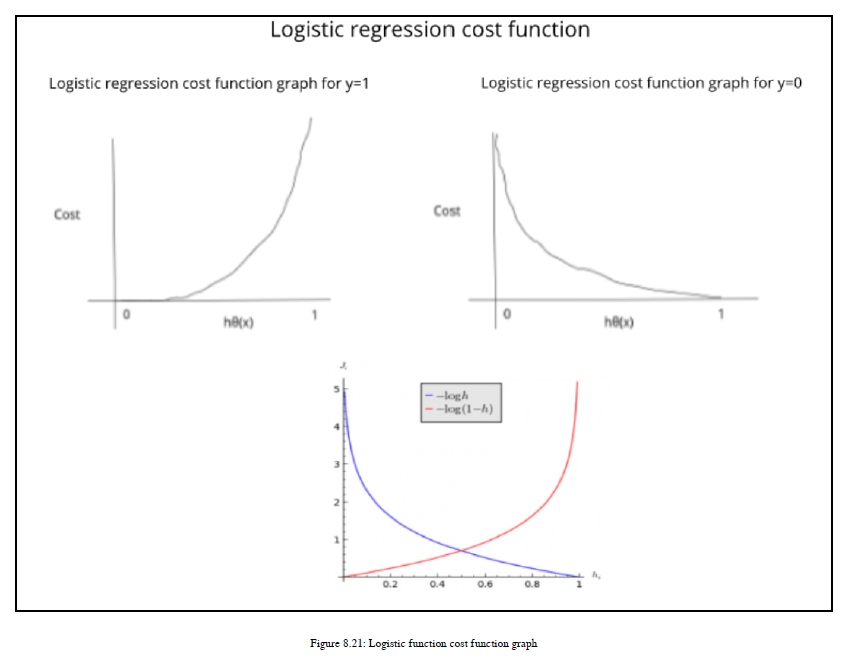
如果你看任何一个对数函数图,它会像误差函数y=0的图。这里,我们翻转曲线,因为我们有一个负号,然后你得到我们为y=1值绘制的曲线。在图8.21中,您可以看到日志图,以及图8.22中的翻转图:
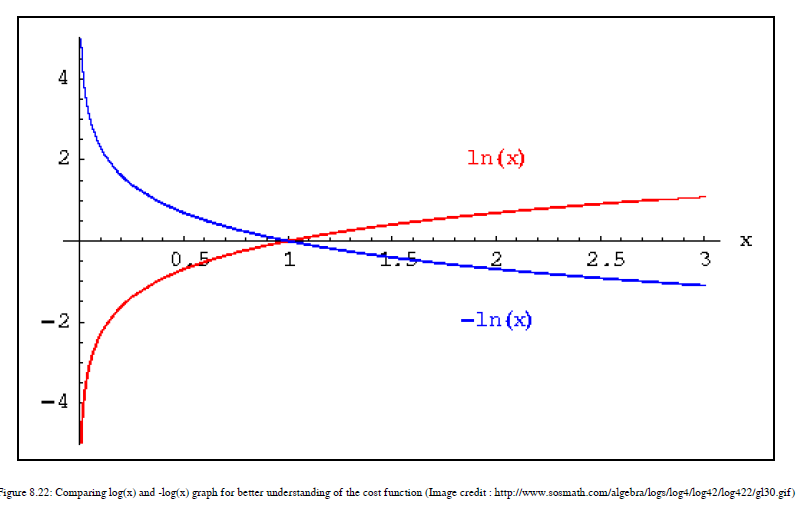
这里,我们对值0和1感兴趣,因此我们考虑图8.21中描述的图的那部分。这个成本函数有一些有趣和有用的特性。如果预测标签或候选标签与实际目标标签相同,则成本为零。如果假设函数预测hθ(x)=1,那么成本=0;如果hθ(x)趋向于0,这意味着如果它更接近于零,那么成本函数就会放大到∞。对于y=0,您可以看到图8.21中左上方的图。这种情况下的条件也具有与我们之前看到的相同的优点和特性。当实际值为0且假设函数预测为1时,它将变为∞。如果假设函数预测为0,实际目标也为0,则成本=0。现在,我们来看看为什么要选择这个成本函数。原因是这个函数使我们的优化变得容易,因为我们将使用最大对数似然,因为它有一个凸曲线,可以帮助我们进行梯度下降。
为了应用梯度下降,我们需要生成相对于θ的偏导数,并生成如图8.23所示的方程:
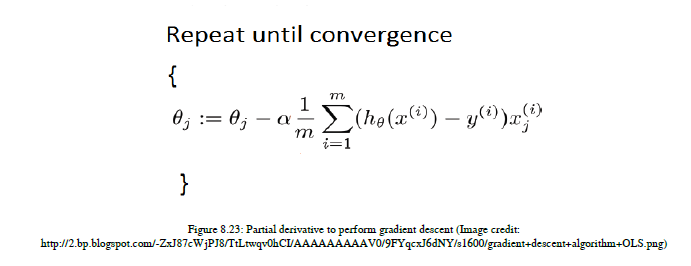
该方程用于更新θ的参数值;定义学习率。这是可以用来设置算法学习或训练的速度或速度的参数。如果你把学习率设置得太高,那么算法就无法学习,如果你把它设置得太低,那么训练就需要很多时间。所以你需要明智地选择学习率。
代码实现
import math
import numpy as np
import pandas as pd
from pandas import DataFrame
from sklearn import preprocessing
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import train_test_split
from numpy import loadtxt, where
from pylab import scatter, show, legend, xlabel, ylabel
d:\Program Files\Anaconda3\lib\site-packages\sklearn\cross_validation.py:44: DeprecationWarning: This module was deprecated in version 0.18 in favor of the model_selection module into which all the refactored classes and functions are moved. Also note that the interface of the new CV iterators are different from that of this module. This module will be removed in 0.20.
"This module will be removed in 0.20.", DeprecationWarning)
# scale larger positive and values to between -1,1 depending on the largest
# value in the data
min_max_scaler = preprocessing.MinMaxScaler(feature_range=(-1,1))
df = pd.read_csv("data.csv", header=0)
# clean up data
df.columns = ["grade1","grade2","label"]
x = df["label"].map(lambda x: float(x.rstrip(';')))
# formats the input data into two arrays, one of independant variables
# and one of the dependant variable
X = df[["grade1","grade2"]]
X = np.array(X)
X = min_max_scaler.fit_transform(X)
Y = df["label"].map(lambda x: float(x.rstrip(';')))
Y = np.array(Y)
# if want to create a new clean dataset
##X = pd.DataFrame.from_records(X,columns=['grade1','grade2'])
##X.insert(2,'label',Y)
##X.to_csv('data2.csv')
# creating testing and training set
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.33)
# train scikit learn model
clf = LogisticRegression()
clf.fit(X_train,Y_train)
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)
print('score Scikit learn: ', clf.score(X_test,Y_test))
score Scikit learn: 0.8484848484848485
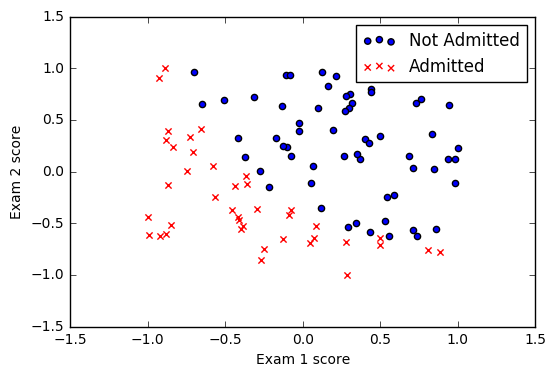
# visualize data, uncomment "show()" to run it
pos = where(Y == 1)
neg = where(Y == 0)
scatter(X[pos, 0], X[pos, 1], marker='o', c='b')
scatter(X[neg, 0], X[neg, 1], marker='x', c='r')
xlabel('Exam 1 score')
ylabel('Exam 2 score')
legend(['Not Admitted', 'Admitted'])
show()
##The sigmoid function adjusts the cost function hypotheses to adjust the algorithm proportionally for worse estimations
def Sigmoid(z):
G_of_Z = float(1.0 / float((1.0 + math.exp(-1.0*z))))
return G_of_Z
##The hypothesis is the linear combination of all the known factors x[i] and their current estimated coefficients theta[i]
##This hypothesis will be used to calculate each instance of the Cost Function
def Hypothesis(theta, x):
z = 0
for i in range(len(theta)):
z += x[i]*theta[i]
return Sigmoid(z)
##For each member of the dataset, the result (Y) determines which variation of the cost function is used
##The Y = 0 cost function punishes high probability estimations, and the Y = 1 it punishes low scores
##The "punishment" makes the change in the gradient of ThetaCurrent - Average(CostFunction(Dataset)) greater
def Cost_Function(X,Y,theta,m):
sumOfErrors = 0
for i in range(m):
xi = X[i]
hi = Hypothesis(theta,xi)
if Y[i] == 1:
error = Y[i] * math.log(hi)
elif Y[i] == 0:
error = (1-Y[i]) * math.log(1-hi)
sumOfErrors += error
const = -1/m
J = const * sumOfErrors
print('cost is ', J )
return J
##This function creates the gradient component for each Theta value
##The gradient is the partial derivative by Theta of the current value of theta minus
##a "learning speed factor aplha" times the average of all the cost functions for that theta
##For each Theta there is a cost function calculated for each member of the dataset
def Cost_Function_Derivative(X,Y,theta,j,m,alpha):
sumErrors = 0
for i in range(m):
xi = X[i]
xij = xi[j]
hi = Hypothesis(theta,X[i])
error = (hi - Y[i])*xij
sumErrors += error
m = len(Y)
constant = float(alpha)/float(m)
J = constant * sumErrors
return J
##For each theta, the partial differential
##The gradient, or vector from the current point in Theta-space (each theta value is its own dimension) to the more accurate point,
##is the vector with each dimensional component being the partial differential for each theta value
def Gradient_Descent(X,Y,theta,m,alpha):
new_theta = []
constant = alpha/m
for j in range(len(theta)):
CFDerivative = Cost_Function_Derivative(X,Y,theta,j,m,alpha)
new_theta_value = theta[j] - CFDerivative
new_theta.append(new_theta_value)
return new_theta
##The high level function for the LR algorithm which, for a number of steps (num_iters) finds gradients which take
##the Theta values (coefficients of known factors) from an estimation closer (new_theta) to their "optimum estimation" which is the
##set of values best representing the system in a linear combination model
def Logistic_Regression(X,Y,alpha,theta,num_iters):
m = len(Y)
for x in range(num_iters):
new_theta = Gradient_Descent(X,Y,theta,m,alpha)
theta = new_theta
if x % 100 == 0:
#here the cost function is used to present the final hypothesis of the model in the same form for each gradient-step iteration
Cost_Function(X,Y,theta,m)
print('theta ', theta)
print('cost is ', Cost_Function(X,Y,theta,m))
Declare_Winner(theta)
##This method compares the accuracy of the model generated by the scikit library with the model generated by this implementation
def Declare_Winner(theta):
score = 0
winner = ""
#first scikit LR is tested for each independent var in the dataset and its prediction is compared against the dependent var
#if the prediction is the same as the dataset measured value it counts as a point for thie scikit version of LR
scikit_score = clf.score(X_test,Y_test)
length = len(X_test)
for i in range(length):
prediction = round(Hypothesis(X_test[i],theta))
answer = Y_test[i]
if prediction == answer:
score += 1
#the same process is repeated for the implementation from this module and the scores compared to find the higher match-rate
my_score = float(score) / float(length)
if my_score > scikit_score:
print('You won!')
elif my_score == scikit_score:
print('Its a tie!')
else:
print('Scikit won.. :(')
print('Your score: ', my_score)
print('Scikits score: ', scikit_score )
initial_theta = [0,0]
alpha = 0.1
iterations = 1000
Logistic_Regression(X,Y,alpha,initial_theta,iterations)
cost is 0.6886958174712052
theta [0.015808968977217012, 0.014030982200249273]
cost is 0.6886958174712052
cost is 0.6886958174712052
cost is 0.45043928326843835
theta [1.1446039323506159, 1.030383323481578]
cost is 0.45043928326843835
cost is 0.45043928326843835
cost is 0.37210396400568835
theta [1.7920198800927762, 1.6251057941038252]
cost is 0.37210396400568835
cost is 0.37210396400568835
cost is 0.33493174290971306
theta [2.2378078311381255, 2.0381775708737533]
cost is 0.33493174290971306
cost is 0.33493174290971306
cost is 0.3134393548415864
theta [2.5764517180022444, 2.35358660097723]
cost is 0.3134393548415864
cost is 0.3134393548415864
cost is 0.2995143683386589
theta [2.8487364478320787, 2.608155678935002]
cost is 0.2995143683386589
cost is 0.2995143683386589
cost is 0.2898100759552151
theta [3.0758031030008572, 2.8210921909376734]
cost is 0.2898100759552151
cost is 0.2898100759552151
cost is 0.2826976528686292
theta [3.2700162725064694, 3.0036648752998807]
cost is 0.2826976528686292
cost is 0.2826976528686292
cost is 0.2772893938976962
theta [3.4392392975568247, 3.163057635787686]
cost is 0.2772893938976962
cost is 0.2772893938976962
cost is 0.2730601259267772
theta [3.588788716304762, 3.3041402117668226]
cost is 0.2730601259267772
cost is 0.2730601259267772
Its a tie!
