摘要
本文提出了一种从未标记或部分标记的数据中学习判别分类器的方法。方法基于客观函数,该函数在观察到的示例与其预测的分类类别分布之间交换互信息,与生成模型的分类器的鲁棒性进行对抗。得到的算法可以被解释为生成对抗网络(GAN)框架的自然概括,或者被解释为正则化信息最大化(RIM)框架的扩展,用于针对最优对手进行鲁棒分类。作者凭经验评估他们的方法-作者将分类生成对抗网络(CatGAN)用于合成数据以及具有挑战性的图像分类任务,并陈述了该分类器的鲁棒性。作者进一步定性地评估由判别分类器学习的对抗生成器生成的样本的保真度,并将CatGAN目标和判别性聚类算法(例如RIM)之间进行连接。
1、引言
从未标记或仅部分标记的数据中学习非线性分类器是机器学习中长期存在的问题。从未标记数据中学习的前提是,训练样本中存在的结构包含可用于推断未知标签的信息。也就是说,在无监督学习中,假设输入分布 包含关于 的信息,其中 表示未知标签。通过利用来自数据分布的标记和未标记的样本,人们希望学习得到这种共有结构的表示。这样的表示可以仅使用少数标记样本来生成数据的部分分布,用于帮助分类器的训练。此外,无监督的数据分类是用于发现具有未知类结构的数据集中的组的常用工具。
传统上,这个任务被形式化为群集分配问题,可以使用大量经过充分研究的算法。这些可以分为两种类型:
(1)生成聚类方法,如高斯混合模型,k均值和密度估计算法,它们直接尝试对数据分布
或其几何性质进行建模;
(2)判别聚类方法,如最大边缘聚类(MMC)(徐等,2005)或正则化信息最大化(RIM)(Krause等,2010),其目的是通过一些分类机制将未标记的数据直接分组到已经被良好区分的类别,而无需明确地对
进行建模。
虽然后一种方法更直接地对应于学习类别分离的目标(而不是样本类别或样本中心),但它们很容易过度拟合数据中的虚假相关性,特别是当与强大的非线性分类器(如神经网络)结合使用时。
最近,神经网络社区已经探索了用于无监督和半监督学习任务的各种方法。这些方法通常训练参数化的生成模型,例如,通过深度玻尔兹曼机(如Salakhutdinov&Hinton,2009或Goodfellow等,2013)或者通过前馈神经网络(如,Bengio等,2014或Kingma等,2014)或训练自动编码器网络(如,Hinton和Salakhutdinov,2006或Vincent等,2008)。因为他们通过重建输入样本明确地模拟数据分布,所有这些模型都与聚类生成方法相关,并且通常仅用于预训练分类网络。这种基于重建的学习方法的一个问题是,通过构造,他们试图学习保留输入样本中存在的所有信息的表示。这种完美重建的目标通常与学习分类器的目标相反,因为分类器是对 进行建模,因此只希望保留预测所必需的信息(并对其他不重要的细节具有鲁棒性)。
本文的分类生成对抗网络(CatGAN)框架的想法是结合生成和判别的角度。特别地,学习判别性神经网络分类器 ,其最大化输入 和标签 之间的互信息(如通过条件分布 预测的)。对于k个未知类别,为了帮助这些分类器更好的发现潜在的数据,作者将分类器的鲁棒性施加到对抗性生成模型产生的示例,该模型试图欺骗分类器接受虚假输入示例。
本文的其余部分安排如下:在介绍新方法之前,将简要回顾一节中的生成对抗网络框架;然后,将CatGAN的目标推导为GAN框架的扩展,然后在MNIST(LeCun等,1989)和CIFAR-10(Krizhevsky&Hinton,2009)数据集上进行实验。
2、生成对抗网络
