昨日内容回顾


# 一对多的添加方式1(推荐) # book=Book.objects.create(title="水浒传",price=100,pub_date="1643-4-12",publish_id=1) # print(book.title) # 一对多的添加方式2 # publish必须接受一个对象 # xigua=Publish.objects.filter(name="西瓜出版社").first() # book=Book.objects.create(title="三国演义",price=300,pub_date="1643-4-12",publish=xigua) # print(book.title) # ### # book=Book(title="三国演义",price=300,pub_date="1643-4-12",publish=xigua) # book.save() # # # ### # book=Book() # book.title="三国演义" # book.price=300 # book.pub_date="1643-4-12" # book.publish=xigua # book.publish # 与这本书籍关联的出版社对象 # print(book.publish) # print(book.publish_id) ################################################################################ # 添加多对多关系 # book=Book.objects.create(title="python葵花宝典",price=122,pub_date="2012-12-12",publish_id=1) # alex=Author.objects.filter(name="alex").first() # egon=Author.objects.filter(name="egon").first() # jinxin=Author.objects.filter(name="jinxin").first() # book.publish=xigua # book.authors.add(alex,egon) # book.authors.add(*[alex,egon]) # author_list=Author.objects.all() # [obj,.....] # book.authors.add(*author_list) # 解除绑定的关系 # book=Book.objects.filter(id=4).first() # book.authors.clear() # book.authors.add(jinxin) # book.authors.set([jinxin,]) # book.authors.remove(alex,egon) # book.authors.remove(*[alex,egon]) # book.authors.clear() # book.authors.add(1,2) # book.authors.add(*[1,2]) ############################################# # print(book.publish) # 与这本书籍关联的出版社对象 # print(book.authors.all()) # 与这本书关联的作者对象queryset对象集合 <QuerySet [<Author: alex>, <Author: egon>, <Author: jinxin>]> # ############################################# # print(book.authors) # app01.Author.None # print(type(book.authors)) # print(book.pub_date) # 2012-12-12 2012-12-12 00:00:00+00:00 # print(type(book.pub_date)) # <class 'datetime.date'> <class 'datetime.datetime'>
一、基于双下划线的跨表查询
Django 还提供了一种直观而高效的方式在查询(lookups)中表示关联关系,它能自动确认 SQL JOIN 联系。要做跨关系查询,就使用两个下划线来链接模型(model)间关联字段的名称,直到最终链接到你想要的model 为止。
核心得学会通知ORM引擎什么时候,join哪张表
join看似复杂,实则最简单。因为把字段列出来之后,就相当于单表操作了!想怎么取值都可以!
正向查询按字段,反向查询按表名小写用来告诉ORM引擎join哪张表
返回值是QuerySet
一对多:
正向查询
返回结构是queryset()
正向查询:关联属性在book表中,所以book对象找关联出版社对象,正向查询
反向查询:关联属性在book表中,所以publish对象找关联书籍,反向查询
按字段:xx book ------------------ > publish <-------------------- 按表名小写__字段名。比如publish__name
举例:查询西游记这本书的出版社名字
先使用原生sql查询
SELECT app01_publish.name from app01_book INNER JOIN app01_publish on app01_book.publish_id = app01_publish.id WHERE app01_book.title = '西游记'
执行结果为:榴莲出版社
它的步骤为:先连表,再过滤
使用orm引擎查询
修改settings.py,最后一行添加。表示开启日志
LOGGING = { 'version': 1, 'disable_existing_loggers': False, 'handlers': { 'console':{ 'level':'DEBUG', 'class':'logging.StreamHandler', }, }, 'loggers': { 'django.db.backends': { 'handlers': ['console'], 'propagate': True, 'level':'DEBUG', }, } }
修改urls.py,增加路径query
urlpatterns = [ path('admin/', admin.site.urls), path('add/', views.add), path('query/', views.query), ]
修改views.py,增加query视图函数
def query(request): ret = Book.objects.filter(title='西游记').values("publish__name") print(ret)
解释:
Book.objects 表示基础表,它是链式编程的开始。
publish__name 表示publish表下的name字段。因为要的name字段,它不在Book表中。那么指定外部表示,需要加双下划线。注意:此表必须要和Book表有关联!
访问url:http://127.0.0.1:8000/query/
查看Pycharm控制台,输出:
<QuerySet [{'publish__name': '榴莲出版社'}]>
(0.000) SELECT "app01_publish"."name" FROM "app01_book" INNER JOIN "app01_publish" ON ("app01_book"."publish_id" = "app01_publish"."id") WHERE "app01_book"."title" = '西游记' LIMIT 21; args=('西游记',)
可以看出,ORM执行的sql和手写的sql,大致是一样的!
反向查询
举例:查询出版过西游记的出版社
def query(request): ret = Publish.objects.filter(book__title="西游记").values("name") print(ret) return HttpResponse('查询成功')
解释:
book__title 表示book表中的title字段,它不需要加引号
values("name") 表示publish表的中name字段,为什么呢?因为基础表示publish,它可以直接取name字段!
刷新页面,查看控制台输出:
(0.001) SELECT "app01_publish"."name" FROM "app01_publish" INNER JOIN "app01_book" ON ("app01_publish"."id" = "app01_book"."publish_id") WHERE "app01_book"."title" = '西游记' LIMIT 21; args=('西游记',) <QuerySet [{'name': '榴莲出版社'}]>
查询结果上面的例子是一样的。
多对多查询
正向查询:关联属性在book表中,所以book对象找关联作者集合,正向查询
反向查询:关联属性在book表中,所以author对象找关联书籍,反向查询
正 按字段:xx book ------------------------- > author <------------------------- 反 按表名小写__字段名
正向查询
举例:查询西游记这本书籍的所有作者的姓名和年龄
先用原生sql查询
SELECT app01_author.name,app01_author.age from app01_book INNER JOIN app01_book_authors on app01_book_authors.book_id = app01_book.id INNER JOIN app01_author on app01_book_authors.author_id = app01_author.id WHERE app01_book.title = '西游记'
涉及到3表查询,查询结果为:

使用orm引擎查询
def query(request): ret = Book.objects.filter(title="西游记").values("authors__name","authors__age") print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
<QuerySet [{'authors__name': 'xiao', 'authors__age': 25}]>
(0.001) SELECT "app01_author"."name", "app01_author"."age" FROM "app01_book" LEFT OUTER JOIN "app01_book_authors" ON ("app01_book"."id" = "app01_book_authors"."book_id") LEFT OUTER JOIN "app01_author" ON ("app01_book_authors"."author_id" = "app01_author"."id") WHERE "app01_book"."title" = '西游记' LIMIT 21; args=('西游记',)
解释:
由于book表和author表是多对多关系,所以使用ORM查询时,它会自动对应关系
authors__name 表示author表的name字段
那么使用ORM处理多表,就显得很简单了!
反向查询
还是上面的需求,以author为基础表查询
def query(request): ret = Author.objects.filter(book__title="西游记").values("name","age") print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
<QuerySet [{'name': 'xiao', 'age': 25}]>
(0.002) SELECT "app01_author"."name", "app01_author"."age" FROM "app01_author" INNER JOIN "app01_book_authors" ON ("app01_author"."id" = "app01_book_authors"."author_id") INNER JOIN "app01_book" ON ("app01_book_authors"."book_id" = "app01_book"."id") WHERE "app01_book"."title" = '西游记' LIMIT 21; args=('西游记',)
执行结果同上!
