版权声明:转载请声明原文链接地址,谢谢! https://blog.csdn.net/weixin_42859280/article/details/85227996
Python爬虫获取文章的标题及你的博客的阅读量,评论量。所有数据写入本地记事本。最后输出你的总阅读量!还可以进行筛选输出!比如阅读量大于1000,之类的!
完整代码在最后。依据阅读数量进行降序输出!
还有代码截图(适用于不知道为啥出现错误的朋友)
运行结果截图,写入后的记事本截图都有。
都在最后!
把链接换成你的就可以直接使用啦!
我是以我的主页作为列子来实践的!
注意链接格式呦!
还有,访问量是大于阅读量的。
访问量=阅读量+访问主页次数
因为别人可能访问你,但是没有阅读你的文章!
先说一段吧,诉诉苦水。也是我忙碌了好久才解决的!
1,第一个就是这个东西,会让你的数据错位。最后跟正确数据总有不同!
而且每个人的主页都有这个人的链接:
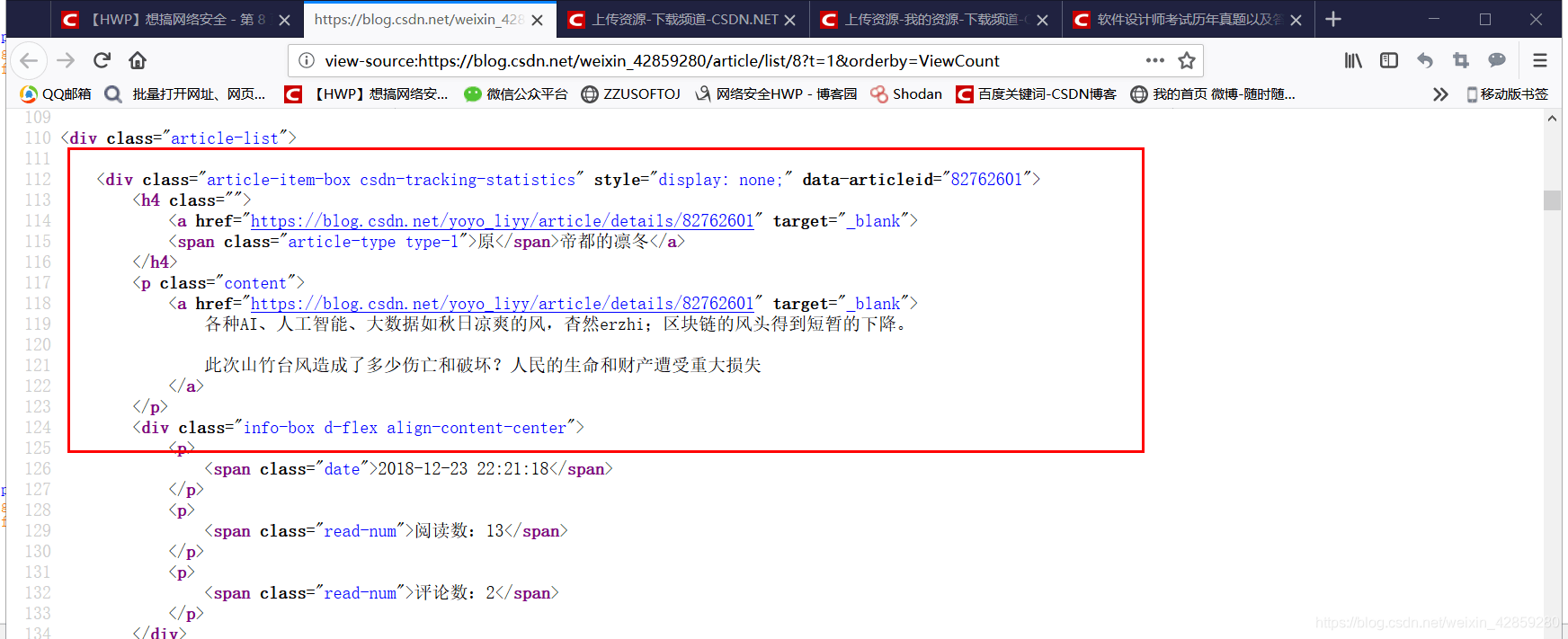
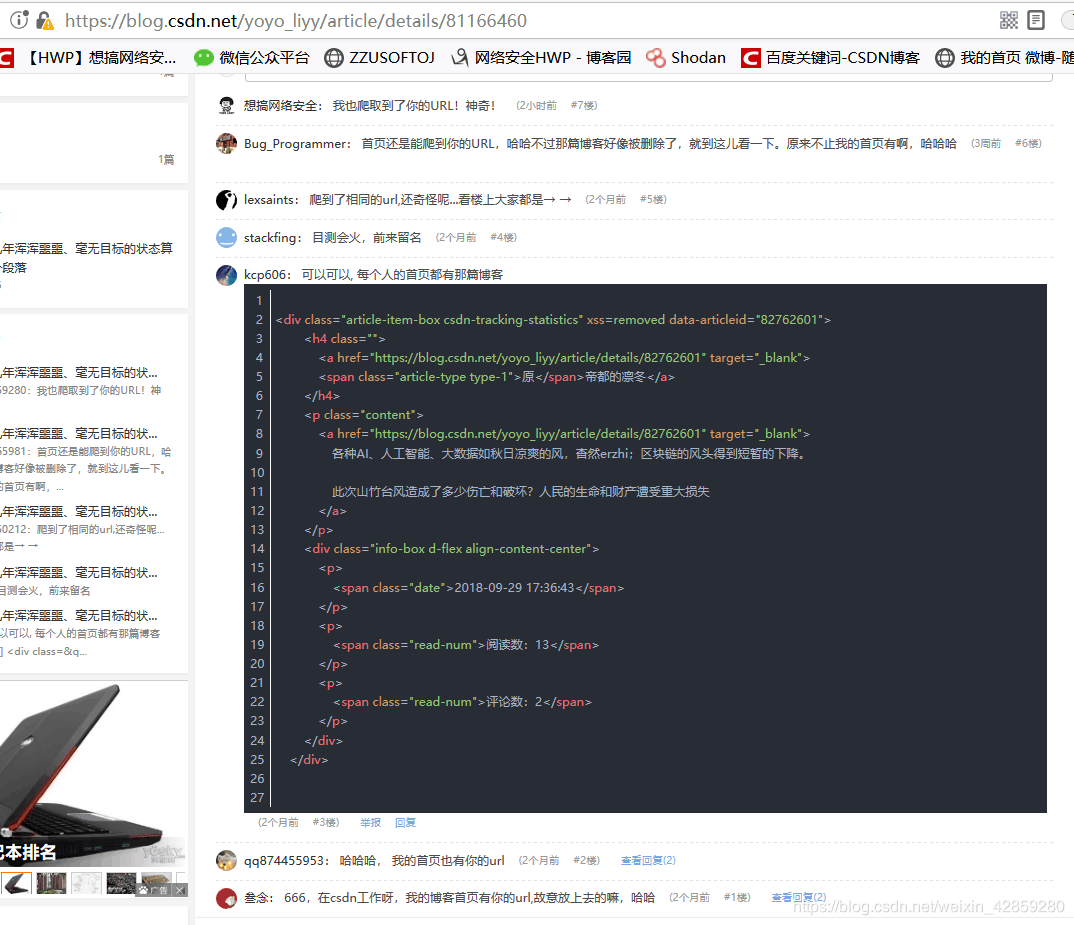
你说气人不!
但是,我是借助列表来存储的。
那么,这样就好啦:
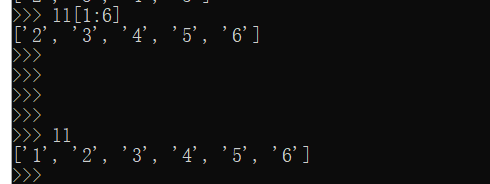
让列表输出第二个到最后一个
实现这个功能,通过切片来实现
自己不会,所以耽误好久!通过切片来就好啦!
nn = nn[1:]
其他就没啥啦!就是这个错位,也不知道什么原因!
