集合输出
在进行集合输出时都利用了数据类型中定义的toString方法,或是利用了List接口中的get方法。集合输出共有四种手段:1.Iterator 2.ListIterator 3.Enumeration 4.foreach
1.Iterator(单向迭代器)
在Collection接口中定义由iterator方法,因此通过集合的实例化对象调用此方法就可以使用迭代器输出集合.
Iterator接口最初的设计里面实际有三个抽象方法:
- 判断是否有下一个元素:
public boolean hasNext(); - 取得当前元素:
public E next(); - 删除元素:
public default void remove();此方法从JDK1.8开始变为default完整方法
next()方法与hasNext方法成对出现,每当取得一个元素,迭代器的游标后移一个。
不能在遍历集合时修改集合元素,会引发异常。
System.out.println("单向迭代器迭代输出");
Iterator<Integer> iterator1=list.iterator();
while(iterator1.hasNext()){
System.out.println(iterator1.next());
}
2.ListIterator(双向迭代器)
- 判断是否有上一个元素:
public boolean hasPrevious(); - 取得上一个元素:
public E previous();
Iterator接口对象是由Collection接口支持的,但是ListIterator是由List接口支持的
//通过迭代方法打印集合,正向遍历(listIterator是双向迭代器)
ListIterator<Integer> iterator=list.listIterator();
while(iterator.hasNext()){
System.out.print(iterator.next());
}
System.out.println(">>>>>>>>>>>");
//通过迭代方法打印集合,反向遍历
while(iterator.hasPrevious()){//此时游标已经移到了最末尾
System.out.println(iterator.previous());
System.out.println(" ->");
}
3. Enumeration枚举输出
只能够依靠Vector子类,因为 Enumeration最早的设计就是为Vector服务的,在Vector类中提供有一个取得Enumeration接口对象的方法:
取得Enumeration接口对象:public Enumeration elements()
判断是否有下一个元素:public boolean hasMoreElements();
取得元素:public E nextElement();
Enumeration<String> enumeration=((Vector<String>) vector).elements();
System.out.println(enumeration);
4.4 foreach输出
for(Integer e:list){
System.out.println(e);
}
Map集合
Collection集合的特点是对单个对象进行保存,而Map集合中会一次性保存两个对象(类型定义为泛型),并且两个对象间的关系是key=value结构,可以通过key值找到value
Map中常用方法:
向Map中追加数据public V put(K key,V value);
根据key取得value,若没有返回null public V get(Object key);
取得key的所有信息,key不能重复 public Set<K> keySet();
取得所有value信息,可以重复 public Collection<V>values;
Map的常用子类
1.HashMap
可在一个key中存放多个value,当根据key取得value时,取得的是最后一次存入此key的value
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
//key值可重复
map.put(1, "一班");
map.put(1, "一班优");
map.put(1, "一班差");
map.put(2, "二班");
map.put(3, "三班");
map.put(4, "四班");
//根据key取得value
System.out.println(map.get(1));
//取得Map中所有Key的信息
Set<Integer> set=map.keySet();
System.out.println(set);
//取得Map中所有value信息
Collection collection=map.values();
System.out.println(collection);
}
输出结果:[1, 2, 3, 4]
[一班差, 二班, 三班, 四班]
HashMap源码分析
HashMap的内部实现可以看做是数组和链表组成的复合结构,数组被分为一个个的桶,通过哈希值决定键值对在这个数组中的寻址,哈希值相同的键值对会以链表的形式存储,而哈希值不同的键值对会新开辟数组空间.