一对一
正向查询:关联属性在authordetail表中,所以author对象找关联作者详情,正向查询
反向查询:关联属性在author表中,所以authordetail对象找关联作者信息,反向查询
正向: 按字段:.ad author ------------------------- > authordetail <------------------------- 反向: 按表名小写 authordetail_obj.author
正向查询
举例:查询xiao的女朋友名字
def query(request): ret = Author.objects.filter(name="xiao").values("ad__gf") print(ret) return HttpResponse('查询成功')
解释:ORM查询时,会自动对应关系。ad__gf表示authordetail表的gf字段
刷新页面,查看控制台输出:
<QuerySet [{'ad__gf': '赵丽颖'}]>
(0.001) SELECT "app01_authordetail"."gf" FROM "app01_author" INNER JOIN "app01_authordetail" ON ("app01_author"."ad_id" = "app01_authordetail"."id") WHERE "app01_author"."name" = 'xiao' LIMIT 21; args=('xiao',)
反向查询
还是上面的需求,以authordetail表为基础表查询
def query(request): ret = AuthorDetail.objects.filter(author__name="xiao").values("gf") print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
<QuerySet [{'gf': '赵丽颖'}]>
(0.002) SELECT "app01_authordetail"."gf" FROM "app01_authordetail" INNER JOIN "app01_author" ON ("app01_authordetail"."id" = "app01_author"."ad_id") WHERE "app01_author"."name" = 'xiao' LIMIT 21; args=('xiao',)
进阶练习(连续跨表)
举例1
查询榴莲出版社出版过的所有书籍的名字以及作者的姓名
正向查询
def query(request): ret = Book.objects.filter(publish__name="榴莲出版社").values_list("title","authors__name") print(ret) return HttpResponse('查询成功')
解释:
book表示连接出版社和作者的核心表。以它为基础表查询,比较好处理!
publish__name 表示publish表的name字段。
authors__name表示book_authors表(book和author的关系表)的name字段。
刷新页面,查看控制台输出:
<QuerySet [('西游记', 'xiao')]> (0.000) SELECT "app01_book"."title", "app01_author"."name" FROM "app01_book" INNER JOIN "app01_publish" ON ("app01_book"."publish_id" = "app01_publish"."id") LEFT OUTER JOIN "app01_book_authors" ON ("app01_book"."id" = "app01_book_authors"."book_id") LEFT OUTER JOIN "app01_author" ON ("app01_book_authors"."author_id" = "app01_author"."id") WHERE "app01_publish"."name" = '榴莲出版社' LIMIT 21; args=('榴莲出版社',)
反向查询
还是上面的需求,以publish表为基础表查询
def query(request): ret = Publish.objects.filter(name="榴莲出版社").values_list("book__title","book__authors__age","book__authors__name") print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
<QuerySet [('西游记', 25, 'xiao')]> (0.001) SELECT "app01_book"."title", "app01_author"."age", "app01_author"."name" FROM "app01_publish" LEFT OUTER JOIN "app01_book" ON ("app01_publish"."id" = "app01_book"."publish_id") LEFT OUTER JOIN "app01_book_authors" ON ("app01_book"."id" = "app01_book_authors"."book_id") LEFT OUTER JOIN "app01_author" ON ("app01_book_authors"."author_id" = "app01_author"."id") WHERE "app01_publish"."name" = '榴莲出版社' LIMIT 21; args=('榴莲出版社',)
举例2
手机号以11开头的作者出版过的所有书籍名称以及出版社名称
提示:涉及到5表查询!
先使用原生sql查询
SELECT app01_book.title,a01p.name from app01_book INNER JOIN app01_book_authors as a on app01_book.id = a.book_id INNER JOIN app01_author as a3 on a.author_id = a3.id INNER JOIN app01_authordetail as a2 on a3.ad_id = a2.id INNER JOIN app01_publish as a01p on app01_book.publish_id = a01p.id WHERE a2.tel like '11%'
执行结果:

使用orm引擎查询
正向查询:
def query(request): ret = Book.objects.filter(authors__ad__tel__startswith="11").values("title","publish__name") print(ret) return HttpResponse('查询成功')
解释:
authors__ad__tel 表示book_authors表,author表的ad字段,authordetail表的tel字段,做关联查询。
__startswith 表示以什么开头,它会使用like查询,比如'11%'
"title","publish__name" 分别表示book表的title字段,publish表的name字段
刷新页面,查看控制台输出:
<QuerySet [{'title': 'python', 'publish__name': '西瓜出版社'}, {'title': 'python', 'publish__name': '西瓜出版社'}, {'title': 'python', 'publish__name': '西瓜出版社'}, {'title': '西游记', 'publish__name': '榴莲出版社'}, {'title': '三国演义', 'publish__name': '西瓜出版社'}]>
(0.001) SELECT "app01_book"."title", "app01_publish"."name" FROM "app01_book" INNER JOIN "app01_book_authors" ON ("app01_book"."id" = "app01_book_authors"."book_id") INNER JOIN "app01_author" ON ("app01_book_authors"."author_id" = "app01_author"."id") INNER JOIN "app01_authordetail" ON ("app01_author"."ad_id" = "app01_authordetail"."id") INNER JOIN "app01_publish" ON ("app01_book"."publish_id" = "app01_publish"."id") WHERE "app01_authordetail"."tel" LIKE '11%' ESCAPE '\' LIMIT 21; args=('11%',)
反向查询:
def query(request): ret = Author.objects.filter(ad__tel__startswith="11").values("book__title","book__publish__name") print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
<QuerySet [{'book__publish__name': '西瓜出版社', 'book__title': 'python'}, {'book__publish__name': '榴莲出版社', 'book__title': '西游记'}, {'book__publish__name': '西瓜出版社', 'book__title': 'python'}, {'book__publish__name': '西瓜出版社', 'book__title': '三国演义'}, {'book__publish__name': '西瓜出版社', 'book__title': 'python'}]>
(0.001) SELECT "app01_book"."title", "app01_publish"."name" FROM "app01_author" INNER JOIN "app01_authordetail" ON ("app01_author"."ad_id" = "app01_authordetail"."id") LEFT OUTER JOIN "app01_book_authors" ON ("app01_author"."id" = "app01_book_authors"."author_id") LEFT OUTER JOIN "app01_book" ON ("app01_book_authors"."book_id" = "app01_book"."id") LEFT OUTER JOIN "app01_publish" ON ("app01_book"."publish_id" = "app01_publish"."id") WHERE "app01_authordetail"."tel" LIKE '11%' ESCAPE '\' LIMIT 21; args=('11%',)
二、聚合查询
聚合 是aggreate(*args,**kwargs),通过QuerySet 进行计算。做求值运算的时候使用
主要有Sum,Avg,Max,Min。使用前,需要导入模块
from django.db.models import Sum,Avg,Max,Min,Count
Sum (总和)
返回值是一个字典
举例:查询所有书籍的总价格
def query(request): ret = Book.objects.all().aggregate(Sum("price")) print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
{'price__sum': Decimal('522.00')}
(0.001) SELECT CAST(SUM("app01_book"."price") AS NUMERIC) AS "price__sum" FROM "app01_book"; args=()
[02/Jul/2018 21:45:26] "GET /query/ HTTP/1.1" 200 12
Avg (平均值)
返回值是一个字典
举例:查询所有书籍的平均价格
使用原生sql查询
select avg(price) from app01_book
执行输出:174
使用orm引擎查询
def query(request): ret = Book.objects.all().aggregate(Avg("price")) print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
(0.001) SELECT AVG("app01_book"."price") AS "price__avg" FROM "app01_book"; args=() [02/Jul/2018 21:38:42] "GET /query/ HTTP/1.1" 200 12 {'price__avg': 174.0}
aggregate()是QuerySet 的一个终止子句,意思是说,它返回一个包含一些键值对的字典。键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。如果你想要为聚合值指定一个名称,可以向聚合子句提供它。
对返回的key起别名
def query(request): ret = Book.objects.all().aggregate(avg = Avg("price")) print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
{'avg': 174.0}
(0.001) SELECT AVG("app01_book"."price") AS "avg" FROM "app01_book"; args=()
Max 和Min
返回值是一个字典
如果你希望生成不止一个聚合,你可以向aggregate()子句中添加另一个参数。
举例:所有图书价格的最大值和最小值
def query(request): ret = Book.objects.aggregate(Avg('price'), Max('price'), Min('price')) print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
{'price__avg': 174.0, 'price__min': Decimal('100.00'), 'price__max': Decimal('300.00')}
(0.001) SELECT AVG("app01_book"."price") AS "price__avg", CAST(MIN("app01_book"."price") AS NUMERIC) AS "price__min", CAST(MAX("app01_book"."price") AS NUMERIC) AS "price__max" FROM "app01_book"; args=()
Count (统计结果行数)
举例:查询西瓜出版社总共出版过多少本书籍
def query(request): ret = Book.objects.all().aggregate(count = Count("id")) print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
{'count': 3}
(0.001) SELECT COUNT("app01_book"."id") AS "count" FROM "app01_book"; args=()
三、分组查询
分组:将查询结果按照某个字段或多个字段进行分组。字段中值相等的为一组!
