版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/weixin_37029453/article/details/78917066
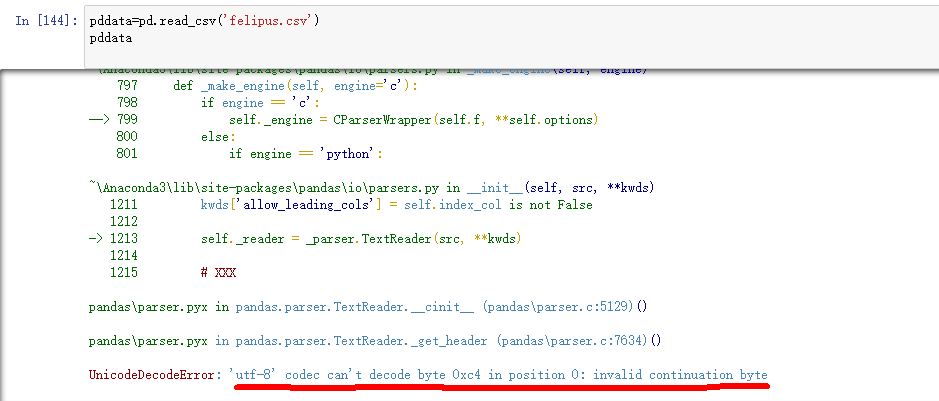
在用pandas读入csv文档是,因为文档中有中文所以会出现读取不了的错误。错误的原因是'utf-8'编解码器无法解码0位的字节0xc4
解决方案:
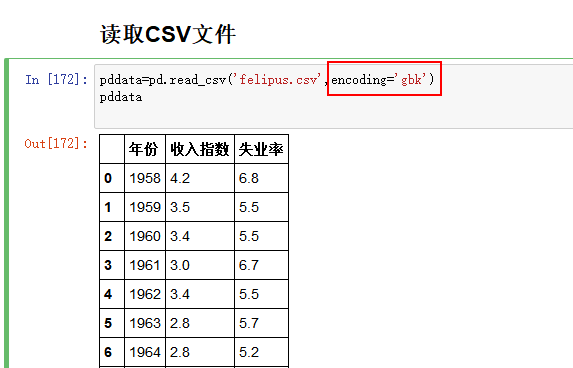
在读入文件后面加encoding=’gbk’,
如:pddata=pd.read_csv('felipus.csv',encoding='gbk')
有兴趣的继续看原因!
众所周知,我们用python默认的是utf-8编码。关于编码方式的介绍,我推荐看一下廖大的python教程——“字符串和编码”。既然utf-8格式不能正确的读取带中文的csv文件,那么我们就选取一个可以读取中文字符的格式不就好了吗。
那么什么格式可以读取中文字符呢?我们打开Python3官方网站: 找到关于标准字符的部分。如下图:

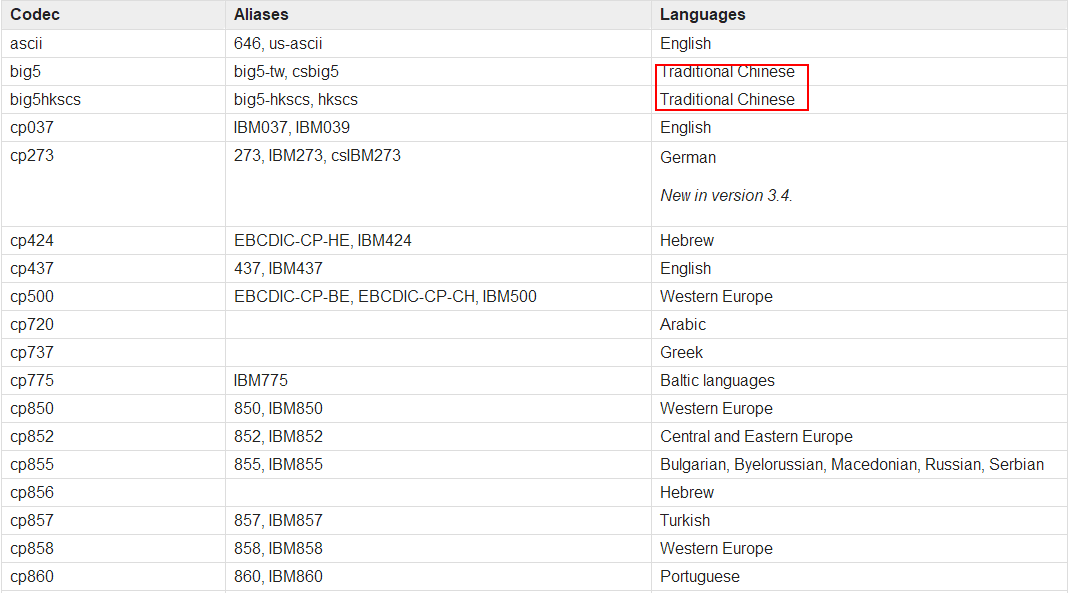
那么到底要改成什么格式呢?可以看到表格第三列Language表示的是此种编码支持什么语言。那么我们找找看。
 !
!
表格就不在这里展示给大家看了,有兴趣的自己去网站上看吧。反正在我仔细的寻找下一共有big5;big5hkscs;gb2312;gbk;gb18030;hz;iso2022_jp_2这5种格式可能支持中文。经过我的测试,发现gb2312;gbk;gb18030这3种格式可以顺利的读取带中文的csv文件。(既然3种都可以,那么我们就记个好记的’gbk’吧)