HashMap的存储结构示意图:
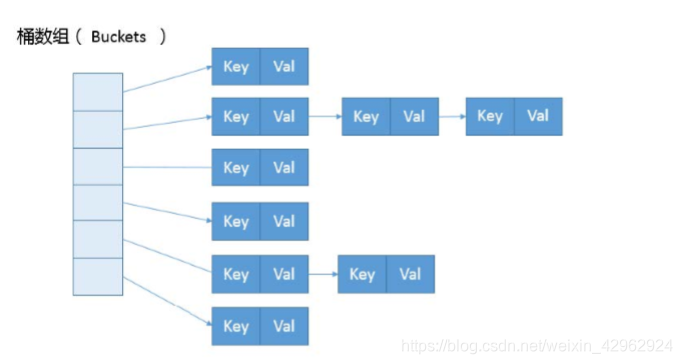
HashMap的数组的初始化是按照lazy-load原则,在首次使用时才会初始化,
添加集合元素的put方法中有一个putVal方法显示了HashMap的实现逻辑:如果数组为null,resize()方法负责初始化桶数组,默认桶容量为16个 ,当添加元素数量大于门限值(初始门限值为16,即桶容量)的0.75倍(0.75是默认负载因子,可改变)就会进行扩容,增加门限值,门限值的调整是以2倍数增加 (例如第一次扩容16=10000<<1,即32),扩容后,需要将老的数组中的元素重新放置到新的数组,是扩容主要的开销来源,(容量理论最大极限由 MAXIMUM_CAPACITY 指定,数值为 1<<30,也就是 2 的 30 次方).
键值对在哈希表中的位置(数组下标)运算规则:i=(n-1)&hash,因此存放位置并不仅仅只是依赖于key的哈希值,还需要将高位数据移位到低位进行异或运算 ,是因为有些数据计算出的哈希值差异主要在高 位,而 HashMap 里的哈希寻址是忽略容量以上的高位的,那么这种处理就可以有效避免类似情况下的哈希 碰撞。
当数组中的链表长度大于8(阈值)并且桶超过64个就会树化,图中的链表就会被改造为树形结构(红黑树,利用TreeNode类)。只要一个不满足,就会继续扩容。
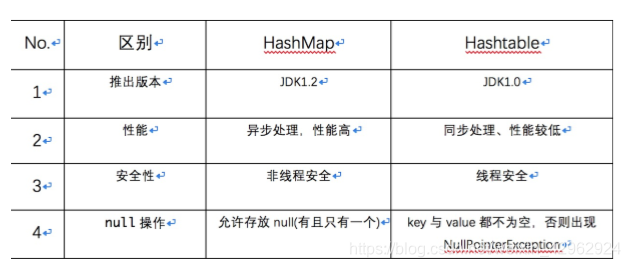
2.Hashtable类
Hashtable 本身比较低效,因为它的实现基本就是将 put、get、size 等各种方法加上“synchronized”。简单来说, 这就导致了所有并发操作都要竞争同一把锁,一个线程在进行同步操作时,其他线程只能等待,大大降低了并发操 作的效率
Hashtable与HashMap用法基本类似,其主要区别是:
3.ConcurrentHashMap
是能实现并发的HashMap,其内部实现设计为:里面则是HashEntry 的数组,和 HashMap类似,哈希相同的条目也是以链表形式存放。不同的是它将内部进行分段,当集合进行修改时就会把相应的段锁住,不能被get,其他段未被锁,依然可以get.
在 ConcurrentHashMap中扩容同样存在。不过有一个明显区别,就是它进行的不是整体的扩容,而是 单独对 Segment 进行扩
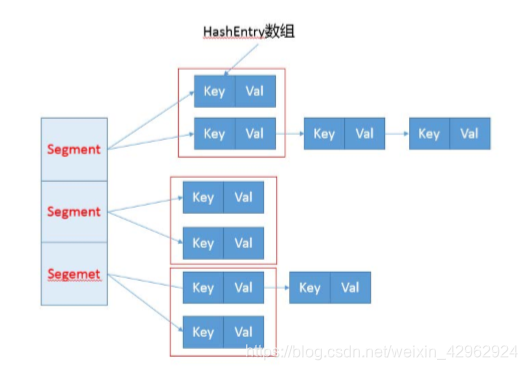
在构造的时候,Segment 的数量由所谓的 concurrentcyLevel (并发等级)决定,默认是 16,也可以在相应构造函数直接指定
4.TreeMap
TreeMap是一个可以排序的Map子类,它是按照Key的内容排序的
若key是系统定义(如String,Integer等,不能修改其compareTo方法)TreeMap中若想对排序规则改变:通过TreeMap的构造方法传入比较器(Comparator)的实现接口的实现类对象(lambda表达式)
若是自定义的类:1.实现comprable接口,实现接口中的compareTo方法 2.不实现,在使用时指定比较器(Comparator)接口的实现对象(更灵活一些)
采用使用时指定Comparator,方式比较灵活,其具体实现与TreeSet类似
有Comparable出现的地方,判断数据就依靠compareTo()方法完成,不再需要equals()与hashCode()
Map集合使用Iterator输出
Map接口中没有iterator()方法直接提供迭代器输出,而是通过一个重要的方法public Set<Map.Entry<K, V>> entrySet();将Map集合转为Set集合,再利用Set集合中的iterator()方法迭代.
