Xavier初始化:
论文:Understanding the difficulty of training deep feedforward neural networks
论文地址:http://proceedings.mlr.press/v9/glorot10a/glorot10a.pdf
“Xavier”初始化方法是一种很有效的神经网络初始化方法。“Xavier”初始化方法初始化方法的目标就是使得每一层输出的方差应该尽量相等。xavier权重初始化使得信号在经过多层神经元后保持在合理的范围(不至于太小或太大)。Xavier初始化可以帮助减少梯度弥散问题, 使得信号在神经网络中可以传递得更深。
Xavier初始化算法的推导:
Xavier 的推导过程主要基于以下三个假设:
1、忽略偏置项对网络的影响;
2、所有的非线性函数均为双曲正切函数Tanh ,且非线性函数的前向后向计算都近似为线性计算,因此它的影响也可以忽略;
3、输入数据和参数相互独立。
我们假设神经网络的隐藏层计算公式为:
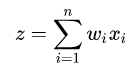
其中n是上一层神经元的数量。那么,根据概率统计里的两个随机变量乘积的方差展开式为:
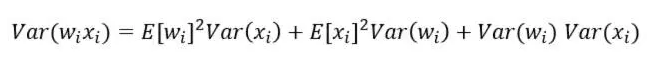
如果E(xi)=E(wi)=0(可以通过批量标准化Batch Normalization来满足这个条件),则上式变为:

如果随机变量xi、wi还满足独立同分布,则上式变为:

即输出的方差var(z)与输入的方差var(x)有关,为使输出的方差var(z)与输入的方差var(x)相同,则只要nVar(Wi)=1。
即:
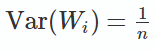
对于前向传播时,wi的方差为:
![]()
反向传播时wi的方差为:
![]()
我们需要保证正向传播和反向传播时的方差相等。而实际情况中,![]() 和
和![]() 往往不相等,因此,我们就取一种折衷方案,即令方差为:
往往不相等,因此,我们就取一种折衷方案,即令方差为:
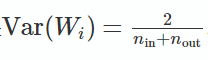
又在概率统计学中,[a,b] 间的均匀分布的方差为:
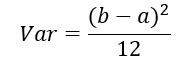
我们这里假设参数初始化的范围是[-a,a]。将b=-a带入上面的的公式,得:
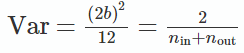
上面两式是相等的,故可以解出:
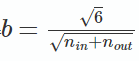
故Xavier初始化就是下面的均匀分布:

因此,假如我们定义参数所在层的输入维度为n,输出维度为m,那么这层的权重w的初始化就是从![]() 范围内的均匀分布内取随机值。
范围内的均匀分布内取随机值。
Xavier初始化方法适用的激活函数需要满足一定限制:关于0对称;线性(或可以近似看成线性)。而ReLU和PReLU激活函数不满足前面的条件一。
He Initialization(MSRA初始化):
论文:Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification
论文地址:https://arxiv.org/pdf/1502.01852.pdf
上面的Xavier初始化的非线性函数选择的是tanh,那么如果非线性函数选择RELU时,我们仍然想使得每一层输出的方差尽量相等,该怎么做呢?
He Initialization推导过程:
这里又有一个假设:
假定在ReLU网络中,每一层有一半的神经元被激活,另一半为0。也就是说,我们假定前面的线性计算部分输出的值有一半大于0,另一半小于0。
假设卷积层的线性计算部分公式为:
![]()
我们假设wl和xl仍然都是独立同分布的,则:
![]()
我们令wl的均值为0,则有:

又![]() ,故xl的均值显然不为0。
,故xl的均值显然不为0。
如果我们让wl-1对称分布在0附近,bl-1=0,那么yl-1也关于0对称分布,yl-1的均值也为0,令其上界为k,则有:
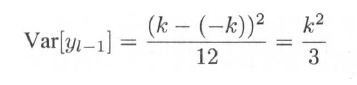
按照我们最开始的假设,经过ReLU 层后,xl的数据有一半变成了0,另一半变成了从0到k的均匀分布,那么有:

故
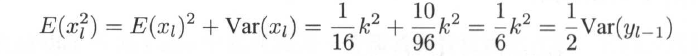
即当非线性函数是RELU时,有![]()
注意上面的推导式基于假设xl的数据经过Relu层后,有一半变成了0,另一半变成了从0到k的均匀分布。
代回上式,得:
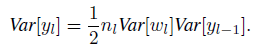
如果将前面的层都带入,则:
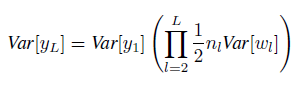
故可得:

于是我们在初始化w时,就可以在一个一个均值为0,方差为![]() 的高斯分布中取随机值。
的高斯分布中取随机值。
可以类比上面的Xavier初始化的推导过程,我们发现就是右边多乘了一个1/2。
注意我们的第一层的w应该满足![]() ,因为输入数据没有经过relu函数就进入了第一层。
,因为输入数据没有经过relu函数就进入了第一层。
类似地,对于反向传播,我们也能得出类似的结论:
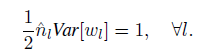
注意:
有的文章将He Initialization这种初始化方法称为MSRA初始化,且引用的论文也是同一篇,推导过程完全一样,可以认为He Initialization与MSRA初始化就是同一种方法。
Tensorflow中如何选择合适的初始化方法?
如果使用sigmoid和tanh等关于0对称且为线性(或近似线性)的激活函数,最好使用xavier初始化;
如果使用relu和Prelu激活函数,则最好使用He Initialization。