Goodfellow等(2014)提出了生成对抗网络(GAN)框架。他们通过一个目标函数训练生成模型,该目标函数在一个鉴别器 和一个生成器 之间实现一个双人zero sum游戏。判别器旨在分辨真假输入数据,生成器 用于生成“愚弄”判别器的输入数据(来自噪声)。然后可以如下直观地描述生成器和判别器所玩的“游戏”。在每个步骤中,生成器从随机噪声中产生一个样本,该样本有可能欺骗判别器。然后,判别器被呈现一些真实数据样本,以及由生成器产生的示例,其任务是将它们分类为“真实的”或“假的”。之后,判别器被训练以区分正确的分类,并且生成器被训练以生成愚弄鉴别器的示例。然后更新两个模型并开始下一个”游戏“周期。
该过程可以如下形式化。设 是 维的真实数据输入(即 )。设 表示上述判别函数, 表示生成函数。即 将随机向量 映射到 ,并且用判别器 来计算样本 存在于数据集 中的概率: 。
GAN的目标函数如下:
其中 是一个任意的噪声分布,在不失一般性的情况下,在本文中假设是的均匀分布 。如果生成器和判别器都是可微函数(例如深度神经网络),则可以通过交替随机梯度下降(SGD)步骤对目标函数 进行训练,有效地实现上述两个玩家的游戏。
3 类别生成的对抗网络(CATGANS)
建立在第2章的基础上,现在将推导出用于无监督和半监督学习的分类生成对抗网络(CatGAN)的目标函数。作者首先将自己局限于无监督设置,这可以通过将GAN框架推广到多个类来获得,并在3.3章中介绍了半监督学习。应该注意的是,从正则化信息最大化(RIM)的角度出发,可以等效地推导出CatGAN模型,如附录中所述(注:附录未翻译),且具有相同的结果。

3.1 问题设置
和以前一样,令
是未标记的数据集。考虑无监督地学习判别分类器
的问题,使得
能将数据分类为先验选择的类别
。此外,需要
来产生到类别的条件概率分布,即
然后学习的目标是训练概率分类器
,其类别分配满足拟合优度的标准。值得注意的是,由于对示例的真实类分布未知,不得不求助于中间度量来判断分类器性能,而不是仅仅最小化负对数似然之类的准则。具体而言,在下文中,作者将总是优先选择
,对于给定样本
的条件类分布
具有高确定性,并且对所有的
,边际类分布
接近于某些先验分布
。在后文中,将始终假设一个均匀分布的先验类别,即期望
中每个类别的样本数对于所有
是相同的:
关于这个问题的第一个观点是它自然可以被认为是“软的”或概率集群分配任务。因此,原则上可以通过概率聚类算法来解决,例如正则化信息最大化(RIM)(Krause等,2010)或相关的熵最小化(Grandvalet和Bengio,2005),或早期关于仿真目标的无监督分类的工作(Bridle等人,1992)。所有这些方法都有过度拟合数据中虚假相关性的趋势,作者的目标是通过将鉴别器与对抗性生成模型配对来缓解这个问题,使其变得鲁棒。这种方法可以被理解为RIM的强大扩展,这种对抗提供了自适应正则化机制。这种关系在附录中明确说明。
可以做出的一个稍微明显但重要的第二个观点是标准GAN目标不能直接用于解决所描述的类别分配问题。这样做的原因是同时优化公式 确实产生了一个有辨别力的分类器 ,这个分类器能区分训练数据与生成数据,即这个分类器用于确定给定的样本 是否属于 。原则上,作者希望能够对数据分布建模的分类器也可以学习特征表示(例如,在神经网络的情况下, 的最后一层中的隐藏表示)对于在第二步中的提取类别是有用的(例如通过判别模型进行聚类)。然后,有必要认识到函数 执行二元分类任务的方法(区分真实样本和假样本)在GAN框架中不受限制,因此分类器将主要关注输入特征,这些输入特性尚未由生成器正确建模。反过来,这些特征不一定与想要分类数据的目标一致。在最坏的情况下,它们可以检测源自生成器数据中的噪声。