Your score: 0.8484848484848485
Scikits score: 0.8484848484848485
这有一个逻辑回归的实现,您可以在SciKit学习库中找到它与给定实现的比较。
垃圾邮件过滤
垃圾邮件过滤是一种基本的NLP应用程序。使用此算法,我们希望建立一个ML模型,将给定邮件分类为垃圾邮件或正常类。所以,让我们制作一个垃圾邮件过滤应用程序。在垃圾邮件过滤中,我们将使用scikit-learn的CountVectorizer API学习生成特性,然后使用LogisticRegression进行训练。
import pandas as pd
import numpy as np
# read file into pandas using a relative path
path = 'sms.tsv'
sms = pd.read_table(path, header=None, names=['label', 'message'])
# examine the shape
sms.shape
(5572, 2)
# examine the first 10 rows
sms.head(10)
| label | message | |
|---|---|---|
| 0 | ham | Go until jurong point, crazy.. Available only ... |
| 1 | ham | Ok lar... Joking wif u oni... |
| 2 | spam | Free entry in 2 a wkly comp to win FA Cup fina... |
| 3 | ham | U dun say so early hor... U c already then say... |
| 4 | ham | Nah I don't think he goes to usf, he lives aro... |
| 5 | spam | FreeMsg Hey there darling it's been 3 week's n... |
| 6 | ham | Even my brother is not like to speak with me. ... |
| 7 | ham | As per your request 'Melle Melle (Oru Minnamin... |
| 8 | spam | WINNER!! As a valued network customer you have... |
| 9 | spam | Had your mobile 11 months or more? U R entitle... |
# examine the class distribution
sms.label.value_counts()
ham 4825
spam 747
Name: label, dtype: int64
# convert label to a numerical variable
sms['label_num'] = sms.label.map({'ham':0, 'spam':1})
# check that the conversion worked
sms.head(10)
| label | message | label_num | |
|---|---|---|---|
| 0 | ham | Go until jurong point, crazy.. Available only ... | 0 |
| 1 | ham | Ok lar... Joking wif u oni... | 0 |
| 2 | spam | Free entry in 2 a wkly comp to win FA Cup fina... | 1 |
| 3 | ham | U dun say so early hor... U c already then say... | 0 |
| 4 | ham | Nah I don't think he goes to usf, he lives aro... | 0 |
| 5 | spam | FreeMsg Hey there darling it's been 3 week's n... | 1 |
| 6 | ham | Even my brother is not like to speak with me. ... | 0 |
| 7 | ham | As per your request 'Melle Melle (Oru Minnamin... | 0 |
| 8 | spam | WINNER!! As a valued network customer you have... | 1 |
| 9 | spam | Had your mobile 11 months or more? U R entitle... | 1 |
# how to define X and y (from the SMS data) for use with COUNTVECTORIZER
X = sms.message
y = sms.label_num
print(X.shape)
print(y.shape)
(5572,)
(5572,)
# split X and y into training and testing sets
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
(4179,)
(1393,)
(4179,)
(1393,)
# import and instantiate CountVectorizer (with the default parameters)
from sklearn.feature_extraction.text import CountVectorizer
# instantiate the vectorizer
vect = CountVectorizer()
# learn training data vocabulary, then use it to create a document-term matrix
vect.fit(X_train)
X_train_dtm = vect.transform(X_train)
# equivalently: combine fit and transform into a single step
X_train_dtm = vect.fit_transform(X_train)
# examine the document-term matrix
X_train_dtm
<4179x7456 sparse matrix of type '<class 'numpy.int64'>'
with 55209 stored elements in Compressed Sparse Row format>
# transform testing data (using fitted vocabulary) into a document-term matrix
X_test_dtm = vect.transform(X_test)
X_test_dtm
<1393x7456 sparse matrix of type '<class 'numpy.int64'>'
with 17604 stored elements in Compressed Sparse Row format>
from sklearn import linear_model
clf = linear_model.LogisticRegression(C=1e5)
# train the model using X_train_dtm (timing it with an IPython "magic command")
%timeit clf.fit(X_train_dtm, y_train)
10 loops, best of 3: 54.7 ms per loop
# make class predictions for X_test_dtm
y_pred_class = clf.predict(X_test_dtm)
# calculate accuracy of class predictions
from sklearn import metrics
metrics.accuracy_score(y_test, y_pred_class)
0.9885139985642498
我们执行一些基本的文本分析,以帮助我们理解数据。这里,我们使用scikit-learn API, CountVectorizer().将文本数据转换为矢量格式。此API在下面使用(tf-idf)。我们将数据集分为一个训练数据集和一个测试集,这样我们就可以检查分类器模型在测试数据集上的表现。
# print the confusion matrix
metrics.confusion_matrix(y_test, y_pred_class)
array([[1205, 3],
[ 13, 172]])
# print message text for the false positives (ham incorrectly classified as spam)
X_test[y_test < y_pred_class]
2340 Cheers for the message Zogtorius. I’ve been st...
4009 Forgot you were working today! Wanna chat, but...
1497 I'm always on yahoo messenger now. Just send t...
Name: message, dtype: object
# print message text for the false negatives (spam incorrectly classified as ham)
X_test[y_test > y_pred_class]
1777 Call FREEPHONE 0800 542 0578 now!
763 Urgent Ur £500 guaranteed award is still uncla...
3132 LookAtMe!: Thanks for your purchase of a video...
1875 Would you like to see my XXX pics they are so ...
1893 CALL 09090900040 & LISTEN TO EXTREME DIRTY LIV...
4298 thesmszone.com lets you send free anonymous an...
4394 RECPT 1/3. You have ordered a Ringtone. Your o...
4949 Hi this is Amy, we will be sending you a free ...
761 Romantic Paris. 2 nights, 2 flights from £79 B...
19 England v Macedonia - dont miss the goals/team...
2821 INTERFLORA - “It's not too late to order Inter...
2247 Hi ya babe x u 4goten bout me?' scammers getti...
4514 Money i have won wining number 946 wot do i do...
Name: message, dtype: object
# example false negative
X_test[3132]
"LookAtMe!: Thanks for your purchase of a video clip from LookAtMe!, you've been charged 35p. Think you can do better? Why not send a video in a MMSto 32323."
# calculate predicted probabilities for X_test_dtm (poorly calibrated)
y_pred_prob = clf.predict_proba(X_test_dtm)[:, 1]
y_pred_prob
array([9.90605780e-07, 4.03318013e-09, 1.38284780e-07, ...,
6.48404534e-06, 1.00000000e+00, 3.77161160e-09])
# calculate AUC
metrics.roc_auc_score(y_test, y_pred_prob)
0.9932611419366387
逻辑回归的优势:
它能处理非线性效应
它可以为每个类生成概率分数,这使得解释变得容易
逻辑回归的缺点:
此分类技术仅用于二进制分类。如果要将数据分类为两个以上的类别,我们可以使用其他算法。我们可以使用随机森林和决策树等算法将数据分类为两个以上的类别。
如果你提供了大量的特征作为这个算法的输入,那么特征空间就会增加,这个算法的性能就不好了。
过度拟合的可能性很高,这意味着分类器在训练数据集上表现良好,但不能进行足够的归纳,从而能够预测未知数据的正确目标标签。
决策树
决策树是最古老的ML算法之一。这个算法很简单,但很健壮。这个算法为我们提供了一个树结构来做任何决定。逻辑回归用于二进制分类,但如果有两个以上的类,则可以使用决策树。
让我们通过一个例子来理解决策树。假设克里斯喜欢风帆冲浪,但他有自己的喜好——他通常喜欢晴天和有风的天气来享受它,也不喜欢在下雨天或阴天或风小的日子冲浪。参见图8.26:
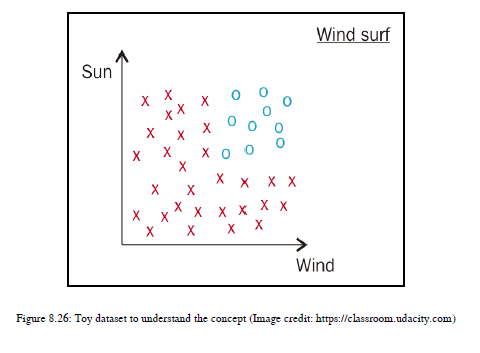
如你所见,O(圆点)是克里斯喜欢风浪的好天气条件,X(十字)是克里斯不喜欢风浪的坏天气条件。
我所绘制的数据不是线性可分的,这意味着你不能仅仅用一条线来区分红色十字和蓝色圆点。你可能会认为,如果目标只是把蓝点和红十字分开,那么我可以用两条线来实现这一点。然而,一条线能把蓝点和红十字分开吗?答案是否定的,这就是为什么我告诉你这个数据集不能线性分离的原因。因此对于这种情况,我们将使用决策树。
决策树实际上为您做了什么?用外行的术语来说,决策树学习实际上是关于提出多个线性问题。让我们理解我所说的线性问题。
假设我们问一个问题:有风吗?你有两个答案:是或否。我们有一个与风有关的问题,所以我们需要集中在图8.26的X轴上。如果我们的答案是:是的,有风,那么我们应该考虑右手边有红十字和蓝点的区域;如果我们回答:不是,没有风,那么我们需要考虑左手边所有的红十字。为了更好地理解,您可以参考图8.27:
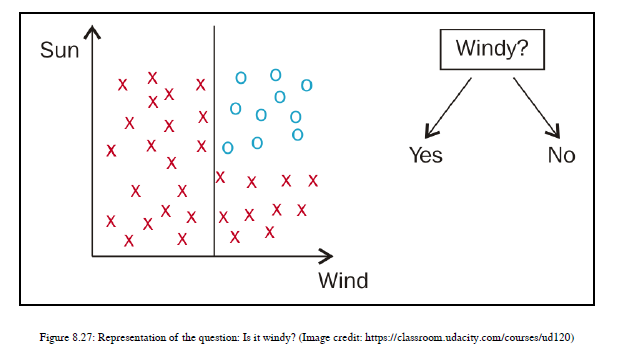
如图8.27所示,我画了一条穿过x轴中点的线。我刚刚选择了一个中点,没有具体的原因。所以我画了一条黑线。行左侧的红色十字表示:不,没有风,行右侧的红色十字表示:有风。在这条线的左边,只有红色的十字,没有一个蓝色的点。如果你选择了答案,不,那么实际上你是用标记为“否”的分支进行遍历的。左侧的区域只有红色交叉,因此你最终得到了属于同一类的所有数据点,这些数据点用红色交叉表示,你不会再为该树的分支提出进一步的问题。现在,如果您选择答案,是的,那么我们需要将焦点放在右侧的数据点上。您可以看到有两种类型的数据点,蓝点和红十字。所以,为了对它们进行分类,你需要提出一个线性边界,这样由直线组成的部分只有一种数据点,我们将通过问另一个问题来实现这一点:天气晴朗吗?这一次,再一次,你有两个可能的答案-是或否。记住,我已经遍历了树的分支,它以是的形式回答了我们的第一个问题。所以我的重点是在数据点的右边,因为在那里我有以红十字和蓝点的形式表示的数据点。我们已经在y轴上描述了太阳,所以你需要看看这个轴,如果你画一条线穿过y轴的中点,那么线上面的部分代表答案,是的,这是一个晴天。线下的所有数据点代表答案,不,这不是晴天。当您绘制这样一条线并停止在第一条线之后延伸该线时,您可以成功地分离位于右侧的数据点。所以线上方的部分只包含蓝点,线下方的部分,红色十字。您可以看到水平线,如图8.28所示:
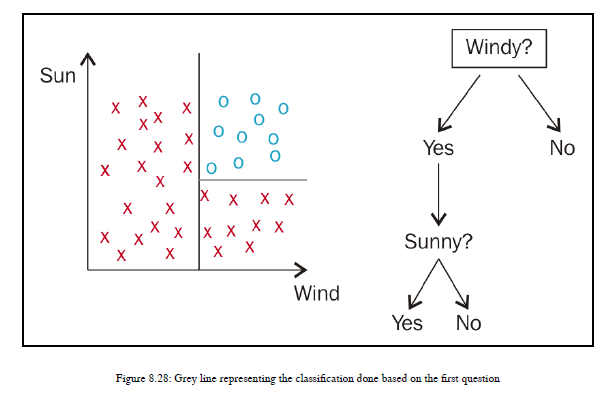
我们可以观察到,通过问一系列问题或一系列线性问题,我们实际上将表示克里斯不冲浪的红色十字和表示克里斯冲浪的蓝色圆点分类。
这是一个非常基本的示例,可以帮助您了解决策树如何处理分类问题。在这里,我们通过问一系列问题以及生成多个线性边界来分类数据点来构建树。让我们举一个数字例子,这样你就能更清楚地看到它了。参见图8.29:
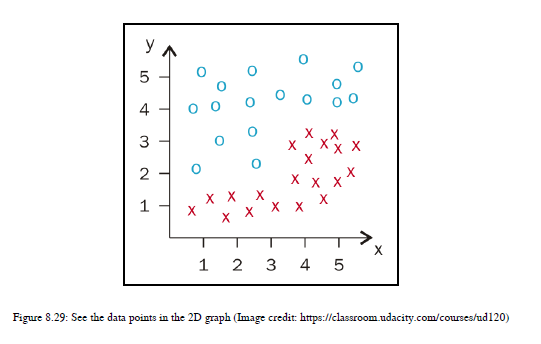
您可以看到给定的数据点。我们先从x轴开始。您希望选择X轴上的哪个阈值,以便获得这些数据点的最佳分割?想一想!我想选择一条在点3通过x轴的线。现在有两个部分。在数学上,我选择了给定数据点的最佳分割,即x<=3和x>3。参见图8.30:
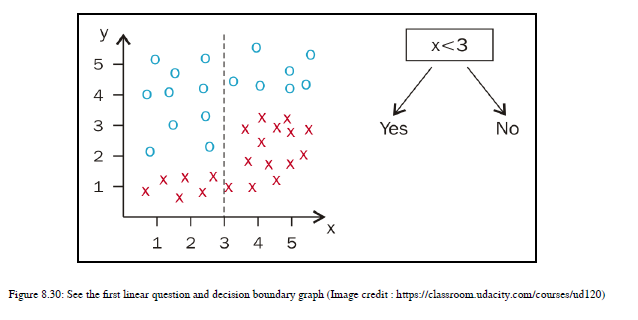
我们先看一下左侧部分。您希望选择Y轴上的哪个值,以便在绘制该线后在一个区域中只有一种类型的数据点?您选择的Y轴上的阈值是多少,以便在一个部分中有一种类型的数据集,而在另一个部分中有另一种类型的数据集?我将选择穿过Y轴上点2的线。因此,线上方的数据点属于一个类,线下方的数据点属于另一个类。数学上,y<=2给你一个类,y>2给你另一个类。参见图8.31:
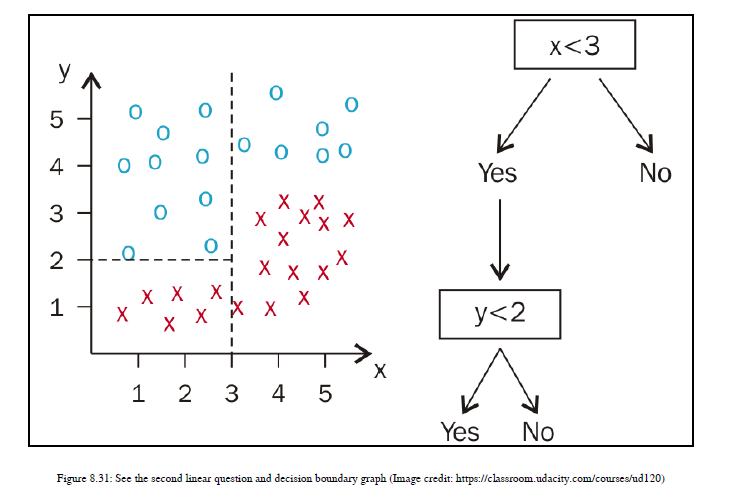
现在集中在右侧部分;对于该部分,我们还需要选择相对于Y轴的阈值。这里,分离边界的最佳阈值是y=4,因此截面y<4只有红色十字,截面y>=4只有蓝色点。最后,通过一系列线性问题,我们能够对数据点进行分类。参见图8.32:
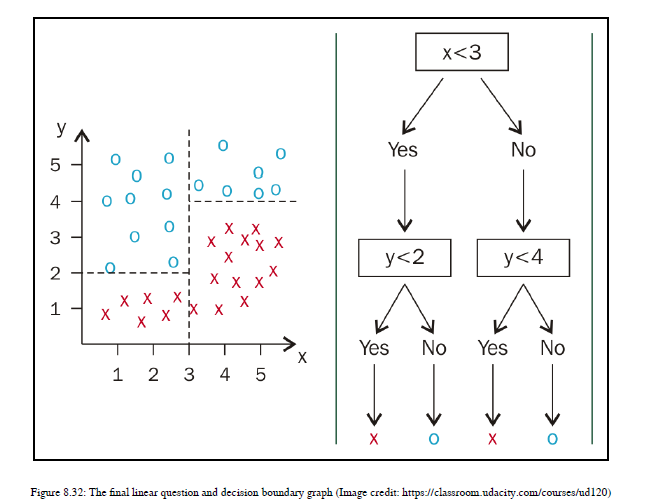
现在你对算法有了一个概念,但是你的脑子里可能有几个问题。我们对获取行进行了可视化,但是决策树算法如何选择最佳的方法来分割数据点并使用给定的特征生成决策边界?假设我有两个以上的特征,比如说十个特性;那么决策树如何知道它需要在第一次使用第二个特性而不是第三个特性?所以我将通过解释决策树背后的数学来回答所有这些问题。我们将查看一个与NLP相关的示例,这样您就可以了解如何在NLP应用程序中使用决策树。
我有一些关于决策树的问题,让我们逐一回答。我们将使用可视化来获得一个线性边界,但是决策树如何识别使用哪些特征以及应该分割数据的哪些特征值?让我们看看熵这个数学术语。因此,决策树使用熵的概念来决定在哪里分割数据。让我们了解熵。熵是一个树分支中杂质的度量,因此,如果一个树分支中的所有数据点都属于同一类,那么熵e=0;否则,熵e>0,e<1。如果熵e=1,则表示树的分支高度不纯,或者数据点在所有可用类之间平均分配。让我们看一个例子,这样你就能理解熵和杂质的概念。我们正在开发一个垃圾邮件过滤应用程序,我们有一个特性,即单词和短语类型。现在我们将介绍另一个特性,即数据集中出现的短语的最小阈值计数。参见图8.33:
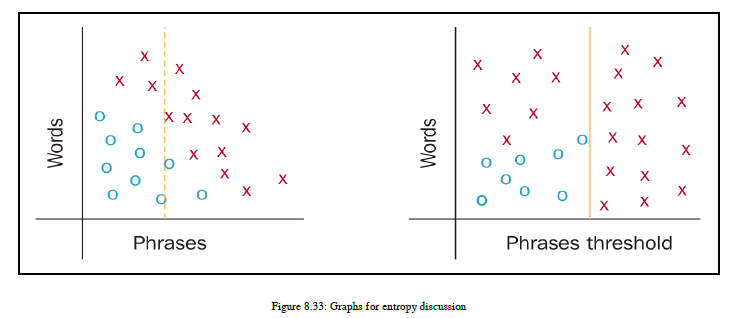