最后找到啦,解决也费了点时间!
我添加了一个对文件进行写操作,就是把东西写入到记事本里面!
(但是,要写入的记事本要和.py文件在同一个路径之下!)
我的都在桌面!

代码的讲解就放在代码块里吧!
ff = open('1.txt','a')#打开文件
if n%10 == 0:#判断,进行多输入一个换行符号,为了美观!
ff.write(titles[w]+' '+str(nn[w])+' \n\n')#写入你想写入的列表元素!
else:
ff.write(titles[w]+' '+str(nn[w])+' \n')#输入一个换行符号,为了美观!
ff.close()#关闭文件!
n += 1#不能一直换行呀,找个变量来!
其他的就是一些正则表达式啦,不会的就直接使用吧!
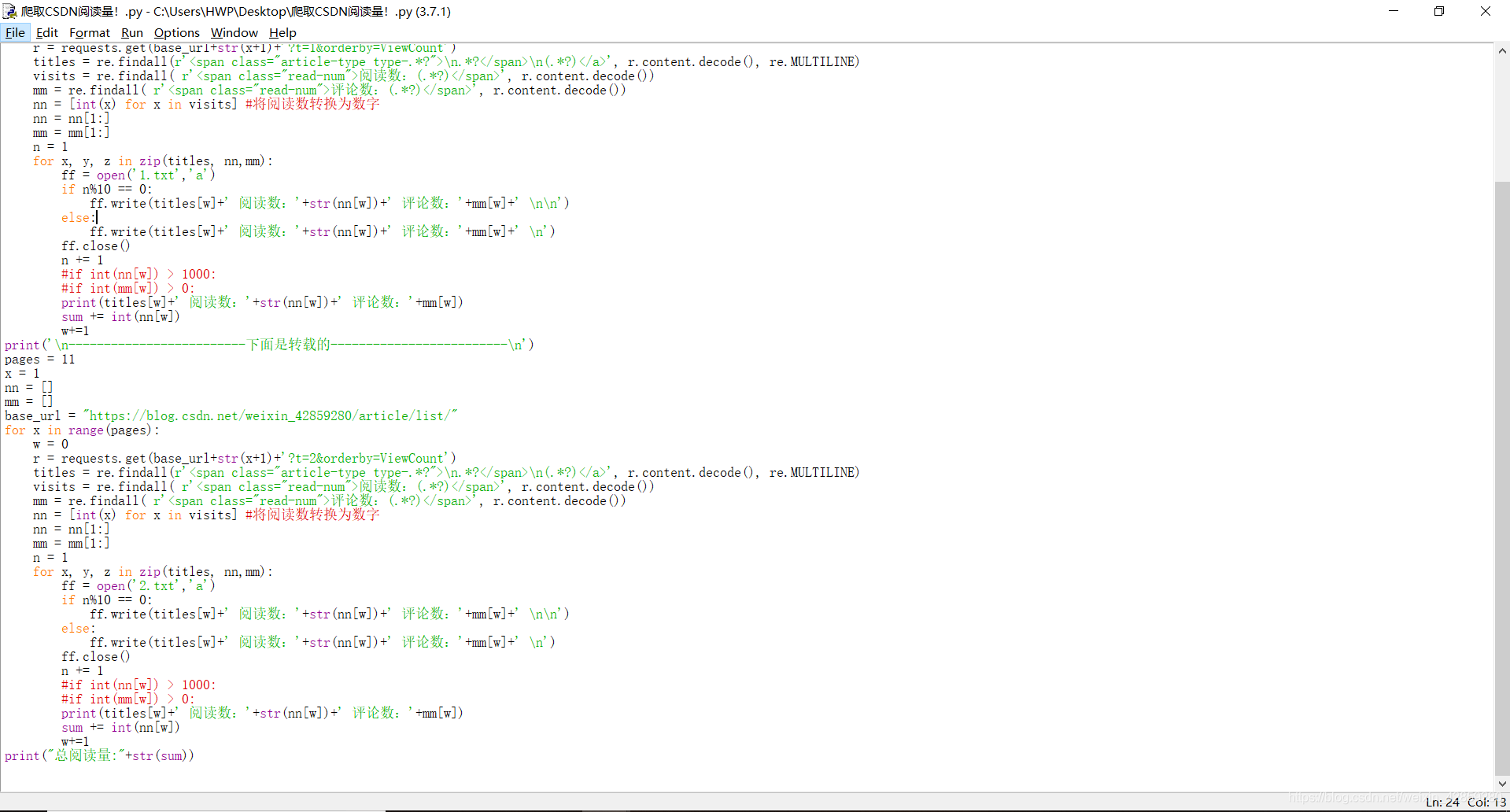
代码:
import requests
import re
sum = 0
pages = 10
x = 1
nn = []
mm = []
base_url = "https://blog.csdn.net/weixin_42859280/article/list/"
print('\n-------------------------下面是原创的-------------------------\n')
for x in range(pages):
w = 0
r = requests.get(base_url+str(x+1)+'?t=1&orderby=ViewCount')
titles = re.findall(r'<span class="article-type type-.*?">\n.*?</span>\n(.*?)</a>', r.content.decode(), re.MULTILINE)
visits = re.findall( r'<span class="read-num">阅读数:(.*?)</span>', r.content.decode())
mm = re.findall( r'<span class="read-num">评论数:(.*?)</span>', r.content.decode())
nn = [int(x) for x in visits] #将阅读数转换为数字
nn = nn[1:]
mm = mm[1:]
n = 1
for x, y, z in zip(titles, nn,mm):
ff = open('1.txt','a')
if n%10 == 0:
ff.write(titles[w]+' 阅读数:'+str(nn[w])+' 评论数:'+mm[w]+' \n\n')
else:
ff.write(titles[w]+' 阅读数:'+str(nn[w])+' 评论数:'+mm[w]+' \n')
ff.close()
n += 1
#if int(nn[w]) > 1000:#可以进行筛选输出!
#if int(mm[w]) > 0:#可以进行筛选输出!
print(titles[w]+' 阅读数:'+str(nn[w])+' 评论数:'+mm[w])
sum += int(nn[w])
w+=1
print('\n-------------------------下面是转载的-------------------------\n')
pages = 11
x = 1
nn = []
mm = []
base_url = "https://blog.csdn.net/weixin_42859280/article/list/"
for x in range(pages):
w = 0
r = requests.get(base_url+str(x+1)+'?t=2&orderby=ViewCount')
titles = re.findall(r'<span class="article-type type-.*?">\n.*?</span>\n(.*?)</a>', r.content.decode(), re.MULTILINE)
visits = re.findall( r'<span class="read-num">阅读数:(.*?)</span>', r.content.decode())
mm = re.findall( r'<span class="read-num">评论数:(.*?)</span>', r.content.decode())
nn = [int(x) for x in visits] #将阅读数转换为数字
nn = nn[1:]
mm = mm[1:]
n = 1
for x, y, z in zip(titles, nn,mm):
ff = open('2.txt','a')
if n%10 == 0:
ff.write(titles[w]+' 阅读数:'+str(nn[w])+' 评论数:'+mm[w]+' \n\n')
else:
ff.write(titles[w]+' 阅读数:'+str(nn[w])+' 评论数:'+mm[w]+' \n')
ff.close()
n += 1
#if int(nn[w]) > 1000:#可以进行筛选输出!