annotate()为调用的QuerySet中每一个对象都生成一个独立的统计值(统计方法用聚合函数)。
单表查询
修改models.py,增加一个模型表
class Emp(models.Model): name=models.CharField(max_length=32) age=models.IntegerField() salary=models.DecimalField(max_digits=8,decimal_places=2) dep=models.CharField(max_length=32) province=models.CharField(max_length=32)
使用2个命令生成表
python manage.py makemigrations
python manage.py migrate
使用sql插入3条数据,注意修改应用名
INSERT INTO `app01_emp` (`id`, `name`, `age`, `salary`, `dep`, `province`) VALUES (1, 'zhang', 26, 4000, '保洁部', '山东省'); INSERT INTO `app01_emp` (`id`, `name`, `age`, `salary`, `dep`, `province`) VALUES (2, 'li', 25, 3500, '保洁部', '北京'); INSERT INTO `app01_emp` (`id`, `name`, `age`, `salary`, `dep`, `province`) VALUES (3, 'wang', 27, 5000, '公关部', '北京');
举例1:查询每一个部门的平均薪水
使用原生sql查询
select dep,avg(salary) from app01_emp GROUP BY dep
使用orm引擎查询
导入emp表
from app01.models import Book,Publish,Author,AuthorDetail,Emp
修改视图函数
<QuerySet [{'dep': '保洁部', 'avg_salary': 3750.0}, {'dep': '公关部', 'avg_salary': 5000.0}]>
(0.000) SELECT "app01_emp"."dep", AVG("app01_emp"."salary") AS "avg_salary" FROM "app01_emp" GROUP BY "app01_emp"."dep" LIMIT 21; args=()
解释:
values("dep") 表示以dep字段进行分组
avg_salary 表示为字段起别名
Avg("salary") 表示取平均数
刷新页面,查看控制台输出:
<QuerySet [{'salary__avg': 3750.0, 'dep': '保洁部'}, {'salary__avg': 5000.0, 'dep': '公关部'}]>
(0.001) SELECT "app01_emp"."dep", AVG("app01_emp"."salary") AS "salary__avg" FROM "app01_emp" GROUP BY "app01_emp"."dep" LIMIT 21; args=()
举例2:查询每一个省/直辖市对应的人数
def query(request): ret = Emp.objects.values("province").annotate(Count("id")) print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
<QuerySet [{'id__count': 2, 'province': '北京'}, {'id__count': 1, 'province': '山东省'}]>
(0.002) SELECT "app01_emp"."province", COUNT("app01_emp"."id") AS "id__count" FROM "app01_emp" GROUP BY "app01_emp"."province" LIMIT 21; args=()
总结:
单表.objects.values('group by 字段').annotate(统计字段)
多表查询
举例1:查询每一个出版社的名称,以及对应书籍的平均价格
使用原生sql查询
select app01_publish.name,avg(app01_book.price) from app01_book INNER JOIN app01_publish ON app01_publish.id = app01_book.publish_id GROUP BY app01_publish.id
查询结果:
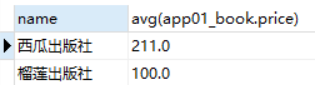
使用orm引擎查询
def query(request): ret = Publish.objects.values("id").annotate(avg=Avg("book__price")).values("name","avg") print(ret) return HttpResponse('查询成功')
解释:
values("id") 以id字段进行分组
avg=Avg("book__price") 表示将关联的book表的price字段,计算平均数。avg表示起别名
values("name","avg") 取出name和avg字段
刷新页面,查看控制台输出:
<QuerySet [{'name': '西瓜出版社', 'avg': 211.0}, {'name': '榴莲出版社', 'avg': 100.0}]>
(0.000) SELECT "app01_publish"."name", AVG("app01_book"."price") AS "avg" FROM "app01_publish" LEFT OUTER JOIN "app01_book" ON ("app01_publish"."id" = "app01_book"."publish_id") GROUP BY "app01_publish"."id", "app01_publish"."name" LIMIT 21; args=()
举例2:查询每一本书籍的名称以及作者个数
def query(request): ret = Book.objects.values("id").annotate(count=Count("authors__name")).values("title","count") print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
<QuerySet [{'title': 'python', 'count': 3}, {'title': '三国演义', 'count': 1}, {'title': '西游记', 'count': 1}]>
(0.001) SELECT "app01_book"."title", COUNT("app01_author"."name") AS "count" FROM "app01_book" LEFT OUTER JOIN "app01_book_authors" ON ("app01_book"."id" = "app01_book_authors"."book_id") LEFT OUTER JOIN "app01_author" ON ("app01_book_authors"."author_id" = "app01_author"."id") GROUP BY "app01_book"."id", "app01_book"."title" LIMIT 21; args=()
举例3:查询大于一个作者的书籍名称
def query(request): ret = Book.objects.values("id").annotate(count=Count("authors__name")).filter(count__gt=1).values("title","count") print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
<QuerySet [{'title': 'python', 'count': 3}]>
(0.001) SELECT "app01_book"."title", COUNT("app01_author"."name") AS "count" FROM "app01_book" LEFT OUTER JOIN "app01_book_authors" ON ("app01_book"."id" = "app01_book_authors"."book_id") LEFT OUTER JOIN "app01_author" ON ("app01_book_authors"."author_id" = "app01_author"."id") GROUP BY "app01_book"."id", "app01_book"."title" HAVING COUNT("app01_author"."name") > 1 LIMIT 21;
注意:它使用了HAVING
总结:
跨表分组查询本质就是将关联表join成一张表,再按单表的思路进行分组查询。
1 确定是否是多表分组 2 如果是多表分组,确定分组条件(group by哪一个字段) 3 语法: 每一个后跟的表A.objects.values("id").annotate("统计函数(与A表关联的B表下的某个字段)")
查询练习
举例1:统计每一个出版社的最便宜书籍的价格
def query(request): ret = Publish.objects.annotate(MinPrice=Min("book__price")).values_list("name","MinPrice") print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
<QuerySet [('西瓜出版社', Decimal('122.00')), ('榴莲出版社', Decimal('100.00'))]> (0.001) SELECT "app01_publish"."name", CAST(MIN("app01_book"."price") AS NUMERIC) AS "MinPrice" FROM "app01_publish" LEFT OUTER JOIN "app01_book" ON ("app01_publish"."id" = "app01_book"."publish_id") GROUP BY "app01_publish"."id", "app01_publish"."name", "app01_publish"."email", "app01_publish"."addr" LIMIT 21; args=()
举例2:统计每一本书的作者个数
def query(request): ret = Book.objects.annotate(authorsNum=Count('authors__name')).values() print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
<QuerySet [{'publish_id': 2, 'authorsNum': 1, 'pub_date': datetime.date(1743, 4, 12), 'id': 1, 'title': '西游记', 'price': Decimal('100.00')}, {'publish_id': 1, 'authorsNum': 1, 'pub_date': datetime.date(1643, 4, 12), 'id': 2, 'title': '三国演义', 'price': Decimal('300.00')}, {'publish_id': 1, 'authorsNum': 3, 'pub_date': datetime.date(2012, 12, 12), 'id': 3, 'title': 'python', 'price': Decimal('122.00')}]>
(0.001) SELECT "app01_book"."id", "app01_book"."title", "app01_book"."price", "app01_book"."pub_date", "app01_book"."publish_id", COUNT("app01_author"."name") AS "authorsNum" FROM "app01_book" LEFT OUTER JOIN "app01_book_authors" ON ("app01_book"."id" = "app01_book_authors"."book_id") LEFT OUTER JOIN "app01_author" ON ("app01_book_authors"."author_id" = "app01_author"."id") GROUP BY "app01_book"."id", "app01_book"."title", "app01_book"."price", "app01_book"."pub_date", "app01_book"."publish_id" LIMIT 21; args=()
举例3:统计每一本以py开头的书籍的作者个数
def query(request): ret = Book.objects.filter(title__startswith="Py").annotate(num_authors=Count('authors')) print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
<QuerySet [{'title': 'python', 'price': Decimal('122.00'), 'id': 3, 'pub_date': datetime.date(2012, 12, 12), 'publish_id': 1, 'num_authors': 3}]>
(0.001) SELECT "app01_book"."id", "app01_book"."title", "app01_book"."price", "app01_book"."pub_date", "app01_book"."publish_id", COUNT("app01_book_authors"."author_id") AS "num_authors" FROM "app01_book" LEFT OUTER JOIN "app01_book_authors" ON ("app01_book"."id" = "app01_book_authors"."book_id") WHERE "app01_book"."title" LIKE 'Py%' ESCAPE '\' GROUP BY "app01_book"."id", "app01_book"."title", "app01_book"."price", "app01_book"."pub_date", "app01_book"."publish_id" LIMIT 21; args=('Py%',)
举例4:根据一本图书作者数量的多少对查询集 QuerySet进行排序
def query(request): ret = Book.objects.annotate(num_authors=Count('authors')).order_by('num_authors').values() print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
<QuerySet [{'title': '西游记', 'publish_id': 2, 'pub_date': datetime.date(1743, 4, 12), 'price': Decimal('100.00'), 'id': 1, 'num_authors': 1}, {'title': '三国演义', 'publish_id': 1, 'pub_date': datetime.date(1643, 4, 12), 'price': Decimal('300.00'), 'id': 2, 'num_authors': 1}, {'title': 'python', 'publish_id': 1, 'pub_date': datetime.date(2012, 12, 12), 'price': Decimal('122.00'), 'id': 3, 'num_authors': 3}]>
(0.001) SELECT "app01_book"."id", "app01_book"."title", "app01_book"."price", "app01_book"."pub_date", "app01_book"."publish_id", COUNT("app01_book_authors"."author_id") AS "num_authors" FROM "app01_book" LEFT OUTER JOIN "app01_book_authors" ON ("app01_book"."id" = "app01_book_authors"."book_id") GROUP BY "app01_book"."id", "app01_book"."title", "app01_book"."price", "app01_book"."pub_date", "app01_book"."publish_id" ORDER BY "num_authors" ASC LIMIT 21; args=()
举例5:查询各个作者出的书的总价格
def query(request): ret = Author.objects.annotate(SumPrice=Sum("book__price")).values("name","SumPrice") print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
<QuerySet [{'SumPrice': Decimal('222.00'), 'name': 'xiao'}, {'SumPrice': Decimal('422.00'), 'name': 'zhang'}, {'SumPrice': Decimal('122.00'), 'name': 'wang'}, {'SumPrice': None, 'name': 'hong'}]>
(0.001) SELECT "app01_author"."name", CAST(SUM("app01_book"."price") AS NUMERIC) AS "SumPrice" FROM "app01_author" LEFT OUTER JOIN "app01_book_authors" ON ("app01_author"."id" = "app01_book_authors"."author_id") LEFT OUTER JOIN "app01_book" ON ("app01_book_authors"."book_id" = "app01_book"."id") GROUP BY "app01_author"."id", "app01_author"."name", "app01_author"."age", "app01_author"."ad_id" LIMIT 21; args=()
四、F查询
F() 专门取对象中某列值的操作
F()允许Django在未实际链接数据的情况下具有对数据库字段的值的引用。通常情况下我们在更新数据时需要先从数据库里将原数据取出后方在内存里,然后编辑某些属性,最后提交。
在上面所有的例子中,我们构造的过滤器都只是将字段值与某个常量做比较。如果我们要对两个字段的值做比较,那该怎么做呢?