尽管存在这些问题,但是存在一种原则但简单的扩展GAN框架的方式,使得判别器可用于多类分类。为了实现这一点,作者考虑改变一下GAN框架后面的两个玩家游戏的规则(这将在下一节中形式化):不要求 预测 属于 的概率,作者要求 能判别所有 类别之一的样本,同时保持对生成模型 中的样本的类别分配的不确定性。作者期望这将有助于使分类器具有鲁棒性。类似地,可以将生成的问题从”生成属于数据集的样本“更改为”“生成属于 类中的一个的样本”。
如果成功地训练了这样的分类器-生成器的组合,对同时确保发现的 类与感兴趣的分类问题一致(例如 满足上面概述的拟合优度标准)。将有一个通用的公式从未标记的数据中训练分类器。
3.2 CatGAN的目标
如上所述,作者要解决的优化问题在一个关键方面不同于标准GAN的公式(1):这里不是要学习二元判别函数,而是旨在通过为每个示例
分配标签
来学习能将数据分成
类的判别器。形式上,作者将此设置的判别器
定义为可预测
类的对数概率的可微函数:
。然后,基于判别器输出通过softmax赋值给出样本
属于
互斥类之一的概率:
与标准GAN公式中一样,作者将生成器
定义为将随机噪声
映射到生成的样本
的函数:
其中 表示任意噪声分布。为了本文的目的, 和 总是被参数化为具有线性或Sigmoid输出的多层神经网络。
考虑到3.1节中的 拟合优度标准,并结合作者想要使用一个生成模型来规范化分类器的想法,可以直接得到学习判别器应该满足三个要求,以及生成器应该满足两个要求。这些需求被直观的展示在图1中。
图1:左半部分是生成器(绿色)和判别器(紫色)神经网络的信息流的可视化。右半部分是判别器目标函数
的三个部分的草图。为了获得给定样本点的确定性的预测,判别器最小化
的熵,这会生成条件类峰值分布。为了获得所生成样本的不确定的预测,作者将
的熵最大化。这在在极限情况下将导致均匀分布。最后,最大化所有数据点的边际类熵使得模型可以在所有类下使用。
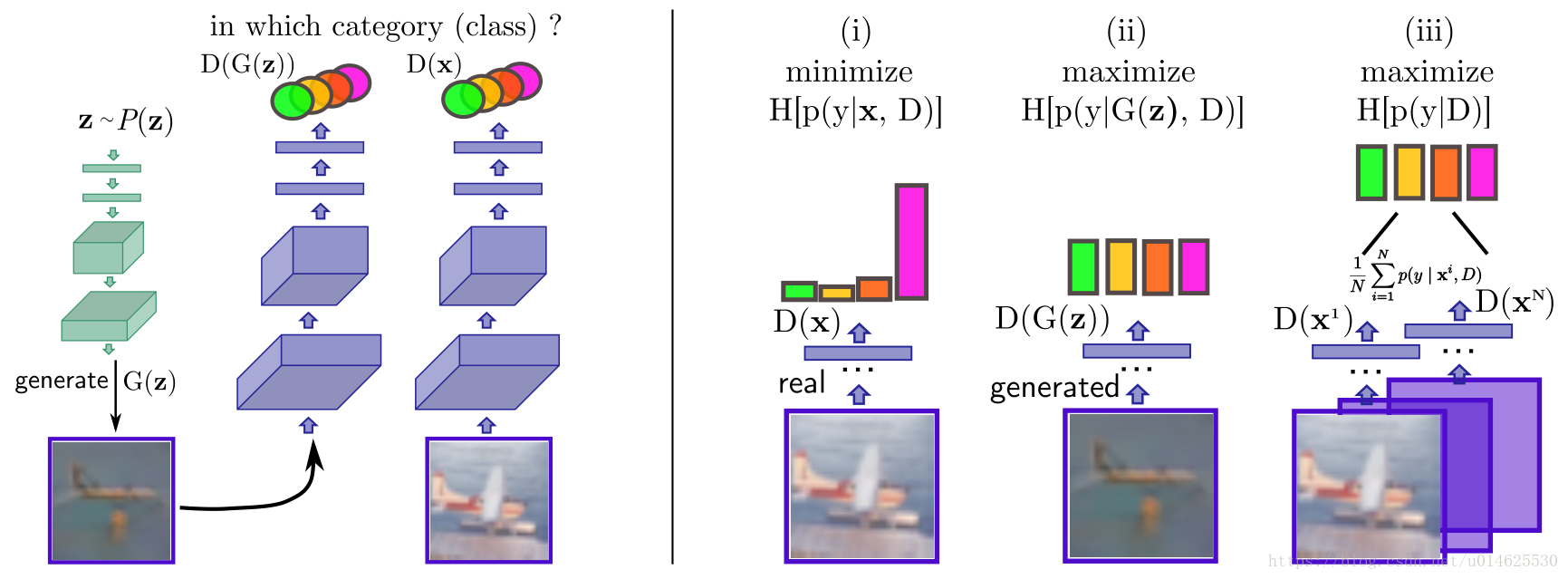
判别器的要求 对判别器的要求是它应该**(i)对来自原始样本的类别分配具有确定性,(ii)对来自生成样本的类别分配具有不确定性,(iii)**平等的使用所有类别。
生成器的要求 对生成器的要求是它应该(i)生成具有高度确定的类别分配的样本,(ii)在所有K类中均等地分配样本。
作者现在将依次解决这些要求。从判别器的角度开始,将它们定义为类概率的最大化或最小化问题。注意,如果没有关于 类的附加(标签)信息,任何给定 ,不能直接指定哪个类概率 应该最大化以满足判别器的要求**(i)**。尽管如此,可以通过计算预测类别分布的信息熵来满足获得这一要求。可以应用于该问题的最直接的度量是香农熵 ,其被定义为来自给定分布的样本所携带的信息的预期值。
直觉上,如果希望给定 为条件的类别分布 的峰值非常明显,即 能够确定类别,那么希望来自它的样本的信息熵 是低的,因为样本不论如何抽取,它的类别都是固定的。
另一方面,如果希望条件类别分布对于不属于
(来自生成器的样本)是比较平坦的,可以最大化熵
,在最佳情况下,将生成对类别的均匀条件分布并满足要求**(ii)**。具体而言,可以通过下面的式子来计算
的条件熵的经验估计,
生成器产生的样本的条件熵的经验估计可以表示为
的期望值,其中噪声向量
具有先验分布
。近似通过蒙特卡罗抽样导出下式,
其中 表示独立抽取的样本的数量(可以i简单地设置使其等于 )。为了满足所有类别被平等使用的第三个要求(对应于均匀边际分布)可以根据经验测量最大化 和 中的样本边际类分布的熵
第二个熵可以容易地用于满足生成器第二个要求的的最大化问题。从生成器角度,满足条件(i)等效最小化公式 。
结合方程 ,可以为CatGAN定义目标函数。对于判别器的目标函数用 来表示;生成器的目标函数用 来表示。
