我的批注一:
方案三在实际运行中遇到了一些问题:
第一:我的脚本反斜杠“\”变成了红色报错,直接粘贴博主的脚本保存为train.sh文件,用bash train.sh的方式运行是不行的,暂时还没找到原因。补充一下博主的脚本里面没有写dataset_set和train_dir的路径。
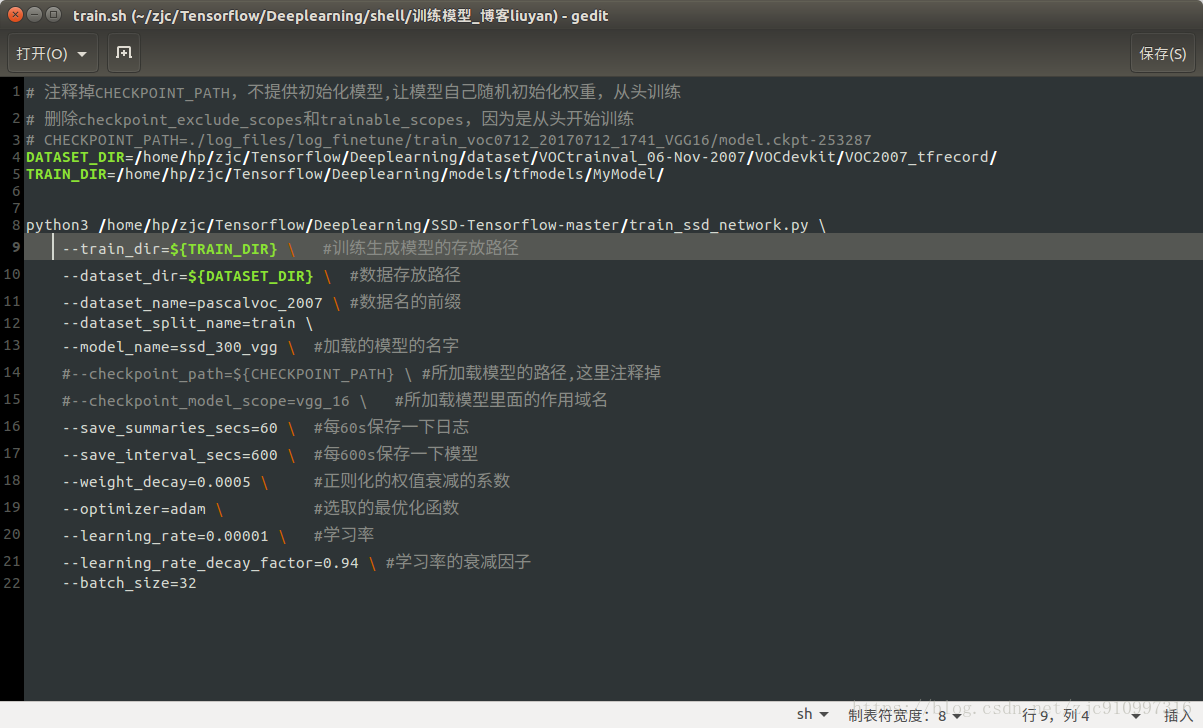
问题已经解决:把注释去掉,另外换行也有问题需要从新TAB换行即可

第二:因此我使用的方法是另外一中不需要脚本的方法,直接在train_ssd_network.py里面去修改对应博主提供的脚本的内容。
比如dataset_name=pascalvoc_2007要去搜索dataset_dir位置把后面的然后改为pascalvoc_2007,我在这里卡了很久
model_name=ssd_300_vgg 同样去找 model_name后面,替换为ssd_300_vgg

dataset_dir=${DATASET_DIR}

dataset_name=pascalvoc_2007
这个是关键

后面同理
批注二:
(在生成tfrecord的过程中dataset_dir的目录是VOC2007,在训练我玩们自己的数据集的时候,可以用自己的img,xml,text文件分别替换到voc2007的目录里面对应文件夹里面。)
如下图:我选中的文件夹可以删除,因为没有用到。

批注三:计算搜有图片总对象数目

1
1
1