现在关注右边的图表。在这个图中,右侧部分只有一种数据点,用红色十字表示。所以从技术上讲,所有的数据点都是同质的,因为它们属于同一个类。因此,没有杂质,熵的值约为零。现在,如果您将焦点放在左侧图表上并查看其右侧部分,您将找到属于其他类标签的数据点。这部分含有杂质,因此熵很高。因此,在实现决策树的过程中,您需要找出可用于定义分割点的变量以及变量。您需要记住的另一件事是,您正试图最小化数据中的杂质,因此请尝试根据这些数据拆分数据。我们将看到如何在一段时间内选择变量来执行拆分。现在,让我们先看看熵的数学公式。参见图8.34:
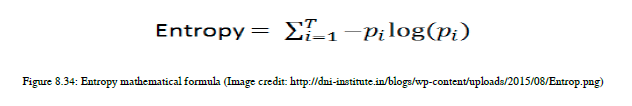
让我们看看圆周率是什么。它是给定类的分数值。假设我是班上的学生。t是可用类的总值。您有四个数据点;如果两个点属于A类,另两个点属于B类,则t=2。我们在使用分数值生成日志值后执行求和。现在是时候对熵进行数学计算了,然后我将告诉您如何使用熵对变量或特性执行拆分。我们来看一个计算熵的例子。您可以找到图8.35中的示例:
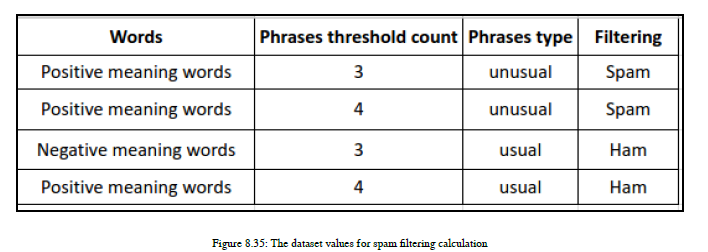
如果您关注过滤列,那么您有两个值为spam的标签和两个值为ssh的ham。现在回答以下几个问题:我们总共有多少数据行?答案是4
数据标签在筛选列中出现多少次?答案是2
数据标签H在筛选列中出现多少次?答案是2
要为类标签s生成分数值,需要执行数学运算使用以下公式:pS = No. of time S occurred / Total no. of data rows = 2/4 = 0.5
现在我们还需要计算h的p:pH = No. of time H occurred / Total no. of data rows = 2/4 = 0.5
现在我们有了产生熵的所有必要值。
专注于公式:Entropy = -pS* log2(pS) -pHlog2(pH) = -0.5 * log(0.5) -0.5log(0.5) = 1.0
您可以使用python的数学模块进行计算。如你所见,我们得到熵e=1。这是最不纯净的状态,数据均匀地分布在可用的类中。因此,熵告诉我们数据的状态,不管类是否处于不纯状态。
现在我们来看看最期待的问题:我们如何知道在哪一个变量上或者使用哪一个特性来执行分割?要理解这一点,我们需要了解信息获取。这是决策树算法的核心概念之一。让我介绍一下信息获取(ig)的公式:
信息增益(ig)=熵(父节点)-[权重平均值]熵(子节点)现在我们来看看这个公式。我们正在计算父节点的熵,并减去子节点的加权熵。如果在父节点上执行拆分,决策树将尝试最大化信息获取。使用ig,决策树将选择我们需要对其执行拆分的功能。该计算针对所有可用的特性进行,因此决策树确切知道要在哪里进行拆分。您需要参考图8.33。
我们计算了父节点的熵:e(父节点)=1。现在我们将关注单词并计算ig。让我们检查一下是否应该使用带ig的words执行split。在这里,我们将重点放在单词栏。所以,让我回答一些问题,以便您理解ig的计算:一共有多少个肯定意义的词?答案是3
一共有多少个否定意义的词?答案是1
所以,对于这个分支,熵e=0。当我们计算子节点的加权平均熵时,我们将使用这个方法。你可以看到,对于右边的节点,熵是零,所以分支中没有任何杂质,所以我们可以停在那里。但是,如果您查看左侧节点,它具有ssh类,因此我们需要计算每个类标签的熵。让我们一步一步地为左侧节点执行此操作:
ps=分支中S标签的数量/分支中示例的总数=2/3
ph=分支中H标签的数量/分支中示例的总数=1/3
现在熵e=-2/3 log2(2/3)-1/3 log2(1/3)=0.918
在下一步中,我们需要计算子节点的加权平均熵。
我们有三个数据点作为左侧分支的一部分,一个数据点作为右侧分支,如图8.36所示。因此,值和公式如下:
子级权重平均熵=左侧分支数据点/数据点总数*(该分支中的子级熵)+右侧分支数据点/数据点总数*(该分支中的子级熵)
儿童体重平均熵=[体重平均]熵(儿童)=¾0.918+¼(0)=0.6885
现在是时候获得免疫球蛋白了:
ig=熵(父节点)-[权重平均值]熵(子节点)。我们两个部分的us-e(父节点)=1和[权重平均]熵(子节点)=0.6885
因此,最终计算如下:
ig=1-0.6885=0.3115
让我们集中讨论短语出现计数列,并计算短语计数值3的熵,即ethree(3)=1.0,短语计数值4的熵为efour(4)=1.0;现在
[权重平均]熵(子项)=1.0,ig=1.0-1.0=0。所以,我们并没有得到任何关于这个特性拆分的信息。所以,我们不应该选择这个特性。
现在,让我们集中讨论短语列,其中我们提到了短语类别异常短语或常用短语。当我们使用此列拆分数据点时,我们得到一个分支中的垃圾邮件类和另一个分支中的ham类。所以这里,你需要自己计算ig,但是ig=1。我们得到最大的免疫球蛋白。因此,我们将为分割选择此功能。您可以在图8.37中看到决策树:
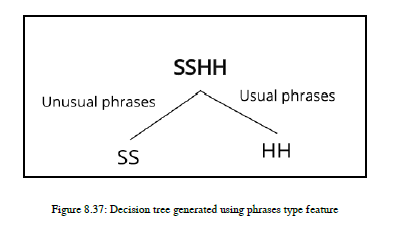
如果您有大量的特性,那么决策树执行培训非常缓慢,因为它为每个特性计算ig,并通过选择提供最大ig的特性来执行拆分。现在是时候看一下使用决策树的NLP应用程序了。我们将重新开发垃圾邮件过滤,但这次,我们将使用决策树。我们只需更改垃圾邮件过滤应用程序的算法,我们采用了之前生成的相同功能集,这样您就可以比较逻辑回归和垃圾邮件过滤决策树的结果。在这里,我们将使用由scikit-learn.学习中的CountVectorizer API生成的相同功能。
import pandas as pd
import numpy as np
# read file into pandas using a relative path
path = 'sms.tsv'
sms = pd.read_table(path, header=None, names=['label', 'message'])
# examine the shape
sms.shape
(5572, 2)
# examine the first 10 rows
sms.head(10)
| label | message | |
|---|---|---|
| 0 | ham | Go until jurong point, crazy.. Available only ... |
| 1 | ham | Ok lar... Joking wif u oni... |
| 2 | spam | Free entry in 2 a wkly comp to win FA Cup fina... |
| 3 | ham | U dun say so early hor... U c already then say... |
| 4 | ham | Nah I don't think he goes to usf, he lives aro... |
| 5 | spam | FreeMsg Hey there darling it's been 3 week's n... |
| 6 | ham | Even my brother is not like to speak with me. ... |
| 7 | ham | As per your request 'Melle Melle (Oru Minnamin... |
| 8 | spam | WINNER!! As a valued network customer you have... |
| 9 | spam | Had your mobile 11 months or more? U R entitle... |
# examine the class distribution
sms.label.value_counts()
ham 4825
spam 747
Name: label, dtype: int64
# convert label to a numerical variable
sms['label_num'] = sms.label.map({'ham':0, 'spam':1})
# check that the conversion worked
sms.head(10)
| label | message | label_num | |
|---|---|---|---|
| 0 | ham | Go until jurong point, crazy.. Available only ... | 0 |
| 1 | ham | Ok lar... Joking wif u oni... | 0 |
| 2 | spam | Free entry in 2 a wkly comp to win FA Cup fina... | 1 |
| 3 | ham | U dun say so early hor... U c already then say... | 0 |
| 4 | ham | Nah I don't think he goes to usf, he lives aro... | 0 |
| 5 | spam | FreeMsg Hey there darling it's been 3 week's n... | 1 |
| 6 | ham | Even my brother is not like to speak with me. ... | 0 |
| 7 | ham | As per your request 'Melle Melle (Oru Minnamin... | 0 |
| 8 | spam | WINNER!! As a valued network customer you have... | 1 |
| 9 | spam | Had your mobile 11 months or more? U R entitle... | 1 |
# how to define X and y (from the SMS data) for use with COUNTVECTORIZER
X = sms.message
y = sms.label_num
print(X.shape)
print(y.shape)
(5572,)
(5572,)
# split X and y into training and testing sets
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
(4179,)
(1393,)
(4179,)
(1393,)
# import and instantiate CountVectorizer (with the default parameters)
from sklearn.feature_extraction.text import CountVectorizer
# instantiate the vectorizer
vect = CountVectorizer()
# learn training data vocabulary, then use it to create a document-term matrix
vect.fit(X_train)
X_train_dtm = vect.transform(X_train)
# equivalently: combine fit and transform into a single step
X_train_dtm = vect.fit_transform(X_train)
# examine the document-term matrix
X_train_dtm
<4179x7456 sparse matrix of type '<class 'numpy.int64'>'
with 55209 stored elements in Compressed Sparse Row format>
# transform testing data (using fitted vocabulary) into a document-term matrix
X_test_dtm = vect.transform(X_test)
X_test_dtm
<1393x7456 sparse matrix of type '<class 'numpy.int64'>'
with 17604 stored elements in Compressed Sparse Row format>
from sklearn import tree
clf = tree.DecisionTreeClassifier(criterion='entropy')
# train the model using X_train_dtm (timing it with an IPython "magic command")
%timeit clf.fit(X_train_dtm, y_train)
10 loops, best of 3: 169 ms per loop
# make class predictions for X_test_dtm
y_pred_class = clf.predict(X_test_dtm)
# calculate accuracy of class predictions
from sklearn import metrics
metrics.accuracy_score(y_test, y_pred_class)
0.9655419956927495
# print the confusion matrix
metrics.confusion_matrix(y_test, y_pred_class)
array([[1182, 26],
[ 22, 163]])
# print message text for the false positives (ham incorrectly classified as spam)
X_test[y_test < y_pred_class]
1827 Dude. What's up. How Teresa. Hope you have bee...
1973 Yes but can we meet in town cos will go to gep...
3242 Ok i've sent u da latest version of da project.
1791 Am not working but am up to eyes in philosophy...
2900 Aight, I should be there by 8 at the latest, p...
2497 HCL chennai requires FRESHERS for voice proces...
745 Men like shorter ladies. Gaze up into his eyes.
2340 Cheers for the message Zogtorius. I’ve been st...
1832 Hello- thanx for taking that call. I got a job...
566 Ill call u 2mrw at ninish, with my address tha...
858 Hai ana tomarrow am coming on morning. <DE...
3544 I'm e person who's doing e sms survey...
987 I'm in office now . I will call you <#>...
705 True dear..i sat to pray evening and felt so.s...
988 Geeee ... I miss you already, you know ? Your ...
5336 Sounds better than my evening im just doing my...
100 Please don't text me anymore. I have nothing e...
1364 Yetunde, i'm sorry but moji and i seem too bus...
4092 Hey doc pls I want to get nice t shirt for my ...
4766 if you text on your way to cup stop that shoul...
5094 Hi Shanil,Rakhesh here.thanks,i have exchanged...
3826 Hi. I'm always online on yahoo and would like ...
3237 Aight text me when you're back at mu and I'll ...
4814 i can call in <#> min if thats ok
4958 I'm vivek:)i got call from your number.
330 I'm reading the text i just sent you. Its mean...
Name: message, dtype: object
# print message text for the false negatives (spam incorrectly classified as ham)
X_test[y_test > y_pred_class]
3642 You can stop further club tones by replying "S...
1777 Call FREEPHONE 0800 542 0578 now!
2680 New Tones This week include: 1)McFly-All Ab..,...
763 Urgent Ur £500 guaranteed award is still uncla...
4574 URGENT! This is the 2nd attempt to contact U!U...
881 Reminder: You have not downloaded the content ...
3132 LookAtMe!: Thanks for your purchase of a video...
2514 U have won a nokia 6230 plus a free digital ca...
5 FreeMsg Hey there darling it's been 3 week's n...
3530 Xmas & New Years Eve tickets are now on sale f...
4768 Your unique user ID is 1172. For removal send ...
4298 thesmszone.com lets you send free anonymous an...
1734 Hi, this is Mandy Sullivan calling from HOTMIX...
4949 Hi this is Amy, we will be sending you a free ...
761 Romantic Paris. 2 nights, 2 flights from £79 B...
3230 Ur cash-balance is currently 500 pounds - to m...
579 our mobile number has won £5000, to claim call...