其中 表示如上定义的经验熵,生成器的目标 定义为最小化问题,以便与公式1进行明显对比。该目标满足上述所有要求,并且具有简单的信息理论解释: 中的前两项的作用是估计数据分布与预测类分布之间的互信息,判别器希望最大化互信息的同时最小化关于 的信息。类似地, 中的前两个项是估计生成的样本的分布与预测的类分布之间的互信息,并希望互信息最小。
因为作者有兴趣在大型数据集上使用目标 (7) ,因此作者希望 和 能够用小批量随机梯度下降进行优化,批的大小为 ,每一次都从 中独立计算得到。方程 中的条件熵项两者仅由每个示例熵的总和组成,因此可以简单地适用于分批计算。然而,边缘熵 和 的计算需要整个数据集 ,或需要计算来自 的大量样本的总和,因此不能使用批量的梯度下降。如果判别器需要预测的类别 的数量远小于批量大小 ,则对该问题的简单解决方案是对这小批量的 个样本估计边际类分布: 。对 ,可以类似地仅使用 个样本估计,而不是使用 个样本。值得注意的是,虽然这种近似对于这个问题是合理的(对于 且 ),但对于大量类别的情况,这是有问题的。在这样的设定下,人们将不得不估计多个批的边际类别分布(或者在更多的例子上定期评估它)。
3.3 推广到半监督学习
现在考虑将3.2节中的式子应用到半监督学习。令
是一
个标注的样本,其中标记向量
是one-hot编码。另外还提供了
个包含于
的未标注的样本。这些新增加的样本可以通过计算
的真实标签分布与预测的条件分布
之间的交叉熵,来整合到 公式(7) 的优化目标里(而不是计算未标记样本的熵
)。标记数据对
的交叉熵如下所示:
然后半监督的GAN的目标也可以通过定义
和
实现:
其中
是成本的加权项,
,即与公式7中的定义相同。
3.4 实施细节
在本文的实验中,生成器和判别器都通过神经网络参数化。每个考虑的基准的架构选择的细节在附录中给出(附录未翻译),而本节仅涵盖主要设计选择。
众所周知,在几种不好的情况下,GAN很难训练。首先,如果判别器学得太快(在这种情况下生成器的损失很容易饱和),则**公式(1)**的准则会变得不稳定。其次,生成器可能被卡住(作者在这里形容只输出数据的一种模式的情况),或者它可能在训练期间在生成不同模式之间开始疯狂地切换。
作者针对上述问题,在训练中采取两项措施。首先在判别器的所有层中以及生成器的最后一层(生成 的层)之外的所有层使用批量标准化(Ioffe&Szegedy,2015)。这有助于限制每层中的激活,并且凭经验发现它可以防止生成器的模式切换,以及在少数标签情况下增加判别器的泛化能力。此外,通过对其隐藏层应用噪声来标准化判别器。作者发现虽然dropout(Hinton,2012)对实现这一目的也有作用,但是在批量归一化的隐藏激活中添加高斯噪声可以产生稍好的性能。作者认为这主要是由于dropout噪声会严重影响批量归一化期间的均值和方差计算,而在计算这些统计量的激活时应用高斯噪声是一个自然的假设。
4 实验评估
作者的评估结果在表1、2、3中给出。可以看出,本文的方法几乎对所有数据集都具有竞争力。只有在每一层都去噪阶梯网络(ladder net full)效果更好。
4.1 使用catGAN聚类
由于未标记数据的分类通常与聚类相关联,因此作者对通常用于评估聚类算法的常见合成数据集执行了一组实验。比较CatGAN算法与标准k均值聚类和使用神经网络作为判别模型的RIM,这相当于从CatGAN模型中删除生成器并添加
正则化(附录B)。作者应用了三个标准的合成数据集(特征维数为2,因此
)。假设聚类中的类别数目
是已知的:“two moons”数据集包含两个聚类,“圆圈”排列数据集包含两个聚类,和一个具有三个各向同性的高斯气泡的简单数据集。
图2:k-means(左),RIM(中)和CatGAN(右边三个)在“圆圈”数据集上的比较,聚类数目为2,蓝色和绿色表示对两个不同类别的分配。对于CatGAN还显示了更大的决策区域以及生成的样本。

