
论文源址:http://www.cs.berkeley.edu/~rbg/#girshick2014rcnn
摘要
在PASCAL VOC数据集上,最好的方法的思路是将低级信息与较高层次的上下文信息进行结合。该文的两个亮点:(1)将CNN应用到region proposals 用于对目标物体的定位。(2)对于较少数量的标签数据,先在规模较大的数据集上进行有监督的预训练,然后针对特定场景进行微调,发现性能提升的较大。R-CNN:region with CNN features
介绍
特征问题:视觉识别任务主要基于SIFT 和HOG等特征。该文首次将CNN引入了目标检测任务中。该文主要针对两个问题:用深度网络对目标进行定位,在少量有标签的数据集上训练一个较大规模的模型。
不同于图像分类任务,检测要求在一张图片中对多个目标物进行定位。一种方法是将目标检测问题看作为是回归问题,但是效果并不理想。另一种方法是建立一个滑窗检测器。为了保留较多的空间信息,CNN只包含两层卷积和池化层。而该文网络中包含5层卷积层有较大的感受野,造成了滑动窗口式的精确定位发展为一项挑战。
该文通过对区域进行识别来解决CNN的定位问题。该网络对输入图片产生了2000个类别独立的候选框,使用CNN从每一个候选框中提取出固定长度的特征向量。然后使用不同类别分类的SVM对提取的特征进行分类。没有考虑候选框的形状只是简单的计算CNN的固定输入大小。

目标检测中存在的另一个挑战为有标记的数据量较少不足以训练较大的CNN。传统的解决方法是首先使用无监督进行预训练,然后进行有监督的微调。本文的另一个贡献是展示在大规模数据集上进行预训练,后在特定数据集上进行微调,其结果有较大的提升。较好的解决了在稀少数据集上训练大规模的卷积网络。R-CNN中唯一一个确定类别的组件为轻量级的矩阵乘和基于贪恋的非最大抑制处理。
基于R-CNN的目标检测
本文目标检测包含三个模型:(1)生成类别独立的感兴趣区域,定义可用于目标检测的候选框(2) 卷积网络用于从每个候选框中提取出固定尺寸的特征向量。(3)一系列类别确定的线性SVM分类器。
region proposals: 一些用于区域框生成的方法如下。该文使用Selective Search作为候选框的生成方法。

特征提取: 从每个region proposal中提取4096维的特征向量。输入图片经过5个卷积层和两个全连接层提取特征,输入图片大小为227x227并经过了一个减均值处理。对于每个候选区域,首先调整其尺寸,使其变为大小为227x227满足CNN的输入要求。

目标检测的测试:首先基于SS方式从一张图片上提取2000张region proposals,然后将proposals wrap至227x227大小,送入CNN网络进行特征提取。对于分类,使用训练好的对应类别的分类器对提取的特征进行预测。得到图片中所有的scored 区域后,利用非最大抑制处理来删除冗余区域,标准是挑出IOU比阈值大的scored 区域。
运行时间分析:两个属性使检测过程高效:I:CNN的所有参数是共享的,减少了计算资源。II:经过CNN提取后的特征是低维的。类别确定的计算包含:矩阵乘和NMS,特征矩阵大小为2000x4096,SVM的权重为4096xN。N代表的为类别数。
训练过程:首先在ILSVRC2012数据集上进行预训练,然后,只在与ground truth IOU值大于0.5作为正训练样本,其余的作为负训练样本的wrapped proposals上进行微调训练。使用SGD优化方法,在没次迭代中,选择32个正训练样本,96个背景组成一个mini-batch,同时,由于负样本过少,偏向采样正样本。
目标类别的分类:要实现检测车的二分类问题,图片中围绕在车周围的区域很明显是一个正样本。不包含任何车的区域为负样本。难点在于如何检测到与车重叠的区域。该文通过IOU解决,IOU低于某个值代表负样本。特征从CNN中提取后,针对每个类别训练一个线性的SVM分类器。对于内存来说,训练数据过于庞大,因此,采用Hard negative minging 方法进行处理。
实验