//1.将Map集合变为Set集合
Set<Map.Entry<Integer,String>> setMap=map.entrySet();
//获得Iterator对象
Iterator<Map.Entry<Integer,String>> iterator=setMap.iterator();
while(iterator.hasNext()){
//取出每一个Map.Entry对象
Map.Entry<Integer,String> entry=iterator.next();
//取得key value
System.out.println(entry.getKey()+"="+entry.getValue());
}
栈与队列
栈是一种先进后出的数据结构 浏览器的后退、编辑器的撤销、安卓Activity的返回等都属于栈的功能。
栈
在Java集合中提供有Stack类,这个类时Vector的子类。
- 入栈 : public E push(E item)
- 出栈 : public synchronized E pop()
- 观察栈顶元素 : public synchronized E peek()
如果栈已经空了,那么再次出栈就会抛出空栈异常(EmptyStackException)。
队列
Stack是先进后出,与之对应的Queue是先进先出
队列用于高并发访问的情况,利用缓冲队列,将高并发用户的访问顺序排队,降低速度,当程序不能处理大量数据时,可以部署多个节点,成为分布式统称为集群,如果单节点不能满足存储,可以部署多个数据库,采用分布分表。当对数据访问的读写量不一致时,可以采用数据库的读写分离,将读的数据库多部署几个,当要实现读写同步时,部署一个数据库实现读写同步
Queue接口有一个子类LinkedListQueue<V> queue=new LinkedList<>();
使用Queue接口主要是进行先进先出的实现,在这个接口里面有如下的方法:
按照队列取出内容: public E poll();
队列在整个的操作之中可以起到一个缓冲的作用,那么可以利用队列修改之前多线程部分讲解的生产者和消费者程序模型
public static void main(String[] args) {
//生产者队列
Queue<String> queue=new LinkedList<>();
new Thread(new Runnable() {
{
System.out.println("生产者线程启动");
}
@Override
public void run() {
while (true){
try {
Thread.sleep(1000);
//生产数据,放入队列
queue.add("生产"+String.valueOf(Math.random()));
}catch (InterruptedException e){
e.printStackTrace();
}
}
}
}).start();//将一个线程启动,则与主线程分离,独立于主线程执行,在此线程中可以再定义执行逻辑
//两个线程的执行时间随机
//消费队列
//通过两个线程,实现消费者与生产者的分离解耦
new Thread(new Runnable() {
{
System.out.println("消费者线程");
}
@Override
public void run() {
while(true){
try {
Thread.sleep(1000);
System.out.println("消费队列"+queue.poll());
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}).start();
try {
System.in.read();
} catch (IOException e) {
e.printStackTrace();
}
}
}
Properties属性文件操作
在java中有一种属性文件(资源文件)的定义:.properties文件,在这种文件里面其内容的保存形式为"key = value",Properties(.properties(属性文件)–>Properties(属性类))是Hashtable的子类,因此可以用get put方法
*.properties文件中: 注释是“#” 属性文件中内容不换行 行结尾不以任何符号结尾,换行即可
在进行属性操作时利用Properties类提供的方法完成
- 设置属性 :
public synchronized Object setProperty(String key, String value) - 取得属性 :
public String getProperty(String key),如果没有指定的key则返回null - 取得属性 :
public String getProperty(String key, String defaultValue),如果没有指定的key则返回默认值
在Properties类中提供有IO支持的方法:
- 保存属性: public void store(OutputStream out, String comments) throws IOException
- 读取属性: public synchronized void load(InputStream inStream) throws IOException
public static void main(String[] args) {
//因为Properties继承了Hashtable,因此可以用get put方法
//*.properties ->属性文件
//Properties ->属性类
//读取文件:load ->Properties InputStream
//写入文件:store ->Properties OutputStream
Properties properties=new Properties();
//读取属性
try {
//1.通过文件流读取属性
properties.load(new FileInputStream("D:\\TL-BITE\\JAVA\\java_examples\\collection_practice\\src\\com\\sweet\\properties\\hello.properties"));
//
InputStream inputStream= PropertiesTest.class.getClassLoader()
.getResourceAsStream("com/sweet/properties/hello.properties");//文件名须包含包名
properties.load(inputStream);