在图2作者展示了该实验对于“圆圈”数据集的结果(其他两个实验的图表被显示在附录的图4-6)。总体而言,所有算法都解决了具有三个数据blob的简单聚类分配。而对于两个更困难的例子,k-means和RIM都无法“正确”识别聚类:(1)k-means由于用于评估数据点和聚类中心之间距离的欧氏距离测量而失败,(2)RIM目标函数仅指定深层网络必须将数据分成两个相等的类,没有任何几何约束。在CatGAN模型中,判别器必须放置其决策边界,使其可以检测到与正确的聚类分配一致的非最佳对抗生成器。此外,生成器可以在各种情况下去快速学习样本生成。
4.2 无监督和半监督的图像特征学习
作者根据以下两种设定进行了实验:(1)使用标记样本的子集,根据 公式(7)优化学习半监督目标;(2)用未标记的样本,假设一共有二十个类别,根据 公式(9)优化无监督的目标。
在设定(2)中,学习之后是类别匹配步骤。在第二步中,作者简单地查看了验证集中的100个示例(始终保留了10000个用于验证的训练集的示例),假设已知正确的标记,并将每个伪类别 指定为一个真正的类 。具体而言,将伪类别 分配给类别 ,使得被分类为 并且属于 的样本数目最多。因此,这种设置与One-Shot学习(李飞飞等,2006于计算机视觉的应用)。由于在实际匹配步骤中没有学习,作者将此设置称为Half-Shot Learning。
关于置换不变MNIST(PI-MNIST)任务的实验结果列于表1。该表还列出了该基准测试的最新结果以及两个baseline:
(1)生成器被移除,但其他部分保留,称之为RIM+NN;
(2)标准GAN判别器与SVM结合,具体来说,首先使用标准GAN目标训练发生器、判别器,然后从可用标记示例上的判别器中提取最后一层特征,并使用它们来训练SVM。
表1:具有不同个标记样本的MNIST分类错误百分比,结果在10组不同的示例中取平均值。
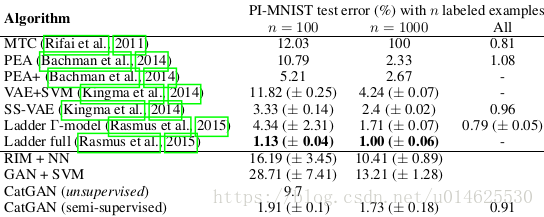
虽然RIM和GAN确实产生了对数字分类有用的功能,但它们的性能远远低于表中的最佳结果。另一方面,半监督的CatGAN接近最佳结果,即使仅有100个标记样本也能很好地工作,并且只有每层都去噪的梯形网络表现比它更好。更令人惊讶的是,上述half-shot产生的分类器在训练期间不需要任何标签信息就能实现9.7%的良好性能。
最后,作者将卷积判别器网络和反卷积(Zeiler等,2011)生成网络(Dosovitskiy等,2015)应用在MNIST和CIFAR-10上。网络架构的详细信息在附录中给出。结果列于表2和表3,与PI-MNIST结果相似。值得注意的是,无监督的CatGAN再次表现非常好,实现了4.27%的分类误差。使用半监督CatGAN训练的判别器在两个任务上表现良好,与CIFAR-10的标签相匹配。
表2:与CNN的分类错误率百分比的对比。
表3:完整数据集的CIFAR-10数据集上的不同方法的分类错误率(无数据增强),以及将每类减少到400个样本时的分类错误率。


4.3 生成模型的评价
图3:使用半监督CatGAN训练的生成器产生的示例图像,在MNIST(左)和CIFAR-10(右)上训练的生成样本。

最后,为了定性评估生成模型的能力,在MNIST、LFW和CIFAR-10上训练了一个无监督的CatGAN,并在图中绘制了这些模型生成的样本(如图3)。作为额外的定量评估,将基于MNIST训练的无监督CatGAN模型与基于生成样本的对数似然性的其他生成模型进行比较(通过Parzen窗口估计器测量),在附录的表6给出了全部结果。简而言之:CatGAN模型性能与现有最佳算法相当,在MNIST上实现了 的对数似然,相比下,Goodfellow等2014年的结果是 。然而这并不一定意味着CatGAN模型是优越的,因为比较生成模型通过Parzen窗口估计测量的对数似然可能会产生误导(Theis等2015的深入讨论)。