3564 Auction round 4. The highest bid is now £54. N...
2863 Adult 18 Content Your video will be with you s...
2247 Hi ya babe x u 4goten bout me?' scammers getti...
4514 Money i have won wining number 946 wot do i do...
789 5 Free Top Polyphonic Tones call 087018728737,...
Name: message, dtype: object
# example false negative
X_test[761]
'Romantic Paris. 2 nights, 2 flights from £79 Book now 4 next year. Call 08704439680Ts&Cs apply.'
# calculate predicted probabilities for X_test_dtm (poorly calibrated)
y_pred_prob = clf.predict_proba(X_test_dtm)[:, 1]
y_pred_prob
array([0., 0., 0., ..., 0., 1., 0.])
# calculate AUC
metrics.roc_auc_score(y_test, y_pred_prob)
0.929778951136567
如你所见,与逻辑回归相比,我们的精确度较低。现在是时候看一些可以用来提高ML模型精度的调整参数了。
可调参数
scikit-learn学习中有一个参数,这就是标准。你可以把它设置为熵或者基尼。熵或基尼被用来计算ig。因此,它们都有一个相似的机制来计算ig,决策树将根据熵或基尼给出的ig计算来执行分割。
有最小样本大小,其默认值为2。因此,决策树分支将被拆分,直到每个分支的数据元素多于或等于两个。有时,决策树会试图拟合最大的训练数据,并过度拟合训练数据点。为了防止过拟合,您需要将最小样本尺寸从2增加到50或60。
我们可以使用树木修剪技术,为此我们将采用自下而上的方法。
决策树的优点
决策树简单易开发
决策树很容易被人理解,是一种白盒算法
它帮助我们确定不同情况下的最差、最佳和预期值
决策树的缺点
如果您有很多特性,那么决策树可能有过拟合问题。
在训练过程中,你需要注意你通过的参数
随机森林
该算法是解决过拟合问题的决策树的一个变种。
随机森林既能发展线性回归,又能发展分类任务,这里我们将重点放在分类任务上。它使用了一个非常简单的技巧,而且效果非常好。关键是随机森林使用投票机制来提高测试结果的准确性。
随机森林算法从训练数据集中生成数据的随机子集,并使用该子集为每个数据子集生成决策树。所有这些生成的树都称为随机林。现在让我们了解投票机制。一旦我们生成了决策树,我们就检查类标签,每个树都是为特定的数据点提供的。假设我们生成了三个随机的森林决策树。其中两个表示某个特定数据点属于A类,第三个决策树预测该特定数据点属于B类,算法考虑了更高的投票数,并为该特定数据点分配了类标签A。对于随机森林,分类的所有计算都类似于决策树。
import nltk
from nltk import word_tokenize
import pprint
from sklearn.tree import DecisionTreeClassifier
from sklearn.feature_extraction import DictVectorizer
from sklearn.pipeline import Pipeline
#tagged_sentences = nltk.corpus.brown.tagged_sents()
tagged_sentences = nltk.corpus.treebank.tagged_sents()
print(tagged_sentences[0])
[('Pierre', 'NNP'), ('Vinken', 'NNP'), (',', ','), ('61', 'CD'), ('years', 'NNS'), ('old', 'JJ'), (',', ','), ('will', 'MD'), ('join', 'VB'), ('the', 'DT'), ('board', 'NN'), ('as', 'IN'), ('a', 'DT'), ('nonexecutive', 'JJ'), ('director', 'NN'), ('Nov.', 'NNP'), ('29', 'CD'), ('.', '.')]
print("Tagged sentences: ", len(tagged_sentences))
Tagged sentences: 3914
print("Tagged words:", len(nltk.corpus.treebank.tagged_words()))
Tagged words: 100676
def features(sentence, index):
" sentence: [w1, w2, ...], index: the index of the word "
return {
'word': sentence[index],
'is_first': index == 0,
'is_last': index == len(sentence) - 1,
'is_capitalized': sentence[index][0].upper() == sentence[index][0],
'is_all_caps': sentence[index].upper() == sentence[index],
'is_all_lower': sentence[index].lower() == sentence[index],
'prefix-1': sentence[index][0],
'prefix-2': sentence[index][:2],
'prefix-3': sentence[index][:3],
'suffix-1': sentence[index][-1],
'suffix-2': sentence[index][-2:],
'suffix-3': sentence[index][-3:],
'prev_word': '' if index == 0 else sentence[index - 1],
'next_word': '' if index == len(sentence) - 1 else sentence[index + 1],
'has_hyphen': '-' in sentence[index],
'is_numeric': sentence[index].isdigit(),
'capitals_inside': sentence[index][1:].lower() != sentence[index][1:]
}
pprint.pprint(features(['This', 'is', 'a', 'sentence'], 2))
{'capitals_inside': False,
'has_hyphen': False,
'is_all_caps': False,
'is_all_lower': True,
'is_capitalized': False,
'is_first': False,
'is_last': False,
'is_numeric': False,
'next_word': 'sentence',
'prefix-1': 'a',
'prefix-2': 'a',
'prefix-3': 'a',
'prev_word': 'is',
'suffix-1': 'a',
'suffix-2': 'a',
'suffix-3': 'a',
'word': 'a'}
def untag(tagged_sentence):
return [w for w, t in tagged_sentence]
def transform_to_dataset(tagged_sentences):
X, y = [], []
for tagged in tagged_sentences:
for index in range(len(tagged)):
X.append(features(untag(tagged), index))
y.append(tagged[index][1])
#print "index:"+str(index)+"original word:"+str(tagged)+"Word:"+str(untag(tagged))+" Y:"+y[index]
return X, y
cutoff = int(.75 * len(tagged_sentences))
training_sentences = tagged_sentences[:cutoff]
test_sentences = tagged_sentences[cutoff:]
print(len(training_sentences))
2935
print(len(test_sentences))
979
X, y = transform_to_dataset(training_sentences)
clf = Pipeline([
('vectorizer', DictVectorizer(sparse=False)),
('classifier', DecisionTreeClassifier(criterion='entropy'))
])
%timeit clf.fit(X[:10000],y[:10000]) # Use only the first 10K samples if you're running it multiple times. It takes a fair bit :)
1 loop, best of 3: 14.9 s per loop
print('Training completed')
Training completed
X_test, y_test = transform_to_dataset(test_sentences)
print("Accuracy:", clf.score(X_test, y_test))
Accuracy: 0.8937409609513096
def pos_tag(sentence):
tagged_sentence = []
tags = clf.predict([features(sentence, index) for index in range(len(sentence))])
return zip(sentence, tags)
list(pos_tag(word_tokenize('This is my friend, John.')))
[('This', 'DT'),
('is', 'VBZ'),
('my', 'NN'),
('friend', 'NN'),
(',', ','),
('John', 'NNP'),
('.', '.')]
随机森林的优势
它有助于我们防止过拟合
它既可用于回归,也可用于分类
随机森林的缺点
随机森林模型可以很容易地生长,这意味着如果数据集的随机子集很高,那么我们将得到更多的决策树,因此,我们将得到一组树,也就是可能占用大量内存的决策树林。
对于高维的特征空间,很难解释树的每个节点,尤其是当一个森林中有大量的树时。
朴素贝叶斯
在本节中,我们将了解在许多数据科学应用中大量使用的概率ML算法。我们将使用此算法开发最著名的NLP应用程序情感分析,但在进入应用程序之前,我们将了解朴素贝叶斯算法的工作原理。那么,我们开始吧!朴素的贝叶斯ML算法基于贝叶斯定理。根据这个定理,我们最重要的假设是事件是独立的,这是一个朴素的假设,这就是这个算法被称为朴素贝叶斯的原因。那么,让我给你一个独立事件的概念。在分类任务中,我们有许多特性。如果我们使用朴素的贝叶斯算法,那么我们假设我们要提供给分类器的每个特征都是相互独立的,这意味着类中某个特定特征的存在不会影响任何其他特征。让我们举个例子。你想找出这句话的感悟,很好!你有很多特点,比如词袋、形容词短语等等。即使所有这些特征相互依赖或依赖于其他特征的存在,这些特征所携带的所有属性都独立地贡献了这个句子带有积极情绪的可能性,这就是我们称之为朴素算法的原因。
这个算法非常简单,而且非常强大。如果你有大量的数据,这就非常有效。它可以对两个以上的类进行分类,因此有助于构建一个多类分类器。那么,现在,让我们来看一些点,这些点将告诉我们朴素贝叶斯算法是如何工作的。让我们了解它背后的数学和概率定理。
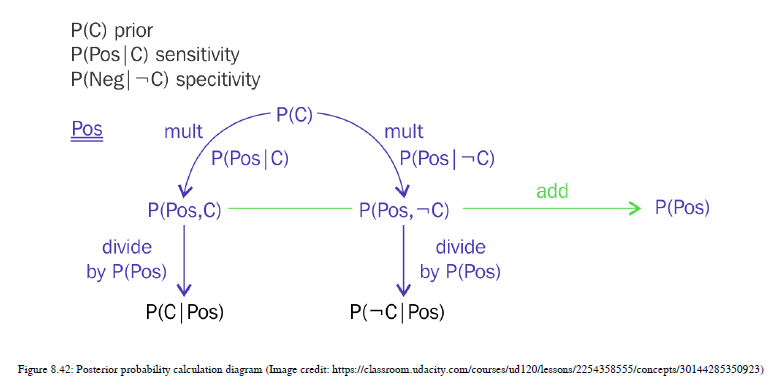
我们将首先理解贝叶斯规则。在非常简单的语言中,您有一些事件的先验概率,并且您在测试数据中发现了相同事件的一些证据,并将它们相乘。然后你得到后验概率,帮助你得到最终的预测。别担心术语,我们会详细讨论这些细节的。让我先给你一个方程,然后我们举一个例子,这样你就知道我们需要做的计算是什么。如图8.41所示

这里,p(c|x)是C类的概率,c类是目标,x是特征或数据属性。p(c)是C类的先验概率,p(x|c)是对给定目标类的预测概率的似然估计,p(x)是预测概率的先验概率。让我们用这个方程来计算一个例子。假设有一个医学测试可以帮助确定一个人是否患有癌症。患这种特定类型癌症的人的先前概率只有1%,这意味着p(c)=0.01=1%,因此p(而非c)=0.99=99%。如果患者患有癌症,有90%的几率检测结果呈阳性。因此,p(阳性|c)=0.9=90%的先验概率,10%的概率,即使患者没有癌症,结果仍然显示阳性,所以p(阴性|c)=0.1=10%。现在,我们需要检查这个人是否真的得了癌症。如果结果为阳性,则概率写为p(c阳性),如果患者没有癌症,但结果仍然为阳性,则表示为p(c阴性)。我们需要计算这两个概率来推导后验概率。首先,我们需要计算联合概率:
Joint P(c | Positive result) = P© * P(Positive result | c) = 0.01 x 0.9 =0.009
Joint P(not c | Positive result) = P(not c) * P(Positive result | not c) = 0.99 x 0.1 = 0.099
前面的概率称为联合概率。这将有助于推导最终后验概率。为了得到后验概率,我们需要应用归一化。
P (Positive result) = P(c | Positive result) + P ( not c | Positive result) = 0.009 +0.099 = 0.108
现在实际后验概率如下:
Posterior probability of P( not c | Positive result) = joint probability of P(not c | Positive result) / P
(Positive result) = 0.099 / 0.108 = 0.916
如果你把p的后验概率P(c | Positive result) +加上p的后验概率P(not c| Positive result),应为=1。在这种情况下,它的总和是1。
有很多数学在进行,所以我会给你画一个图表,帮助你理解这些事情。参见图8.42:
我们将把这个概念扩展到一个NLP应用程序。这里,我们将以一个基于NLP的基本示例为例。假设有两个人——克里斯和萨拉。我们有克里斯和萨拉的电子邮件详细信息。他们都使用诸如生活、爱情和交易之类的词。为了简单起见,我们只考虑三个词。他们都以不同的频率使用这三个词。
克里斯在邮件中只使用了1%的时间“爱”这个词,而他使用“交易”这个词的时间占80%,而“生活”的时间占1%。另一方面,萨拉使用“爱”这个词的时间占50%,交易时间占20%,生活时间占30%。如果我们有新的电子邮件,那么我们需要决定它是由克里斯还是萨拉写的。p的先验概率(chris)=0.5,p(sara)=0.5。
邮件中有句话“生命交易”,所以概率计算是针对p(Chris“生命交易”)=p(Life)*p(Deal)*p(Chris)=0.04,而计算p(Sara“生命交易”)=p(Life)*p(Deal)*p(Sara)=0.03。现在,让我们应用规范化并生成实际概率,为此,我们需要计算联合概率=P(Chris“Life Deal”)+P(Sara“Life Deal”)=0.07。以下是实际概率值:
P(Chris| “Life Deal”) = 0.04 / 0.07 = 0.57
P(Sara| “Life Deal”) = 0.03 / 0.07 = 0.43
“生命交易”这个句子更有可能是克里斯写的。本例到此结束,现在是实际实施的时候了。在这里,我们正在开发最著名的NLP应用程序,即情感分析。我们将对文本数据进行情绪分析,这样我们就可以说情绪分析是对人类产生的观点进行的文本分析。情绪分析帮助我们分析客户对某个产品或事件的看法。
对于情绪分析,我们将使用“词语袋”方法。你也可以使用人工神经网络,但我解释的是一种简单而基本的方法。
import sys
import os
import time
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import classification_report
data_dir = "data"
classes = ['pos', 'neg']
# Read the data
train_data = []
train_labels = []
test_data = []
test_labels = []
for curr_class in classes:
dirname = os.path.join(data_dir, curr_class)
for fname in os.listdir(dirname):
with open(os.path.join(dirname, fname), 'r') as f:
content = f.read()
if fname.startswith('cv9'):
test_data.append(content)
test_labels.append(curr_class)
else:
train_data.append(content)
train_labels.append(curr_class)