System.out.println(properties.get("c++"));
System.out.println("java");
//当某个属性可能没有时,利用getProperty方法,为属性(key)赋值
System.out.println(properties.getProperty("php","nice"));
} catch (IOException e) {
e.printStackTrace();
}
properties.put("go", "better");
properties.setProperty("python", "hard");
//将写的key存入
try {
properties.store(new FileOutputStream("D:\\TL-BITE\\JAVA\\java_examples\\collection_practice\\src\\com\\sweet\\properties\\hello-1.properties"),"写入");
} catch (IOException e) {
e.printStackTrace();
}
}
Collections工具类
Collections是一个集合操作的工具类,包含有集合反转、排序等操作。
public static void main(String[] args) {
List<String> data = new ArrayList<>();
for(int i=65;i<=123;i++){
data.add(String.valueOf((char)i));
}
System.out.println(data);
System.out.println("原始数据"+data);
System.out.println("反转:");
Collections.reverse(data);
//二分查找
//index=-(插入点的下标)-1
int index= Collections.binarySearch(data, "A");
System.out.println("查看A下标"+index);
//乱序
Collections.shuffle(data);
//将非同步集合变为同步集合
//将集合变为不可修改的集合
Map<String, String> map = new HashMap<>();
System.out.println(map.put("q","退出"));
map= Collections.unmodifiableMap(map);
System.out.println(map.put("q","退出"));
//将集合变为不可修改的集合后再对集合进行修改则会报错
}
Stream数据流
,在整个大数据的开发里面有一个最经典的模 型:MapReduce。实际上这属于数据的两个操作阶段: 1. Map: 处理数据 2. Reduce: 分析数据,Java1.8中提供的大数据的相关操作(入门)
将集合流化的数据执行了终结流的方法后,不能再对此流进行操作,否则系统会抛异常IllegalStateException
从JDK1.8开始,Collection口里面除了定义一些抽象方法外,也提供了一些普通方法
1.利用forEach输出
List<String> list = new ArrayList<>();
//1.forEach 来自于Iterable
Collections.addAll(list,"php", "java", "go");
list.forEach(new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
});
//lambda表达式
list.forEach(s -> {
System.out.println(s);
});
List<String> list = new ArrayList<>();
//2.Stream来自于Collection
System.out.println(list.stream().count());
//若包含Java则遍历打印
list.stream()
.filter(s->s.contains("java"))
.map(s->s.toUpperCase())//将list元素转为大写
.forEach(System.out::println);
//普通写法,将集合中的元素转为大写放入另一个集合
List<String> newList=new ArrayList<>();
for(String item:list){
if (item.contains("java")){
newList.add(item.toUpperCase());
}
}
System.out.println(newList);
//利用stream写法
List<String> newList1=list.stream()
.filter(s->s.contains("java"))//断言函数,进行数据过滤
.map(s->s.toUpperCase())
.collect(Collectors.toList());//Collectors.toList()收集器作用
System.out.println(newList1);
//将Integer转为String
List<Integer> list1 = new ArrayList<>();
list1.add(1);
list1.add(11);
list1.add(111);
List<String> list2=list1
.stream()
.map(s->String.valueOf(s))
.collect(Collectors.toList());
//符合条件的个数统计
long count=list.stream().filter(s -> s.contains("java")).count();
System.out.println(count);
System.out.println("---------------------");
//skip与limit方法实现分页
list.stream()
.skip(1)//跳过1个
.limit(2)//取2个
.forEach(System.out::println);
System.out.println("----------------------");
list.stream()
.skip(0)
.limit(1)
.forEach(System.out::println);
}
Collection接口里提供有一个重要的stream()方法,将集合数据交给Stream之后,就相当于这些数据一个一个进行处理.且支持多线程,高并发,多核内存利用
