生物医学中常见的问题:
how we know the tissue specific cell type?
how we know the exactly cell type from a bunch of bulk data?
basic analysis flow:
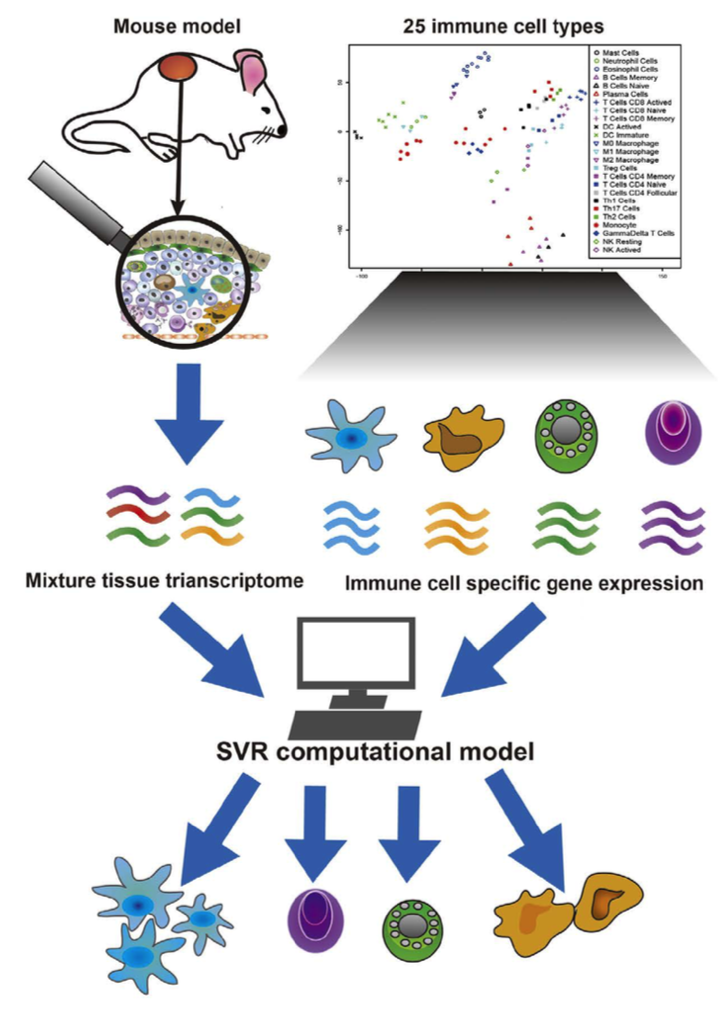
the basic principle:
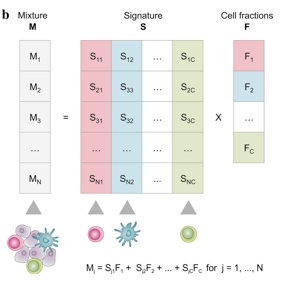
the specific steps:
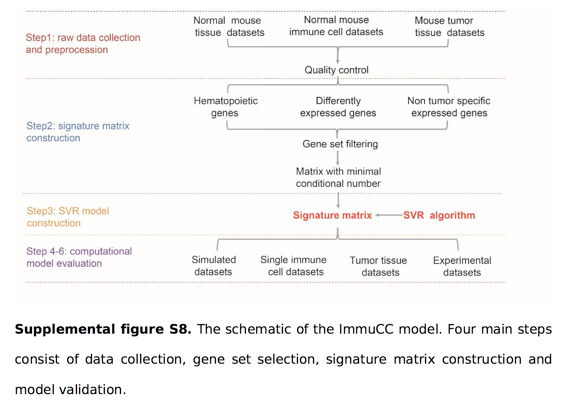
some key words:
NGS Next-generation sequencing
二代测序
NMF Non-negative matrix factorization
非负矩阵因子分解
NNML Non-negative maximum likelihood
非负矩阵因子相似性
RMSE Root-mean-square error
标准误
ES Enrichment score
富集分数
GSEA Gene set enrichment analysis
基因集的富集分析
ssGSEA Single-sample gene set enrichment analysis
单样本的基因集的富集分析
SVR Support vector regression
支持向量回归
LDA Latent Dirichlet allocation
中文叫做文档主题生成模型,主要在机器学习中用来生成和分析大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。
一篇review中所涉及的在生物信息领域分类或者预测细胞亚型的软件和代码,分析方法;

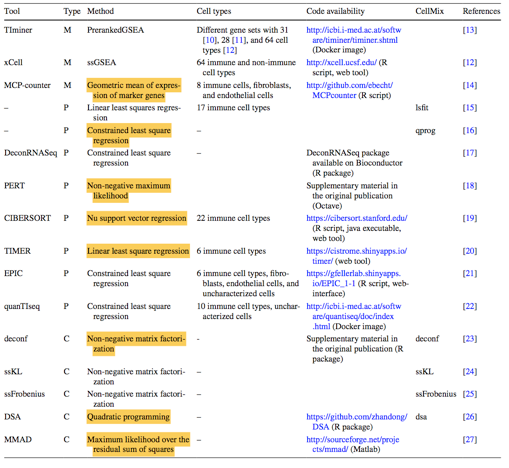
The Prediction of MCP counter method: 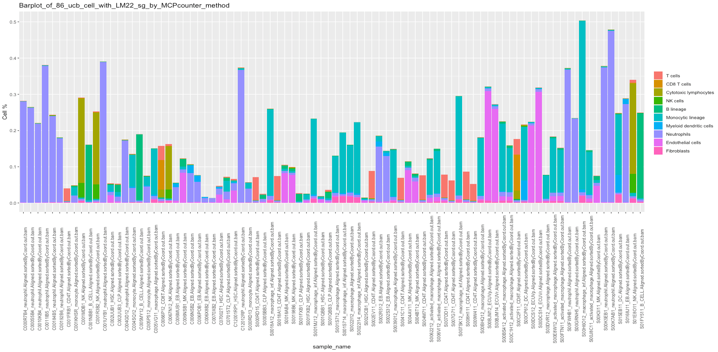
我们可以看出颜色为多的就是预测准确的比例,大部分的celltype都有比较完整色域,可推测比较准确的预测性能;
但是还需更多的测试,因为很多软件都是因为细胞类型或者是marker基因matrix过少而显得比较有局限性。
总结:掌握好deconvolution的机器学习底层方法和原理,及其在不同情况下的使用策略。
只有好好的理解了才能更好的用这些tools来分析自己的数据,同时找准一个媒介来实现它(no matter R or python)