# Create feature vectors
vectorizer = TfidfVectorizer(min_df=5,
max_df = 0.8,
sublinear_tf=True,
use_idf=True)
train_vectors = vectorizer.fit_transform(train_data)
test_vectors = vectorizer.transform(test_data)
d:\Program Files\Anaconda3\lib\site-packages\sklearn\feature_extraction\text.py:1059: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
if hasattr(X, 'dtype') and np.issubdtype(X.dtype, np.float):
clf = MultinomialNB()
%time clf.fit(train_vectors, train_labels)
Wall time: 7 ms
MultinomialNB(alpha=1.0, class_prior=None, fit_prior=True)
%time prediction = clf.predict(test_vectors)
Wall time: 1 ms
# Print results in a nice table
print("Results for NaiveBayes (MultinomialNB) ")
print(classification_report(test_labels, prediction))
Results for NaiveBayes (MultinomialNB)
precision recall f1-score support
neg 0.81 0.92 0.86 100
pos 0.91 0.78 0.84 100
avg / total 0.86 0.85 0.85 200
-
可调参数
对于此算法,有时需要应用平滑。现在,平滑是什么意思?让我给你一个简单的想法。训练数据中有一些词,我们的算法使用这些数据生成一个ML模型。如果ML模型看到的单词不在训练数据中,而是出现在测试数据中,那么此时,我们的算法不能很好地预测事情。我们需要解决这个问题。因此,作为一个解决方案,我们需要应用平滑,这意味着我们也在计算稀有词的概率,这是scikit-learn学习中的可调参数。它只是一个标志——如果启用它,它将执行平滑;如果禁用它,则不会应用平滑。 -
朴素贝叶斯的优势
可以使用朴素贝叶斯算法处理高维特征空间
它可用于对两个以上的类进行分类 -
朴素贝叶斯的缺点
如果你有一个由不同的词组成的词组有不同的意思,那么这个算法将不会帮助你。你有一句话,古吉拉特狮子。这是板球队的名字,但古吉拉特邦是印度的一个州,狮子是一种动物。因此,朴素贝叶斯算法将单个单词单独解释,因此该算法无法正确解释古吉拉特邦狮子。
如果一些分类数据只出现在测试数据集中,而不出现在训练数据中,那么朴素贝叶斯就不会对此提供预测。所以,为了解决这类问题,我们需要应用平滑技术。
现在是时候看看最后的分类算法了,支持向量机。
支持向量机
这是我们将在本章中看到的最后一个但不是最不受监督的ML算法。它被称为支持向量机(SVM)。该算法用于分类任务和回归任务。该算法也适用于多类分类任务。
SVM获取标记的数据,并试图通过使用一条称为超平面的线将数据点分离来对其进行分类。目标是获得一个最佳的超平面,用于对现有的和新的,未发现的例子进行分类。如何获得一个最佳超平面是我们将要理解的。
首先让我们了解最优超平面这个术语。我们需要以这样一种方式获得超平面:获得的超平面最大化到所有类的最近点的距离,这个距离称为边界。这里,我们将讨论一个二进制分类器。边界是超平面(或直线)与两个类中任何一个类的最近点之间的距离。SVM试图使利润最大化。参见图8.45:
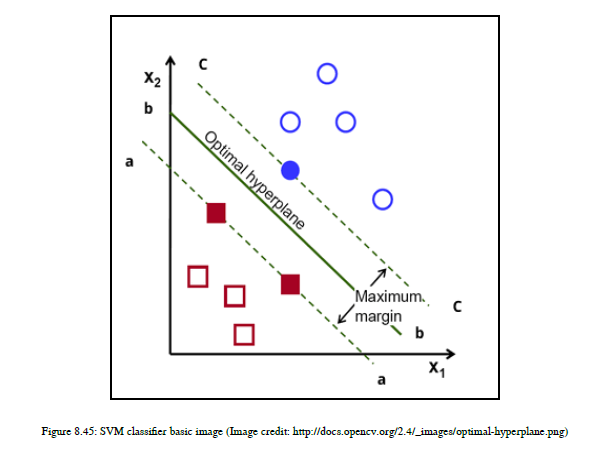
在给定的图中,有三行A、B和C。现在,选择您认为最能分隔数据点的行。我会选择B行,因为它最大化了两个类的边界,而其他A行和C行不这样做。
请注意,SVM首先尝试完美地执行分类任务,然后尝试最大化利润。因此,对于SVM来说,正确地执行分类任务是第一要务。支持向量机既能获得线性超平面,又能生成非线性超平面。那么,让我们理解这背后的数学原理。如果你有n个特征,那么使用SVM,你可以画出n-1维超平面。如果你有一个二维特征空间,那么你可以画一个一维的超平面。
如果有三维特征空间,则可以绘制二维超平面。在任何ML算法中,我们实际上都尝试最小化损失函数,因此我们首先定义SVM的损失函数。SVM使用铰链损失功能。我们使用这个损失函数,试图将我们的损失降到最低,并获得超平面的最大裕度。铰链损失函数方程如下:
C (x, y, f(x)) = (1 - y * f(x))+
这里,x是样本数据点,y是真标签,f(x)是预测标签,c是损失函数。方程中的+符号表示的是,当我们计算y*f(x)并且它大于等于1时,我们试图从1中减去它,得到一个负值。我们不想这样,所以为了表示这一点,我们把+号放在:
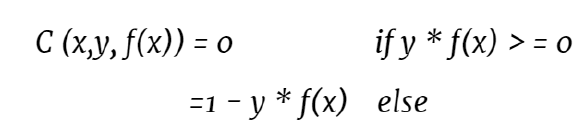
现在是时候定义接受损失函数的目标函数,以及一个名为正则化项的lambda项。我们会看到它对我们有什么作用。但是,它也是一个调整参数。数学方程见图8.46:
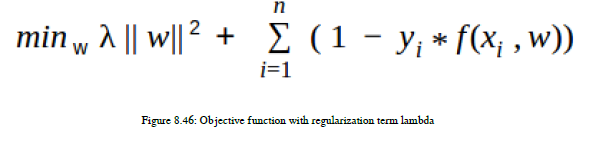
SVM有两个我们需要注意的调整参数。其中一个术语是lambda,它表示正则化术语。如果正则化项太高,那么我们的ML模型就过拟合,不能推广未看到的数据。如果它太低,那么它的下溢,我们会得到一个巨大的训练误差。所以,我们也需要一个正则化项的精确值。我们需要注意有助于防止过度拟合的正则化条件,我们需要将损失最小化。因此,我们对这两个项都取偏导数,下面是正则化项和损失函数的导数,我们可以用它们来进行梯度下降,这样我们可以最小化损失,得到一个准确的正则化值。偏导数方程见图8.47:
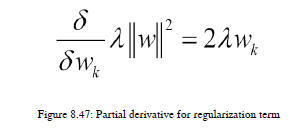
损失函数的偏导数如图8.48所示:
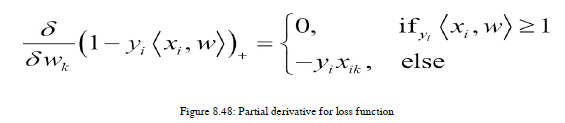
我们需要计算偏导数的值,并相应地更新权重。如果我们错误地分类了数据点,那么我们需要使用下面的公式来更新权重。参见图8.49:
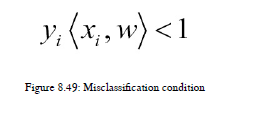
因此,如果y<1,那么我们需要使用图8.50中的以下方程:
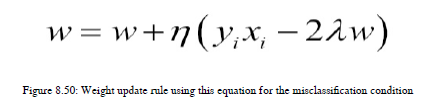
在这里,长n形被称为eta,它表示学习率。学习速率是一个调整参数,它可以显示算法的运行速度。这也需要一个准确的值,因为如果它太高,那么训练将完成得太快,算法将错过全局最小值。另一方面,如果速度太慢,那就需要太多的时间来训练,而且可能永远不会收敛。如果发生错误分类,那么我们需要更新我们的损失函数以及正则化项。
现在,如果算法正确地对数据点进行分类呢?在这种情况下,我们不需要更新损失函数;我们只需要更新我们的正则化参数,您可以使用图8.51中给出的方程看到:
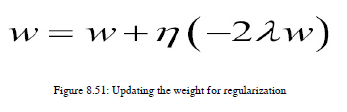
当我们有一个适当的正则化值和全局极小值时,我们就可以对支持向量机中的所有点进行分类,此时,边缘值也成为最大值。
如果要使用SVM进行非线性分类器,则需要应用内核技巧。简单地说,内核技巧就是将较低的特征空间转换为较高的特征空间,从而引入非线性属性,以便对数据集进行分类。如图8.52所示:
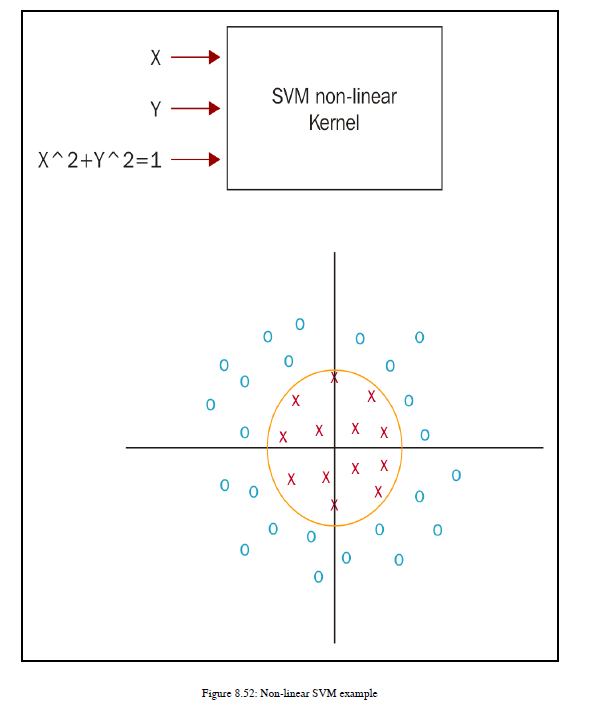
为了对这些数据进行分类,我们有X,Y特征。我们引入了新的非线性特征x2+y2,这有助于我们绘制一个能够正确分类数据的超平面。
所以,现在是时候实现SVM算法了,我们将再次开发情感分析应用程序,但这次,我使用的是SVM,看看在准确性上有什么不同。
import sys
import os
import time
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn import svm
from sklearn.metrics import classification_report
data_dir = "data"
classes = ['pos', 'neg']
# Read the data
train_data = []
train_labels = []
test_data = []
test_labels = []
for curr_class in classes:
dirname = os.path.join(data_dir, curr_class)
for fname in os.listdir(dirname):
with open(os.path.join(dirname, fname), 'r') as f:
content = f.read()
if fname.startswith('cv9'):
test_data.append(content)
test_labels.append(curr_class)
else:
train_data.append(content)
train_labels.append(curr_class)
# Create feature vectors
vectorizer = TfidfVectorizer(min_df=5,
max_df = 0.8,
sublinear_tf=True,
use_idf=True)
train_vectors = vectorizer.fit_transform(train_data)
test_vectors = vectorizer.transform(test_data)
# Perform classification with SVM, kernel=rbf
classifier_rbf = svm.SVC()
t0 = time.time()
classifier_rbf.fit(train_vectors, train_labels)
t1 = time.time()
prediction_rbf = classifier_rbf.predict(test_vectors)
t2 = time.time()
time_rbf_train = t1-t0
time_rbf_predict = t2-t1
# Perform classification with SVM, kernel=linear
classifier_linear = svm.SVC(kernel='linear')
t0 = time.time()
classifier_linear.fit(train_vectors, train_labels)
t1 = time.time()
prediction_linear = classifier_linear.predict(test_vectors)
t2 = time.time()
time_linear_train = t1-t0
time_linear_predict = t2-t1
# Perform classification with SVM, kernel=linear
classifier_liblinear = svm.LinearSVC()
t0 = time.time()
classifier_liblinear.fit(train_vectors, train_labels)
t1 = time.time()
prediction_liblinear = classifier_liblinear.predict(test_vectors)
t2 = time.time()
time_liblinear_train = t1-t0
time_liblinear_predict = t2-t1
# Print results in a nice table
print("Results for SVC(kernel=rbf)")
print("Training time: %fs; Prediction time: %fs" % (time_rbf_train, time_rbf_predict))
print(classification_report(test_labels, prediction_rbf))
print("Results for SVC(kernel=linear)")
print("Training time: %fs; Prediction time: %fs" % (time_linear_train, time_linear_predict))
print(classification_report(test_labels, prediction_linear))
print("Results for LinearSVC()")
print("Training time: %fs; Prediction time: %fs" % (time_liblinear_train, time_liblinear_predict))
print(classification_report(test_labels, prediction_liblinear))
d:\Program Files\Anaconda3\lib\site-packages\sklearn\feature_extraction\text.py:1059: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
if hasattr(X, 'dtype') and np.issubdtype(X.dtype, np.float):
Results for SVC(kernel=rbf)
Training time: 8.710498s; Prediction time: 0.945054s
precision recall f1-score support
neg 0.86 0.75 0.80 100
pos 0.78 0.88 0.83 100
avg / total 0.82 0.81 0.81 200
Results for SVC(kernel=linear)
Training time: 7.742443s; Prediction time: 0.762043s
precision recall f1-score support
neg 0.91 0.92 0.92 100
pos 0.92 0.91 0.91 100
avg / total 0.92 0.92 0.91 200
Results for LinearSVC()
Training time: 0.075004s; Prediction time: 0.000000s
precision recall f1-score support
neg 0.92 0.94 0.93 100
pos 0.94 0.92 0.93 100
avg / total 0.93 0.93 0.93 200
-
可调参数
Scikit Learn为内核技巧提供了一个非常有用的调优参数。您可以使用各种类型的内核,如线性、RBF等。
还有其他参数称为c和gamma。
c控制平滑决策边界和正确分类训练点之间的权衡。如果C值较大,则可以获得更正确的训练点。
如果你想设置你的边界,gamma会很有用。如果为gamma设置了较高的值,则只考虑附近的数据点来绘制决策边界;如果gamma的值较低,则也会考虑远离决策边界的点来测量决策边界是否使边界最大化。 -
支持向量机的优点
它在复杂的数据集中表现良好
它可用于多类分类器 -
支持向量机的缺点
当你有一个非常大的数据集时,它不会表现得很好,因为它需要大量的培训时间
当数据太嘈杂时,它将无法有效工作
8.3.2 无监督机器学习方法
这是另一种机器学习算法。当我们没有任何标记的数据时,我们可以使用无监督的机器学习算法。在NLP域中,有一种常见的情况是您找不到标记的数据集,然后这种类型的ML算法就被我们拯救了。
在这里,我们将讨论无监督的ML算法,称为k-均值聚类。这种算法有许多应用。谷歌已经为他们的许多产品使用了这种无监督的学习算法。YouTube视频建议使用聚类算法。
下图将向您介绍如何在无监督的ML算法中表示数据点。参见图8.55:
如图8.55所示,数据点没有与其关联的标签,但从视觉上看,可以看到它们形成了一些组或集群。实际上,我们将尝试使用无监督的ML算法来确定数据中的结构,这样我们就可以对看不见的数据点获得一些卓有成效的见解。
在这里,我们将研究k-means聚类算法,并开发与NLP域相关的文档分类示例。那么,我们开始吧!
k-均值聚类
在本节中,我们将讨论k-均值聚类算法。我们将首先了解算法。k均值聚类采用迭代细化技术。
让我们了解一些关于k均值算法的基础知识。k是指我们要生成多少个集群。现在,您可以选择一个随机点,并将质心放在这个点上。k-均值聚类中的形心数不大于k的值,即不大于聚类值k。
该算法有以下两个步骤,我们需要重申:
1、第一步是指定质心。
2、第二步是计算优化步骤。
为了理解k-means的步骤,我们将看一个例子。您有五个数据点,在表中给出,我们希望将这些数据点分组为两个集群,所以k=2。参见图8.56:
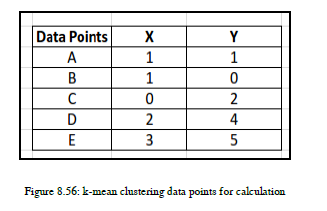
我们选择了点A(1,1)和点C(0,2)来分配我们的质心。这是分配步骤的结束,现在让我们了解优化步骤。
我们将计算从每个点到这个质心的欧几里得距离。欧几里得距离方程如图8.57所示:
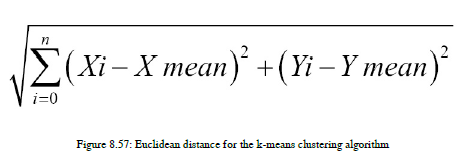
每次我们都需要计算两个质心之间的欧几里得距离。让我们检查一下计算结果。起始质心平均值为c1=(1,1)和c2=(0,2)。这里,我们要做两个星团,这就是我们取两个质心的原因。
迭代1
For point A = (1,1):
C1 = (1,1) so ED = Square root ((1-1)2 + (1-1)2) = 0
C2 = (0,2) so ED = Square root ((1-0)2 + (1-2)2) = 1.41
Here, C1 < C2, so point A belongs to cluster 1.
