一、预备知识
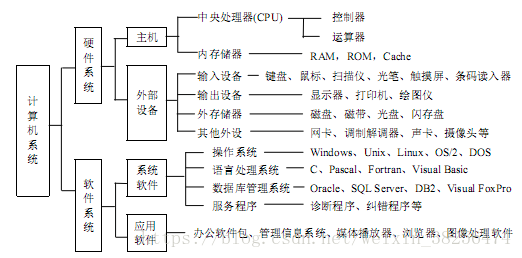
1、一台计算机(甭管台式机、PC机,也甭管系统(Windows、iOS、Linux、Unix等))的基本构成:硬件系统+软件系统
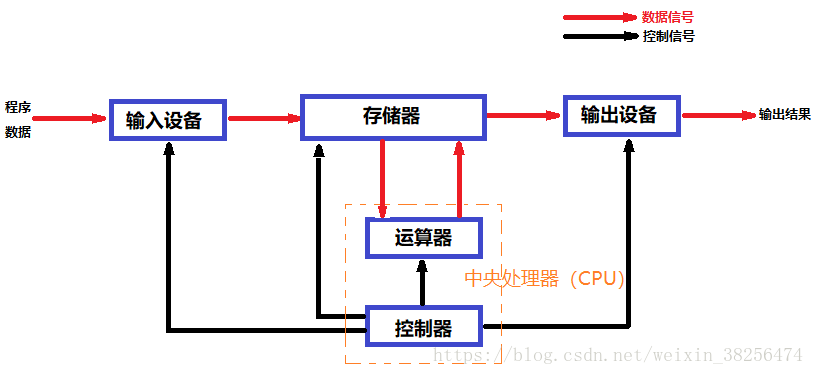
硬件系统主要有五大组成部分,是物质基础、物理实体,没有安装任何软件的计算机称为“裸机”,是无法工作的。如图:著名的冯诺依曼体系结构
软件系统:是介于用户和硬件系统之间的界面。由操作系统(OS)、应用软件组成。
操作系统(OS)的设计,归纳为3点:
- 以多进程形式,允许多个任务同时运行;
- 以多线程形式,允许单个任务分成不同的部分运行;
- 提供协调机制,一方面阻止进程之间和线程之间产生冲突,另一方面允许进程之间和线程之间共享资源。
2、进程、线程、协程之概念
①、进程和线程:
生活中形象比喻:
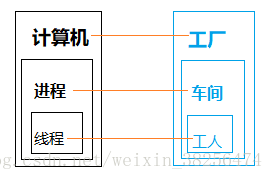
计算机的核心是CPU,它承担所有的计算任务。计算机比作一座工厂,时刻在运行。
进程比作工厂的车间,它代表CPU所能处理的单个任务;任一时刻,CPU总是运行一个进程,其他进程处于非运行状态。
一个车间里,有多名工人,协同完成一个任务。线程比作车间工人,一个进程可包括多个线程。
计算机中举例:
打开一个QQ,就开了一个进程;打开Chrome浏览器,开了一个进程;运行一个Python程序,也开了一个进程。
在QQ进程中,传输文字开了一个线程、传输语音开了一个线程、弹出对话框也开了一个线程。
执行一段程序代码,实现一个功能。当得到CPU时,相关资源(如显卡等等)也必须到位,然后CPU才开始执行。在此除了CPU以外所有的就构成了该程序的执行环境,即所定义的程序上下文。进程拥有代码和打开的文件资源、数据资源、独立的内存空间。
进程、线程 是两个名词,实际对应的是CPU工作时间段的描述,只是颗粒大小不同。
进程(即上下文切换的程序执行时间总和)=CPU加载上下文+CPU执行+CPU保存上下文。
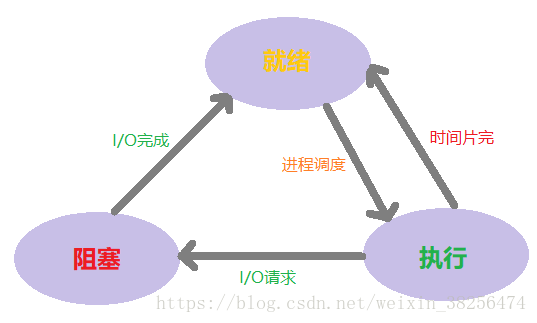
论进程的 3种基本状态:
- 就绪状态(Ready)
当进程已分配到 除CPU以外的所有必要资源 后,只要再获得CPU,便可立即执行,进程此时的状态就称为 就绪状态。在一个系统中处于就绪状态的进程可能有多个,通常将它们排成一个队列,称为 就绪队列。 - 执行状态
进程已获得CPU,其程序正在执行。在单处理机系统中,只有一个进程处于 执行状态;在多处理机系统中,则有多个进程处于 执行状态。 - 阻塞状态
正在执行的进程由于发生某事件而暂时无法继续执行时,便放弃处理机而处于 暂停状态,即 程序的执行收到阻塞,把这种暂停状态称为 阻塞状态 (也称为 等待状态或封锁状态)。
进程间的几种通信方式:
- 管道(pipe):管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系 通常是指父子进程关系。
- 有名管道(named pipe):有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
- 信号量(semophore):信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
- 消息队列(message queue):消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流 以及缓冲区大小受限等缺点。
- 信号(sinal):信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
- 共享内存(shared memory):共享内存 就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的IPC方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制(如信号量)配合使用,来实现进程间的同步和通信。
