在spark中《Memory usage of state in Spark Structured Streaming》讲解Spark内存分配情况,以及提到了HDFSBackedStateStoreProvider存储多个版本的影响;从stackoverflow上也可以看到别人遇到了structured streaming中内存问题,同时也对问题做了分析《Memory issue with spark structured streaming》;另外可以从spark的官网问题修复列表中查看到如下内容:
1)在流聚合中从值中删除冗余密钥数据(Split out min retain version of state for memory in HDFSBackedStateStoreProvider)
问题描述:
HDFSBackedStateStoreProvider has only one configuration for minimum versions to retain of state which applies to both memory cache and files. As default version of "spark.sql.streaming.minBatchesToRetain" is set to high (100), which doesn't require strictly 100x of memory, but I'm seeing 10x ~ 80x of memory consumption for various workloads. In addition, in some cases, requiring 2x of memory is even unacceptable, so we should split out configuration for memory and let users adjust to trade-off memory usage vs cache miss.
In normal case, default value '2' would cover both cases: success and restoring failure with less than or around 2x of memory usage, and '1' would only cover success case but no longer require more than 1x of memory. In extreme case, user can set the value to '0' to completely disable the map cache to maximize executor memory.
修复情况:
对应官网bug情况概述《[SPARK-24717][SS] Split out max retain version of state for memory in HDFSBackedStateStoreProvider #21700》、《Split out min retain version of state for memory in HDFSBackedStateStoreProvider》
相关知识:
《Spark Structrued Streaming源码分析--(三)Aggreation聚合状态存储与更新》
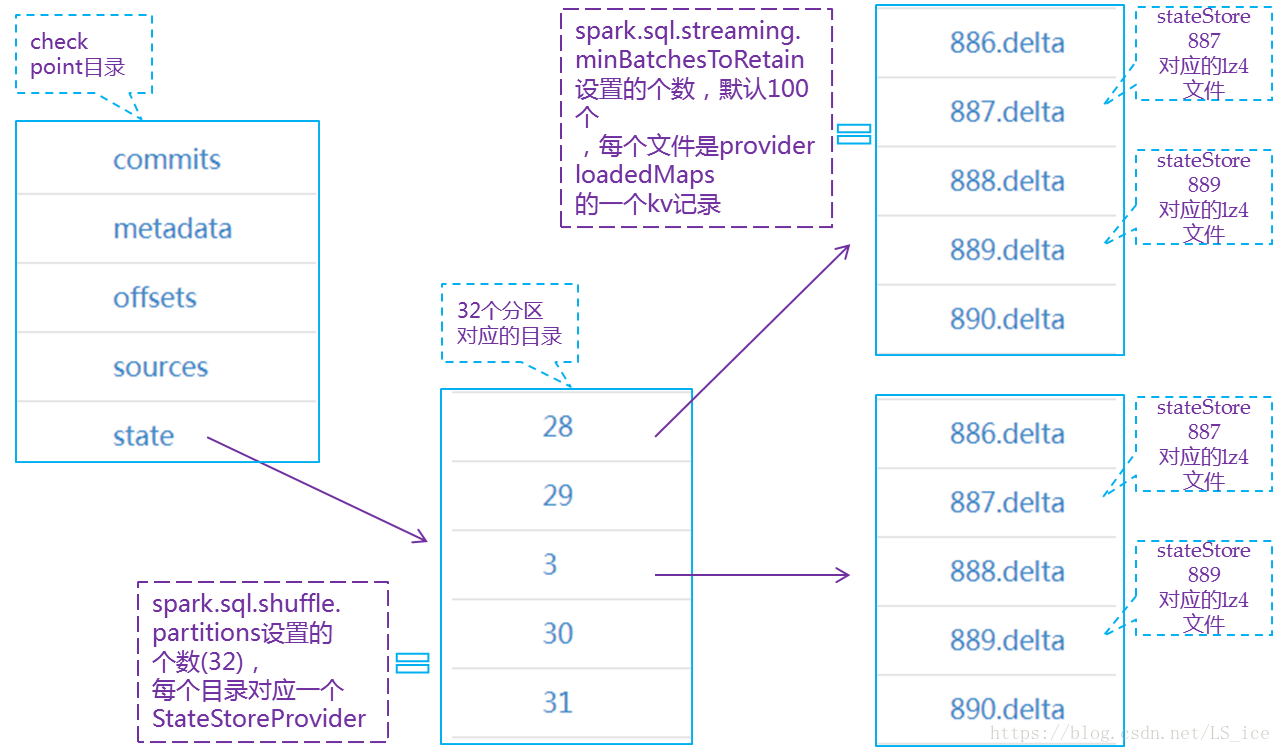
HDFSBackedStateStoreProvider存储state的目录结构在该文章中介绍的,另外这些文件是一个系列,建议可以多读读,下边借用作者文章中的图展示下state存储目录结构:
2)在HDFSBackedStateStoreProvider中为内存分配最大保留版本的状态(Remove redundant key data from value in streaming aggregation)
问题描述:
Key/Value of state in streaming aggregation is formatted as below:
- key: UnsafeRow containing group-by fields
- value: UnsafeRow containing key fields and another fields for aggregation results
which data for key is stored to both key and value.
This is to avoid doing projection row to value while storing, and joining key and value to restore origin row to boost performance, but while doing a simple benchmark test, I found it not much helpful compared to "project and join". (will paste test result in comment)
So I would propose a new option: remove redundant in stateful aggregation. I'm avoiding to modify default behavior of stateful aggregation, because state value will not be compatible between current and option enabled.
修复情况:
对应官网bug情况概述《[SPARK-24763][SS] Remove redundant key data from value in streaming aggregation #21733》、《Remove redundant key data from value in streaming aggregation》