Django 提供 F() 来做这样的比较。F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值。
修改models.py,增加3个字段
class Book(models.Model): title=models.CharField(max_length=32,unique=True) price=models.DecimalField(max_digits=8,decimal_places=2,null=True) pub_date=models.DateField() publish=models.ForeignKey(to="Publish",to_field="id",on_delete=models.CASCADE) authors=models.ManyToManyField(to="Author") comment_count=models.IntegerField(default=0) up_count=models.IntegerField(default=0) read_count = models.IntegerField(default=0)
使用2个命令生成表
python manage.py makemigrations
python manage.py migrate
使用sql语句更新数据,注意:修改应用名
UPDATE app01_book SET comment_count=123, read_count=1231, up_count=2 WHERE id=1; UPDATE app01_book SET comment_count=231, read_count=132, up_count=33 WHERE id=2; UPDATE app01_book SET comment_count=332, read_count=123, up_count=12 WHERE id=3;
举例1:查询评论数大于收藏数的书籍
常规写法是不能执行的
ret = Book.objects.filter(comment_count__gt=read_count)
正确写法
使用F查询,需要导入模块
from django.db.models import F
然后使用F查询
def query(request): ret = Book.objects.filter(comment_count__gt=F("read_count")).values("title") print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
(0.000) SELECT "django_migrations"."app", "django_migrations"."name" FROM "django_migrations"; args=() (0.000) SELECT "app01_book"."title" FROM "app01_book" WHERE "app01_book"."comment_count" > ("app01_book"."read_count") LIMIT 21; args=() <QuerySet [{'title': '三国演义'}, {'title': 'python'}]>
Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作。
举例2:查询评论数大于收藏数2倍的书籍
def query(request): ret = Book.objects.filter(comment_count__gt=F('up_count')*2).values("title") print(ret) return HttpResponse('查询成功')
解释:
comment_count 表示评论字段
__gt 表示大于
刷新页面,查看控制台输出:
(0.001) SELECT "app01_book"."title" FROM "app01_book" WHERE "app01_book"."comment_count" > (("app01_book"."up_count" * 2)) LIMIT 21; args=(2,) <QuerySet [{'title': '西游记'}, {'title': '三国演义'}, {'title': 'python'}]>
修改操作也可以使用F函数
举例:将每一本书的价格提高30元
def query(request): Book.objects.all().update(price=F("price")+30) # 更新 ret = Book.objects.all().values("title","price") #查询 print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
(0.006) UPDATE "app01_book" SET "price" = CAST(("app01_book"."price" + 30) AS NUMERIC); args=(30,) (0.001) SELECT "app01_book"."title", "app01_book"."price" FROM "app01_book" LIMIT 21; args=() <QuerySet [{'title': '西游记', 'price': Decimal('160.00')}, {'title': '三国演义', 'price': Decimal('360.00')}, {'title': 'python', 'price': Decimal('182.00')}]>
五、Q查询
Q() 对对象的复杂查询
Q对象(django.db.models.Q)可以对关键字参数进行封装,从而更好地应用多个查询。可以组合使用 &(and),(or),~(not)操作符,当一个操作符是用于两个Q的对象,它产生一个新的Q对象。
filter() 等方法中的关键字参数查询都是一起进行“AND” 的。 如果你需要执行更复杂的查询(例如OR 语句),你可以使用Q 对象。
使用Q查询,需要导入模块
from django.db.models import Q
举例:分别查询作者xiao、zhang出版过的书籍名称
Q 对象可以使用& 和| 操作符组合起来。当一个操作符在两个Q 对象上使用时,它产生一个新的Q 对象。
def query(request): ret = Book.objects.filter(Q(authors__name="xiao")|Q(authors__name="zhang")).values("title") print(ret) return HttpResponse('查询成功')
等同于下面的SQL WHERE 子句:
WHERE name ="xiao" OR name ="zhang"
刷新页面,查看控制台输出:
<QuerySet [{'title': 'python'}, {'title': 'python'}, {'title': '西游记'}, {'title': '三国演义'}]>
(0.001) SELECT "app01_book"."title" FROM "app01_book" INNER JOIN "app01_book_authors" ON ("app01_book"."id" = "app01_book_authors"."book_id") INNER JOIN "app01_author" ON ("app01_book_authors"."author_id" = "app01_author"."id") WHERE ("app01_author"."name" = 'xiao' OR "app01_author"."name" = 'zhang') LIMIT 21; args=('xiao', 'zhang')
你可以组合& 和| 操作符以及使用括号进行分组来编写任意复杂的Q 对象。同时,Q 对象可以使用~ 操作符取反,这允许组合正常的查询和取反(NOT) 查询:
举例:查询作者xiao不在2017出版过的所有书籍
def query(request): ret = Book.objects.filter(Q(authors__name="xiao") & ~Q(pub_date__year=2017)).values("title") print(ret) return HttpResponse('查询成功')
等同于下面的where语句
WHERE ("app01_author"."name" = 'xiao' AND NOT ("app01_book"."pub_date" BETWEEN '2017-01-01' AND '2017-12-31'))
刷新页面,查看控制台输出:
<QuerySet [{'title': 'python'}, {'title': '西游记'}]>
(0.001) SELECT "app01_book"."title" FROM "app01_book" INNER JOIN "app01_book_authors" ON ("app01_book"."id" = "app01_book_authors"."book_id") INNER JOIN "app01_author" ON ("app01_book_authors"."author_id" = "app01_author"."id") WHERE ("app01_author"."name" = 'xiao' AND NOT ("app01_book"."pub_date" BETWEEN '2017-01-01' AND '2017-12-31')) LIMIT 21; args=('xiao', '2017-01-01', '2017-12-31')
查询函数可以混合使用Q 对象和关键字参数。所有提供给查询函数的参数(关键字参数或Q 对象)都将"AND”在一起。但是,如果出现Q 对象,它必须位于所有关键字参数的前面。
举例:查询书籍名称中包含 "python",且python不区分大小写。在2012年或者2017年是否出版过
def query(request): ret = Book.objects.filter(Q(pub_date__year=2012) | Q(pub_date__year=2017),title__icontains="python").values("title") print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
<QuerySet [{'title': 'python'}]>
(0.000) SELECT "app01_book"."title" FROM "app01_book" WHERE (("app01_book"."pub_date" BETWEEN '2012-01-01' AND '2012-12-31' OR "app01_book"."pub_date" BETWEEN '2017-01-01' AND '2017-12-31') AND "app01_book"."title" LIKE '%python%' ESCAPE '\') LIMIT 21; args=('2012-01-01', '2012-12-31', '2017-01-01', '2017-12-31', '%python%')
参考资料:
转载声明:
作者:肖祥
出处: https://www.cnblogs.com/xiao987334176/
昨日内容回顾
