关于flask数据库的一些操作:
flask官方文档:http://flask-sqlalchemy.pocoo.org/2.3/
参考文档:https://blog.csdn.net/zyshappy/article/details/74092153
参考文档:https://www.cnblogs.com/we8fans/p/7107360.html
参考文档:https://www.cnblogs.com/alima/p/5734992.html
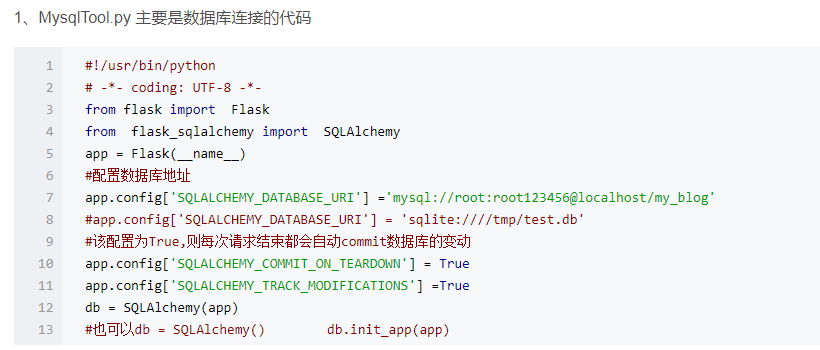
注意:第10行和第11行
如果设置成True(默认情况),Flask-SQLAlchemy 将会追踪对象的修改并且发送信号。这需要额外的内存, 如果不必要的可以禁用它。如果你不显示的调用它,在最新版的运行环境下,会显示警告。

这里需要着重说明一下一对多的关系是如何实现的:
参考链接:https://blog.csdn.net/qq_41376740/article/details/79340025
这个还需要再好好研究一下,就先不写了
增:
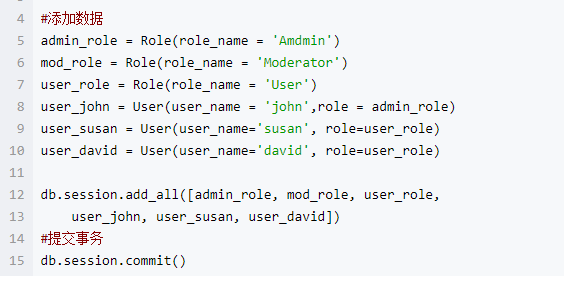
当想要一次性添加大量数据的时候,可以使用db.session.add_all([ , , ,])的方式
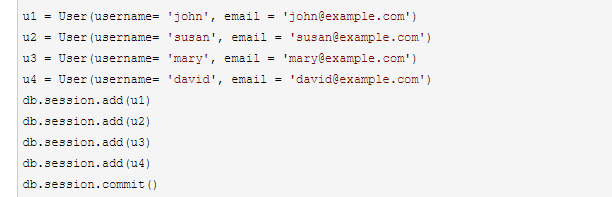
此方法为逐个添加,把所有的添加完之后再commit()
删:
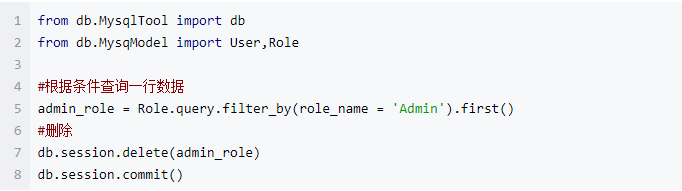
注意:from MysqlTool import db 把数据库的配置信息写在了MysqlTool里面
两个表是写在了MysqlModel里面
改:

首先进行查询,查询到的对象之后重新赋值
查:
查询有两种方式:


查询数据库有两种方式:1,表名.query.filter_by(字段=‘条件’).first() [.first()表示第一个匹配的条件]
2,db.session.query(表名).filter_by(字段='条件').first()
查询所有:

role.query.all() 得到的是一个包含所有实例对象的列表
这两种情况是一样的:

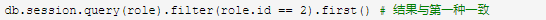
模糊查询:

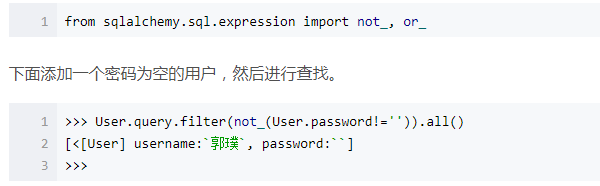

当然模糊查询还有另外一种方式:

找出u_name中既有“三”又有“猫”的记录:

排序:
1,第一个例子既是排序又可以分页
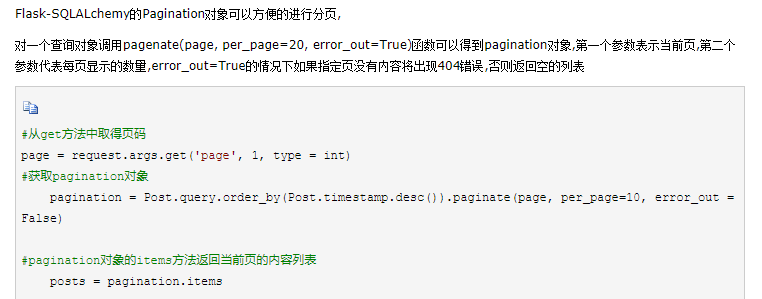
2,flask先对所要查询的表进行排序,然后是所要查询的内容