- 套接字(socket):套接口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同及其间的进程通信。
进程的颗粒度太大,每次都要上下文的调入、保存、调出。进程若比作运行在计算机上的一个软件,该软件的执行不可能是一条逻辑执行的,必定有多个分支、多个程序段,好比实现程序A,实际分成a、b、c等多个块组合而成。具体的执行是:
在此,a、b、c的执行共享了A上下文,CPU在执行时没有进行上下文切换,a、b、c即是线程,它是共享了进程的上下文环境的更为细小的CPU时间段。

线程 从属于进程,是程序的实际执行者,一个进程至少包含一个主线程,也可有更多子线程。
对操作系统(OS)而言,线程是最小的执行单元,进程是最小的资源管理单元。
在一定意义上,进程是一个应用程序在处理机(也可以是安卓设备、苹果手机)上的一次执行过程,是一个动态的概念,而线程是进程中的一部分,进程包含多个线程在运行,它们可利用进程所拥有的资源。在引入线程的操作系统(OS)中,通常将进程作为分配资源的基本单位,而将线程作为独立运行和独立调度的基本单位。由于线程比进程更小,基本上不拥有系统资源,因此,对它的调度所付出的开销小得多,能高效地提高系统内多个程序间并发执行的效率。
岂止于进程,回答:有进程了,为什么还要线程?
进程有很多优点,提供了多道编程,让使用者感觉每个人都拥有自己的CPU、其他资源,可以提高计算机的利用率。双刃剑,它也有缺陷:
- 进程只能在一个时刻做一件事,如果想同时干两件事、或多件事,进程就无能为力了;
- 进程在执行过程中如果阻塞,例如等待输入,整个进程就会挂起,即使进程中有些工作不依赖于输入的数据,也将无法执行。
举例:在使用QQ聊天程序时,QQ作为一个独立进程,如果同一时间只能干一件事(一个功能),那如何实现在同一时刻 监听键盘输入、监听他人发送的消息、他人发送的消息显示在屏幕上?OS虽有分时功能,但分时是指在不同进程间的分时,即OS一会处理QQ任务、一会切换到Word文档任务上,每个CPU时间片分配给QQ程序时,QQ还是只能同时做一件事。如果QQ同时实现上述功能,轮到线程了。
线程,即轻量级进程(Lightweight Process,LWP),是程序执行流的最小单元。一个标准的线程 组成:线程ID、当前指令指针(PC)、寄存器集合、堆栈。
线程是进程中的一个实体,是被系统独立调度和分派的基本单位,线程自己不拥有系统资源,只拥有一点在运行中必不可少的资源,但它可与同属一个进程的其他线程共享进程所拥有的全部资源。
一个线程可以创建、撤销另外一个线程,同一进程中的多个线程之间可以并发执行。由于线程之间的相互制约,致使线程在运行中呈现出间断性。线程也有就绪、阻塞、运行3种基本状态。
- 就绪状态:指线程具备运行的所有条件,逻辑上可以运行,在等候处理机;
- 运行状态:指线程占有处理机、正在运行;
- 阻塞状态:指线程在等待一个事件(如某个信号量),逻辑上不可执行。
每个程序都至少有一个线程,若程序只有一个线程,那必是程序本身。线程是程序中一个单一的顺序控制流程,是进程内一个相对独立的、可调度的执行单元,是系统独立调度和分派CPU的基本单位。在单个程序中同时运行多个线程完成不同的工作,称之为:多线程。
经上述描述,可看出进程、线程之间的区别:
主要在于两者 是不同的操作系统资源管理的方式。进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其他进程造成影响;而线程只是一个进程中的不同执行路径。线程拥有自己的堆栈和局部变量,但线程之间没有单独的地址空间,一个线程死掉=整个进程死掉,所以多进程的程序要比多线程的程序健壮,但在进程切换时,耗费资源较大,效率低些。但对于一些要求同时进行并且又要共享某些变量的并发操作,只能用线程,不能用进程。
- 一个程序 至少有一个进程,一个进程至少有一个线程;