# 一对多的添加方式1(推荐) # book=Book.objects.create(title="水浒传",price=100,pub_date="1643-4-12",publish_id=1) # print(book.title) # 一对多的添加方式2 # publish必须接受一个对象 # xigua=Publish.objects.filter(name="西瓜出版社").first() # book=Book.objects.create(title="三国演义",price=300,pub_date="1643-4-12",publish=xigua) # print(book.title) # ### # book=Book(title="三国演义",price=300,pub_date="1643-4-12",publish=xigua) # book.save() # # # ### # book=Book() # book.title="三国演义" # book.price=300 # book.pub_date="1643-4-12" # book.publish=xigua # book.publish # 与这本书籍关联的出版社对象 # print(book.publish) # print(book.publish_id) ################################################################################ # 添加多对多关系 # book=Book.objects.create(title="python葵花宝典",price=122,pub_date="2012-12-12",publish_id=1) # alex=Author.objects.filter(name="alex").first() # egon=Author.objects.filter(name="egon").first() # jinxin=Author.objects.filter(name="jinxin").first() # book.publish=xigua # book.authors.add(alex,egon) # book.authors.add(*[alex,egon]) # author_list=Author.objects.all() # [obj,.....] # book.authors.add(*author_list) # 解除绑定的关系 # book=Book.objects.filter(id=4).first() # book.authors.clear() # book.authors.add(jinxin) # book.authors.set([jinxin,]) # book.authors.remove(alex,egon) # book.authors.remove(*[alex,egon]) # book.authors.clear() # book.authors.add(1,2) # book.authors.add(*[1,2]) ############################################# # print(book.publish) # 与这本书籍关联的出版社对象 # print(book.authors.all()) # 与这本书关联的作者对象queryset对象集合 <QuerySet [<Author: alex>, <Author: egon>, <Author: jinxin>]> # ############################################# # print(book.authors) # app01.Author.None # print(type(book.authors)) # print(book.pub_date) # 2012-12-12 2012-12-12 00:00:00+00:00 # print(type(book.pub_date)) # <class 'datetime.date'> <class 'datetime.datetime'>
一、基于双下划线的跨表查询
Django 还提供了一种直观而高效的方式在查询(lookups)中表示关联关系,它能自动确认 SQL JOIN 联系。要做跨关系查询,就使用两个下划线来链接模型(model)间关联字段的名称,直到最终链接到你想要的model 为止。
核心得学会通知ORM引擎什么时候,join哪张表
join看似复杂,实则最简单。因为把字段列出来之后,就相当于单表操作了!想怎么取值都可以!
正向查询按字段,反向查询按表名小写用来告诉ORM引擎join哪张表
返回值是QuerySet
一对多:
正向查询
返回结构是queryset()
正向查询:关联属性在book表中,所以book对象找关联出版社对象,正向查询
反向查询:关联属性在book表中,所以publish对象找关联书籍,反向查询
按字段:xx book ------------------ > publish <-------------------- 按表名小写__字段名。比如publish__name
举例:查询西游记这本书的出版社名字
先使用原生sql查询
SELECT app01_publish.name from app01_book INNER JOIN app01_publish on app01_book.publish_id = app01_publish.id WHERE app01_book.title = '西游记'
执行结果为:榴莲出版社
它的步骤为:先连表,再过滤
使用orm引擎查询
修改settings.py,最后一行添加。表示开启日志
LOGGING = { 'version': 1, 'disable_existing_loggers': False, 'handlers': { 'console':{ 'level':'DEBUG', 'class':'logging.StreamHandler', }, }, 'loggers': { 'django.db.backends': { 'handlers': ['console'], 'propagate': True, 'level':'DEBUG', }, } }
修改urls.py,增加路径query
urlpatterns = [ path('admin/', admin.site.urls), path('add/', views.add), path('query/', views.query), ]
修改views.py,增加query视图函数
def query(request): ret = Book.objects.filter(title='西游记').values("publish__name") print(ret)
解释:
Book.objects 表示基础表,它是链式编程的开始。
publish__name 表示publish表下的name字段。因为要的name字段,它不在Book表中。那么指定外部表示,需要加双下划线。注意:此表必须要和Book表有关联!
访问url:http://127.0.0.1:8000/query/
查看Pycharm控制台,输出:
<QuerySet [{'publish__name': '榴莲出版社'}]>
(0.000) SELECT "app01_publish"."name" FROM "app01_book" INNER JOIN "app01_publish" ON ("app01_book"."publish_id" = "app01_publish"."id") WHERE "app01_book"."title" = '西游记' LIMIT 21; args=('西游记',)
可以看出,ORM执行的sql和手写的sql,大致是一样的!
反向查询
举例:查询出版过西游记的出版社
def query(request): ret = Publish.objects.filter(book__title="西游记").values("name") print(ret) return HttpResponse('查询成功')
解释:
book__title 表示book表中的title字段,它不需要加引号
values("name") 表示publish表的中name字段,为什么呢?因为基础表示publish,它可以直接取name字段!
刷新页面,查看控制台输出:
(0.001) SELECT "app01_publish"."name" FROM "app01_publish" INNER JOIN "app01_book" ON ("app01_publish"."id" = "app01_book"."publish_id") WHERE "app01_book"."title" = '西游记' LIMIT 21; args=('西游记',) <QuerySet [{'name': '榴莲出版社'}]>
查询结果上面的例子是一样的。
多对多查询
正向查询:关联属性在book表中,所以book对象找关联作者集合,正向查询
反向查询:关联属性在book表中,所以author对象找关联书籍,反向查询
正 按字段:xx book ------------------------- > author <------------------------- 反 按表名小写__字段名
正向查询
举例:查询西游记这本书籍的所有作者的姓名和年龄
先用原生sql查询
SELECT app01_author.name,app01_author.age from app01_book INNER JOIN app01_book_authors on app01_book_authors.book_id = app01_book.id INNER JOIN app01_author on app01_book_authors.author_id = app01_author.id WHERE app01_book.title = '西游记'
涉及到3表查询,查询结果为:
使用orm引擎查询
def query(request): ret = Book.objects.filter(title="西游记").values("authors__name","authors__age") print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
<QuerySet [{'authors__name': 'xiao', 'authors__age': 25}]>
(0.001) SELECT "app01_author"."name", "app01_author"."age" FROM "app01_book" LEFT OUTER JOIN "app01_book_authors" ON ("app01_book"."id" = "app01_book_authors"."book_id") LEFT OUTER JOIN "app01_author" ON ("app01_book_authors"."author_id" = "app01_author"."id") WHERE "app01_book"."title" = '西游记' LIMIT 21; args=('西游记',)
解释:
由于book表和author表是多对多关系,所以使用ORM查询时,它会自动对应关系
authors__name 表示author表的name字段
那么使用ORM处理多表,就显得很简单了!
反向查询
还是上面的需求,以author为基础表查询
def query(request): ret = Author.objects.filter(book__title="西游记").values("name","age") print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
<QuerySet [{'name': 'xiao', 'age': 25}]>
(0.002) SELECT "app01_author"."name", "app01_author"."age" FROM "app01_author" INNER JOIN "app01_book_authors" ON ("app01_author"."id" = "app01_book_authors"."author_id") INNER JOIN "app01_book" ON ("app01_book_authors"."book_id" = "app01_book"."id") WHERE "app01_book"."title" = '西游记' LIMIT 21; args=('西游记',)
执行结果同上!