For point B = (1,0):
C1 = (1,1) so ED = Square root ((1-1)2 + (0-1)2) = 1
C2 = (0,2) so ED = Square root ((1-0)2 + (0-2)2) = 2.23
Here, C1 < C2, so point B belongs to cluster 1.
For point C = (0,2):
C1 = (1,1) so ED = Square root ((0-1)2 + (2-1)2) = 1.41
C2 = (0,2) so ED = Square root ((0-0)2 + (2-2)2) = 0
Here, C1 > C2, so point C belongs to cluster 2.
For point D = (2,4):
C1 = (1,1) so ED = Square root ((2-1)2 + (4-1)2) = 3.16
C2 = (0,2) so ED = Square root ((2-0)2 + (4-2)2) = 2.82
Here, C1 > C2, so point C belongs to cluster 2.
For point E = (3,5):
C1 = (1,1) so ED = Square root ((3-1)2 + (5-1)2)= 4.47
C2 = (0,2) so ED = Square root ((3-0)2 + (5-2)2)= 4.24
Here, C1 > C2, so point C belongs to cluster 2.
在第一次迭代之后,我们的集群看起来如下。cluster c1有点a和b,c2有点c、d和e。因此,这里我们需要根据新的cluster point重新计算质心平均值:
C1 = XA + XB / 2 = (1+1) / 2 = 1
C1 = YA + YB / 2 = (1+0) / 2 = 0.5
So new C1 = (1,0.5)
C2 = Xc + XD + XE / 3 = (0+2+3) / 3 = 1.66
C2 = Yc +YD + YE / 3 = (2+4+5) / 3 = 3.66
So new C2 = (1.66,3.66)
我们需要以和迭代1相同的方式再次进行所有的计算。所以我们得到如下的值。
迭代 2
For point A = (1,1):
C1 = (1,0.5) so ED = Square root ((1-1)2 + (1-0.5)2) = 0.5
C2 = (1.66,3.66) so ED = Square root ((1-1.66)2 + (1-3.66)2) = 2.78
Here, C1 < C2, so point A belongs to cluster 1.
For point B = (1,0):
C1 = (1,0.5) so ED = Square root ((1-1)2 + (0-0.5)2) = 1
C2 = (1.66,3.66) so ED = Square root ((1-1.66)2 + (0-3.66)2) = 3.76
Here, C1 < C2, so point B belongs to cluster 1.
For point C = (0,2):
C1 = (1,0.5) so ED = Square root ((0-1)2 + (2-0.5)2)= 1.8
C2 = (1.66, 3.66) so ED = Square root ((0-1.66)2 + (2-3.66)2)= 2.4
Here, C1 < C2, so point C belongs to cluster 1.
For point D = (2,4):
C1 = (1,0.5) so ED = Square root ((2-1)2 + (4-0.5)2)= 3.6
C2 = (1.66,3.66) so ED = Square root ((2-1.66)2 + (4-3.66)2)= 0.5
Here, C1 > C2, so point C belongs to cluster 2.
For point E = (3,5):
C1 = (1,0.5) so ED = Square root ((3-1)2 + (5-0.5)2) = 4.9
C2 = (1.66,3.66) so ED = Square root ((3-1.66)2 + (5-3.66)2) = 1.9
Here, C1 > C2, so point C belongs to cluster 2.
在第二次迭代之后,我们的集群看起来如下。C1有点A、B和C,C2有点D和E:
C1 = XA + XB + Xc / 3 = (1+1+0) / 3 = 0.7
C1 = YA + YB + Yc / 3 = (1+0+2 ) / 3 = 1
So new C1 = (0.7,1)
C2 = XD + XE / 2 = (2+3) / 2 = 2.5
C2 = YD + YE / 2 = (4+5) / 2 = 4.5
So new C2 = (2.5,4.5)
我们需要进行迭代,直到集群不会改变。这就是为什么这个算法被称为迭代算法的原因。这是k均值聚类算法的直觉。现在我们将查看文档分类应用程序中的一个实际示例。
文档聚类
文档集群可以帮助您使用推荐系统。假设你有很多研究论文,而且没有标签。您可以使用k-means聚类算法,它可以帮助您根据文档中出现的单词形成聚类。您可以构建一个新闻分类应用程序。所有来自同一类别的新闻都应该组合在一起;您有一个超集类别,例如体育新闻,而这个体育新闻类别包含关于板球、足球等的新闻。
# We are going to generate 5 movie genre by using K-mena clustering.
from IPython.display import Image
Image(filename='./K_means_clustering/data/kmeanexample.png')

import numpy as np
import pandas as pd
import nltk
from bs4 import BeautifulSoup
import re
import os
import codecs
from sklearn import feature_extraction
import mpld3
#import three lists: titles, links and wikipedia synopses
titles = open('./K_means_clustering/data/title_list.txt',encoding='utf-8').read().split('\n')
#ensures that only the first 100 are read in
titles = titles[:100]
links = open('./K_means_clustering/data/link_list_imdb.txt',encoding='utf-8').read().split('\n')
links = links[:100]
synopses_wiki = open('./K_means_clustering/data/synopses_list_wiki.txt',encoding='utf-8').read().split('\n BREAKS HERE')
synopses_wiki = synopses_wiki[:100]
synopses_clean_wiki = []
for text in synopses_wiki:
text = BeautifulSoup(text, 'html.parser').getText()
#strips html formatting and converts to unicode
synopses_clean_wiki.append(text)
synopses_wiki = synopses_clean_wiki
genres = open('./K_means_clustering/data/genres_list.txt',encoding='utf-8').read().split('\n')
genres = genres[:100]
print(str(len(titles)) + ' titles')
print(str(len(links)) + ' links')
print(str(len(synopses_wiki)) + ' synopses')
print(str(len(genres)) + ' genres')
100 titles
100 links
100 synopses
100 genres
synopses_imdb = open('./K_means_clustering/data/synopses_list_imdb.txt',encoding='utf-8').read().split('\n BREAKS HERE')
synopses_imdb = synopses_imdb[:100]
synopses_clean_imdb = []
for text in synopses_imdb:
text = BeautifulSoup(text, 'html.parser').getText()
#strips html formatting and converts to unicode
synopses_clean_imdb.append(text)
synopses_imdb = synopses_clean_imdb
synopses = []
for i in range(len(synopses_wiki)):
item = synopses_wiki[i] + synopses_imdb[i]
synopses.append(item)
# generates index for each item in the corpora (in this case it's just rank) and I'll use this for scoring later
ranks = []
for i in range(0,len(titles)):
ranks.append(i)
# load nltk's English stopwords as variable called 'stopwords'
stopwords = nltk.corpus.stopwords.words('english')
# load nltk's SnowballStemmer as variabled 'stemmer'
from nltk.stem.snowball import SnowballStemmer
stemmer = SnowballStemmer("english")
# here I define a tokenizer and stemmer which returns the set of stems in the text that it is passed
def tokenize_and_stem(text):
# first tokenize by sentence, then by word to ensure that punctuation is caught as it's own token
tokens = [word for sent in nltk.sent_tokenize(text) for word in nltk.word_tokenize(sent)]
filtered_tokens = []
# filter out any tokens not containing letters (e.g., numeric tokens, raw punctuation)
for token in tokens:
if re.search('[a-zA-Z]', token):
filtered_tokens.append(token)
stems = [stemmer.stem(t) for t in filtered_tokens]
return stems
def tokenize_only(text):
# first tokenize by sentence, then by word to ensure that punctuation is caught as it's own token
tokens = [word.lower() for sent in nltk.sent_tokenize(text) for word in nltk.word_tokenize(sent)]
filtered_tokens = []
# filter out any tokens not containing letters (e.g., numeric tokens, raw punctuation)
for token in tokens:
if re.search('[a-zA-Z]', token):
filtered_tokens.append(token)
return filtered_tokens
totalvocab_stemmed = []
totalvocab_tokenized = []
for i in synopses:
allwords_stemmed = tokenize_and_stem(i)
totalvocab_stemmed.extend(allwords_stemmed)
allwords_tokenized = tokenize_only(i)
totalvocab_tokenized.extend(allwords_tokenized)
vocab_frame = pd.DataFrame({'words': totalvocab_tokenized}, index = totalvocab_stemmed)
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vectorizer = TfidfVectorizer(max_df=0.8, max_features=200000,
min_df=0.2, stop_words='english',
use_idf=True, tokenizer=tokenize_and_stem, ngram_range=(1,3))
%time tfidf_matrix = tfidf_vectorizer.fit_transform(synopses)
print(tfidf_matrix.shape)
Wall time: 12.1 s
(100, 563)
terms = tfidf_vectorizer.get_feature_names()
from sklearn.metrics.pairwise import cosine_similarity
dist = 1 - cosine_similarity(tfidf_matrix)
from sklearn.cluster import KMeans
num_clusters = 5
km = KMeans(n_clusters=num_clusters)
%time km.fit(tfidf_matrix)
clusters = km.labels_.tolist()
Wall time: 679 ms
from sklearn.externals import joblib
#joblib.dump(km, 'doc_cluster.pkl')
km = joblib.load('./K_means_clustering/data/doc_cluster.pkl')