- 线程的划分尺度小于进程,使得多线程程序的并发性高;
- 进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运算效率;
- 线程在执行过程中与进程是有区别的。每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能独立运行,必须依存在应用程序中,由应用程序提供多个线程执行控制;
- 从逻辑角度看,多线程的意义在于一个应用程序中,有多个执行部分可以同时执行。但OS并没有将多个线程看作多个独立的应用,来实现进程的调度和管理以及资源分配。这是进程、线程的重要区别。
- 线程和进程在使用上各有优缺点:线程执行开销小,但不利于资源的管理和保护;而进程正相反。同时,线程适合于在SMP(多核处理机)机器运行,而进程则可以跨机器迁移。
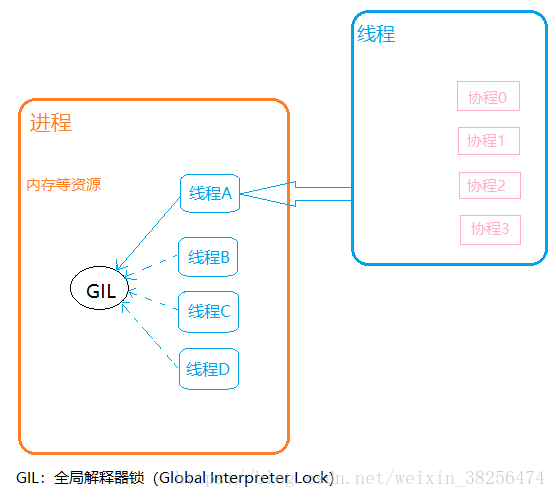
②、协程:
协程(Coroutine),又称微线程,是单个线程执行的,是一种比线程更加轻量级的存在。如同一个进程可拥有多个线程一样,一个线程可拥有多个协程。
不过,协程不是由OS 内核管理,而是完全由程序控制(即用户执行)。由此提升性能,不用线程切换消耗资源。
在Python语言中,当协程执行到yield关键字时,会暂停在该行,直到主线程调用send()发送了数据,协程接收到数据,继续执行。【Python 3.5+版本,async/await替代了yield/send成为更好的替代方案】
PS:yield使协程暂停,和线程阻塞有本质区别,即 协程暂停完全由程序控制,线程阻塞由OS内核来进行切换。协程开销远小于线程开销。
子程序(又称为 函数),在所有语言中都是层级调用,如【A调用B,B在执行过程中调用了C,C执行完毕返回,B执行完毕返回,最后A执行完毕】。因此,函数调用是通过栈实现的,一个线程 就是执行一个函数。函数调用总是一个入口、一次返回,其调用顺序是明确的。而协程的调用和函数不同,协程在执行过程中,可中断,转而执行其他函数,在适当时再返回继续执行。
③、简要解释 堆栈、队列:Python语言中
首先明白一个概念:数据结构。数据结构 是计算机存储、组织数据的方式。也即 指相互之间存在一种或多种特定关系的数据元素的集合。当然,精心选择的数据结构可带来更高的运行、存储效率。
堆栈、队列: 均是 数据结构的其中2种:
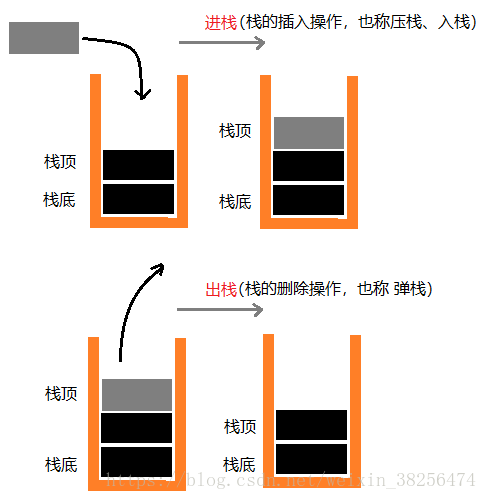
栈(stack):(又名堆栈),是限定在表尾进行插入和删除的操作的线性表。
将允许插入和删除的一端称为栈顶(top),另一端称为栈底(bottom),不包含任何数据元素的栈称为空栈。栈又称为后进先出(Last In First Out)的线性表,简称LIFO结构。
队列(queue):一种特殊的线性表,它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作。进行插入操作的端称为队尾,进行删除操作的端称为队头。队列是按照“先进先出”或“后进后出”的原则组织数据的。队列中没有元素时,称为空队列。
参考:
1、Python之进程与线程:极好的一篇文章,赞。
2、进程与线程的一个简单解释
二、实际应用:Python语言中
1、Python----进程:multiprocessing
在Linux/Unix OS中,系统提供了fork()函数,但它跟普通函数不同,fork调用一次,返回两次。因为OS将当前进程(父进程)copy了一份(子进程),所以在父、子进程内分别返回,即 返回两次:子进程返回0,父进程返回进程ID。
在Windows中,没有fork调用,不过,Python提供了multiprocessing包,以便支持其跨平台性。
from multiprocessing import Pool
def f(x):
return x*x
if __name__ == '__main__':
with Pool(5) as p:
print(p.map(f, [1, 2, 3]))
运行结果:
[1, 4, 9]
***Repl Closed***
参考:
1、多进程----Python 3.6官方文档之multiprocessing包
2、子进程----Python 3.6官方文档之subprocess模块
3、subprocess模块(子进程)部分参考博客
2、Python----线程:threading模块
threading模块(module)用于提供 线程 相关操作。线程是应用程序中工作的最小单元。
import threading
import time
def sayhi(num):#定义每个线程要运行的函数
print("running on number:%s" %num)
time.sleep(3)
if __name__=='__main__':
t1 = threading.Thread(target=sayhi, args=(1,))#生成一个线程实例
t2 = threading.Thread(target=sayhi, args=(2,))#再生成一个线程实例
t1.start()#启动线程
t2.start()#启动另一个线程
print(t1.getName())#取得线程名
print(t2.getName())
运行:
running on number:1
running on number:2
Thread-1
Thread-2
***Repl Closed***
上述代码创建了2个“前台”线程,然后控制器交给了CPU,CPU根据指定算法进行调度,分片执行指令。
如下是继承式调用:
import threading
import time
class MyThread(threading.Thread):
def __init__(self,num):
threading.Thread.__init__(self)
self.num = num
def run(self):#定义每个线程要运行的函数
print("running on number:%s" %self.num)
time.sleep(3)
if __name__ == '__main__':
t1 = MyThread(1)
t2 = MyThread(2)
t1.start()
t2.start()
运行:
running on number:1
running on number:2
***Repl Closed***
参考:
Python 3.6官方文档----threading模块
3、Python----协程
Python对协程的支持是通过generator来实现的。子程序(函数) 是协程的一种特例。
在generator中,不仅可通过for循环进行迭代,而且还可不断调用next()函数获取 由yield语句返回的下一个值。
而且,Python的yield不但可以返回一个值,还可以接收调用者发出的参数。
实例:传统的生产者-消费者模型是一个线程写消息,一个线程取消息,通过锁机制控制队列和等待,但一不小心就可能死锁。
如果改用协程,生产者生产消息后,直接通过yield跳转到消费者开始执行,待消费者执行完毕后,切换回生产者继续生产,效率极高:
def consumer():
r = ''
while True:
n = yield r
if not n:
return
print('[CONSUMER] Consuming %s...' % n)
r = '200 OK'
def produce(c):
c.send(None)
n = 0
while n < 5:
n = n + 1
print('[PRODUCER] Producing %s...' % n)
r = c.send(n)
print('[PRODUCER] Consumer return: %s' % r)
c.close()
c = consumer()
produce(c)
运行结果:
[PRODUCER] Producing 1...