一对一
正向查询:关联属性在authordetail表中,所以author对象找关联作者详情,正向查询
反向查询:关联属性在author表中,所以authordetail对象找关联作者信息,反向查询
正向: 按字段:.ad author ------------------------- > authordetail <------------------------- 反向: 按表名小写 authordetail_obj.author
正向查询
举例:查询xiao的女朋友名字
def query(request): ret = Author.objects.filter(name="xiao").values("ad__gf") print(ret) return HttpResponse('查询成功')
解释:ORM查询时,会自动对应关系。ad__gf表示authordetail表的gf字段
刷新页面,查看控制台输出:
<QuerySet [{'ad__gf': '赵丽颖'}]>
(0.001) SELECT "app01_authordetail"."gf" FROM "app01_author" INNER JOIN "app01_authordetail" ON ("app01_author"."ad_id" = "app01_authordetail"."id") WHERE "app01_author"."name" = 'xiao' LIMIT 21; args=('xiao',)
反向查询
还是上面的需求,以authordetail表为基础表查询
def query(request): ret = AuthorDetail.objects.filter(author__name="xiao").values("gf") print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
<QuerySet [{'gf': '赵丽颖'}]>
(0.002) SELECT "app01_authordetail"."gf" FROM "app01_authordetail" INNER JOIN "app01_author" ON ("app01_authordetail"."id" = "app01_author"."ad_id") WHERE "app01_author"."name" = 'xiao' LIMIT 21; args=('xiao',)
进阶练习(连续跨表)
举例1
查询榴莲出版社出版过的所有书籍的名字以及作者的姓名
正向查询
def query(request): ret = Book.objects.filter(publish__name="榴莲出版社").values_list("title","authors__name") print(ret) return HttpResponse('查询成功')
解释:
book表示连接出版社和作者的核心表。以它为基础表查询,比较好处理!
publish__name 表示publish表的name字段。
authors__name表示book_authors表(book和author的关系表)的name字段。
刷新页面,查看控制台输出:
<QuerySet [('西游记', 'xiao')]> (0.000) SELECT "app01_book"."title", "app01_author"."name" FROM "app01_book" INNER JOIN "app01_publish" ON ("app01_book"."publish_id" = "app01_publish"."id") LEFT OUTER JOIN "app01_book_authors" ON ("app01_book"."id" = "app01_book_authors"."book_id") LEFT OUTER JOIN "app01_author" ON ("app01_book_authors"."author_id" = "app01_author"."id") WHERE "app01_publish"."name" = '榴莲出版社' LIMIT 21; args=('榴莲出版社',)
反向查询
还是上面的需求,以publish表为基础表查询
def query(request): ret = Publish.objects.filter(name="榴莲出版社").values_list("book__title","book__authors__age","book__authors__name") print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
<QuerySet [('西游记', 25, 'xiao')]> (0.001) SELECT "app01_book"."title", "app01_author"."age", "app01_author"."name" FROM "app01_publish" LEFT OUTER JOIN "app01_book" ON ("app01_publish"."id" = "app01_book"."publish_id") LEFT OUTER JOIN "app01_book_authors" ON ("app01_book"."id" = "app01_book_authors"."book_id") LEFT OUTER JOIN "app01_author" ON ("app01_book_authors"."author_id" = "app01_author"."id") WHERE "app01_publish"."name" = '榴莲出版社' LIMIT 21; args=('榴莲出版社',)
举例2
手机号以11开头的作者出版过的所有书籍名称以及出版社名称
提示:涉及到5表查询!
先使用原生sql查询
SELECT app01_book.title,a01p.name from app01_book INNER JOIN app01_book_authors as a on app01_book.id = a.book_id INNER JOIN app01_author as a3 on a.author_id = a3.id INNER JOIN app01_authordetail as a2 on a3.ad_id = a2.id INNER JOIN app01_publish as a01p on app01_book.publish_id = a01p.id WHERE a2.tel like '11%'
执行结果:
使用orm引擎查询
正向查询:
def query(request): ret = Book.objects.filter(authors__ad__tel__startswith="11").values("title","publish__name") print(ret) return HttpResponse('查询成功')
解释:
authors__ad__tel 表示book_authors表,author表的ad字段,authordetail表的tel字段,做关联查询。
__startswith 表示以什么开头,它会使用like查询,比如'11%'
"title","publish__name" 分别表示book表的title字段,publish表的name字段
刷新页面,查看控制台输出:
<QuerySet [{'title': 'python', 'publish__name': '西瓜出版社'}, {'title': 'python', 'publish__name': '西瓜出版社'}, {'title': 'python', 'publish__name': '西瓜出版社'}, {'title': '西游记', 'publish__name': '榴莲出版社'}, {'title': '三国演义', 'publish__name': '西瓜出版社'}]>
(0.001) SELECT "app01_book"."title", "app01_publish"."name" FROM "app01_book" INNER JOIN "app01_book_authors" ON ("app01_book"."id" = "app01_book_authors"."book_id") INNER JOIN "app01_author" ON ("app01_book_authors"."author_id" = "app01_author"."id") INNER JOIN "app01_authordetail" ON ("app01_author"."ad_id" = "app01_authordetail"."id") INNER JOIN "app01_publish" ON ("app01_book"."publish_id" = "app01_publish"."id") WHERE "app01_authordetail"."tel" LIKE '11%' ESCAPE '\' LIMIT 21; args=('11%',)
反向查询:
def query(request): ret = Author.objects.filter(ad__tel__startswith="11").values("book__title","book__publish__name") print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
<QuerySet [{'book__publish__name': '西瓜出版社', 'book__title': 'python'}, {'book__publish__name': '榴莲出版社', 'book__title': '西游记'}, {'book__publish__name': '西瓜出版社', 'book__title': 'python'}, {'book__publish__name': '西瓜出版社', 'book__title': '三国演义'}, {'book__publish__name': '西瓜出版社', 'book__title': 'python'}]>
(0.001) SELECT "app01_book"."title", "app01_publish"."name" FROM "app01_author" INNER JOIN "app01_authordetail" ON ("app01_author"."ad_id" = "app01_authordetail"."id") LEFT OUTER JOIN "app01_book_authors" ON ("app01_author"."id" = "app01_book_authors"."author_id") LEFT OUTER JOIN "app01_book" ON ("app01_book_authors"."book_id" = "app01_book"."id") LEFT OUTER JOIN "app01_publish" ON ("app01_book"."publish_id" = "app01_publish"."id") WHERE "app01_authordetail"."tel" LIKE '11%' ESCAPE '\' LIMIT 21; args=('11%',)
二、聚合查询
聚合 是aggreate(*args,**kwargs),通过QuerySet 进行计算。做求值运算的时候使用
主要有Sum,Avg,Max,Min。使用前,需要导入模块
from django.db.models import Sum,Avg,Max,Min,Count
Sum (总和)
返回值是一个字典
举例:查询所有书籍的总价格
def query(request): ret = Book.objects.all().aggregate(Sum("price")) print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
{'price__sum': Decimal('522.00')}
(0.001) SELECT CAST(SUM("app01_book"."price") AS NUMERIC) AS "price__sum" FROM "app01_book"; args=()
[02/Jul/2018 21:45:26] "GET /query/ HTTP/1.1" 200 12
Avg (平均值)
返回值是一个字典
举例:查询所有书籍的平均价格
使用原生sql查询
select avg(price) from app01_book
执行输出:174
使用orm引擎查询
def query(request): ret = Book.objects.all().aggregate(Avg("price")) print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
(0.001) SELECT AVG("app01_book"."price") AS "price__avg" FROM "app01_book"; args=() [02/Jul/2018 21:38:42] "GET /query/ HTTP/1.1" 200 12 {'price__avg': 174.0}
aggregate()是QuerySet 的一个终止子句,意思是说,它返回一个包含一些键值对的字典。键的名称是聚合值的标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。如果你想要为聚合值指定一个名称,可以向聚合子句提供它。
对返回的key起别名
def query(request): ret = Book.objects.all().aggregate(avg = Avg("price")) print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
{'avg': 174.0}
(0.001) SELECT AVG("app01_book"."price") AS "avg" FROM "app01_book"; args=()
Max 和Min
返回值是一个字典
如果你希望生成不止一个聚合,你可以向aggregate()子句中添加另一个参数。
举例:所有图书价格的最大值和最小值
def query(request): ret = Book.objects.aggregate(Avg('price'), Max('price'), Min('price')) print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
{'price__avg': 174.0, 'price__min': Decimal('100.00'), 'price__max': Decimal('300.00')}
(0.001) SELECT AVG("app01_book"."price") AS "price__avg", CAST(MIN("app01_book"."price") AS NUMERIC) AS "price__min", CAST(MAX("app01_book"."price") AS NUMERIC) AS "price__max" FROM "app01_book"; args=()
Count (统计结果行数)
举例:查询西瓜出版社总共出版过多少本书籍
def query(request): ret = Book.objects.all().aggregate(count = Count("id")) print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
{'count': 3}
(0.001) SELECT COUNT("app01_book"."id") AS "count" FROM "app01_book"; args=()
三、分组查询
分组:将查询结果按照某个字段或多个字段进行分组。字段中值相等的为一组!