5 与之前工作的联系
正如引言中所强调的那样,catGAN方法与很多无监督和半监督类别的文献有关。虽然对这些方法的全面回顾超出了本文的范围,但作者指出了一些有趣的联系。
首先,正如已经讨论过的,很多文献已经考虑了将分类器的熵最小化到未标记数据上的想法(Bridle,1992;Grandvalet & Bengio,2005;Krause等,2010),catGAN的目标函数,当移除生成器并且将分类器 正则化时,可以追溯到正则信息最大化的工作(Krause等,2010)。最近几位研究人员还报告了使用pseudo-task进行无监督学习的成功经验,例如自我监督标记一组未标记的训练样例(Lee,2013),学习识别通过数据增强获得的pseudo-class(Dosovitskiy等人,2014)和pseudo-ensemble学习(Bachman等,2014),其中一组模型(具有共享参数)被训练,使得它们通过交叉熵来测量它们的预测。虽然这些看起来只是微弱相关,但它们与熵最小化密切相关(Bachman等,2014)。
从生成建模的角度来看,catGAN模型是生成对抗网络框架的直接后代(Goodfellow等,2014)。最近已经开发了对该框架的若干扩展,包括对一组变量的调节(Gauthier,2014;Mirza & Osindero,2014)和使用拉普拉斯金字塔的层次生成(Denton等,2015)。这些与本文开发的方法是正交的,例如,CatGAN与更先进的生成对抗网络架构的组合会是很有趣的未来工作。
6 结论
作者提出了分类生成对抗网络,一个强大的无监督和半监督学习的框架,将神经网络分类器与对抗性生成模型相结合,该模型使经过判别训练的分类器正规化。所提出的方法产生的分类性能与用于图像分类的半监督学习的最新结果相竞争,并且进一步证实了与分类器一起学习的生成器能够生成高视觉保真度的图像。
致谢
作者要感谢Alexey Dosovitskiy,Alec Radford,Manuel Watter,Joschka Boedecker和Martin Riedmiller对本手稿内容的极为有益的讨论。此外,非常感谢Alec Radford和Theano的开发人员(Bergstra等,2010;Bastien等,2012)和Lasagne(Dieleman等,2015)分享研究代码。这项工作由德国研究基金会(DFG)在优先计划“自主学习”(SPP1597)内资助。
References
Bachman, Phil, Alsharif, Ouais, and Precup, Doina. Learning with pseudo-ensembles. In Advances in Neural Information Processing Systems (NIPS) 27, pp. 3365–3373. Curran Associates, Inc., 2014.
Bastien, Frédéric, Lamblin, Pascal, Pascanu, Razvan, Bergstra, James, Goodfellow, Ian J., Bergeron, Arnaud, Bouchard, Nicolas, and Bengio, Yoshua. Theano: new features and speed improvements. Deep Learning and Unsupervised Feature Learning NIPS 2012 Workshop, 2012.