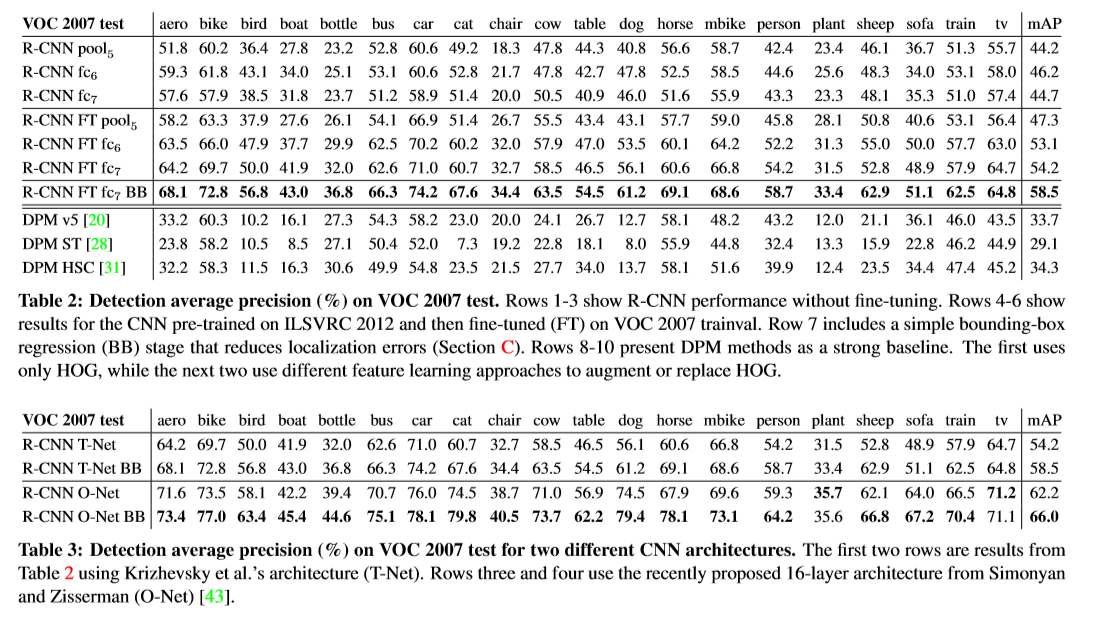
正负样本的选取
将每个proposal与ground truth进行比较,IoU大于0.5的标记为正样本,对于某个类别中,与GroundTruth IoU的值小于0.3的标记为负样本。而0.3到0.5之间的则被丢弃。
生成框的回归模型
为了提高检测的准确性,训练一个线性回归模型。在通过SVM实现对每个候选区域的类别标记后,基于框回归器进行预测得到一个新的回归框。
训练算法的输入为:N个训练样本,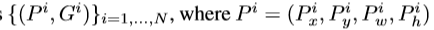 ,对于ground truth 的定义形式相似。
,对于ground truth 的定义形式相似。
 ,通过定义线性函数,将P,与标记G建立联系。
,通过定义线性函数,将P,与标记G建立联系。
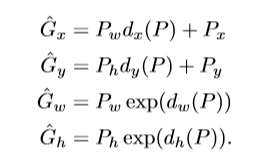


在进行回归计算时,选取候选框与ground truth 的IoU大于0.6的作为回归训练样本。
reference
[1] B.Alexe,T.Deselaers,andV.Ferrari. Measuringtheobjectness of image windows. TPAMI, 2012. 2
[2] P. Arbel´aez, B. Hariharan, C. Gu, S. Gupta, L. Bourdev, and J. Malik. Semantic segmentation using regions and parts. In CVPR, 2012. 10, 11
[3] P. Arbel´aez, J. Pont-Tuset, J. Barron, F. Marques, and J. Malik. Multiscale combinatorial grouping. In CVPR, 2014. 3
[4] J. Carreira, R. Caseiro, J. Batista, and C. Sminchisescu. Semantic segmentation with second-order pooling. In ECCV, 2012. 4, 10, 11, 13, 14
[5] J. Carreira and C. Sminchisescu. CPMC: Automatic object segmentation using constrained parametric min-cuts. TPAMI, 2012. 2, 3
[6] D. Cires¸an, A. Giusti, L. Gambardella, and J. Schmidhuber. Mitosisdetectioninbreastcancerhistologyimageswith deep neural networks. In MICCAI, 2013. 3