annotate()为调用的QuerySet中每一个对象都生成一个独立的统计值(统计方法用聚合函数)。
单表查询
修改models.py,增加一个模型表
class Emp(models.Model): name=models.CharField(max_length=32) age=models.IntegerField() salary=models.DecimalField(max_digits=8,decimal_places=2) dep=models.CharField(max_length=32) province=models.CharField(max_length=32)
使用2个命令生成表
python manage.py makemigrations
python manage.py migrate
使用sql插入3条数据,注意修改应用名
INSERT INTO `app01_emp` (`id`, `name`, `age`, `salary`, `dep`, `province`) VALUES (1, 'zhang', 26, 4000, '保洁部', '山东省'); INSERT INTO `app01_emp` (`id`, `name`, `age`, `salary`, `dep`, `province`) VALUES (2, 'li', 25, 3500, '保洁部', '北京'); INSERT INTO `app01_emp` (`id`, `name`, `age`, `salary`, `dep`, `province`) VALUES (3, 'wang', 27, 5000, '公关部', '北京');
举例1:查询每一个部门的平均薪水
使用原生sql查询
select dep,avg(salary) from app01_emp GROUP BY dep
使用orm引擎查询
导入emp表
from app01.models import Book,Publish,Author,AuthorDetail,Emp
修改视图函数
<QuerySet [{'dep': '保洁部', 'avg_salary': 3750.0}, {'dep': '公关部', 'avg_salary': 5000.0}]>
(0.000) SELECT "app01_emp"."dep", AVG("app01_emp"."salary") AS "avg_salary" FROM "app01_emp" GROUP BY "app01_emp"."dep" LIMIT 21; args=()
解释:
values("dep") 表示以dep字段进行分组
avg_salary 表示为字段起别名
Avg("salary") 表示取平均数
刷新页面,查看控制台输出:
<QuerySet [{'salary__avg': 3750.0, 'dep': '保洁部'}, {'salary__avg': 5000.0, 'dep': '公关部'}]>
(0.001) SELECT "app01_emp"."dep", AVG("app01_emp"."salary") AS "salary__avg" FROM "app01_emp" GROUP BY "app01_emp"."dep" LIMIT 21; args=()
举例2:查询每一个省/直辖市对应的人数
def query(request): ret = Emp.objects.values("province").annotate(Count("id")) print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
<QuerySet [{'id__count': 2, 'province': '北京'}, {'id__count': 1, 'province': '山东省'}]>
(0.002) SELECT "app01_emp"."province", COUNT("app01_emp"."id") AS "id__count" FROM "app01_emp" GROUP BY "app01_emp"."province" LIMIT 21; args=()
总结:
单表.objects.values('group by 字段').annotate(统计字段)
多表查询
举例1:查询每一个出版社的名称,以及对应书籍的平均价格
使用原生sql查询
select app01_publish.name,avg(app01_book.price) from app01_book INNER JOIN app01_publish ON app01_publish.id = app01_book.publish_id GROUP BY app01_publish.id
查询结果:
使用orm引擎查询
def query(request): ret = Publish.objects.values("id").annotate(avg=Avg("book__price")).values("name","avg") print(ret) return HttpResponse('查询成功')
解释:
values("id") 以id字段进行分组
avg=Avg("book__price") 表示将关联的book表的price字段,计算平均数。avg表示起别名
values("name","avg") 取出name和avg字段
刷新页面,查看控制台输出:
<QuerySet [{'name': '西瓜出版社', 'avg': 211.0}, {'name': '榴莲出版社', 'avg': 100.0}]>
(0.000) SELECT "app01_publish"."name", AVG("app01_book"."price") AS "avg" FROM "app01_publish" LEFT OUTER JOIN "app01_book" ON ("app01_publish"."id" = "app01_book"."publish_id") GROUP BY "app01_publish"."id", "app01_publish"."name" LIMIT 21; args=()
举例2:查询每一本书籍的名称以及作者个数
def query(request): ret = Book.objects.values("id").annotate(count=Count("authors__name")).values("title","count") print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
<QuerySet [{'title': 'python', 'count': 3}, {'title': '三国演义', 'count': 1}, {'title': '西游记', 'count': 1}]>
(0.001) SELECT "app01_book"."title", COUNT("app01_author"."name") AS "count" FROM "app01_book" LEFT OUTER JOIN "app01_book_authors" ON ("app01_book"."id" = "app01_book_authors"."book_id") LEFT OUTER JOIN "app01_author" ON ("app01_book_authors"."author_id" = "app01_author"."id") GROUP BY "app01_book"."id", "app01_book"."title" LIMIT 21; args=()
举例3:查询大于一个作者的书籍名称
def query(request): ret = Book.objects.values("id").annotate(count=Count("authors__name")).filter(count__gt=1).values("title","count") print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
<QuerySet [{'title': 'python', 'count': 3}]>
(0.001) SELECT "app01_book"."title", COUNT("app01_author"."name") AS "count" FROM "app01_book" LEFT OUTER JOIN "app01_book_authors" ON ("app01_book"."id" = "app01_book_authors"."book_id") LEFT OUTER JOIN "app01_author" ON ("app01_book_authors"."author_id" = "app01_author"."id") GROUP BY "app01_book"."id", "app01_book"."title" HAVING COUNT("app01_author"."name") > 1 LIMIT 21;
注意:它使用了HAVING
总结:
跨表分组查询本质就是将关联表join成一张表,再按单表的思路进行分组查询。
1 确定是否是多表分组 2 如果是多表分组,确定分组条件(group by哪一个字段) 3 语法: 每一个后跟的表A.objects.values("id").annotate("统计函数(与A表关联的B表下的某个字段)")
查询练习
举例1:统计每一个出版社的最便宜书籍的价格
def query(request): ret = Publish.objects.annotate(MinPrice=Min("book__price")).values_list("name","MinPrice") print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
<QuerySet [('西瓜出版社', Decimal('122.00')), ('榴莲出版社', Decimal('100.00'))]> (0.001) SELECT "app01_publish"."name", CAST(MIN("app01_book"."price") AS NUMERIC) AS "MinPrice" FROM "app01_publish" LEFT OUTER JOIN "app01_book" ON ("app01_publish"."id" = "app01_book"."publish_id") GROUP BY "app01_publish"."id", "app01_publish"."name", "app01_publish"."email", "app01_publish"."addr" LIMIT 21; args=()
举例2:统计每一本书的作者个数
def query(request): ret = Book.objects.annotate(authorsNum=Count('authors__name')).values() print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
<QuerySet [{'publish_id': 2, 'authorsNum': 1, 'pub_date': datetime.date(1743, 4, 12), 'id': 1, 'title': '西游记', 'price': Decimal('100.00')}, {'publish_id': 1, 'authorsNum': 1, 'pub_date': datetime.date(1643, 4, 12), 'id': 2, 'title': '三国演义', 'price': Decimal('300.00')}, {'publish_id': 1, 'authorsNum': 3, 'pub_date': datetime.date(2012, 12, 12), 'id': 3, 'title': 'python', 'price': Decimal('122.00')}]>
(0.001) SELECT "app01_book"."id", "app01_book"."title", "app01_book"."price", "app01_book"."pub_date", "app01_book"."publish_id", COUNT("app01_author"."name") AS "authorsNum" FROM "app01_book" LEFT OUTER JOIN "app01_book_authors" ON ("app01_book"."id" = "app01_book_authors"."book_id") LEFT OUTER JOIN "app01_author" ON ("app01_book_authors"."author_id" = "app01_author"."id") GROUP BY "app01_book"."id", "app01_book"."title", "app01_book"."price", "app01_book"."pub_date", "app01_book"."publish_id" LIMIT 21; args=()
举例3:统计每一本以py开头的书籍的作者个数
def query(request): ret = Book.objects.filter(title__startswith="Py").annotate(num_authors=Count('authors')) print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
<QuerySet [{'title': 'python', 'price': Decimal('122.00'), 'id': 3, 'pub_date': datetime.date(2012, 12, 12), 'publish_id': 1, 'num_authors': 3}]>
(0.001) SELECT "app01_book"."id", "app01_book"."title", "app01_book"."price", "app01_book"."pub_date", "app01_book"."publish_id", COUNT("app01_book_authors"."author_id") AS "num_authors" FROM "app01_book" LEFT OUTER JOIN "app01_book_authors" ON ("app01_book"."id" = "app01_book_authors"."book_id") WHERE "app01_book"."title" LIKE 'Py%' ESCAPE '\' GROUP BY "app01_book"."id", "app01_book"."title", "app01_book"."price", "app01_book"."pub_date", "app01_book"."publish_id" LIMIT 21; args=('Py%',)
举例4:根据一本图书作者数量的多少对查询集 QuerySet进行排序
def query(request): ret = Book.objects.annotate(num_authors=Count('authors')).order_by('num_authors').values() print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
<QuerySet [{'title': '西游记', 'publish_id': 2, 'pub_date': datetime.date(1743, 4, 12), 'price': Decimal('100.00'), 'id': 1, 'num_authors': 1}, {'title': '三国演义', 'publish_id': 1, 'pub_date': datetime.date(1643, 4, 12), 'price': Decimal('300.00'), 'id': 2, 'num_authors': 1}, {'title': 'python', 'publish_id': 1, 'pub_date': datetime.date(2012, 12, 12), 'price': Decimal('122.00'), 'id': 3, 'num_authors': 3}]>
(0.001) SELECT "app01_book"."id", "app01_book"."title", "app01_book"."price", "app01_book"."pub_date", "app01_book"."publish_id", COUNT("app01_book_authors"."author_id") AS "num_authors" FROM "app01_book" LEFT OUTER JOIN "app01_book_authors" ON ("app01_book"."id" = "app01_book_authors"."book_id") GROUP BY "app01_book"."id", "app01_book"."title", "app01_book"."price", "app01_book"."pub_date", "app01_book"."publish_id" ORDER BY "num_authors" ASC LIMIT 21; args=()
举例5:查询各个作者出的书的总价格
def query(request): ret = Author.objects.annotate(SumPrice=Sum("book__price")).values("name","SumPrice") print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
<QuerySet [{'SumPrice': Decimal('222.00'), 'name': 'xiao'}, {'SumPrice': Decimal('422.00'), 'name': 'zhang'}, {'SumPrice': Decimal('122.00'), 'name': 'wang'}, {'SumPrice': None, 'name': 'hong'}]>
(0.001) SELECT "app01_author"."name", CAST(SUM("app01_book"."price") AS NUMERIC) AS "SumPrice" FROM "app01_author" LEFT OUTER JOIN "app01_book_authors" ON ("app01_author"."id" = "app01_book_authors"."author_id") LEFT OUTER JOIN "app01_book" ON ("app01_book_authors"."book_id" = "app01_book"."id") GROUP BY "app01_author"."id", "app01_author"."name", "app01_author"."age", "app01_author"."ad_id" LIMIT 21; args=()
四、F查询
F() 专门取对象中某列值的操作
F()允许Django在未实际链接数据的情况下具有对数据库字段的值的引用。通常情况下我们在更新数据时需要先从数据库里将原数据取出后方在内存里,然后编辑某些属性,最后提交。
在上面所有的例子中,我们构造的过滤器都只是将字段值与某个常量做比较。如果我们要对两个字段的值做比较,那该怎么做呢?