#if int(mm[w]) > 0:#可以进行筛选输出!
print(titles[w]+' 阅读数:'+str(nn[w])+' 评论数:'+mm[w])
sum += int(nn[w])
w+=1
print("总阅读量:"+str(sum))
代码截图:
(1):
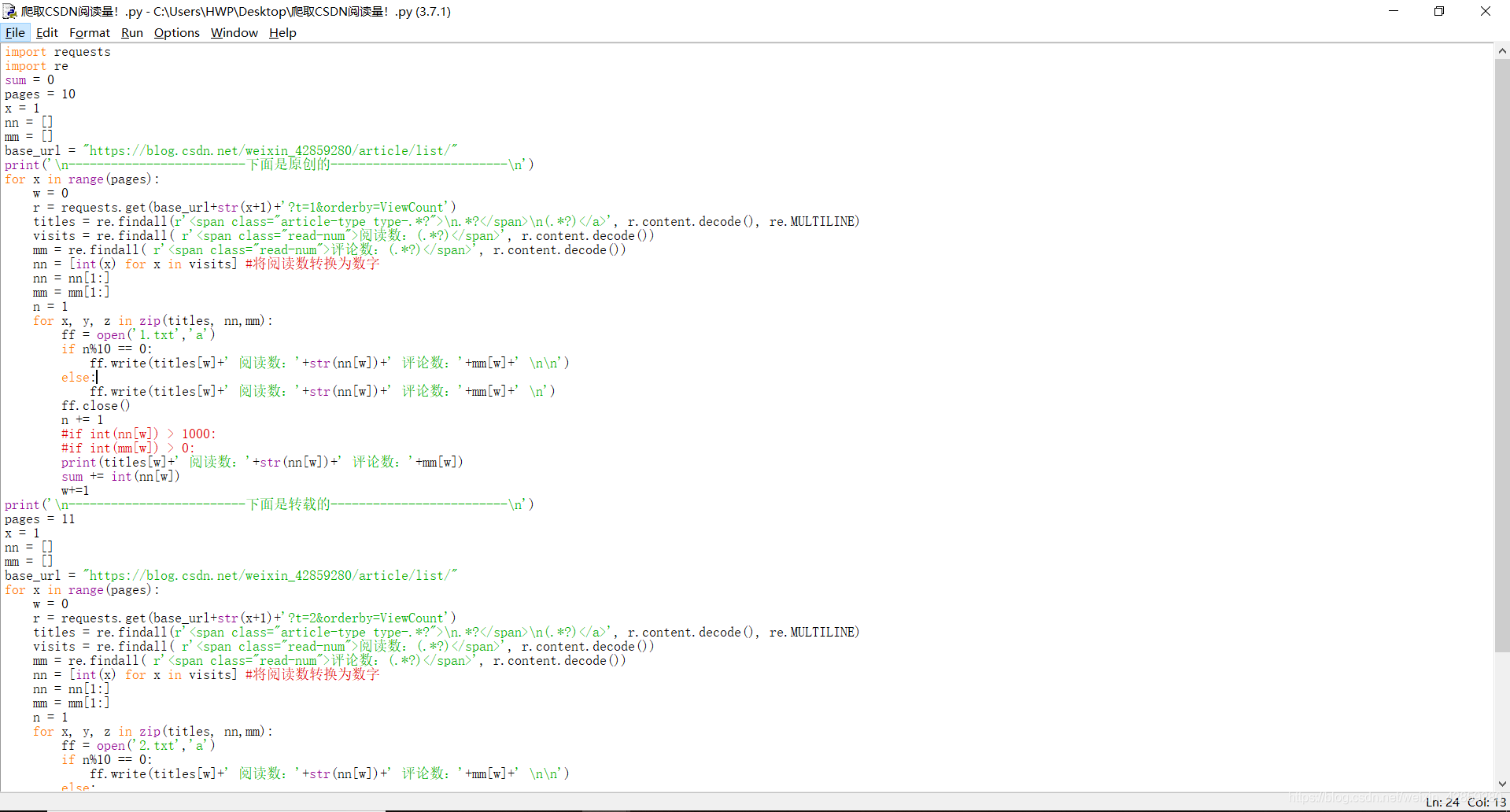
(2):
执行结果:
(1):
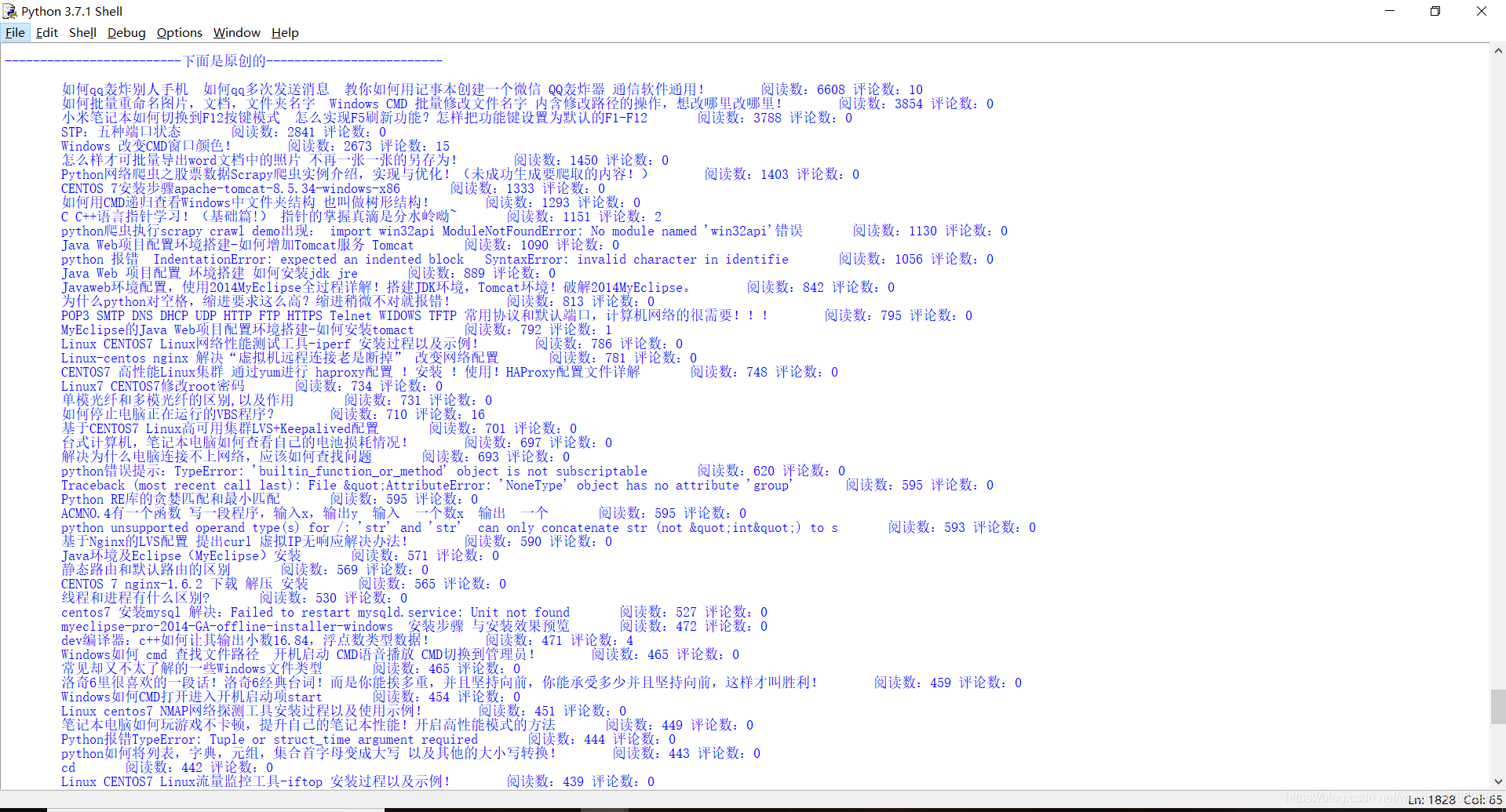
(2):

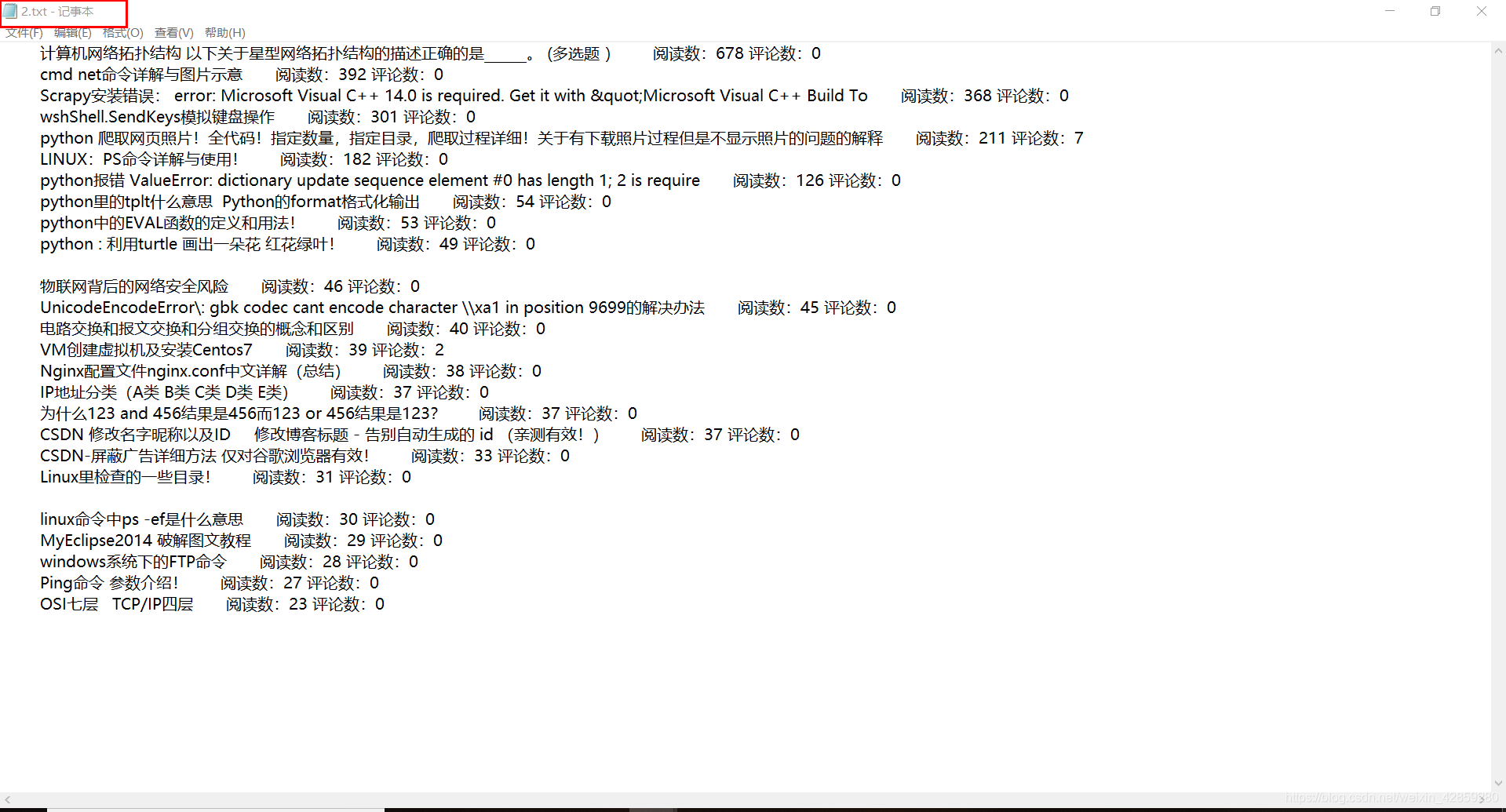
被写入文本截图:
原创:

转载:
OK,有问题欢迎来留言讨论!
关于这个方面,我写的还有别的爬虫:
功能和这个有不同!
https://blog.csdn.net/weixin_42859280/article/details/85175854
欢迎留言讨论!