MapReduce基础模型:
public class Order {
private String titile;
private double price;
private int amount;
public Order(String titile, double price, int amount) {
this.titile = titile;
this.price = price;
this.amount = amount;
}
public String getTitile() {
return titile;
}
public void setTitile(String titile) {
this.titile = titile;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
public int getAmount() {
return amount;
}
public void setAmount(int amount) {
this.amount = amount;
}
}
public class MapReduce {
public static void main(String[] args) {
List<Order> orderList = new ArrayList<>();
orderList.add(new Order("iphone", 8999.99, 122));
orderList.add(new Order("外行星人笔记本", 8969.99, 12));
orderList.add(new Order("MacBook", 1899.22, 5));
orderList.add(new Order("javaBook", 78, 122));
orderList.add(new Order("中性笔", 2, 67));
//计算金额综合
double total=0.0;
for(Order order:orderList){
total+=order.getPrice()*order.getAmount();
}
System.out.println("总金额是:"+total);
//利用MapReduce计算 fork-join
orderList.stream()
.mapToDouble(o->o.getPrice()*o.getAmount())
//将DoubleStream中的每个元素求和
.reduce(new DoubleBinaryOperator() {
@Override
//left->sum right ->map()中的每个数据
public double applyAsDouble(double left, double right) {
return left+right;
}
}).orElseGet(new DoubleSupplier() {
@Override
public double getAsDouble() {
return 0;
}
});
//mapreduce统计分析
DoubleSummaryStatistics ds= orderList.stream().mapToDouble(o->o.getAmount()*o.getPrice())
.summaryStatistics();
//统计结果:订单数量,最大订单 最小订单 总额 平均值
System.out.println("订单数量"+ds.getCount());
System.out.println("最大订单"+ds.getMax());
System.out.println("最小订单"+ds.getMin());
System.out.println("总额"+ds.getSum());
System.out.println("平均值"+ds.getAverage());
group();
}
public static void group(){
List<Order> orderList = new ArrayList<>();
orderList.add(new Order("MacBook", 1899.22, 5));
orderList.add(new Order("MacBook", 1899.22, 5));
orderList.add(new Order("javaBook", 78, 122));
orderList.add(new Order("中性笔", 2, 67));
orderList.add(new Order("中性笔", 2, 67));
Map<String, List<Order>> map = new HashMap<>();
for(Order order:orderList){
if(map.containsKey(order.getTitile())){
map.get(order.getTitile()).add(order);
}else{
List<Order> orders=new ArrayList<>();
orders.add(order);
map.put(order.getTitile(), orders);
}
}
//计算title相同的订单金额(原逻辑)
Map<String, Double> doubleMap = new HashMap<>();
for(Map.Entry<String,List<Order>> entry:map.entrySet()){
String title=entry.getKey();
List<Order> orders=entry.getValue();
double sum=0.0D;
for(Order o:orders){
sum+=o.getPrice()*o.getAmount();
}
doubleMap.put(title, sum);
}
System.out.println(doubleMap);
//MapReduce 实现分组
orderList.stream()
//title作为标识分组
.collect(Collectors.groupingBy(o -> o.getTitile()))
.forEach((k,v)->{
//为各组赋值key为title,value为每组的订单的和
//mapToDouble计算每个订单的金额
doubleMap.put(k,v.stream().mapToDouble(o->o.getAmount()*o.getPrice())
//reduce计算每组订单金额的和
.reduce((sum,x)->sum+x).orElse(0));
});
}
}