[CONSUMER] Consuming 1...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 2...
[CONSUMER] Consuming 2...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 3...
[CONSUMER] Consuming 3...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 4...
[CONSUMER] Consuming 4...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 5...
[CONSUMER] Consuming 5...
[PRODUCER] Consumer return: 200 OK
***Repl Closed***
上述代码中,consumer()函数 是一个generator,把一个consumer传入produce后:
- 调用
c.cend(None)启动生成器; - 一旦生产了东西,通过
c.send(n)切换到consumer执行; consumer通过yield拿到消息,处理,又通过yield把结果传回;produce拿到consumer处理的结果,继续生产下一条消息;produce决定不生产了,通过c.close()关闭consumer,整个过程结束。
整个流程无锁,由一个线程执行,produce和consumer协作完成任务,所以称为“协程”,而非线程的抢占式多任务。
4、Python----队列:queue模块
在Python中,可用列表作为队列的底层实现,只需要确定列表的哪一端作为队列的头,也即删除操作端;哪一端作为队列的尾,也即插入操作端。同时,把队列抽象为类,队列的先进先出操作实现为类的方法。
实例:
约瑟夫问题:n个人围成一个圈,每个人分别标注为1、2、…、n,要求从1号从1开始报数,报到k的人出圈,接着下一个人又从1开始报数,如此循环,直到只剩最后一个人时,该人即为胜利者。
解约瑟夫问题的一种方法是模拟这个过程,模拟的载体可以是队列,也可以是链表,下面就用列队来模拟这个过程
循环报数的过程可以看作是一个先报数先出的过程,用队列来模拟时,将当前报数的人弹出,如果报的不是k时,再插入到队尾,从而得以循环,如果报的是k,则抛弃。直至剩下最后一个人。
下面是在生成 Queue 类的基础下,Python 解决约瑟夫问题的一个实例代码,以实际人名来仿真n个人,报数为7时删除,输出最后的胜利者。
#队列的简单实现
class Queue:
def __init__(self):
self.items=[]
def is_empty(self):
return self.items==[]
def enqueue(self,item):
self.items.insert(0,item)
def dequeue(self):
return self.items.pop()
def size(self):
return len(self.items)
#约瑟夫问题仿真函数
def circle(k,nameList):
queue1=Queue()
for i in range(len(nameList)): #将名字列表逐个插入队列
queue1.enqueue(nameList[i])
i=1
while queue1.size()!=1:
temp=queue1.dequeue() #叫到哪个将哪个弹出
if i!=k:
queue1.enqueue(temp) #不是第k个再插入
else :
i=0 #是第k个重新计数
i+=1
return queue1.dequeue()
#主函数
if __name__=='__main__':
nameList=["Bill","David","Susan","Jane","Kent","Brad"]
print(circle(7,nameList))
运行结果:
Kent
***Repl Closed***
总结:
多进程,多线程,提供并发。
IO密集型:多线程。
计算密集型:多进程。
要利用多核CPU,一般采用:多进程+协程。