clusters = km.labels_.tolist()
d:\Program Files\Anaconda3\lib\site-packages\sklearn\base.py:312: UserWarning: Trying to unpickle estimator KMeans from version pre-0.18 when using version 0.19.0. This might lead to breaking code or invalid results. Use at your own risk.
UserWarning)
d:\Program Files\Anaconda3\lib\site-packages\ipykernel\__main__.py:4: DeprecationWarning: The file './K_means_clustering/data/doc_cluster.pkl' has been generated with a joblib version less than 0.10. Please regenerate this pickle file.
import pandas as pd
films = { 'title': titles, 'rank': ranks, 'synopsis': synopses, 'cluster': clusters, 'genre': genres }
frame = pd.DataFrame(films, index = [clusters] , columns = ['rank', 'title', 'cluster', 'genre'])
frame['cluster'].value_counts()
4 26
0 25
2 21
1 16
3 12
Name: cluster, dtype: int64
grouped = frame['rank'].groupby(frame['cluster'])
grouped.mean()
cluster
0 47.200000
1 58.875000
2 49.380952
3 54.500000
4 43.730769
Name: rank, dtype: float64
print("Top terms per cluster:")
print()
order_centroids = km.cluster_centers_.argsort()[:, ::-1]
for i in range(num_clusters):
print("Cluster %d words:" % i, end='')
for ind in order_centroids[i, :6]:
print(' %s' % vocab_frame.ix[terms[ind].split(' ')].values.tolist()[0][0].encode('utf-8', 'ignore'), end=',')
print()
print()
print("Cluster %d titles:" % i, end='')
for title in frame.loc[i]['title'].values.tolist():
print(' %s,' % title, end='')
print()
print()
Top terms per cluster:
Cluster 0 words: b'family', b'home', b'mother', b'war', b'house', b'dies',
Cluster 0 titles: Schindler's List, One Flew Over the Cuckoo's Nest, Gone with the Wind, The Wizard of Oz, Titanic, Forrest Gump, E.T. the Extra-Terrestrial, The Silence of the Lambs, Gandhi, A Streetcar Named Desire, The Best Years of Our Lives, My Fair Lady, Ben-Hur, Doctor Zhivago, The Pianist, The Exorcist, Out of Africa, Good Will Hunting, Terms of Endearment, Giant, The Grapes of Wrath, Close Encounters of the Third Kind, The Graduate, Stagecoach, Wuthering Heights,
Cluster 1 words: b'police', b'car', b'killed', b'murders', b'driving', b'house',
Cluster 1 titles: Casablanca, Psycho, Sunset Blvd., Vertigo, Chinatown, Amadeus, High Noon, The French Connection, Fargo, Pulp Fiction, The Maltese Falcon, A Clockwork Orange, Double Indemnity, Rebel Without a Cause, The Third Man, North by Northwest,
Cluster 2 words: b'father', b'new', b'york', b'new', b'brothers', b'apartments',
Cluster 2 titles: The Godfather, Raging Bull, Citizen Kane, The Godfather: Part II, On the Waterfront, 12 Angry Men, Rocky, To Kill a Mockingbird, Braveheart, The Good, the Bad and the Ugly, The Apartment, Goodfellas, City Lights, It Happened One Night, Midnight Cowboy, Mr. Smith Goes to Washington, Rain Man, Annie Hall, Network, Taxi Driver, Rear Window,
Cluster 3 words:
d:\Program Files\Anaconda3\lib\site-packages\ipykernel\__main__.py:7: DeprecationWarning:
.ix is deprecated. Please use
.loc for label based indexing or
.iloc for positional indexing
See the documentation here:
http://pandas.pydata.org/pandas-docs/stable/indexing.html#ix-indexer-is-deprecated
b'george', b'dance', b'singing', b'john', b'love', b'perform',
Cluster 3 titles: West Side Story, Singin' in the Rain, It's a Wonderful Life, Some Like It Hot, The Philadelphia Story, An American in Paris, The King's Speech, A Place in the Sun, Tootsie, Nashville, American Graffiti, Yankee Doodle Dandy,
Cluster 4 words: b'killed', b'soldiers', b'captain', b'men', b'army', b'command',
Cluster 4 titles: The Shawshank Redemption, Lawrence of Arabia, The Sound of Music, Star Wars, 2001: A Space Odyssey, The Bridge on the River Kwai, Dr. Strangelove or: How I Learned to Stop Worrying and Love the Bomb, Apocalypse Now, The Lord of the Rings: The Return of the King, Gladiator, From Here to Eternity, Saving Private Ryan, Unforgiven, Raiders of the Lost Ark, Patton, Jaws, Butch Cassidy and the Sundance Kid, The Treasure of the Sierra Madre, Platoon, Dances with Wolves, The Deer Hunter, All Quiet on the Western Front, Shane, The Green Mile, The African Queen, Mutiny on the Bounty,
#This is purely to help export tables to html and to correct for my 0 start rank (so that Godfather is 1, not 0)
frame['Rank'] = frame['rank'] + 1
frame['Title'] = frame['title']
#export tables to HTML
print(frame[['Rank', 'Title']].loc[frame['cluster'] == 1].to_html(index=False))
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th>Rank</th>
<th>Title</th>
</tr>
</thead>
<tbody>
<tr>
<td>5</td>
<td>Casablanca</td>
</tr>
<tr>
<td>13</td>
<td>Psycho</td>
</tr>
<tr>
<td>14</td>
<td>Sunset Blvd.</td>
</tr>
<tr>
<td>15</td>
<td>Vertigo</td>
</tr>
<tr>
<td>24</td>
<td>Chinatown</td>
</tr>
<tr>
<td>31</td>
<td>Amadeus</td>
</tr>
<tr>
<td>57</td>
<td>High Noon</td>
</tr>
<tr>
<td>64</td>
<td>The French Connection</td>
</tr>
<tr>
<td>77</td>
<td>Fargo</td>
</tr>
<tr>
<td>87</td>
<td>Pulp Fiction</td>
</tr>
<tr>
<td>91</td>
<td>The Maltese Falcon</td>
</tr>
<tr>
<td>92</td>
<td>A Clockwork Orange</td>
</tr>
<tr>
<td>95</td>
<td>Double Indemnity</td>
</tr>
<tr>
<td>96</td>
<td>Rebel Without a Cause</td>
</tr>
<tr>
<td>98</td>
<td>The Third Man</td>
</tr>
<tr>
<td>99</td>
<td>North by Northwest</td>
</tr>
</tbody>
</table>
K均值聚类的优点
这是一个非常简单的NLP应用算法
它解决了主要的问题,因为它不需要标记数据或结果标签,您可以将此算法用于无标记数据
k-均值聚类的缺点
集群中心的初始化是一个非常关键的部分。假设有三个簇,在同一簇中放置两个形心,在最后一个簇中放置另一个形心。在某种程度上,k-均值聚类使聚类中所有数据点的欧几里得距离最小化,并且它将变得稳定,因此实际上,一个聚类中有两个形心,而第三个聚类中有一个形心。在这种情况下,您最终只有两个集群。这被称为集群中的局部最小问题。这是无监督学习算法的终结。在这里,您学习了k均值聚类算法,并开发了文档分类应用程序。如果你想更多地了解这项技术,试试这个练习。
练习
您需要探索NLP域中的层次集群及其应用。
下一节非常有趣。我们将研究半监督机器学习技术。在这里,我们将得到它们的概述。所以,让我们了解这些技术。
8.3.3 半监督机器学习算法
当您有一个训练数据集,该数据集中的某些数据具有目标概念或目标标签,而另一部分数据没有任何标签时,基本上使用半监督ML或半监督学习(SSL)。如果您有这种数据集,那么可以应用半监督的ML算法。当我们有非常少量的标记数据和大量的未标记数据时,我们可以使用半监督技术。如果您想为任何本地语言(除了英语)构建一个NLP工具,并且您有非常少量的标记数据,那么您可以使用半监督方法。在这种方法中,我们将使用一个使用标记数据并生成ML模型的分类器。此ML Model用于为未标记的数据集生成标签。分类器用于对未标记的数据集进行高置信度预测。您可以使用任何适当的分类器算法对标记的数据进行分类。
半监督技术是一个重要的研究领域,特别是在NLP应用中。去年,Google Research开发了基于图形的半监督技术:
https://research.googleblog.com/2016/10/graph-powered-machine-learning-at-google.html
8.3.4 一些重要概念
在这一节中,我们将看到那些帮助我们了解我们如何掌握我们的数据集的训练,你应该如何判断,你说过这些情况,你应该做什么?什么是新的应用评价矩阵?所以,让我们找到所有这些问题的答案。我将介绍以下主题。我们将逐一查看所有这些内容:
偏差方差权衡
欠拟合
过度拟合
评价矩阵
偏差方差权衡
在这里,我们将看到一个关于偏差-方差权衡的高级概念。让我们逐一理解每个术语。
让我们先了解“偏见”这个词。当您使用ML算法执行训练时,您发现生成的ML模型在第一轮训练迭代中的性能没有不同,那么您可以立即识别出ML算法有很高的偏差。在这种情况下,ML算法没有能力从给定的数据中学习,因此它不会学习您期望ML算法学习的新内容。如果你的算法有很高的偏差,那么它最终会停止学习。假设您正在构建一个情绪分析应用程序,并且您已经提出了MLModel,现在您对ML模型的准确性不满意,希望改进模型。您将通过添加一些新特性和更改一些算法参数来进行训练。现在,这个新生成的模型在测试数据上不能很好地执行或以不同的方式执行,这表明您可能有很高的偏差。您的ML算法不会以预期的方式收敛,因此您可以改进ML模型结果。
让我们理解第二个术语,方差。所以,您使用任何ML算法来训练您的模型,并且观察到您得到了非常好的训练精度。但是,您应用相同的ML模型来为一个看不见的测试数据集生成输出,并且您的ML模型不能很好地工作。这种情况下,你有很好的训练精度,而MLModel对于看不见的数据效果不佳,这被称为高方差情况。因此,在这里,ML模型只能复制它在训练数据中看到的预测或输出,并且没有足够的偏差来概括看不见的情况。换句话说,您可以说您的ML算法正试图记住每个训练示例,最后,它只是模仿您的测试数据集上的输出。如果您有一个高方差问题,那么您的模型将以这样一种方式聚合,即它试图将数据集的每个示例分类到一个特定的类别中。这种情况导致我们过度拟合。我会解释什么是过度拟合,所以别担心!我们几分钟后到。