Bengio, Yoshua, Thibodeau-Laufer, Eric, and Yosinski, Jason. Deep generative stochastic networks trainable by backprop. In Proceedings of the 31st International Conference on Machine Learning (ICML), 2014.
Bergstra, James, Breuleux, Olivier, Bastien, Frédéric, Lamblin, Pascal, Pascanu, Razvan, Des-jardins, Guillaume, Turian, Joseph, Warde-Farley, David, and Bengio, Yoshua. Theano: a CPU and GPU math expression compiler. In Proceedings of the Python for Scientific Computing Conference (SciPy), 2010.
Bridle, John S., Heading, Anthony J. R., and MacKay, David J. C. Unsupervised classifiers, mutual information and phantom targets. In Advances in Neural Information Processing Systems (NIPS) 4. MIT Press, 1992.
Denton, Emily, Chintala, Soumith, Szlam, Arthur, and Fergus, Rob. Deep generative image models using a laplacian pyramid of adversarial networks. In Advances in Neural Information Processing Systems (NIPS) 28, 2015.
Dieleman, Sander, Schlter, Jan, Raffel, Colin, Olson, Eben, Sønderby, Søren Kaae, Nouri, Daniel, Maturana, Daniel, Thoma, Martin, Battenberg, Eric, Kelly, Jack, Fauw, Jeffrey De, Heilman, Michael, and et al. Lasagne: First release., August 2015. URL http://dx.doi.org/10.5281/zenodo.27878.
Dosovitskiy, A., Springenberg, J. T., and Brox, T. Learning to generate chairs with convolutional neural networks. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015.
Dosovitskiy, Alexey, Springenberg, Jost Tobias, Riedmiller, Martin, and Brox, Thomas. Discriminative unsupervised feature learning with convolutional neural networks. In Advances in Neural Information Processing Systems (NIPS) 27. Curran Associates, Inc., 2014.
Ester, Martin, Kriegel, Hans-Peter, Sander, Jrg, and Xu, Xiaowei. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proc. of 2nd International Conference on Knowledge Discovery and Data Mining (KDD), 1996.
Fei-Fei, L., Fergus, R., and Perona. One-shot learning of object categories. IEEE Transactions on Pattern Analysis Machine Intelligence, 28:594–611, April 2006. Funk, Simon. SMORMS3 - blog entry: RMSprop loses to SMORMS3 - beware the epsilon! http://sifter.org/simon/journal/20150420.html, 2015.
Gauthier, Jon. Conditional generative adversarial networks for face generation. Class Project for Stanford CS231N, 2014.
Goodfellow, Ian, Mirza, Mehdi, Courville, Aaron, and Bengio, Yoshua. Multi-prediction deep boltzmann machines. In Advances in Neural Information Processing Systems (NIPS) 26. Curran Associates, Inc., 2013.
Goodfellow, Ian, Pouget-Abadie, Jean, Mirza, Mehdi, Xu, Bing, Warde-Farley, David, Ozair, Sherjil, Courville, Aaron, and Bengio, Yoshua. Generative adversarial nets. In Advances in Neural Information Processing Systems (NIPS) 27. Curran Associates, Inc., 2014.
Grandvalet, Yves and Bengio, Yoshua. Semi-supervised learning by entropy minimization. In Advances in Neural Information Processing Systems (NIPS) 17. MIT Press, 2005.
Hinton, G E and Salakhutdinov, R R. Reducing the dimensionality of data with neural networks. Science, 313(5786):504–507, July 2006.
Hinton, Geoffrey E., Srivastava, Nitish, Krizhevsky, Alex, Sutskever, Ilya, and Salakhutdinov, Ruslan R. Improving neural networks by preventing co-adaptation of feature detectors. CoRR, abs/1207.0580v3, 2012. URL http://arxiv.org/abs/1207.0580v3.
Huang, Gary B., Ramesh, Manu, Berg, Tamara, and Learned-Miller, Erik. Labeled faces in the wild: A database for studying face recognition in unconstrained environments. Technical Report 07-49, University of Massachusetts, Amherst, October 2007.
Hui, Ka Y. Direct modeling of complex invariances for visual object features. In Proceedings of the 30th International Conference on Machine Learning (ICML). JMLR Workshop and Conference Proceedings, 2013.