Django 提供 F() 来做这样的比较。F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同字段的值。
修改models.py,增加3个字段
class Book(models.Model): title=models.CharField(max_length=32,unique=True) price=models.DecimalField(max_digits=8,decimal_places=2,null=True) pub_date=models.DateField() publish=models.ForeignKey(to="Publish",to_field="id",on_delete=models.CASCADE) authors=models.ManyToManyField(to="Author") comment_count=models.IntegerField(default=0) up_count=models.IntegerField(default=0) read_count = models.IntegerField(default=0)
使用2个命令生成表
python manage.py makemigrations
python manage.py migrate
使用sql语句更新数据,注意:修改应用名
UPDATE app01_book SET comment_count=123, read_count=1231, up_count=2 WHERE id=1; UPDATE app01_book SET comment_count=231, read_count=132, up_count=33 WHERE id=2; UPDATE app01_book SET comment_count=332, read_count=123, up_count=12 WHERE id=3;
举例1:查询评论数大于收藏数的书籍
常规写法是不能执行的
ret = Book.objects.filter(comment_count__gt=read_count)
正确写法
使用F查询,需要导入模块
from django.db.models import F
然后使用F查询
def query(request): ret = Book.objects.filter(comment_count__gt=F("read_count")).values("title") print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
(0.000) SELECT "django_migrations"."app", "django_migrations"."name" FROM "django_migrations"; args=() (0.000) SELECT "app01_book"."title" FROM "app01_book" WHERE "app01_book"."comment_count" > ("app01_book"."read_count") LIMIT 21; args=() <QuerySet [{'title': '三国演义'}, {'title': 'python'}]>
Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作。
举例2:查询评论数大于收藏数2倍的书籍
def query(request): ret = Book.objects.filter(comment_count__gt=F('up_count')*2).values("title") print(ret) return HttpResponse('查询成功')
解释:
comment_count 表示评论字段
__gt 表示大于
刷新页面,查看控制台输出:
(0.001) SELECT "app01_book"."title" FROM "app01_book" WHERE "app01_book"."comment_count" > (("app01_book"."up_count" * 2)) LIMIT 21; args=(2,) <QuerySet [{'title': '西游记'}, {'title': '三国演义'}, {'title': 'python'}]>
修改操作也可以使用F函数
举例:将每一本书的价格提高30元
def query(request): Book.objects.all().update(price=F("price")+30) # 更新 ret = Book.objects.all().values("title","price") #查询 print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
(0.006) UPDATE "app01_book" SET "price" = CAST(("app01_book"."price" + 30) AS NUMERIC); args=(30,) (0.001) SELECT "app01_book"."title", "app01_book"."price" FROM "app01_book" LIMIT 21; args=() <QuerySet [{'title': '西游记', 'price': Decimal('160.00')}, {'title': '三国演义', 'price': Decimal('360.00')}, {'title': 'python', 'price': Decimal('182.00')}]>
五、Q查询
Q() 对对象的复杂查询
Q对象(django.db.models.Q)可以对关键字参数进行封装,从而更好地应用多个查询。可以组合使用 &(and),(or),~(not)操作符,当一个操作符是用于两个Q的对象,它产生一个新的Q对象。
filter() 等方法中的关键字参数查询都是一起进行“AND” 的。 如果你需要执行更复杂的查询(例如OR 语句),你可以使用Q 对象。
使用Q查询,需要导入模块
from django.db.models import Q
举例:分别查询作者xiao、zhang出版过的书籍名称
Q 对象可以使用& 和| 操作符组合起来。当一个操作符在两个Q 对象上使用时,它产生一个新的Q 对象。
def query(request): ret = Book.objects.filter(Q(authors__name="xiao")|Q(authors__name="zhang")).values("title") print(ret) return HttpResponse('查询成功')
等同于下面的SQL WHERE 子句:
WHERE name ="xiao" OR name ="zhang"
刷新页面,查看控制台输出:
<QuerySet [{'title': 'python'}, {'title': 'python'}, {'title': '西游记'}, {'title': '三国演义'}]>
(0.001) SELECT "app01_book"."title" FROM "app01_book" INNER JOIN "app01_book_authors" ON ("app01_book"."id" = "app01_book_authors"."book_id") INNER JOIN "app01_author" ON ("app01_book_authors"."author_id" = "app01_author"."id") WHERE ("app01_author"."name" = 'xiao' OR "app01_author"."name" = 'zhang') LIMIT 21; args=('xiao', 'zhang')
你可以组合& 和| 操作符以及使用括号进行分组来编写任意复杂的Q 对象。同时,Q 对象可以使用~ 操作符取反,这允许组合正常的查询和取反(NOT) 查询:
举例:查询作者xiao不在2017出版过的所有书籍
def query(request): ret = Book.objects.filter(Q(authors__name="xiao") & ~Q(pub_date__year=2017)).values("title") print(ret) return HttpResponse('查询成功')
等同于下面的where语句
WHERE ("app01_author"."name" = 'xiao' AND NOT ("app01_book"."pub_date" BETWEEN '2017-01-01' AND '2017-12-31'))
刷新页面,查看控制台输出:
<QuerySet [{'title': 'python'}, {'title': '西游记'}]>
(0.001) SELECT "app01_book"."title" FROM "app01_book" INNER JOIN "app01_book_authors" ON ("app01_book"."id" = "app01_book_authors"."book_id") INNER JOIN "app01_author" ON ("app01_book_authors"."author_id" = "app01_author"."id") WHERE ("app01_author"."name" = 'xiao' AND NOT ("app01_book"."pub_date" BETWEEN '2017-01-01' AND '2017-12-31')) LIMIT 21; args=('xiao', '2017-01-01', '2017-12-31')
查询函数可以混合使用Q 对象和关键字参数。所有提供给查询函数的参数(关键字参数或Q 对象)都将"AND”在一起。但是,如果出现Q 对象,它必须位于所有关键字参数的前面。
举例:查询书籍名称中包含 "python",且python不区分大小写。在2012年或者2017年是否出版过
def query(request): ret = Book.objects.filter(Q(pub_date__year=2012) | Q(pub_date__year=2017),title__icontains="python").values("title") print(ret) return HttpResponse('查询成功')
刷新页面,查看控制台输出:
<QuerySet [{'title': 'python'}]>
(0.000) SELECT "app01_book"."title" FROM "app01_book" WHERE (("app01_book"."pub_date" BETWEEN '2012-01-01' AND '2012-12-31' OR "app01_book"."pub_date" BETWEEN '2017-01-01' AND '2017-12-31') AND "app01_book"."title" LIKE '%python%' ESCAPE '\') LIMIT 21; args=('2012-01-01', '2012-12-31', '2017-01-01', '2017-12-31', '%python%')