为了克服前面的两个坏情况,我们真的需要一些中间的东西,这意味着没有高偏差和高方差。对于ML算法,产生最大偏差和最佳方差的技术可以得到最佳的ML模型。您的ML模型可能并不完美,但它都是关于生成最佳偏差方差权衡。
在下一节中,您将学习欠拟合和过拟合的概念,以及帮助您摆脱这些高偏差和高方差场景的技巧。
欠拟合
在本节中,我们将讨论欠拟合这个术语。什么是欠拟合,它与偏方差权衡有什么关系?假设您使用任何ML算法对数据进行训练,就会得到一个很高的训练错误。参见图8.60:
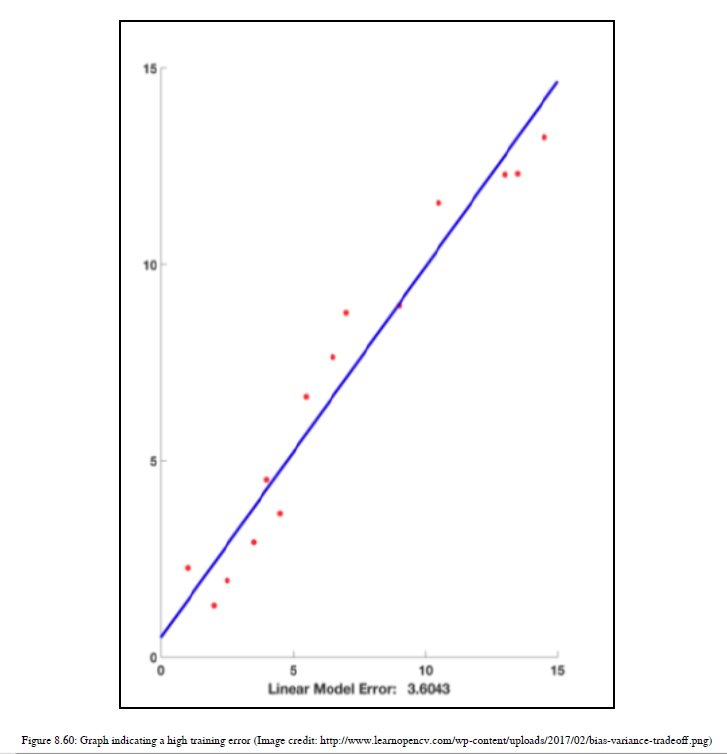
前面的情况,我们得到一个非常高的训练错误,被称为欠拟合。ML算法不能很好地处理训练数据。现在,我们将尝试更高程度的多项式,而不是线性决策边界。参见图8.61:
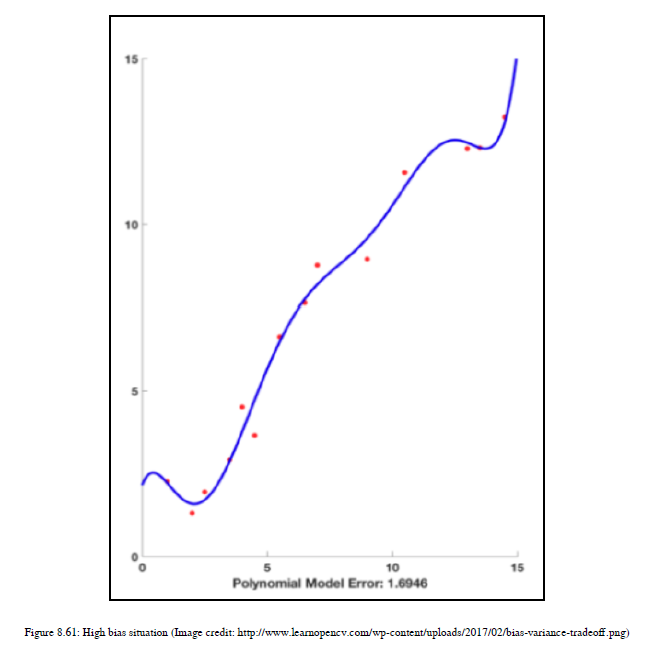
这张图有一条非常曲折的线,它不能很好地处理训练数据。换句话说,您可以说它与前一次迭代的执行情况相同。这表明,ML模型有很高的偏差,并且没有学到新的东西。
过度拟合
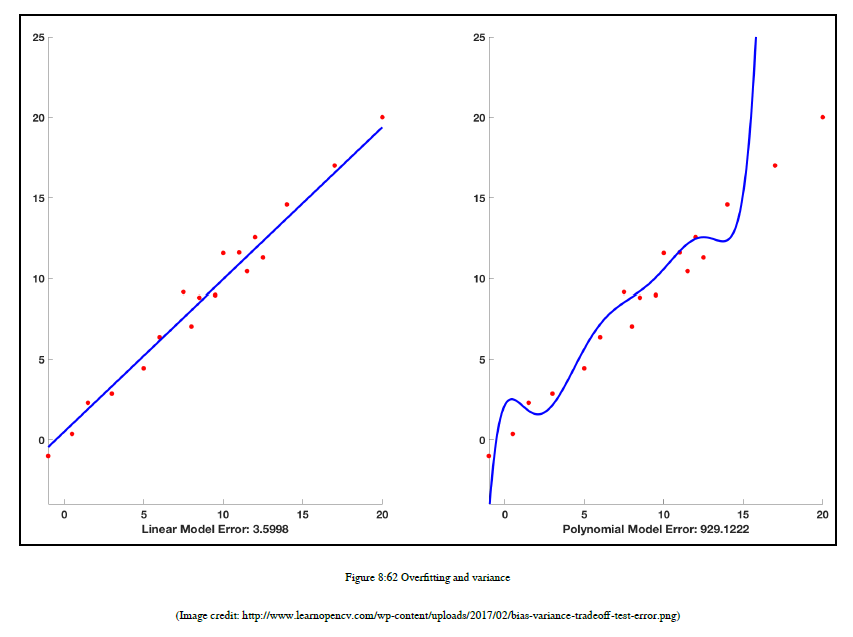
在本节中,我们将讨论“过度拟合”这一术语。当我解释上一节中的差异时,我把这个术语放在你面前。所以,是时候解释过拟合了,为了解释它,我想举个例子。假设我们有一个数据集,我们将所有数据点绘制在二维平面上,现在我们正试图对数据进行分类,我们的ML算法绘制一个决策边界来对数据进行分类。如图8.62所示:
如果你看左边的图,你会看到作为决策边界的直线。现在,这个图显示了一个训练错误,所以在第二次迭代中调整参数,您将获得非常好的训练精度;请参见右侧图。您希望测试数据也能获得良好的测试精度,但是ML模型在测试数据预测方面做得非常糟糕。因此,这种算法具有很好的训练精度,但在测试数据上表现不佳的情况称为过度拟合。在这种情况下,ML模型具有很高的方差,并且不能概括未知的数据。既然你已经看到了欠拟合和过度拟合,那么有一些经验法则可以帮助你避免这些情况。始终将培训数据分为三部分:60%的数据集应视为训练数据集
数据集的20%应被视为验证数据集或开发数据集,这将有助于获得ML算法的中间精度,以便您可以捕获意外的内容并根据此更改算法。
应保留数据集的20%,以报告最终精度,这将是测试数据集。您还应该应用k-折叠交叉验证。k表示需要验证的次数。假设我们把它设为三。我们将训练数据分成三个相等的部分。在训练算法的第一个时间戳中,我们使用两个部分,对单个部分进行测试,因此从技术上讲,它将以66.66%的速度进行训练,并以33.34%的速度进行测试。然后,在第二个时间戳中,ML算法使用一个部分对两个部分进行测试,最后一个时间戳将使用整个数据集进行培训和测试。经过三次时间戳后,计算平均误差,找出最佳模型。通常,对于合理数量的数据集,k应取10。
对于ML模型,您不能有100%的准确度,这背后的主要原因是您的输入数据中存在一些您不能真正删除的噪声,这被称为不可约错误。
因此,ML算法的最终误差方程如下:
Total error = Bias + Variance + Irreducible Error
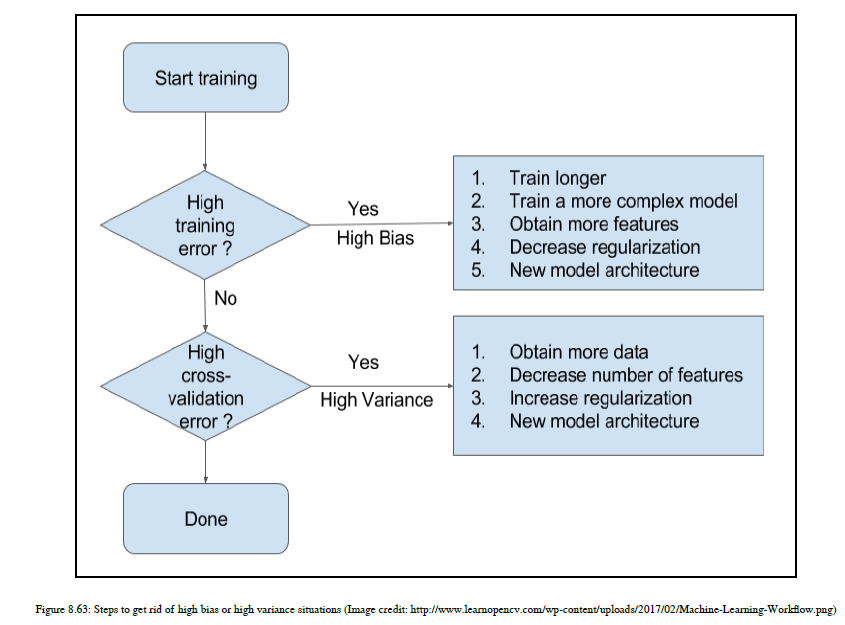
你真的不能摆脱不可约误差,所以你应该集中精力在偏差和方差上。请参阅图8.63,这将有助于向您展示如何处理偏差和差异权衡:
评价矩阵
对于我们的代码,我们会检查准确性,但在评估一个ML模型时,我们真的不知道哪些属性起主要作用。因此,在这里,我们将考虑一个广泛用于NLP应用程序的矩阵。这种评价矩阵称为F1得分或F度量。它有三个主要组成部分;在此之前,让我们介绍一些术语:
真阳性(TP):这是一个由分类器标记为a的数据点,实际上是来自类a。
真阴性(TN):这是对分类器中任何类的适当拒绝,这意味着分类器不会将数据点随机分类为类A,但会拒绝错误的标签。
假阳性(FP):这也被称为I型错误。让我们通过一个例子来理解这个度量:一个人为癌症测试献血。他实际上没有癌症,但他的测试结果是阳性的。这就是所谓的FP。
假阴性(FN):这也被称为II型错误。让我们通过一个例子来理解这个度量:一个人为癌症测试献血。他得了癌症,但他的检查结果是阴性的。所以它实际上忽略了类标签。这叫做FN。
精度:精度是精确性的度量;分类器标记为正且实际为正的数据点的百分比是多少:精度=TP/TP+FP
召回:召回是完整性的度量;分类器将阳性数据点的百分比标记为阳性:召回=TP/TP+FN
F-度量:这只是衡量精度和召回的衡量标准。见公式:F=2精度召回/精度+召回除此之外,您还可以使用混淆矩阵来了解TP、TN、FP和FN中的每一个。
您可以使用ROC曲线下的区域,该区域指示您的分类器能够区分负类和正类的程度。roc=1.0表示模型正确预测了所有类;0.5表示模型只是进行随机预测。
8.3.5 特征选择
现在是时候理解我们如何在第一次迭代之后即兴创作我们的模型了,有时候,特性工程在这方面帮助了我们很多。在第5章,特征工程和NLP算法以及第6章,高级特征工程和NLP算法中,我们解释了如何使用各种NLP概念和统计概念从文本数据中提取特征作为特征工程的一部分。特征工程包括特征提取和特征选择。现在是时候探索作为特征选择一部分的技术了。特征提取和特征选择为我们的NLP应用提供了最重要的特征。一旦我们设置了这些特性,您就可以使用各种ML算法来生成最终结果。如前所述,特征提取和特征选择是特征工程的一部分,在本节中,我们将介绍特征选择。您可能想知道我们为什么要学习特性选择,但有一些原因,我们将研究其中的每一个。首先,我们将看到对特征选择的基本理解。
特征选择也称为变量选择、属性选择或变量子集选择。特征选择是选择最佳相关特征、变量或数据属性的过程,这些特征、变量或数据属性可以帮助我们开发更高效的机器学习模型。如果可以确定哪些功能贡献很大,哪些功能贡献较小,则可以选择最重要的功能,并删除其他不重要的功能。
只要后退一步,首先了解我们使用功能选择试图解决的问题是什么。使用功能选择技术,我们可以获得以下好处:
选择相关和适当的特性将帮助您简化ML模型,这将帮助您轻松地解释ML模型,并降低ML模型的复杂性。
使用特征选择技术选择适当的特征将帮助我们提高ML模型的准确性。
特征选择有助于机器学习算法更快地训练。
功能选择还可以防止过度拟合。
它帮助我们摆脱维度的诅咒。
维数之咒
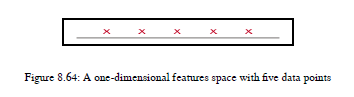
让我们理解我所说的维度性诅咒是什么意思,因为这个概念将帮助我们理解为什么我们需要特性选择技术。维数的诅咒是说,随着特征或维数的增加,这意味着我们的机器学习算法增加了新的特征,那么我们需要推广的数据量将以指数形式精确增长。让我们举个例子来看看。假设你有一条线,一维特征空间,我们在这条线上放置了五个点,你可以看到每一点都在这条线上占据了一些空间。每一点占直线上空间的五分之一。参见图8.64:
如果你有二维特征空间,那么我们需要五个以上的数据点来填充这个空间。所以,我们需要25个数据点来表示这两个维度。现在,每个点都占据了空间的1/25。见图8.65:
如果你有一个三维特征空间,这意味着我们有三个特征,那么我们需要填充立方体。如图8.66所示:
但是,要填充立方体,您需要正好125个数据点,如图8.66所示(假设有125个点)。所以每次我们添加功能时,都需要更多的数据。我想你们都会同意数据点的增长从5、25、125等指数级增长。所以,一般来说,您需要x d特性空间,其中x是训练中的数据点数量,d是特性或维度数量。如果您只是盲目地添加越来越多的特性,以便您的ML算法更好地理解数据集,那么实际上您所做的就是强制您的ML算法用数据填充更大的特性空间。你可以用一个简单的方法来解决这个问题。在这种情况下,您需要为您的算法提供更多的数据,而不是特性。
现在你真的认为我限制了你添加新功能。所以,让我为你澄清一下。如果需要添加功能,那么您可以;您只需要选择帮助您的ML算法从中学习的最佳和最小数量的功能。我真的建议您不要盲目地添加太多功能。
现在,我们如何获得最佳特性集?为我正在构建的特定应用程序设置的最佳特性是什么?我如何知道我的ML算法将在这个特性集上运行良好?我将在下一节特性选择技术中提供所有这些问题的答案。在这里,我将给您一个关于特性选择技术的基本概念。我建议您在我们目前开发的NLP应用程序中实际实现它们。
特征选择技术
使一切尽可能简单但不简单
阿尔伯特·爱因斯坦的这句话,在我们谈论特征选择技术时是非常正确的。我们已经看到为了摆脱维度性的诅咒,我们需要特征选择技术。我们将介绍以下功能选择技术:
滤波法
包装方法
嵌入法- 滤波法
特征选择完全是一个独立的活动,独立于ML算法。对于数字数据集,通常在预处理数据时使用此方法,对于NLP域,应在将文本数据转换为数字格式或矢量格式后执行此方法。让我们首先在图8.67中看到这个方法的基本步骤:

这些步骤非常清楚,也不需要解释。在这里,我们使用统计技术来给我们打分,基于此,我们将决定是保留这个特性,还是只删除它。参见图8.68:
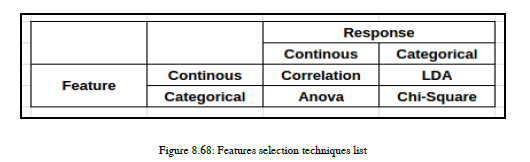
如果特征和响应都是连续的,那么我们将执行相关性
如果特征和响应都是分类的,那么我们将使用Chi Square;在NLP中(我们主要使用这个)
如果特征是连续的,响应是分类的,那么我们将使用线性判别分析(LDA)
如果特征是分类的,响应是连续的,那么我们将使用方差分析。
我将更加关注NLP领域,并解释LDA和Chi Square的基础知识。
LDA通常用于寻找表征或分离一类以上分类变量的特征的线性组合,而与LDA相比,Chi Square主要用于NLP。将卡方应用到一组分类特征中,以了解使用频率分布的特征之间相关或关联的可能性。
— 包装方法
在这个方法中,我们正在寻找最佳特性集。这种方法计算上非常昂贵,因为我们需要为每次迭代搜索最佳特性子集。参见图8.69中的基本步骤:
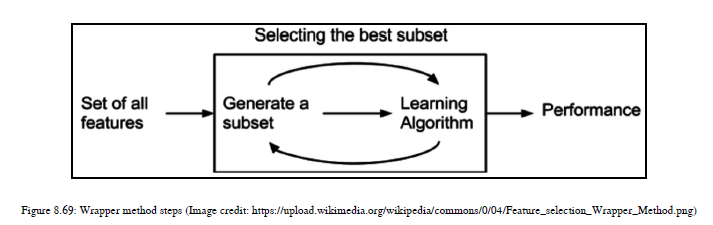
我们可以使用三种子方法来选择最佳功能子集:
正向选择
向后选择
递归特征消除在正向选择中,我们从没有特性开始,并在每次迭代中添加改进MLModel的特性。我们继续这个过程,直到我们的模型不能进一步提高其精度。
反向选择是另一种方法,我们从所有特性开始,在每次迭代中,我们找到最佳特性并删除其他不必要的特性,然后重复,直到在ML模型中观察到没有进一步的改进。
递归特征消除使用贪婪的方法来找出性能最好的特征子集。它反复创建模型,并为每个迭代保留最佳或最差的性能特性。下一次,它使用最好的特性并创建模型,直到所有特性都用尽为止;最后,它根据消除它们的顺序对特性进行排序。
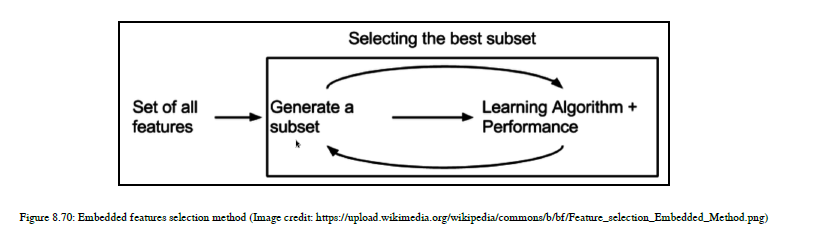
- 嵌入法
在这个方法中,我们结合了过滤器和包装器方法的特性。该方法由具有自己内置特征选择方法的算法实现,见图8.70:
8.3.6 维度约减
降维是机器学习中一个非常有用的概念。如果我们在开发我们的ML模型时包含了很多特性,那么有时我们会包含一些真正不需要的特性。有时我们需要高维的特征空间。有哪些方法可以让我们的功能空间有一定的意义?因此,我们需要一些技术来帮助我们去除不必要的特征,或者将我们的高维特征空间转换为二维或三维特征,以便我们能够看到所有发生的事情。顺便说一下,我们在第6章,高级功能工程和NLP算法中使用了这个概念,当时我们开发了一个应用程序,生成了word2vec用于权力游戏数据集。当时,我们使用t-分布随机邻域嵌入(t-sne)降维技术将我们的结果可视化到二维空间中。
在这里,我们将看到最著名的两种技术,即主成分分析(PCA)和T-SNE,用于在二维空间中可视化高维数据。那么,我们开始吧。
主成分分析
PCA是一种使用正交变换将一组可能相关特征的数据点转换为一组线性不相关特征值的统计方法,称为主成分。主成分的数量小于或等于原始特征的数量。这种技术定义转换的方式是,第一个主要组件对每个后续特性具有最大的可能方差。
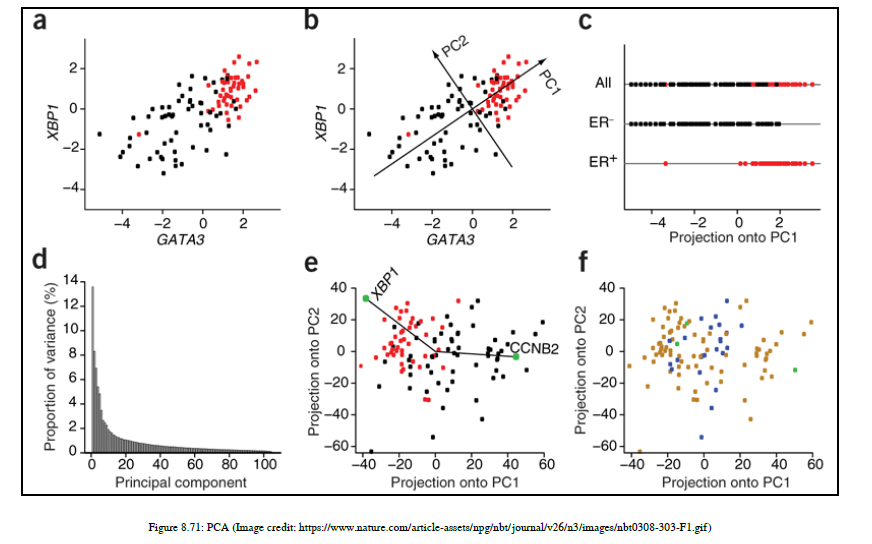
这个图对理解PCA有很大帮助。我们取了两个主成分,它们彼此正交,并且使方差尽可能大。在C图中,我们通过在一条直线上投影,把尺寸从二维缩小到一维。
PCA的缺点是,当你减少维度时,它就失去了数据点所代表的意义。如果解释性是维度减少的主要原因,那么就不应该使用PCA;可以使用T-SNE。
t-SNE
这是帮助我们可视化高维非线性空间的技术。T-SNE试图保留紧密相连的本地数据点组。当你想看到高维空间时,这项技术将帮助你。您可以使用它来可视化使用Word2vec、图像分类等技术的应用程序。有关详细信息,请参阅此链接:https://lvdmaaten.github.io/tsne/
8.4 自然语言处理中的混合方法
混合方法有时确实有助于我们改进NLP应用程序的结果。例如,如果我们正在开发一个语法修正系统,一个模块识别多字表达式,如kick the bucket,一个基于规则的模块识别错误的模式并生成正确的模式。这是一种混合方法。让我们为同一个NLP应用程序再举一个例子。您正在创建一个分类器,用于标识句子中名词短语的正确文章(限定词-a、an和the)。在这个系统中,您可以分为两类-a/an和the。我们需要开发一个分类器,它将生成限定符类别,无论是a/an还是the。一旦我们为名词短语生成了文章,我们就可以应用一个基于规则的系统来进一步确定第一类a/an的实际限定符。我们也知道一些英语语法规则,我们可以用它来决定我们应该用a还是an。这也是混合方法的一个例子。为了更好地进行情绪分析,我们还可以使用混合方法,包括基于词汇的方法、基于ML的方法或Word2vec或Glove预训练模型,以获得真正高的准确性。所以,要有创意,了解你的NLP问题,这样你就可以利用不同类型的技术,使你的NLP应用程序更好。后处理是一种基于规则的系统。假设您正在开发一个机器翻译应用程序,并且您生成的模型会犯一些特定的错误。你想让机器翻译(MT)模型避免这些错误,但要避免这些错误需要很多特性,这些特性会使训练过程变慢,使模型过于复杂。另一方面,如果你知道有一些简单的规则或近似值,一旦生成了输出,就可以帮助你使之更准确,然后我们可以使用后处理我们的机器翻译模型。混合模型和后处理有什么区别?让我来澄清你的困惑。在给定的示例中,我使用了单词近似。因此,您也可以应用近似值,例如应用阈值来调整结果,而不是使用规则,但只有当您知道近似值会给出准确的结果时,才应该应用近似值。这种近似应该对NLP系统进行足够的推广。
8.5 总结
在本章中,我们研究了ML的基本概念,以及NLP领域中使用的各种分类算法。在NLP中,与线性回归相比,我们主要使用分类算法。我们已经看到一些非常酷的例子,比如垃圾邮件过滤、情绪分析等等。我们还重新访问了词性标注示例为您提供更好的理解。我们研究了无监督的ML算法和重要概念,如偏差-方差权衡、欠拟合、过度拟合、评估矩阵等。我们还了解了特征选择和降维。我们还讨论了混合ML方法和后处理。因此,在本章中,我们主要了解如何开发和微调NLP应用程序。在下一章中,我们将看到一个机器学习的新时代——深度学习。我们将探索人工智能所需的基本概念。在此之后,我们将讨论深度学习的基础知识,包括线性回归和梯度下降。我们将看到为什么深度学习成为过去几年最流行的技术。我们将看到与深度学习相关的数学必要概念,探索深度神经网络的结构,并开发一些很酷的应用程序,如NLU域的机器翻译和NLG域的文本摘要。我们将使用TensorFlow、Keras和其他一些最新的工具来实现这一点。我们还将看到可以应用于传统ML算法和深度学习算法的基本优化技术。让我们在下一章深入了解深入学习的世界!
致谢
《Python自然语言处理》1 2 3,作者:【印】雅兰·萨纳卡(Jalaj Thanaki),是实践性很强的一部新作。为进一步深入理解书中内容,对部分内容进行了延伸学习、练习,在此分享,期待对大家有所帮助,欢迎加我微信(验证:NLP),一起学习讨论,不足之处,欢迎指正。

参考文献