Ioffe, Sergey and Szegedy, Christian. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning (ICML). JMLR Proceedings, 2015.
Kingma, Diederik and Ba, Jimmy. Adam: A method for stochastic optimization. In International Conference on Learning Representations (ICLR), 2015.
Kingma, Diederik P, Mohamed, Shakir, Jimenez Rezende, Danilo, and Welling, Max. Semi-supervised learning with deep generative models. In Advances in Neural Information Processing Systems (NIPS) 27. Curran Associates, Inc., 2014.
Krause, Andreas, Perona, Pietro, and Gomes, Ryan G. Discriminative clustering by regularized information maximization. In Advances in Neural Information Processing Systems (NIPS) 23. MIT Press, 2010.
Krizhevsky, A. and Hinton, G. Learning multiple layers of features from tiny images. Master’s thesis, Department of Computer Science, University of Toronto, 2009.
LeCun, Y., Boser, B., Denker, J. S., Henderson, D., Howard, R. E., Hubbard, W., and Jackel, L. D. Backpropagation applied to handwritten zip code recognition. Neural Computation, 1(4):541–551, 1989.
Lee, Dong-Hyun. Pseudo-label : The simple and efficient semi-supervised learning method for deep neural networks. In Workshop on Challenges in Representation Learning, ICML, 2013.
Li, Yujia, Swersky, Kevin, and Zemel, Richard S. Generative moment matching networks. In Proceedings of the 32nd International Conference on Machine Learning (ICML), 2015.
Mirza, Mehdi and Osindero, Simon. Conditional generative adversarial nets. CoRR, abs/1411.1784, 2014. URL http://arxiv.org/abs/1411.1784.
Osendorfer, Christian, Soyer, Hubert, and van der Smagt, Patrick. Image super-resolution with fast approximate convolutional sparse coding. In ICONIP, Lecture Notes in Computer Science. Springer International Publishing, 2014.
Rasmus, Antti, Valpola, Harri, Honkala, Mikko, Berglund, Mathias, and Raiko, Tapani. Semi-supervised learning with ladder network. In Advances in Neural Information Processing Systems (NIPS) 28, 2015.
Rifai, Salah, Dauphin, Yann N, Vincent, Pascal, Bengio, Yoshua, and Muller, Xavier. The manifold tangent classifier. In Advances in Neural Information Processing Systems (NIPS) 24. Curran Associates, Inc., 2011.
Salakhutdinov, Ruslan and Hinton, Geoffrey. Deep Boltzmann machines. In Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS), 2009.
Schaul, Tom, Zhang, Sixin, and LeCun, Yann. No More Pesky Learning Rates. In International Conference on Machine Learning (ICML), 2013.
Springenberg, Jost Tobias, Dosovitskiy, Alexey, Brox, Thomas, and Riedmiller, Martin. Striving for simplicity: The all convolutional net. In arXiv:1412.6806, 2015.
Theis, Lucas, van den Oord, Aäron, and Bethge, Matthias. A note on the evaluation of generative models. CoRR, abs/1511.01844, 2015. URL http://arxiv.org/abs/1511.01844.
Tieleman, T. and Hinton, G. Lecture 6.5—RmsProp: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural Networks for Machine Learning, 2012.
Vincent, Pascal, Larochelle, Hugo, Bengio, Yoshua, and Manzagol, Pierre-Antoine. Extracting and composing robust features with denoising autoencoders. In Proceedings of the Twenty-fifth International Conference on Machine Learning (ICML), 2008.
Weston, J., Ratle, F., Mobahi, H., and Collobert, R. Deep learning via semi-supervised embedding. In Montavon, G., Orr, G., and Muller, K-R. (eds.), Neural Networks: Tricks of the Trade. Springer, 2012.
Xu, Linli, Neufeld, James, Larson, Bryce, and Schuurmans, Dale. Maximum margin clustering. In Advances in Neural Information Processing Systems (NIPS) 17. MIT Press, 2005.
Zeiler, Matthew D., Taylor, Graham W., and Fergus, Rob. Adaptive deconvolutional networks for mid and high level feature learning. In IEEE International Conference on Computer Vision, ICCV, pp. 2018–2025, 2011.
Zhao, Junbo, Mathieu, Michael, Goroshin, Ross, and Lecun, Yann. Stacked what-where autoencoders. CoRR, abs/1506.02351, 2015. URL http://arxiv.org/abs/1506.02351.